基于改进BKM聚类算法的WiFi室内定位方法
2019-09-20
(上海工程技术大学 电子电气工程学院,上海 201620)
近几年,移动手机越来越普及,人们生活方式发生显著变化,基于用户位置服务(Location Based Services,LBS)也得到快速发展,同时对于定位技术的要求也越来越高。在室外,目前应用最为广泛的是基于卫星信号的定位技术,像谷歌地图、百度地图、高德地图等一批较成熟的产品,在室外已经可以给用户提供高精度的定位服务。但是在室内,都是密集的钢筋建筑,卫星信号会容易被削弱或阻挡,导致用户无法进行可靠的定位,而室内又是人类活动的主要场所,用户在室内对于LBS的需求更大,同时针对复杂的室内环境,对于定位技术的要求也更高,所以展开对室内定位技术的相关研究具有重要的意义[1]。
目前常见的室内定位技术有UWB、RFID、ZigBee等技术,虽然以上这些定位技术都能实现对室内用户终端的定位,但同时也都需要依靠一些特定的硬件设备,部署成本高,很难进行大范围的推广。随着WiFi技术的成熟,在很多场所已经实现WiFi全覆盖,尤其是在大型的商场、地下停车场等公众场所。因为WiFi具备自身部署成本低、响应时间快的特点。WiFi已经成为目前室内定位应用上普遍采用的技术之一,同时对WiFi定位技术的研究也越来越广泛[2-3]。
通过WiFi在空间中的电磁接收信号强度(Received Signal Strength,RSS),对室内目标进行定位是当前主要方法之一。其中,用的最多的是基于位置指纹的定位方法,通过利用WiFi电磁信号在空间中的分布规律作为定位基础,实现方法简单、定位精度高。文献[4]提出一种K-means聚类算法运用于WiFi室内指纹数据库的建立阶段,改进了指纹数据库聚类中心选择的复杂度,但是当指纹数据之间的差异比较大时,该方法可能出现大的子类被过度分割反而降低定位的准确度。文献[5]提出了内核K-means算法,并结合SVM,减少了非线性SVM的训练样本,大大减少了采样时间复杂度,但是这种方法也容易导致局部定位区域过拟合现象。文献[6]~文献[9]都是利用BKM聚类算法来优化定位方法,提高了定位精度,但是BKM聚类算法和经典的K-means聚类算法一样,在聚类前都需要随机的确定聚类个数,这样导致聚类的结果容易受到聚类个数的影响。
针对BKM聚类算法在指纹定位过程中存在的不足,本文结合层次聚类的方法对BKM聚类算法进行改进,通过设置聚类准则函数,不需要在聚类前就初始化聚类个数,可以自动确定聚类个数,并结合Chameleon聚类算法,对一些过度划分的簇,以及偏移的点进行归并,优化聚类效果,提高定位精度。
1 基于WiFi电磁指纹定位方法
位置指纹定位方法主要是分为两个阶段完成,分别是离线训练和在线匹配[10]。离线阶段系统采集定位区域内各个参考点接收来自不同无线访问节点(Access Point,AP)反馈的RSS,与参考点的物理地址进行一一映射,建立位置指纹向量并存储在数据库中;在线阶段时采集待测点的位置指纹信息,与数据库中指纹信息进行匹配,最后估算出当前用户的位置,定位流程如图1所示。
2 BKM聚类算法
BKM聚类算法基本思想如下:首先初始化簇表S,使S包含所有点组成的簇。然后,随机从S中选取一个簇ci,通过K-means算法,对选定的簇ci二分,并计算每个簇的最小误差值,选择误差最小的两个簇,再将得到的两个簇加入S中,更新簇表S。这样反复下去,直到最终产生K个簇[11]。
这里通过误差平方和(SSE)作为目标函数,来衡量聚类质量。SSE的定义如下:
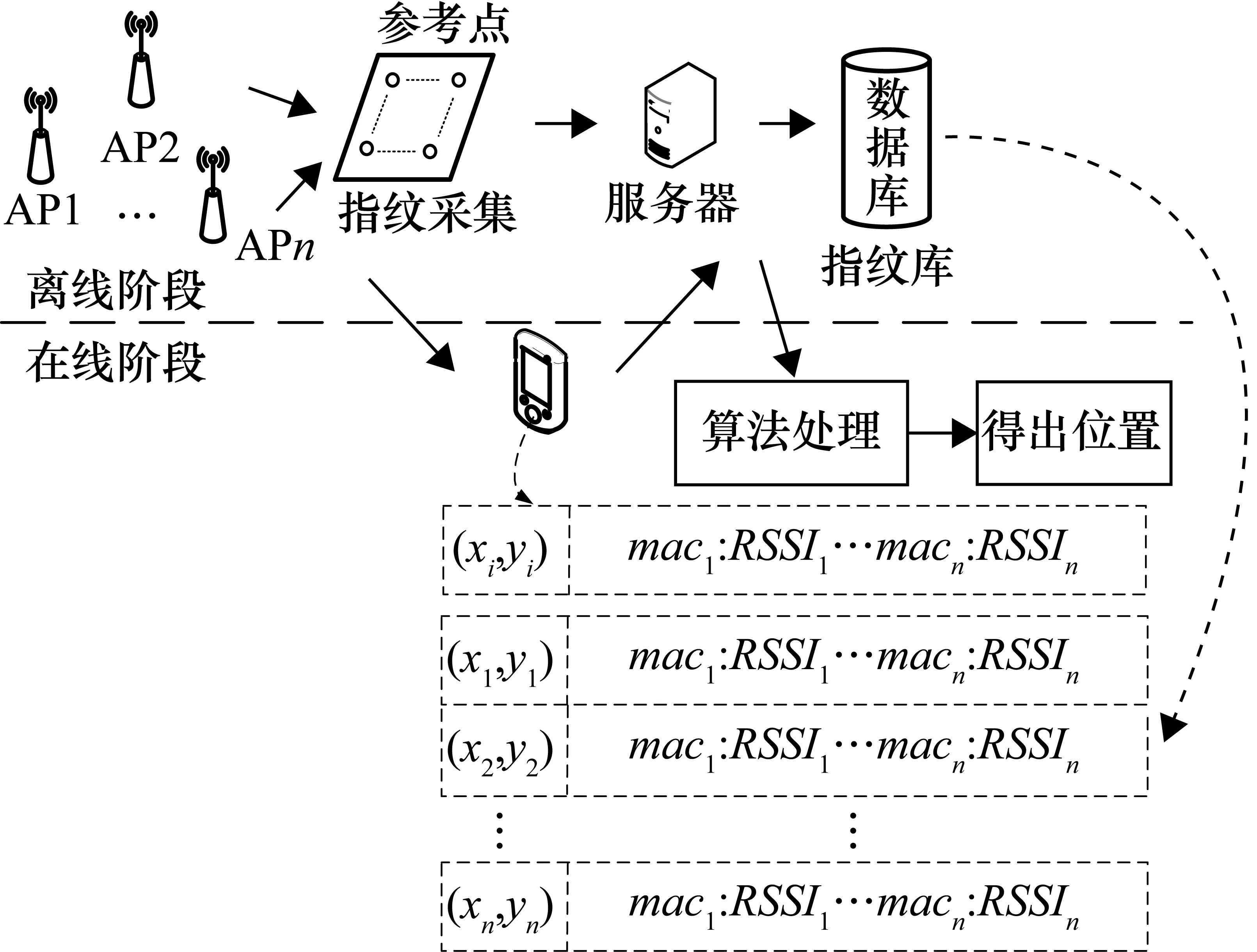
图1 位置指纹定位方法流程图
(1)
式中,ci为簇的聚类中心,x为该簇中的一个样本。
以上过程隐含着一个原则是:聚类性能是通过SSE值来进行衡量的,所以SSE值越小越好,聚类效果也就越好。对上述簇的划分过程不断重复,直到最后簇数目达到目标值为止,与K-means算法相比,BKM算法可以加速K-means算法的执行速度,能够克服K-means收敛于局部最小的缺点,但是BKM聚类算法仍然受初始设定的聚类个数影响。
3 改进的BKM聚类算法
BKM聚类算法与经典K-means聚类算法相比,虽然在计算效率上有所提高,但是在计算过程中需要进行多次K-menas聚类,增加了计算时间上的复杂度。所以,在此基础上,本文对BKM算法进行改进,聚类前不需要初始设定聚类个数,通过二分聚类一次,就可以得到最小SSE的簇集。算法要求首先引入一个聚类测度函数f:
(2)
式中,xij为样本(xi1,xi2,…,xin)中的对象,ci为簇中样本的类中心。选择一个样本x={x1,x2,…,xn},样本包含n个数据对象,分别给定迭代次数和测度函数一个初始值,然后随机地在样本中选择一个ci,并将该ci作为聚类中心,加入到簇表s={s1,s2,…,sk}中。在簇表中选择一个SSE最大的簇,然后在该簇中找出与该簇中心欧氏距离最大的一个样本xi,再找出与样本xi欧氏距离最大的样本xj,同时将得到的两个点,作为新的初始的聚类中心,生成两个新簇,重新计算聚类中心为X1,X2,将其加到簇表中,同时删除旧的聚类中心,并更新簇表,再计算测度函数ft的值,其中t表示迭代次数。
改进后的BKM算法如下:
输入 数据集x={x1,x2,…,xn}
输出 聚类结果X={X1,X2,…,XK}
初始化:f=0.01,t=1,s={}
Begin
Repeat
选择一个聚类中心,作为初始中心,并将该聚类中心加入到簇表中
选取SSE最大的簇
找出该簇中与簇中心最远的点以及与该点最远的点,将这两个点作为新的聚类中心
将这两个新的聚类中心加到簇集S中,删除旧的簇中心
计算当前聚类准则函数的值,与判断值进行比较
Until
ε>Δ(阈值)
输出所有聚类结果
初步改进后BKM聚类算法通过设定合理的ε值和测度函数,可以自动确定聚类个数,这样就不用和BKM聚类算法一样,需要多次进行K-means计算的过程。但是当ε值选择不合适的时候容易将数据集划分过细,所以引进Chameleon算法,根据相近程度合并这些划分过细的簇。具体方法是通过计算簇表中任意两个簇的互连性RI和紧密性RC这两个指标来判定,当RI和RC的值都比较大时才合并这两个簇[12]。
相对互联度RI:
(3)
相对近似性RC:
(4)

R=RI(Ci,Cj)×RC(Ci,Cj)α
(5)
其中α为指数,通常大于1。
优化后的算法如下:
输入 二分聚类后的聚类结果X={X1,X2,…,XK}
输出 输出合并后的聚类结果
通过改进BKM聚类算出新的聚类结果,将其中每一个簇看成一个整体
Begin
Repeat
计算每个簇与邻近每个簇的RC和RI值,得到簇间相似度矩阵
构造K-最近邻图,并对其进行划分
合并对于相似度函数具有最大值的簇
Until
满足条件
输出新的聚类结果
4 仿真与验证
4.1实验环境
本文通过实验来验证定位方法的提高,选择的实验环境为本校1号实训楼的一层实验室及走廊,实验用的AP为该楼层现有的部分AP,且选取10个大部分采样点都能接收到信号的AP。实验用的信号采集设备为联想Lenovo天逸310笔记本,通过内置无线网卡和自主开发的采集软件进行信号采集。
实验共选取了246个指纹采样点,每个指纹采样点处连续采集120组数据,时间间隔为1 s,以1.5 m×1.5 m作为采样间隔,指纹采样点分布如图2所示。为了更好地量化定位效果,所以定义一个用来判断误差的函数为:
(6)
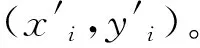
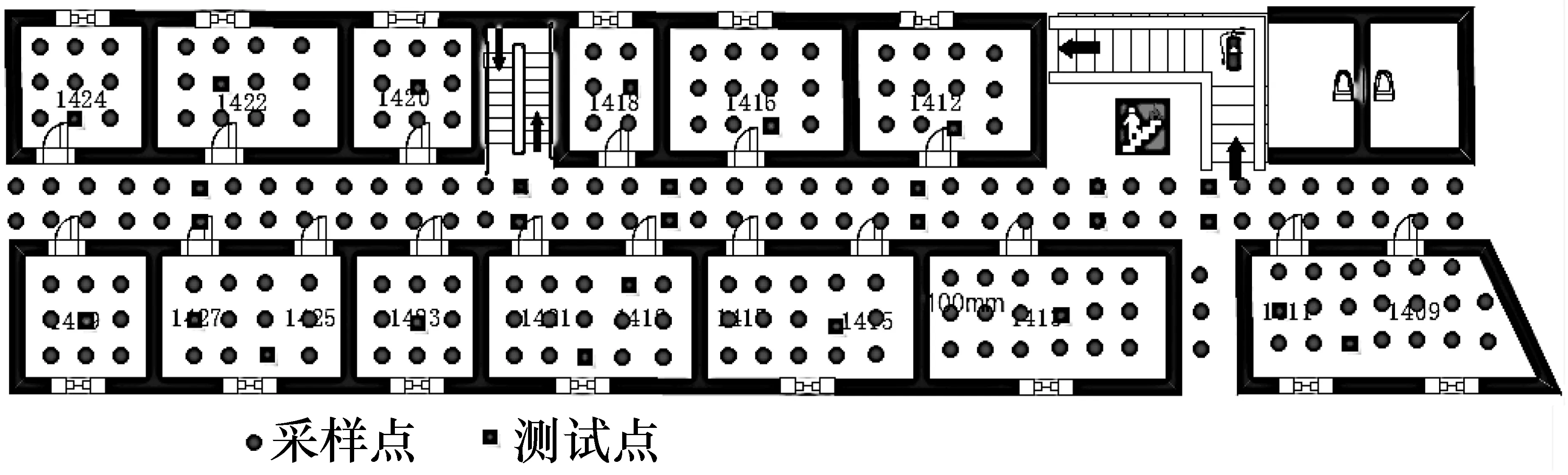
图2 实验区指纹采样点参考图
4.2 数据预处理
因为在实验过程中会受到人员走动、开关门的影响,室内的RSS具有不稳定性,所以聚类前需要对每个采样点采集到的多组数据进行预处理,对数据中的离群值进行剔除,保证数据指纹库的稳定性和可靠性,有利于建立更加精确的指纹数据库。常用的数据预处理方法有3σ法、Chauvenet法、Grubbs法和狄克逊法。本文主要采用3σ法,对初始数据集进行预处理。如图3为预处理前后的RSS变化曲线对比。
4.3 实验结果分析
本文主要通过三种算法进行实验对比,分别是K-means、BKM和改进BKM,表1为实验设定的相关参数。
为了直观展示效果,对实验结果进行量化,图4给出了三种算法的定位误差平均值,可以看出改进的BKM的平均定位误差为1.2125 m,要比K-meanc和BKM平均误差降低48.6%和26.5%。
图3 数据预处理前后的RSS变化曲线对比
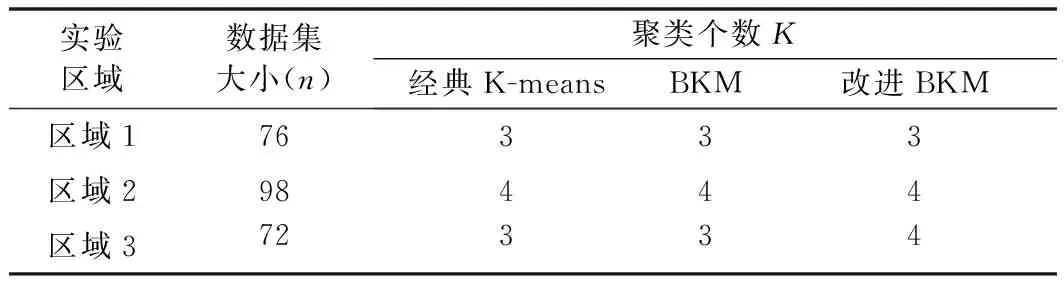
实验区域数据集大小(n)聚类个数K经典K-meansBKM改进BKM区域176333区域298444区域372334
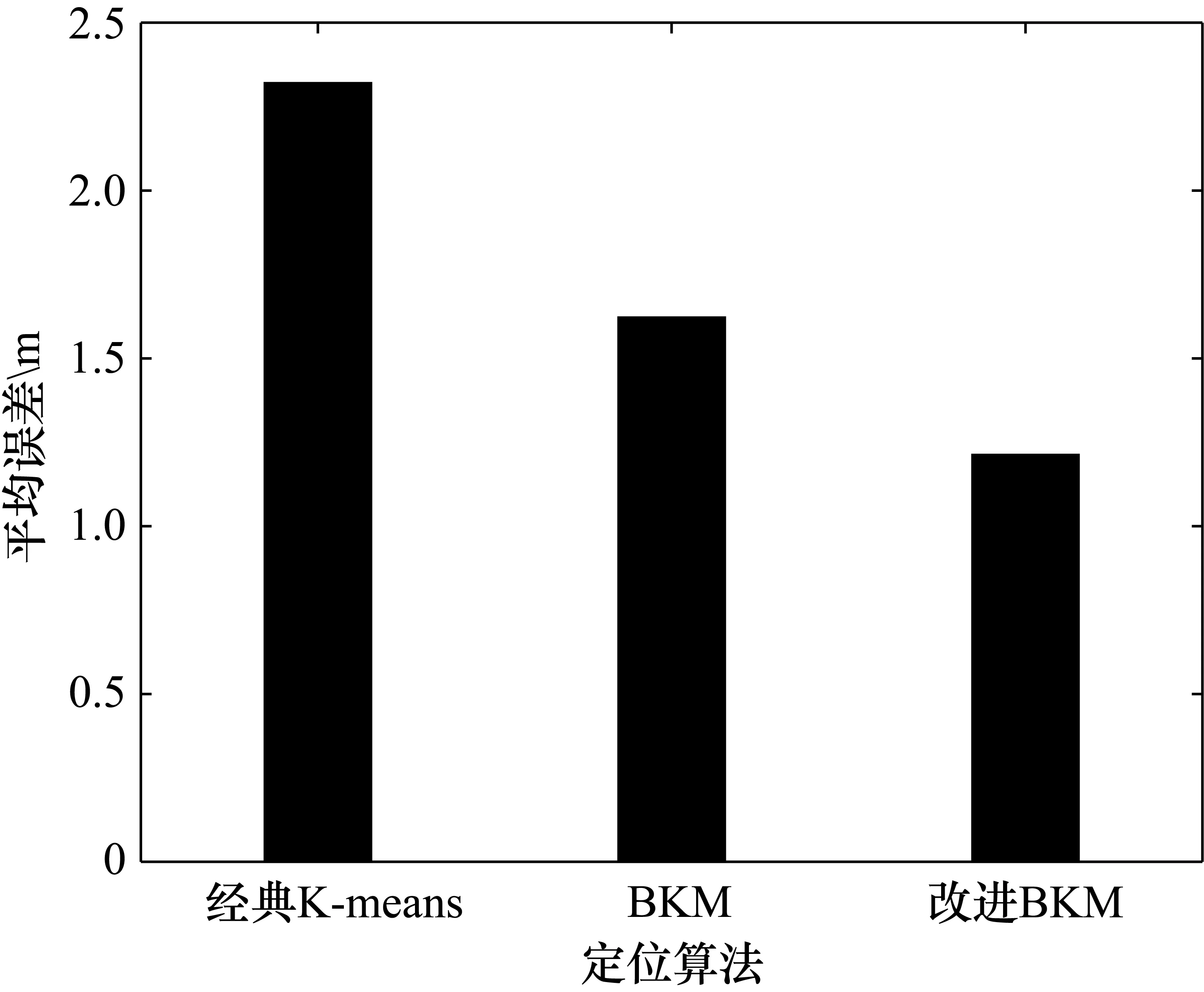
图4 三种不同算法的平均定位误差
图5为不同算法的实际定位误差累计概率图,从图中可以看出,改进的BKM算法在定位结果中,有90%的定位目标误差范围在2.5 m内。作为比较,经典的K-means和BKM在2.5 m范围内的定位误差概率只有78%和82%。综合以上所述,可以说明本文提出的改进的BKM算法在定位精度上要比K-means和BKM算法好。
表2所示的是三种算法在3个不同区域上的平均定位时间。从表2中可以看出,BKM聚类在性能上要比经典的K-means聚类算法好,在定位时间上平均快0.44 s,但是相较于BKM算法和经典K-means算法都需要提前确定聚类个数,改进的BKM聚类算法,不用提前指定聚类的个数K值,通过设置聚类准则函数就

图5 三种算法的定位误差累计分布概率


表2 不同算法的平均定位时间 单位:s
5 结束语
在室内复杂的环境下,WiFi电磁信号由于受到多径效应的影响,导致定位精度不高、误差偏大。本文在分析经典K-means聚类算法和BKM算法的基础上,提出一种改进的BKM聚类方法,在指纹库构建阶段通过设置聚类测度函数,可以自动获取聚类的个数,不需要初始化聚类个数,提高了指纹聚类的效果,同时引进Chameleon算法对初步聚类后的结果进行优化,合并一些不合理的簇,提高指纹在线定位阶段的可靠性和定位精度。实验结果表明,通过利用本文的改进方法,能够将定位平均误差控制在1.2125 m左右,定位误差在2.5 m以下的概率也达到了90%。
利用WiFi和位置指纹的定位技术,定位效率高、成本低,市场应用广泛。而本文提出的定位方法能够在一定程度上提高定位精度,减少定位时间,增强用户的定位体验,具有很好的现实意义。
