面向移动端的轻量化卷积神经网络结构
2019-09-17毕鹏程罗健欣陈卫卫邓益侬
毕鹏程,罗健欣,陈卫卫,邓益侬,刘 祯
(中国人民解放军陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引言
自AlexNet[1]赢得ILSVRC2012[2]挑战赛以来,各种新型网络结构层出不穷,一次次刷新ImageNet分类的准确率。这些结构包括VGGNet[3]、GoogLeNet[4]、ResNet[5]、DenseNet[6]、SE-Net[7]和神经网络架构自动搜索[8],以上卷积神经网络发展的总体趋势是使用更深层更复杂的网络来实现更高的准确度。但是准确度的提高并不一定会使网络在模型尺寸和运行速度方面更有优势。就模型尺寸而言,深层复杂的卷积神经网络拥有大量参数,保存这些参数对设备内存要求很高。运行速度方面,大量实际应用均要求实时性,往往是毫秒级别,这对设备的计算能力要求很高。当前,移动和嵌入式设备大量普及,这些设备的计算资源和存储资源往往十分有限。因此只有在准确度、尺寸和速度方面取得很好的权衡,即在有限计算力之下实现最优的精度,才能将卷积神经网络更好地应用于移动端。
本文提出了一种轻量化的高效卷积神经网络结构S-MobileNet,其可以方便地部署在移动平台上。该网络结构是基于神经网络轻量化领域的先进结构MobileNetV2[9]改进而来的,旨在保证同等准确度水平的前提下进一步减少模型参数量和降低计算复杂度。
1 相关工作
近几年,调整深度神经网络结构以在准确度、尺寸和速度之间实现最佳平衡已经成为一个很受关注的研究领域。这一研究领域的目标是确定一个模型,该模型参数量很少,预测速度很快,同时能保持准确度。
为了解决这个问题,可行的做法是对现有的卷积神经网络模型进行压缩,使得网络拥有更少的参数,同时能降低模型的计算复杂度。这些压缩算法大致可以分为四类[10]:参数修剪和共享、低秩分解、迁移/压缩卷积滤波器和知识蒸馏。基于参数修剪和共享的方法关注于探索模型参数中冗余的部分,并尝试去除冗余和不重要的参数。基于低秩分解技术的方法使用矩阵/张量分解估计深层卷积神经网络中最具信息量的参数。基于迁移/压缩卷积滤波器的方法设计了特殊结构的卷积滤波器以减少存储和计算复杂度。而知识蒸馏则学习了一个精炼模型,即训练一个更加紧凑的神经网络以再现大型网络的输出结果。
除了对现有的网络模型进行压缩,还可以重新设计新的网络结构,使得参数量少、速度快的同时,依然保持较高的准确度,即轻量化网络模型设计。近年来,众多轻量化网络结构纷纷被提出,如SqueezeNet[11]、MobileNetV1[12]、MobileNetV2、ShuffleNetV1[13]和ShuffleNetV2[14]等。在这些网络结构中,MobileNetV2和ShuffleNetV2实现了最先进的性能。MobileNetV2利用深度可分离卷积、线性瓶颈和反向残差结构在兼顾参数量和计算复杂度的同时实现了较高的准确度。而ShuffleNetV2采用通道混洗的方法混合通道间的特征信息,与采用逐点卷积方法来混合通道之间特征信息的MobileNetV2相比,少了大量的参数数量和计算复杂度,因此在保证准确度的同时在模型运行速度方面取得了不错的效果。
2 S-MobileNet结构
总的来说,S-MobileNet是采用通道混洗方法改进MobileNetV2的基本构建模块后得到的网络结构。受益于这种方法,S-MobileNet可以在保证准确度的同时获得较小的模型尺寸和较低的计算复杂度。
2.1 回顾MobileNetV2
MobileNetV2的基本构建模块使用了三个关键结构,即深度可分离卷积、反向残差和线性瓶颈结构。
深度可分离卷积对于许多高效的神经网络结构来说都是非常关键的组件[12]。基本思路是将一个标准卷积分解成两步来实现,第一步是深度卷积,即对每个输入通道用单个卷积核进行卷积运算;第二步是一个1×1卷积,即逐点卷积,负责通过计算输入通道间的线性组合来构建新的特征。如图1所示,(a)表示一组空间尺寸为K×K的标准卷积核,卷积核通道数为N,数量为M;(b)表示标准卷积分解成的一组深度可分离卷积,包含一组空间尺寸为K×K的深度卷积核和一组空间尺寸为1×1的逐点卷积核。
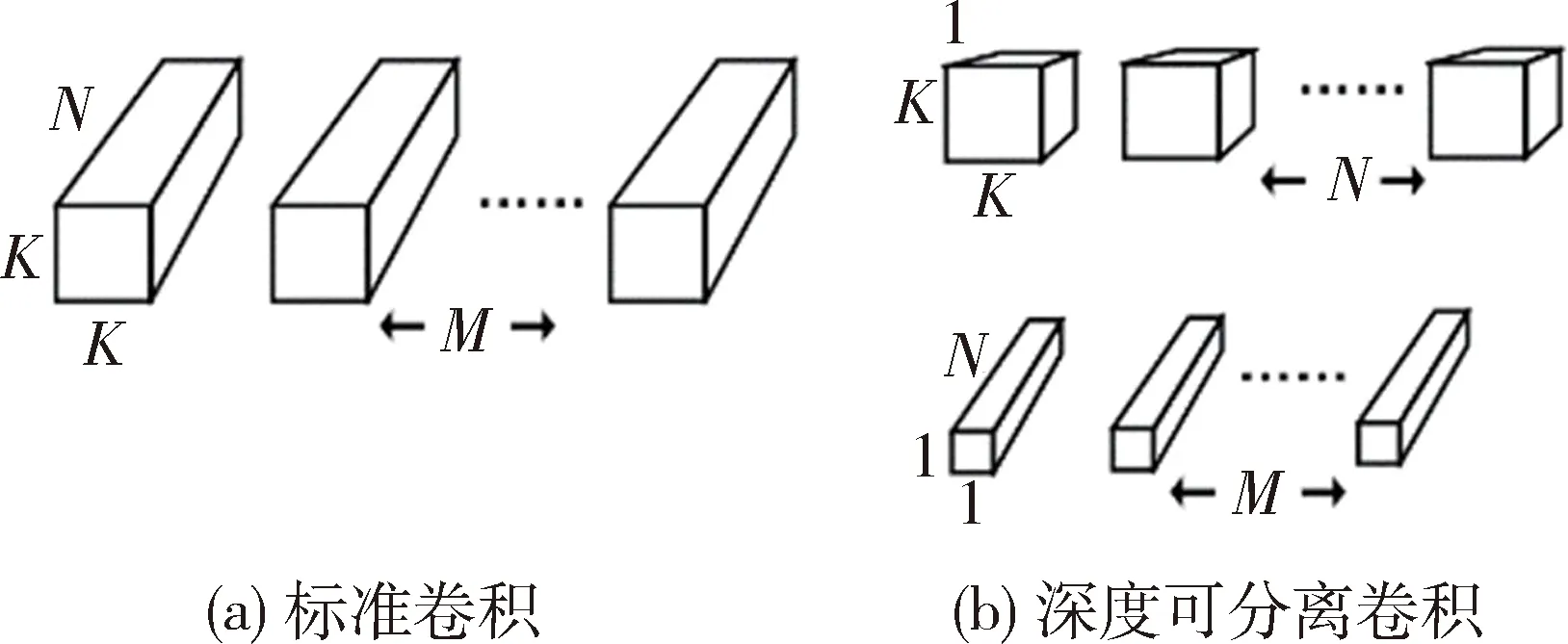
图1 标准卷积结构和深度可分离卷积结构
此时,假设输入特征为RH×W×N,输出特征为RH×W×M,则标准卷积层的计算复杂度为HWNMK2,参数量为NMK2。深度可分离卷积包含一组RK×K×1×N深度卷积核和一组R1×1×N×M逐点卷积核,则深度可分离卷积的计算复杂度为HWNK2+HWNM,是标准卷积的1/M+1/K2,因为网络结构中M≫K2,MobileNetV2使用K=3,即深度可分离卷积计算复杂度降低了标准卷积的8~9倍。同理,深度可分离卷积层的参数量减少了标准卷积层的8~9倍。
残差网络使信息更容易在各层之间流动,包括在前向传播时提供特征重用,在反向传播时缓解梯度消失,梯度更容易流动到浅层网络中去,解决了网络退化问题,即随着层数的增加,训练集上的准确度饱和甚至下降的问题。这样能够通过单纯地增加网络深度来提高网络准确度。传统的残差结构特征通道维度先缩减后扩展,如图2(a)所示,而MobileNetV2中的反向残差结构shortcut连接的是瓶颈层,特征通道维度先扩展后缩减[9],如图2(b)所示。这样做是因为传统残差结构中间的3×3标准卷积计算量太大,先用一个1×1卷积来降低通道维度,目的是减小计算量,而MobileNetV2使用深度卷积替换了3×3标准卷积,虽然极大地减少了计算量和参数量,但提取的特征也会相对减少,如果再进行压缩,能提取的特征将更少,影响模型的准确度。因此为了在准确度、参数量和计算量之间取得更好的平衡,采用反向残差结构,先对通道进行扩展,深度卷积能提取更多特征,保证模型准确度。
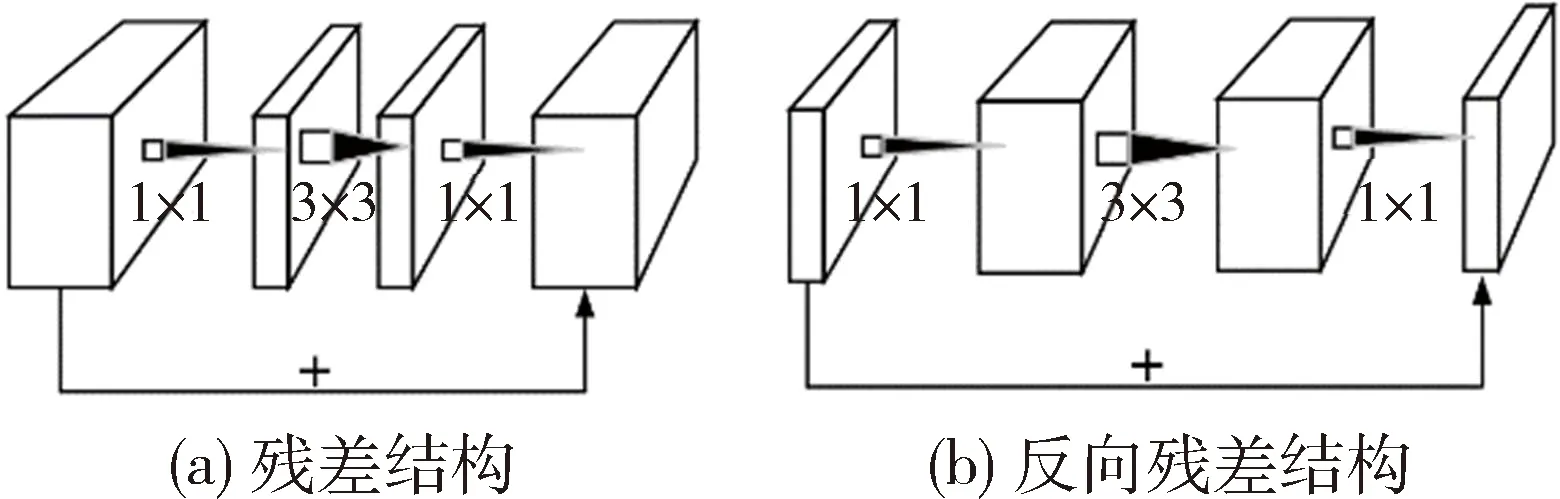
图2 残差结构和反向残差结构
线性瓶颈就是去掉了低维度输出层后面的非线性激活层,目的也是为了保证模型的准确度[9]。图3(a)、(b)为MobileNetV2基本构建模块,(a)为卷积步长为1的构建模块,(b)为空间下采样构建模块。去除了低维度1×1卷积层后的非线性激活函数ReLU6变为线性输出。这样做主要是因为通过低维度输出层之后,特征信息更集中在缩减后的通道中,此时加上一个非线性激活函数,比如ReLU6,ReLU6会使负值输入的输出为0,这样就会有较大的信息丢失,影响准确度。为了减少信息丢失,在通道维度缩减的那一层,即瓶颈层的输出不接非线性激活函数,所以是线性瓶颈。
2.2 网络结构设计
如上所述,MobileNetV2使用的这些方法对于其保证准确度、减少参数量和降低计算复杂度至关重要,因此在S-MobileNet网络结构中依然沿用这三种方法。与此同时,采用深度可分离卷积虽然极大地降低了计算复杂度,减少了参数量,但因为MobileNetV2网络结构在每个构建模块中都引入了扩展因子,这样1×1卷积所占的参数量和计算量依然较高,而1×1卷积的作用在于混合通道间的特征信息。
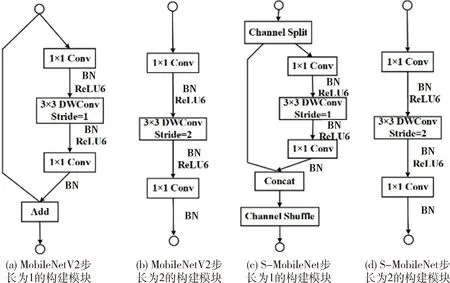
图3 MobileNetV2和S-MobileNet的构建模块
此时想到,ShuffleNet[13]提出的通道混洗方法能很好地解决分组卷积之后分组间“信息流通不畅”的问题,即分组间的特征信息没有得到混合的问题,此问题会影响模型的准确度。图4(a)表示分组卷积之后没有进行通道混洗,(b)表示分组卷积之后进行了通道混洗,(c)操作同(b),混洗操作是均匀打乱而不是随机打乱顺序。而MobileNetV2构建模块中采用的深度卷积是分组卷积的特殊形式,即分组数与通道数相等的分组卷积。
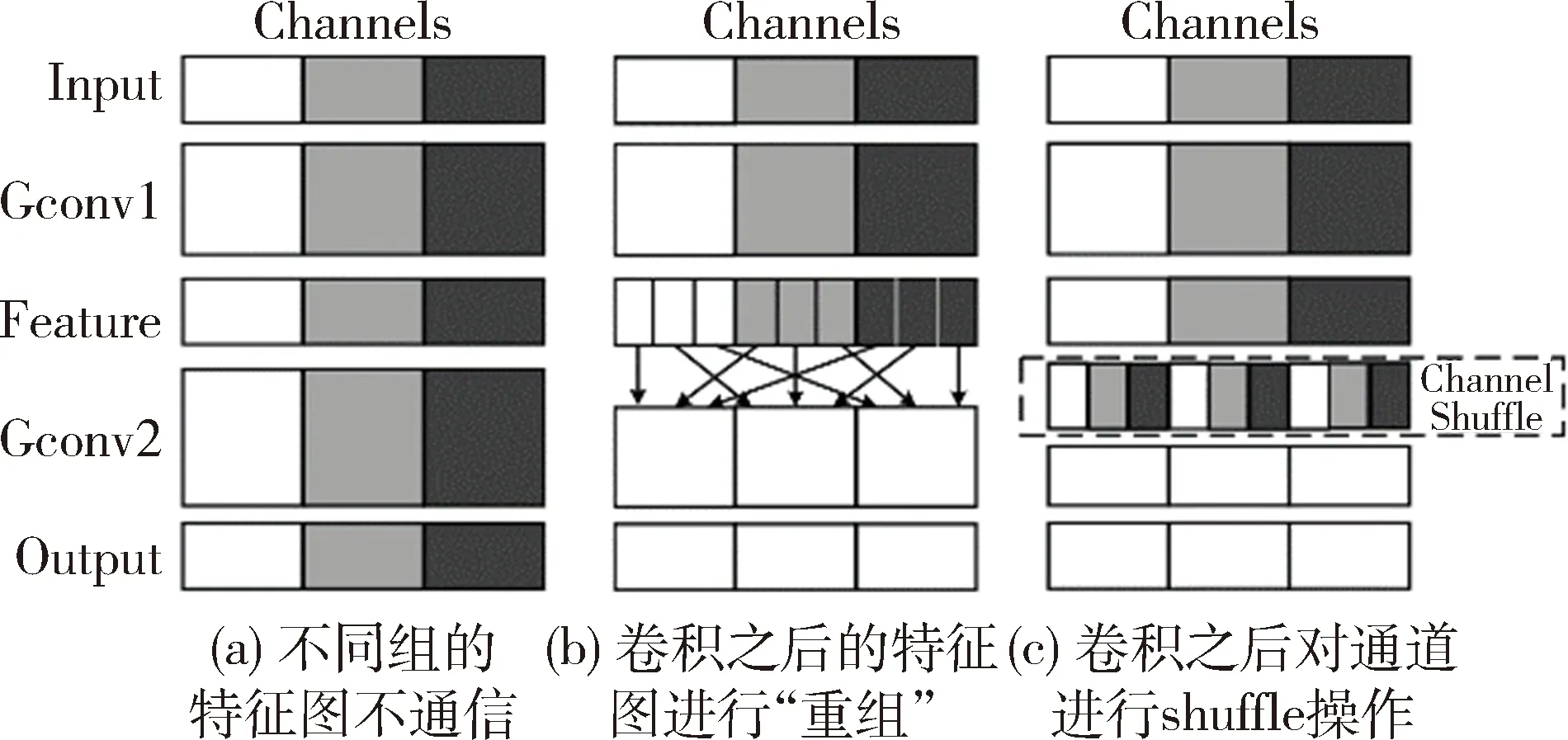
图4 通道混洗
因此,本文采用通道混洗替代一部分1×1卷积的方法来改进MobileNetV2的瓶颈模块,形成S-MobileNet的基本模块。如图3(c)、(d)所示,改进包含shortcut连接的瓶颈块,即卷积步长为1并且输入输出特征通道数相等的瓶颈块。在此类瓶颈块开始,c个特征通道的输入被分为两支,分别带有c-c′和c′个通道。一个分支不进行任何操作,另一个分支与原瓶颈块结构一致,即先用1×1卷积提升通道数,再用深度卷积提取特征,然后用1×1卷积降低通道数,并去除低维度输出层后的ReLU6函数。卷积之后,把两个分支拼接起来,从而输出通道数与输入相等。然后进行与ShuffleNetV2相同的通道混洗操作来保证两个分支间能进行信息交流。之后,下一个瓶颈块开始运算。注意,MobileNetV2中的加法操作不再存在,这样做的目的是为了减少元素级别操作,从而减少模型运算时间,提升速度[14]。采用这种通道分割的方法,每个瓶颈块只有c′个通道特征需要进行卷积运算,相比于原网络c个通道特征均进行卷积运算,极大地降低了计算复杂度,减少了参数量。
空间下采样瓶颈块没有shortcut连接,因此不引入通道分割和通道混洗方法,与原网络结构保持不变。同样地,卷积步长为1但输入输出通道数不相等的瓶颈块也没有shortcut连接,因此也保持不变。构建模块卷积部分的具体实现与MobileNetV2保持一致,如表1所示,对于一个分辨率为H×W的输入特征,扩展因子为t,深度卷积核空间尺寸为3,卷积步长为s,卷积部分输入通道数为N,输出通道数为M,则计算复杂度是HWNt(N+9/s2+M/s2),参数量为Nt(N+9+M)。

表1 S-MobileNet构建模块卷积部分的实现
上述构建模块被重复堆叠以构建整个网络,为简单起见,本文采用与ShuffleNetV2一样的做法,令c′=c/2,整体网络结构与MobileNetV2保持一致,如表2所示。表2每行描述了1个或多个相同层的序列,重复n次。所有序列相同的层有相同的输出通道数c,序列第一层的步长为s,其他层步长为1。所有空间卷积核尺寸使用3×3的大小。扩展因子t总是应用在表1描述的输入中。

表2 S-MobileNet整体网络结构
S-MobileNet参数量减少、速度提升的同时还能保持准确度的原因主要是采用了通道分割的方法。在每个块中,一半的特征通道(当c′=c/2时)直接通过块并加入下一个瓶颈块,这可以被视为一种特征重用,在ShuffleNetV2中已经被证明这种重用模式与DenseNet[6]的特征重用模式是一致的,都有利于提高模型的准确度[14]。
3 实验结果与分析
在CIFAR-10、CIFAR-100和ImageNet三种图像分类数据集上对本文提出的S-MobileNet进行了实验评测。实验结果表明本文提出的卷积网络结构比MobileNetV2的网络模型参数量减少了近1/3,计算复杂度降低了近40%,同时保持了同等水平的模型准确度。除了实现S-MobileNet之外,本文还在这三种图像分类数据集上实现了MobileNetV2作为实验对比。在这三组实验中,除了网络结构不同外,其他实验设置如数据处理方法、初始化方法、批大小、训练轮次等均保持一致。
3.1 CIFAR-10数据集
CIFAR-10[15]数据集是一个由50 000张训练图像和10 000张测试图像组成的彩色图像分类数据集。图像大小为32×32,包含10个不同的物体类别。在实验中,通过随机水平翻转图像来对训练数据进行扩增处理。本文提出的网络结构在CIFAR-10数据集上的实验结果及对比如表3所示。在准确度方面,S-MobileNet在TOP-1精度方面与MobileNetV2保持相当,在TOP-5精度上甚至要高于MobileNetV2。与此同时,参数量和计算复杂度较MobileNetV2降低了35%和38%。

表3 两个网络在CIFAR-10上的表现对比
3.2 CIFAR-100数据集
CIFAR-100[15]数据集和CIFAR-10数据集的组成方式基本一致。区别在于CIFAR-100数据集中具有100类不同的图像,每种类别的图像数量少于CIFAR-10数据集,只有CIFAR-10数据集中的1/10,因此区分难度较大,测试准确度比CIFAR-10数据集低。本文提出的网络结构在CIFAR-100数据集上的实验结果及对比如表4所示。在准确度方面,S-MobileNet与MobileNetV2保持相当水平,与此同时,参数量和计算复杂度较MobileNetV2降低了34%和37%。

表4 两个网络在CIFAR-100上的表现对比
3.3 ImageNet数据集
ImageNet数据集是一个由1 281 670张训练图像和50 000张测试图像组成的彩色图像分类数据集。图像大小为224×224,包含1 000个不同的物体类别。实验结果及与MobileNetV2网络模型的对比如表5所示。在准确度方面,S-MobileNet与MobileNetV2保持相当水平,但参数量和计算复杂度较MobileNetV2降低了23%和38%。

表5 两个网络在ImageNet上的表现对比
4 结论
本文提出了一种轻量化的高效卷积神经网络结构S-MobileNet。与神经网络轻量化领域的先进结构MobileNetV2相比,S-MobileNet在保持同等准确度水平的前提下,模型参数量减少了近1/3,模型计算复杂度降低了近40%。本文提出的S-MobileNet是一种能够方便地迁移到各移动平台上的通用卷积神经网络结构,可以应用到多种任务中,如物体检测、语义分割、人脸识别等。由于时间和实验条件有限,本文只在图像分类任务中对S-MobileNet的有效性进行了验证。分类任务的实验结果表明,S-MobileNet确实是一种高效的神经网络结构。在以后的工作中,笔者会进一步研究S-MobileNet在计算机视觉其他方面的表现,如物体检测及语义分割等,以探究S-MobileNet的高效性和通用性。
