基于车辆构成和特征提取的交通状态预估模型
2019-09-20
(中国科学技术大学 信息科学技术学院,安徽 合肥 230022)
在诸多交通问题中,交通拥堵是发生频率最高、影响最大、时间持续最长的问题。美国德克萨斯州2012年因交通拥堵损失近1210亿美元[1]。交通状态估计是交通拥堵控制的前提和关键,准确的交通状态估计可以密切监视交通系统状态,充分利用道路容量,指导运营管理决策[2]。
基于数据融合的交通状态估计是交通领域研究热点。Deng等人使用环路探测器计数、蓝牙旅行时间读数和GPS(Global Positioning System)定位样本等多个数据源,引入信息度量量化异构流量测量值,改善高速公路段上交通状态估计[3]。Yuan等人使用拉格朗日系统模型,采用扩展卡尔曼滤波技术估计交通状态,证明了拉格朗日估计优于传统欧拉方法[4]。Alfredo等人开发了一种基于模型的方法,利用多源数据建立动脉走廊实时交通预测模型,将高速公路状态估计拓展到城市环境[5]。Felix利用探测器速度数据,将交通流分解自由流、同步流以及动作干扰,获得数据低密度情况下更准确结果[6]。Yang利用密度、速度多种属性来估计该区域拥堵状态,在北京和上海大型出租车GPS数据集上取得良好效果[7]。Majid基于交通流理论开发一种定义明确的非线性函数,以根据队列尾部位置和连接车辆平均速度获得队列内车辆数量,在存在测量噪声情况下,仍具有较高效率和准确性[8]。
传统研究不同程度上实现了对交通状态的估计,但对监测器精度有较高要求。交通系统是非线性系统,具有强不确定性,许多现象无法用确定性分析方法来研究,应引入不确定分析方法。本文结合传统数据融合算法优势,同时引入车辆构成因素,结合CNN和SVM各自优势,利用多监测点数据进行拥堵预测,进而提升交通状态预估的准确率。
1 CNN模型和SVM模型
1.1 CNN模型
卷积神经网络是一种专门用来处理类似网状结构数据的神经网络,随着深度学习的发展,在诸多领域都表现优异,包括图像分类、对象监测、语义分割等,这要归功于它不同层次上学习判别特征能力[9]。从结构上看,CNN主要由卷积层、池化层和全连接层构成。
卷积层对两个实变函数进行卷积运算,在CNN中,一般进行多维度卷积操作:
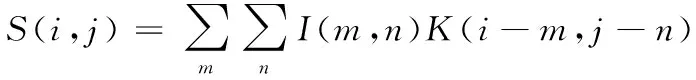
(1)
式中,I为输入数据;K为卷积核。
池化层使用某一位置相邻输出的总体统计特征来代替网络在该位置的输出,可以使输入表示近似不变,常用的池化操作有:最大池化、平均池化、L2范数以及基于中心像素距离的加权平均函数。
全连接层每一个结点都与上一层所有结点相连,把提取到的特征综合起来,在整个卷积神经网络中起分类作用。作用在于将卷积得到的特征映射到样本标记空间,核心操作是矩阵向量乘积。
1.2 SVM模型
SVM算法是基于统计学习理论的机器学习方法,它以最小化结构风险为依据,缩小样本置信区间范围,使经验风险与实际风险更加接近,提高样本可推广性。利用非线性变换将样本空间映射到高维空间,并在高维空间中寻找最优线性分类超平面,以兼顾最小化风险和算法泛化能力。康军等人已将SVM算法引用到交通领域,对短时交通流进行预测[10]。
SVM算法主要有三种:硬间隔支持向量机、软间隔支持向量机和非线性支持向量机。本文采用的是基于核方法的非线性支持向量机。
令φ(x)表示将样本点x映射后的特征向量,在特征空间中划分超平面所对应的模型可表示为
f(x)=wTx+b
(2)
式中,w和b为待求解的模型参数。则待求解问题可以表示为
(3)
其对应的拉格朗日对偶问题是:
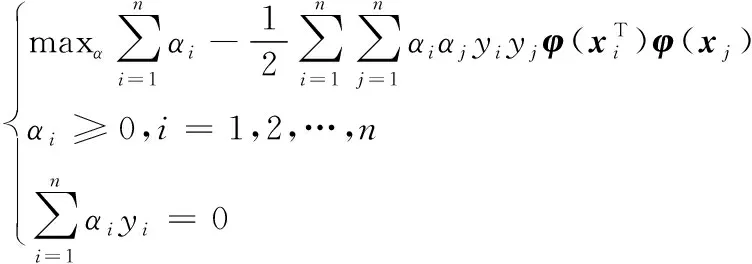
(4)
(5)
考虑到模型复杂度和数值计算的问题,本文采用的是RBF(Radial Basis Function)核函数:
(6)
于是式(5)可以写成:
(7)
得到最终决策函数:
(8)
2 拥堵判别模型
2.1 道路拥堵影响因素分析
传统交通状态估计模型主要采用速度、流量、道路占有率等信息作为模型输入,取得了一定效果[7]。本文将交通拥堵因素拓展到车辆构成,考虑相同车流量下,大车型比例越大,则越容易造成拥堵。因此,本文在拥堵因素方面采用速度、流量、道路占有率、大型车比例作为输入。
单个监测点可能存在精度不高问题,拥堵状况容易造成车辆排队过长超过监测器范围。因此本文假设拥堵路段单个监测器所测量数据是不准确的,采用某一交叉口上下游多个监测点对目标路段进行估计。
为实现交通状态预估计,本文采用某一时刻前20 min数据进行分析,提前预估出路段交通状态,为车辆路段选择提供参考。因此,本文模型的输入主要从拥堵因素、空间、时间三个维度进行构建。
2.2 拥堵状态分类
本文根据拥堵程度,将交通状态分为畅通、拥挤、拥堵三类。参考指标是美国加利福尼亚运输部性能测量系PeMS(Performance Measurement System)交通数据延迟项,通过聚类分析得到延迟项划分标准:延迟项为0,表示车辆没有延迟,定义为畅通状态;延迟项在0~1间,表示车辆有轻微延迟,定义为拥挤状态;延迟项大于1,表示有严重延迟,定义为拥堵状态。
2.3 CNN-SVM模型结构
在提取特征方面,CNN模型可以自动进行,避免了人工提取特征好坏对结果的影响。分类问题中,SVM学习超平面是距离各个类别样本点最远的平面,分类准确率更加具有优势。Niu等人已将CNN-SVM应用到图像识别领域[11]。为结合CNN和SVM优势,本文提出CNN-SVM混合分类模型对交通状态进行预估。CNN对交通数据进行特征提取,SVM利用提取后特征对交通状态进行分类,具体结构如图1所示。
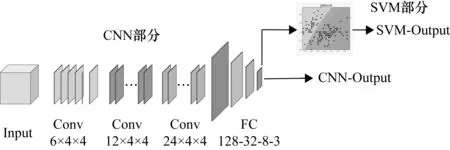
图1 CNN-SVM模型结构图
模型的输入是拥堵因素、空间、时间三维矩阵。为取得最佳学习效果,需要对模型输入进行标准化。本文采用的是线性归一化方法:
(9)
交通数据通过3个卷积层进和4个全连接层对交通状态进行估计。CNN训练结束后,将网络最后一层全连接的输出作为特征,输入到SVM模型中进行分类。CNN-SVM模型训练分为两个过程:
① 利用交通流数据训练CNN模型;
② 利用CNN提取的特征对SVM模型进行训练。
3 案例分析
3.1 数据来源和基本描述
美国加利福尼亚州是拥堵常发性地区,本文选取该地区Hollywood Fwy公路进行分析,路段监测点分布如图2所示。设待预测路段编号为O(764766),选取呈对称分布的3个上游监测点U1(717488)、U2(717489)、U3(717490)和3个下游监测点D1(775990)、D2(717486)、D3(769405)。
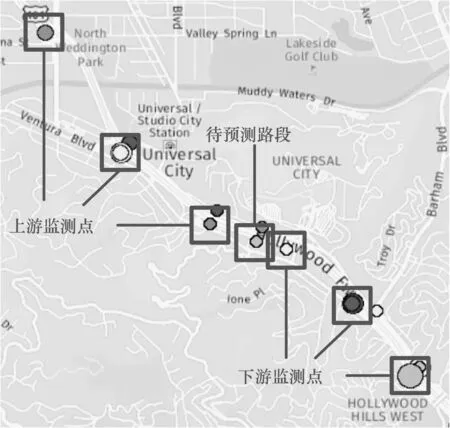
图2 美国加利福尼亚州局部路段监测点分布图
假设待预测路段单个监测器监测数据是不准确的,实验目标是通过该路段上下游多个监测器前20 min监测数据对该路段交通状态进行预估,进而指导车辆选择合理行车路线。
实验采用2017年9月20日到2017年10月27日PeMS交通数据进行实验,数据的采样间隔时间为5 min。其中,2017年9月20日到2017年10月20日作为训练数据,2017年10月21日到2017年10月27日作为测试数据。
3.2 对比实验介绍
车辆构成信息和CNN-SVM模型是影响预估准确性的主要因素。因此,本文设计了两个对比实验,分别对比CNN-SVM模型下考虑车辆构成和忽略车辆构成的预估准确性,以及CNN模型和CNN-SVM模型的预估准确性。
实验具体参数如下:
① CNN模型。卷积层个数为3,卷积核大小为2×2,3个卷积核层数分别为6、12和24,全连接层的神经元个数为128、32、8、3,激活函数采用ReLU函数,模型输出采用softmax激活函数。模型采用交叉熵损失函数,训练过程采用Adam算法进行优化。
② SVM模型。采用Hinge Loss损失函数,核函数采用RBF核函数。为防止过拟合,惩罚因子c设置为0.8。
3.3 实验结果分析
CNN-SVM模型预测结果如表1所示。其中拥堵状态和畅通状态的预估准确率相对较高,测试集中畅通状态预估准确率达到了96.77%;拥挤状态预估准确率相对较低,只有90.71%。原因在于拥挤状态处在畅通和拥堵状态之间,容易被误判为畅通或者拥堵。但从整体上来看,训练集中交通状态预估准确率达到94.68%,测试集准确率达到了95.32%,准确度基本满足预估要求。
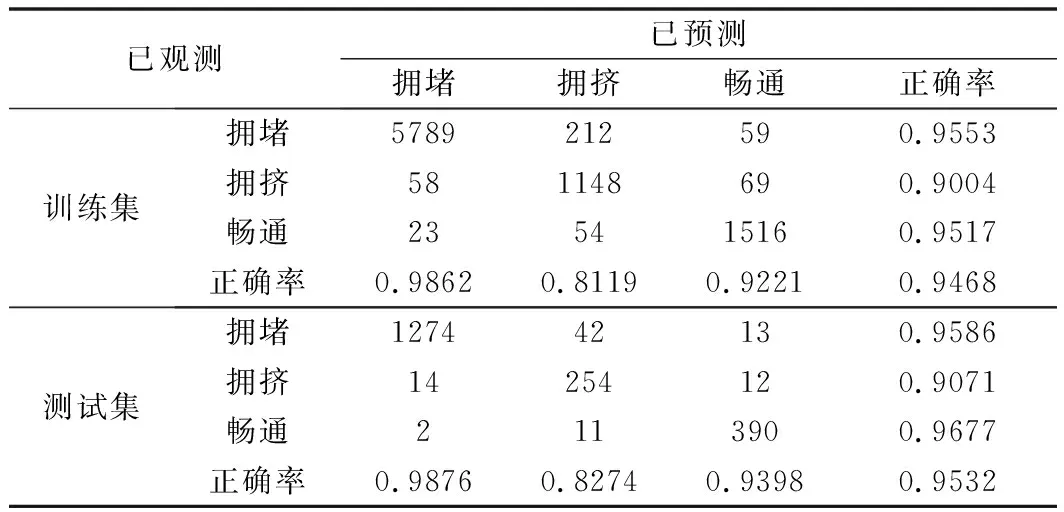
表1 CNN-SVM模型预测结果
考虑车辆构成和忽略车辆构成对比实验中,模型训练准确度如图3所示。黑色实线代表忽略车辆构成训练结果,灰色虚线代表考虑车辆构成训练结果。
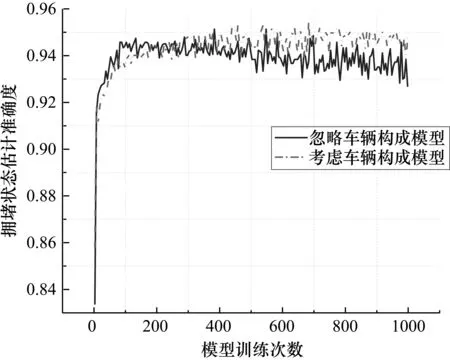
图3 考虑车辆构成和忽略车辆构成训练结果对比
灰色虚线刚开始上升速度较慢,当训练次数超过300次后,考虑车辆构成模型准确率逐渐高于忽略车辆构成模型准确率。原因在于,考虑车辆构成信息时,模型需要学习知识比较多,一开始准确度上升比较慢,后期经过充分训练,考虑车辆构成的模型得到了更多信息,因此预测结果比忽略车辆信息更高。同时,忽略车辆信息的模型信息量有限,后期随着训练次数增加开始趋向于过拟合,预估效果后期开始逐渐下降。
针对不同数据集,考虑车辆构成和忽略车辆构成预测结果如表2所示。验证集中,考虑车辆构成模型预估准确度比忽略车辆构成模型提升1.40%,在测试集中,考虑车辆构成的模型预估准确度比忽略车辆构成模型提升1.12%。说明车辆构成对于交通状态有着不可忽略的影响。
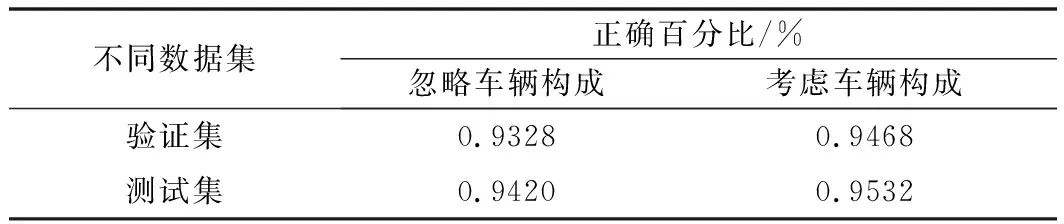
表2 考虑车辆构成和忽略车辆构成预测结果对比
CNN模型和CNN-SVM模型的对比实验中,CNN采用的是softmax分类器,CNN-SVM采用的是SVM分类器,其预估结果如表3所示。验证集中,CNN-SVM模型预估准确度比CNN模型提升1.84%,在测试集中,CNN-SVM模型预估准确度比CNN模型提升2.25%,说明SVM具有更高的分类效果。
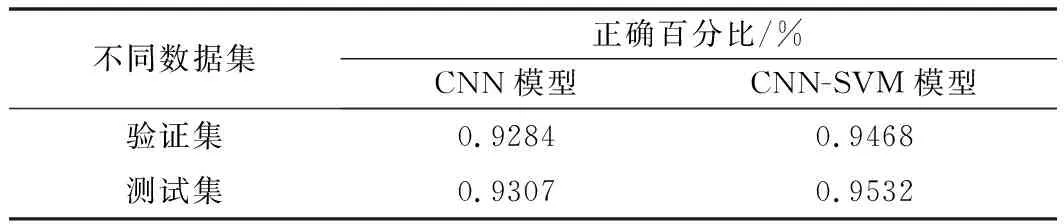
表3 CNN模型和CNN-SVM模型预测结果对比
SVM模型虽然可对交通状态进行估计,但在单个监测器数据不准确的前提下,其使用其他监测器数据时分类准确率不足80%,且输入维度过高,不适合基于多监测器检测数据的交通状态预估。因此,在交通状态预估方面,CNN-SVM相对于CNN模型和SVM模型更加具有优势。
4 结束语
本文提出了一种基于车辆构成和特征提取的交通状态预估模型,考虑相同车流量下,大车型比例对拥堵的影响。将交通状态分成畅通、拥挤和拥堵三种状态,以多个道路监测器数据为输入来预估交通状态。通过CNN自动提取交通拥堵特征,将得到的特征输入SVM进行交通状态预估。通过考虑车辆构成和忽略车辆构成的实验,以及CNN-SVM模型和CNN模型的对比实验,在PeMS数据集的Hollywood Fwy公路上进行验证,结果表明考虑车辆构成信息的CNN-SVM模型,具有更好的交通状态预估能力。
本文实验没有考虑不同道路通行能力差异带来的区别,后续可以结合不同规模的道路进行分类探讨,使模型具有更广泛的应用场景。
