基于重采样和集成学习的弥漫大B细胞淋巴瘤患者复发风险预测模型*
2019-09-17赵志强余红梅郑楚楚黄雪倩武淑琴罗艳虹
王 蕾 赵志强 余红梅 郑楚楚 黄雪倩 武淑琴△ 罗艳虹△
【提 要】 目的 对某肿瘤医院血液科2011-2015年283名弥漫大B细胞淋巴瘤患者进行达到完全缓解后三年内的复发风险预测,为患者三年内的复发情况提供参考。方法 用logistic回归进行复发影响因素分析。采用重采样(包括SMOTE等三种方法)处理不平衡数据,同时基于boosting集成分别构建C5.0决策树、SVM和logistic回归复发风险预测模型。结果 由logistic回归可知,Ki-67(P=0.006,OR=1.826)、LDH是否升高(P=0.012,OR=2.084)、原发纵膈肿物(P=0.033,OR=0.333)及疾病等级(P=0.001,OR=1.605)是弥漫性大B细胞淋巴瘤患者三年复发的重要影响因素。通过将训练集与测试集回代对各种模型性能进行评价,并用五种评价指标的比较模型性能可知,集成模型均优于其对应的单个学习器;平衡后数据构建模型性能均优于未平衡数据构建模型,其中SMOTE最优;在测试集验证的模型中,经过SMOTE平衡数据构建SVMBOOST集成模型(准确率=0.93,F值=0.94,AUC=0.93,Rmse=0.26,G-mean=0.93,灵敏度=0.97)和C5.0BOOST模型(准确率=0.94,F值=0.95,AUC=0.94,RMSE=0.24,G-mean=0.94,灵敏度=0.94),均有较优的表现。结论 基于重采样和集成学习构建的经过SMOTE平衡后SVMBOOST模型达到预期效果。
弥漫大B细胞淋巴瘤(diffuse large B cell lymphoma,DLBCL)是最常见的非霍奇金淋巴瘤(non-Hodgkin lymphoma,NHL),它在每年新诊断的成人非霍奇金淋巴瘤(NHL)中占30%至40%。虽然R-CHOP(利妥昔单抗Rituximab+环磷酰胺Cyclophosphamide、阿霉素[羟基柔红霉素]Doxorubicin、长春新碱Vincristine和强的松Prednisone)化疗方案是目前的标准治疗方法,对于疾病等级Ⅲ、Ⅳ级的患者都有较好的疗效,患者生存率为60%~90%。但仍存在30%到50%患者对该方案耐药,进而使达到完全缓解(complete remission,CR)后的患者有30%复发[1-2]。复发使患者的生存率降到10%~20%。本研究意在对达到完全缓解的患者的复发风险进行预测并探究影响患者复发的危险因素。因30%到50%复发率造成数据的不平衡,故而需对数据进行重采样使其平衡[3]。将经过重采样数据与未平衡数据所构建的预测模型的性能进行比较。
传统用于风险预测的模型是logistic回归,由于影响DLBCL患者复发因素错综复杂,目前尚无定论,故判定患者的复发风险需要收集大量特征。大量文献表明C5.0算法是在输入字段(即患者特征)较多的问题中表现较稳健,处理的数据类型可包括连续型和离散型,分类速度快、精度高,可生成易于理解的分类规则,故本研究采用C5.0决策树构建模型[4-5]。因支持向量机(support vector machine,SVM)针对小样本、非线性、高维数的数据具有较好的预测性能[6],故选择SVM构建预测模型。并将以上模型与传统logistic模型比较。以上模型均为弱学习算法,训练集中较小波动都会使模型预测结果产生较大变化,而boosting集成通过赋予弱学习器不同权重的方法有效地提高模型性能,本研究采用集成学习[7],以便使构建模型为临床医生对患者三年内复发风险及相关危险因素提供更为有效预测。
资料与方法
本研究数据来源于某医院2011-2015年被诊断为DLBCL并通过一线化疗方案达到完全缓解病例共283例,其中三年内复发人数为71例。根据《2013年中国弥漫大B细胞淋巴瘤诊断与治疗指南》[20](中华医学会血液学分会,2013)及电子病历记录情况,收集每个样本的15个变量。具体变量名称及赋值见表1。首先录入到Epidata3.0软件中,采用双录入方式,并逐一核对。表1中可见未复发患者几乎是复发者的三倍,故而需平衡数据后再进行预测。
原理及方法
本研究分别用欠采样(under-sample)、过采样(over-sample)与少类样本合成过采样技术(synthetic over-sampling techniques for small samples,SMOTE)采样对数据进行数据平衡化,分别带入C5.0决策树、支持向量机和logistic回归中构建模型。之后分别用boosting集成,构成C5.0-boosting集成模型,SVM-boosting集成模型和logistic-boosting集成模型。
1.抽样工作原理及过程
对于不平衡数据主要采用重采样的方法,重采样方法可分为两个层面:(1)数据层面包括过采样及欠采样,过采样通过增加少数类中的样本数使数据集达到平衡,欠采样则是通过减少多数类平衡数据集;(2)算法层面包括SMOTE、随机过采样等,其中SMOTE是由Chawla于2002年提出的[8],其主要思想是通过在一些位置相近的少数类样本中插入增加新的并不存在的样本点,而非简单复制已有样本点。此法可有效避免“过拟合”问题[9]。本研究中使用R软件中DMwR包中SMOTE语句实现,其中设定perc.over=500,perc.under=100。使用R软件中ROSE包中ovun.sample语句并设定method选项以实现欠采样与过采样。
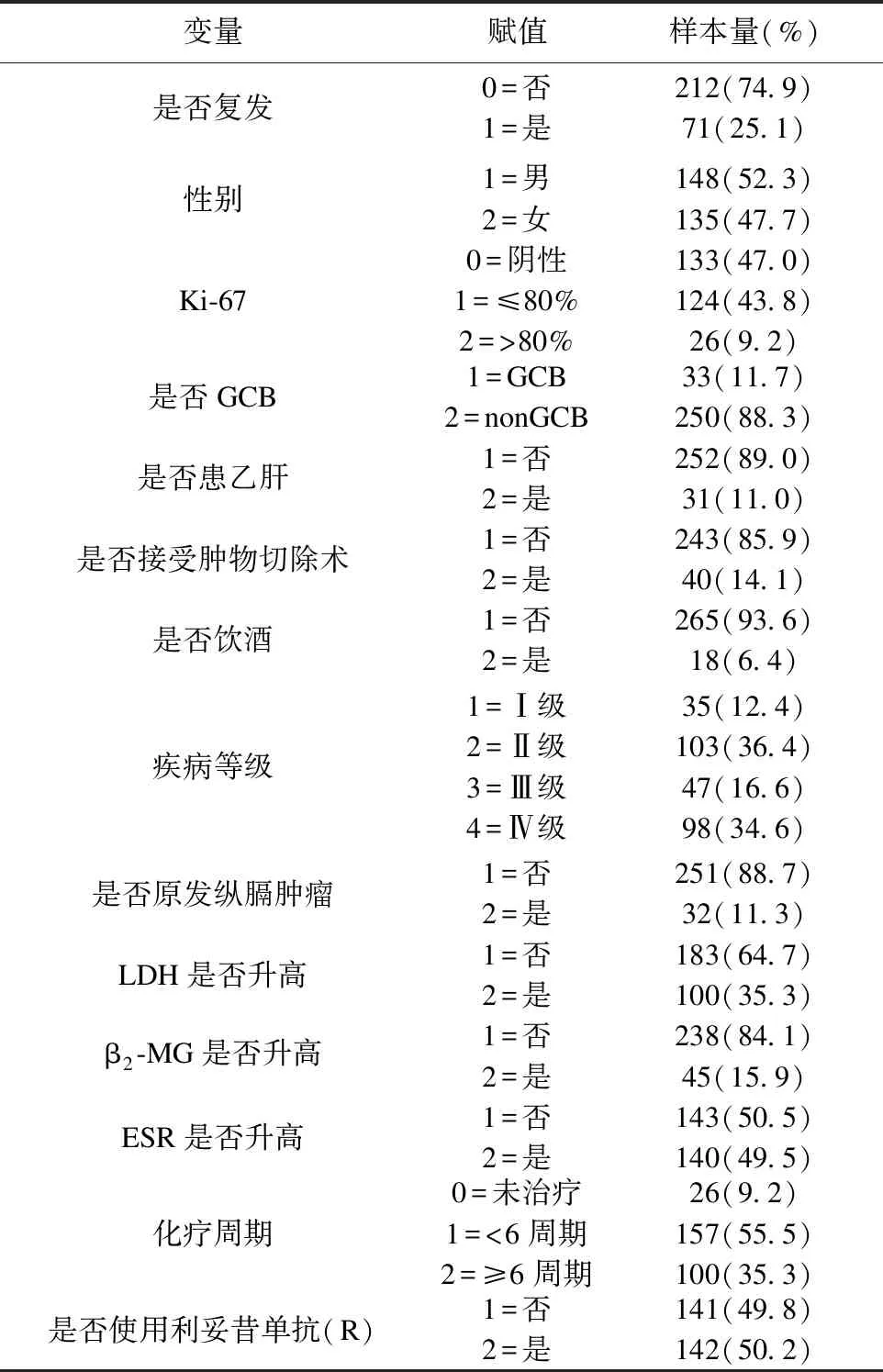
表1 283例弥漫大B细胞淋巴瘤患者基本特征及赋值
2.支持向量机工作原理
将训练数据集非线性映射到高维空间(Hilbert空间),以便将原先线性不可分数据集变为线性可分。并在特征空间中建立最大间距最优分离超平面,使最优超平面与两类样本间距离最大[12-14]。其中结构风险最小化思想使学习器经验风险与泛化误差均较小。本研究利用R软件中kernlab包实现中的ksvm语句,其中kernel选项设定为rbfdot,即为高斯核。
3.C5.0决策树工作原理
C5.0决策树算法较C4.5决策树[10-11]加入boosting过程,其分类依据为信息增益(information gain),通过信息增益最大字段对样本数据分割。通过裁剪合并所得决策树各节点确定最佳阈值。本研究利用R软件中C50包中的C5.0语句,若需要对C5.0决策树进行boosting集成时,设定语句中的trials选项,本研究中将其设为10。
4.集成学习工作原理及过程
集成学习是由多个单个弱学习组成一个强学习器,由同一种弱学习器组成的强学习器称为同型集成模型。由两种及以上弱学习器组成的强学习器称为异型集成模型。本研究中采用boosting算法进行同型集成。boosting集成算法是一种迭代算法,其主要思想是利用重采样的技术对训练集样本进行采样形成多个样本子集,将每个样本子集带入模型训练得到一个弱分类器,以每个弱分类器错误率计算每个样本的权值,根据权重投票表决加权求和,最终形成一个强分类器[15]。本研究中对SVM及logistic的集成均是由R软件caret包中train语句实现。
本研究使用SPSS 22.0进行logistic回归分析,后使用R软件进行数据平衡与模型构建。针对所构建的模型主要使用准确率、灵敏度、F值、G-mean、RMSE及AUC等评价指标进行模型评价。
结 果
1.logistic回归结果
将以上变量纳入logistic回归模型中采用向前似然估计方法,构建关于DLBCL患者三年复发风险预测模型,结果见表2。

表2 logistic回归结果
由logistic回归结果可知LDH是否升高的比值比(OR)最高,OR=2.084其95%CI为(1.178~3.686),说明LDH升高的患者的三年复发风险是正常患者的2.084倍。其次为生化指标Ki-67,OR=1.826其95%CI为(1.188~2.806),说明生化指标Ki-67大于70%患者的复发风险比小于70%的患者高82.6%。疾病等级的OR=1.605其95%CI为(1.208~2.133),说明患者疾病等级每升高一级其复发风险增加60.5%。原发纵膈肿瘤的OR=0.333其95%CI为(0.121~0.912),说明原发纵隔DLBCL肿瘤预后较好,较原发其他部位的患者复发风险降低66.67%。
2.运用重采样与boosting集成后的C5.0决策树、支持向量机与logistic模型
对数据分别进行循环采样及模型构建各1000次,并将训练集与测试集分别代入模型进行验证,选取以下六个指标对模型进行评价,篇幅所限,仅给出使用测试集的验证模型评价结果,见表3。(其中用1代表未平衡的数据,2代表经过欠采样,3代表经过过采样,4代表经过SMOTE采样)
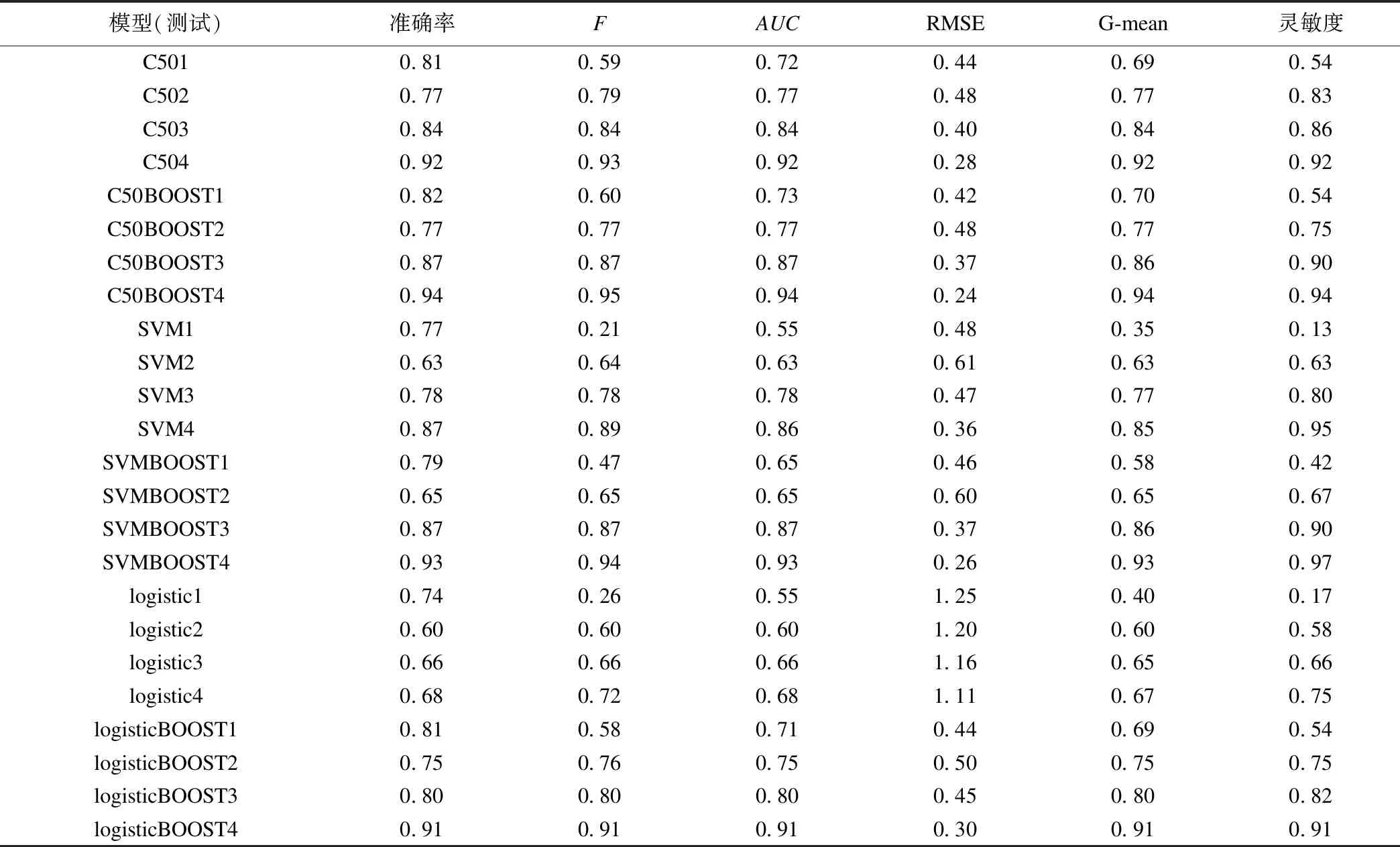
表3 测试集验证模型评价
测试模型中,C5.0BOOST4模型(准确率=0.94,F值=0.95,AUC=0.94,RMSE=0.24,G-mean=0.94,)及SVMBOOST4模型(准确率=0.93,F值=0.94,AUC=0.93,RMSE=0.26,G-mean=0.94),两种模型表现较优。
现以AUC为例,对模型的整体效果进行评价。由图1可知集成模型较各自单个学习器性能好,同时经过重采样后的数据构建模型较未平衡的数据构建有较好的性能,其中SMOTE采样方法又优于过采样与欠采样的模型结果。由于本研究考虑患者的复发风险,故而复发病例为阳性组,进而采用灵敏度这一针对阳性组预测准确率的指标进一步对模型进行评估。意在观察该模型的针对训练集的记忆能力与针对测试集的预测能力,结果见图1。
由图2可知,所有模型中训练模型灵敏度均优于测试模型,平衡后数据所构建模型灵敏度均高于未平衡数据所建模型。通过平衡后数据中,采用SMOTE平衡后SVMBOOST模型对训练集的灵敏度为0.99,对测试集的灵敏度为是0.97,在两种情况下灵敏度均最优。
讨 论
1.DLBCL患者三年复发情况预测
经过logistic回归共有Ki-67、LDH、原发纵膈肿瘤及疾病等级四个因素进入模型。其中除原发纵膈肿瘤患者预后好于其他型DLBCL患者外,其余均为复发危险因素。Ki-67 抗原是Gerdes等[16]于1984 年发现的一种与细胞增殖相关的核抗原,因其可以反映肿瘤细胞增殖活性,而成为目前应用最广泛的细胞增殖标记物之一。当前国内外已有大量文献证明Ki-67高表达与DLBCL患者预后密切相关[17-19],目前该指标已是美国国立综合癌症网络(National Comprehensive Cancer Network,NCCN)指南的必测指标,但其在患者预后及指导治疗方面尚无明确作用。
LDH即乳酸脱氢酶,其与疾病等级、年龄、结外受累数目、体能指数共同构成重要的预后因素IPI指数[20],其中LDH升高、疾病等级增高都会使IPI增大,说明患者预后差,与本研究结果一致。
原发纵隔肿瘤(primary mediastinal large B-cell lymphoma,PMBL)由Lichtenstein等于1980年首次提出[21],是DLBCL中的一种特殊亚型,大量文献报道其预后好于DLBCL,初治缓解后2年复发率低于DLBCL,与本研究结果一致。但其复发后使用R-CHOP治疗效果差,再难缓解,已成为目前一大挑战[22-23]。

图1 训练与测试集AUC比较
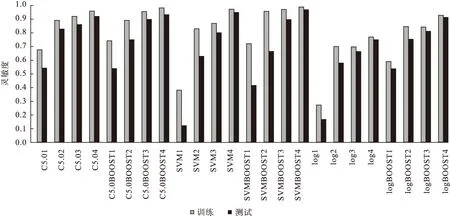
图2 训练与测试集灵敏度比较
本研究中对患者的复发情况进行预测时构建模型与logistic模型相仿,故提前设定患者复发时间为三年内。但是患者达到完全缓解到复发之间的时间也是可能影响患者复发的重要因素,目前已经有关于使用贝叶斯、决策树、SVM及神经网络模型构建Cox生存分析模型[27-28],目前Cox模型满足的比例风险假定对数据的要求过于严苛,机器学习对数据限制较少而被许多国内外学者应用于生存分析问题中[29],下一步我们计划就患者复发过程构建生存分析模型,从而进一步研究更为长期的患者情况。
2.模型分析
SMOTE采样后的数据构建模型性能好,与其采样原理密切相关,目前已有大量对SMOTE采样进行改良的方法,其中大多是应用混合采样的原理,有待进一步进行模型性能比较。
本研究中将灵敏度作为模型重要评价指标,利用重采样平衡后数据构建模型性能好于未平衡数据,有效地解决了因复发病例少,特征较多,灵敏度无法提高的问题。
boosting集成模型好于其对应的单个学习器,因其是由多个弱学习器投票产生的强学习器,其他提高学习器性能的方法包括bagging集成、代价敏感等学习方法,Qi Wang等在2017年[26]用经过SMOTE采样数据构建SVM bagging集成模型的性能优于随机欠采样与随机过采样等方法,灵敏度为87.1%,与本研究结果一致。但SMOTE模型的其他性能不如其基于边界信息SMOTE采样得到的模型,故可进一步进行采样方法比较。本研究表明单模型与集成模型中SVM模型具有稳健性,灵敏度高,泛化能力强的特性,相比于Yuan Sui等在2014年的研究[24]中同样采用SMOTE平衡后的数据构建的SVM模型的准确率为92.2%,好于本研究的结果;而本研究结果优于胡明伟等在2017年[25]构建的准确率为82.4%,灵敏度为77.2%的SVM模型。目前已有大量对SVM的改良模型,下一步计划对此类模型进行比较,从而使预测准确率、模型灵敏度进一步提高。
