支持向量机和人工神经网络在冠状动脉旁路移植术后晚期静脉移植血管病患病风险预测中的应用*
2019-09-17凤思苑巩晓文李长平刘媛媛
凤思苑 巩晓文 崔 壮△ 高 静 李长平 刘媛媛 刘 寅 马 骏
【提 要】 目的 探讨支持向量机和人工神经网络在预测个体冠状动脉旁路移植术后晚期静脉移植血管病患病风险中的应用。方法 选取2015年3月-2017年12月天津市胸科医院CABG术后超过一年的冠状动脉粥样硬化性心脏病患者,分别应用径向基SVM、多项式SVM和BP神经网络建立晚期SVGD预测模型。通过受试者工作特征曲线下面积、精确率、召回率及F1指标评价模型的预测性能。结果 BP神经网络在测试集中反映模型精确率和召回率的F1值为0.84,而ROC曲线下面积均值为0.773,大于其他两种SVM预测模型。结论 BP神经网络对晚期SVGD的预测表现更佳,有助于临床的辅助诊断。
冠状动脉粥样硬化性心脏病(coronary atherosclerotic heart disease,CHD)是严重威胁人类健康的最常见的心脏病之一。根据《中国卫生和计划生育统计年鉴(2016)》,2015年中国城市和农村居民冠心病死亡率分别为110.91/10万和110.67/10万,自2012年一直呈上升趋势[1]。冠状动脉旁路移植术(coronary artery bypass grafting,CABG)是目前治疗CHD最有效方法之一,其中静脉移植血管(saphenous vein graft,SVG)作为CABG术中常用的桥血管材料,其血管术后1年内通畅率为89%,10年后血管通畅率下降到61%[2]。CABG术后静脉移植血管病变会降低血管通畅率,引起患者缺血症状的复发,即静脉移植血管病(saphenous vein graft disease,SVGD)[3]。它直接影响了CABG术后患者的远期预后及生活质量。因此,建立SVGD患病风险的预测模型,在确定高危人群的范围,做好针对性的预防措施,减缓SVGD的发生、降低CHD患者再行相关手术风险等方面显得尤为重要。
目前的研究多为SVGD相关危险因素的研究,对于发病率高的晚期SVGD研究甚少,缺少晚期SVGD的风险预测模型[4-5]。本文主要运用数据挖掘技术中表现良好的支持向量机(support vector machines,SVM)和人工神经网络(artificial neural networks,ANN)建立不同的预测模型,通过对影响模型性能的重要参数进行优化调整,选择适合晚期SVGD患病风险预测的最佳模型,从而更好的预防晚期SVGD的发生发展。
对象和方法
1.研究对象
选取2015年3月-2017年12月在天津市胸科医院就诊的CABG术后超过1年的CHD患者506人。纳入标准:CABG术后出现缺血症状而入院检查的患者;冠状动脉及移植桥血管造影显示至少含1支SVG桥血管狭窄≥50%;SVG桥龄≥1年;所有研究指标均无缺失值。排除标准:外吻合口部狭窄;严重瓣膜疾病;失代偿性心力衰竭;恶性肿瘤或血液系统疾病;急慢性肺部疾病;甲状腺功能异常;严重肝肾功能不全;免疫系统疾病。最终入选患者506例,根据冠状动脉造影结果,将患者分为SVGD组346例和非SVGD组160例。
2.研究方法
(1)资料收集 临床基线资料,包括:性别、年龄、收缩压、舒张压、吸烟史、饮酒史、高血压史、糖尿病病史、高脂血症病史、脑卒中病史和心血管疾病家族史等。收集患者入院时实验室检验指标、基本生化化验指标、血常规化验指标、既往行CABG术基本情况及冠脉造影复查结果。
(2)统计学分析 本研究采用5折交叉验证的方法将506样本集随机分成5个正负比例相同的互斥子集:依次取出1个子集作为测试集,其余4个子集组合为训练集。训练集样本用于建立模型,测试集样本用于评估模型的预测效果。每个模型每次模拟都会得出相应的评估指标,通过循环模拟5次,将5次结果的平均值作为对该模型效果的估计。建模的基本过程如下:①利用非条件logistic回归单因素分析筛选有统计学意义的变量纳入模型,检验水准α=0.05;②利用R软件中“e1071”包建立SVM模型(选择径向基核函数和多项式核函数);③利用R软件中的“nnet”包建立ANN模型(选择误差反向传播网络,简称BP神经网络);④利用ROC曲线下面积、精确率、召回率及F1指标对三个模型的性能进行评估和比较。所有统计分析由SPSS 20.0、R 3.4.2完成。
结 果
1.基本情况
本次研究共纳入CABG术后超过1年的CHD患者506人,其中男性369人,女性137人,平均年龄为(64.84±7.95)岁。
2.非条件logistic单因素分析
以是否是SVGD为因变量对采集到的信息分别进行单因素分析,结果显示桥龄、原位靶血管病变支数、冠心病类型、左室射血分数(LVEF)、左室舒张末期内径(LVDED)、α-羟丁酸脱氢酶(α-HBDH)、极低密度脂蛋白(VLDL)、脂蛋白a(LP(a))和同型半胱氨酸(Hcy)差异有统计学意义,见表1。
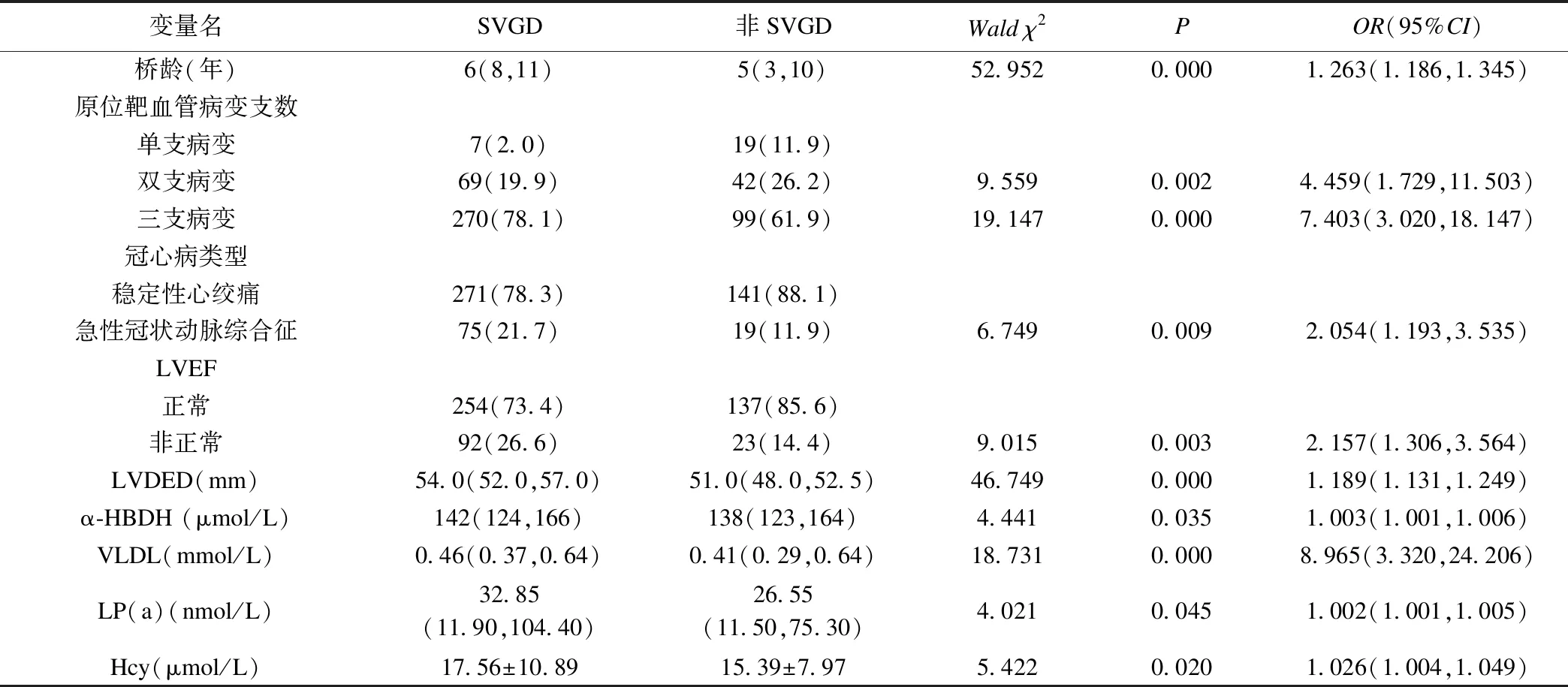
表1 单因素logistic分析结果

3.SVM模型及分析结果
本文SVM模型分别选用处理非线性数据的径向基(RBF)核函数和多项式(Poly)核函数来构建。五次模拟都是通过十折交叉验证误差最小的标准来获取核函数的最优参数[6-7]。两个模型所选预测变量的相对重要性排序如图1和图2。
4.BP神经网络及分析结果
ANN模型采用最常用的BP神经网络来建模分析。其输入层节点数为9,输出层节点数为1,隐藏层为一层,五次模拟的隐藏层节点数分别为2、1、1、1、2。BP神经网络所选预测变量的相对重要性排序如图3。
5.模型的性能度量
模型的性能度量就是对分类器的泛化能力进行比较,可选的评估指标有很多。考虑到患病风险的预测模型更多的是看重疾病的查准率和查全率,除了常见的ROC曲线下面积的比较,还使用了基于精确率(precision)和召回率(recall)调和平均的F1指标来评价[8]。经过交叉验证后的多项式SVM在训练集和测试集的ROC曲线下面积均值分别为0.931和0.726,径向基SVM在训练集和测试集的ROC曲线下面积均值分别为0.791和0.768,BP神经网络在训练集和测试集的ROC曲线下面积均值分别为0.791和0.773。三种模型详细的评估指标参数见表2。
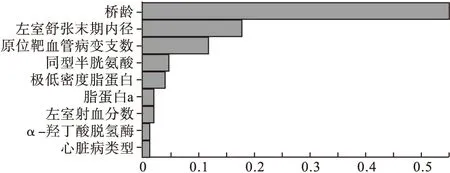
图1 径向基SVM变量相对重要性排序

图2 多项式SVM变量相对重要性排序
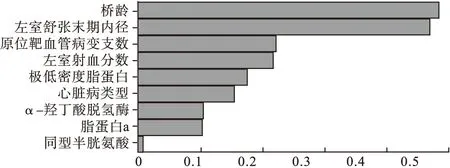
图3 BP神经网络变量相对重要性排序
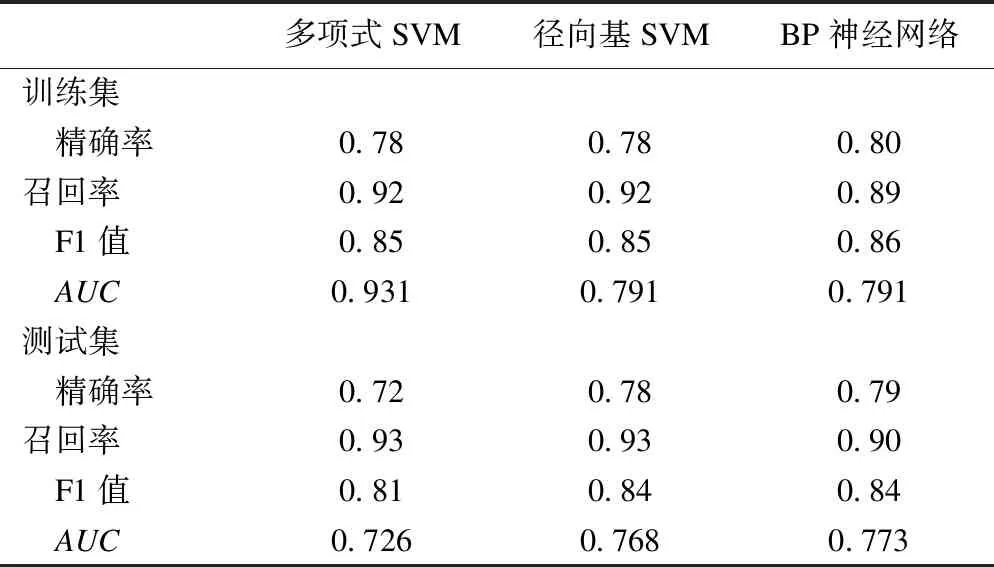
多项式SVM径向基SVMBP神经网络训练集 精确率0.780.780.80召回率0.920.920.89 F1值0.850.850.86 AUC0.9310.7910.791测试集 精确率0.720.780.79召回率0.930.930.90 F1值0.810.840.84 AUC0.7260.7680.773
讨 论
基于所研究数据非线性的特点,本研究采用SVM和ANN应用于CABG术后晚期静脉移植血管病患病风险,得到了三个预测模型及其所选预测变量的相对重要性排序,并利用多项指标对模型的泛化能力进行评估和比较。研究发现虽然每个模型所选预测变量的相对重要性排序不一致,但是影响模型预测性能排在前三位的变量均是桥龄、LVDED和原位靶血管病变支数,说明上述三个指标是影响晚期SVGD发生的主要因素。既往研究发现静脉移植血管远期再狭窄和闭塞的机制主要是血管的粥样硬化[9]。长期的血管内膜损失,使静脉移植血管发生纤维性弥漫粥样斑块病变,继而会形成弥散、向心、少钙及缺少纤维帽的斑块。最终,斑块破裂导致静脉移植血管的狭窄和栓塞。综合分析发现桥龄长的患者发生晚期SVGD可能性较高,原因可能与其静脉桥血管发生粥样硬化可能性较高有关,国外的很多研究也发现桥龄是静脉桥狭窄的危险因素[10-12]。此外,研究还发现原位靶血管病变支数和LVDED与晚期SVGD的发生密切相关。
对于数据线性不可分情况,SVM的主要思想是利用核函数将输入向量映射到一个高维的特征向量空间,并在该特征空间中构造最优分类面[13]。本研究选用的径向基核函数和多项式核函数分别是局部性核函数和全局性核函数的典型代表。在核函数参数选择上,选用网格搜索法来遍历搜索范围内所有的参数组合,虽然预测速度相对较慢,但可以保证搜索到最优参数[14-15]。分析结果显示,径向基SVM在测试集的ROC曲线下面积和F1值都高于多项式SVM,说明径向基SVM较多项式SVM更适合晚期SVGD的风险预测,这可能与径向基核函数有较好的学习能力有关。多项式SVM在训练集的ROC曲线下面积为0.931,但是在测试集的表现较差,提示多项式SVM在训练模型时可能存在过拟合的现象,模型的泛化能力较差。
BP神经网络是一种具有自学习、自适应和很强的非线性映射能力的多层前馈神经网络,由输入层、隐藏层和输出层组成。由于隐藏层的节点数,尚无理论指导,本研究五次模拟的隐藏层节点数都是通过测试集ROC曲线下面积最大的标准反复试验确定。分析的结果显示,BP神经网络在测试集的ROC曲线下面积略高于径向基SVM,但在F1指标方面相同,表明BP神经网络是本研究中最佳的预测模型。
目前冠状动脉造影是诊断SVGD的金标准,但其检测费用相对较高。本研究通过入选患者既往基线资料和临床检查指标建立BP神经网络模型对SVGD患病风险进行预测,具有较高的查准率和查全率,对辅助诊断起到一定的帮助作用。在建模方面采用了交叉验证的方法,可以从有限的数据中尽可能挖掘多的信息,避免结果出现局部的极值,提高了模型的稳定性[16]。
本研究仍存在一些不足之处。首先,利用单因素logistic回归,按0.05的水准从候选变量中筛选分类能力较强的变量作为模型预测因子,以提高建模的效率和预测性能,但受样本含量和入选患者的代表性所限,结果可能会丢失一些与SVGD发病有关的潜在因素。其次,本研究采用了内部验证的方法避免过拟合,但仍缺乏外部数据的验证。因此,还应在后续研究中增大样本量,纳入更多地区的患者,进一步调整优化模型,并对模型的预测性能、泛化能力和稳定性进行更加客观准确的评价。
