一种协作式异常流量检测模型
2019-09-17董理
董 理
(北京邮电大学 信息与通信工程学院,北京 100876)
0 引言
随着网络、存储、计算和传输的不断完善,互联网与人们的互动越来越紧密。虽然互联网使人们的生活更加方便,但它也带来了一些潜在的风险。例如,涉及用户隐私和安全的恶意攻击越来越频繁。
人们对互联网的使用方式的改变,对传统的异常网络事件检测技术提出了新的挑战。研究人员更难意识到一些新的攻击。针对这些问题,提出了一些异常网络流量检测方法。传统的异常流量检测方法可分为两类[1-2]:一种是误用检测,另一种是异常检测。这两种方法各有利弊。误用检测具有很高的准确性,但需要已知知识[3]的支持。异常检测不需要已知的知识,但不能对攻击类型进行分类,准确性也较低。例如,OM H[4]设计了一个混合检测系统,它是一个考虑K-means、K-最近邻和朴素贝叶斯方法的混合异常检测系统。
然而,网络流量的爆炸性增长直接或间接地推动互联网进入大数据时代,由于计算量大,大数据[5-7]导致网络数据分布不断变化,使得异常流量检测更难处理。由于网络数据生成的速度很快,使得正常流量和异常流量相差很大,数据的分布也发生了变化。此外,随着大数据量的增加,正常流量和异常流量之间的差异也在增大。这使得传统的方法无法有效地检测异常流量。
因此,为了提高异常流量的准确度,避免误报检测带来的松散性,提出了一种基于大数据分析的新模型,可以避免网络流量分布调整带来的影响,提高检测精度,降低误报率。该模型的核心不是简单地结合传统的检测方法,而是基于大数据的新型检测模型。在仿真中,使用K-means、决策树和随机森林算法作为比较对象来验证模型的有效性。仿真结果表明,该模型具有较好的检测性能,正常数据检测率为95.4%,DoS攻击检测率为98.6%,探针攻击检测率为93.9%,U2R攻击检测率为56.1%,R2L攻击检测率为77.2%。
1 K-means算法
K-means算法是一种常用的聚类算法[8-9],它使用简单的迭代算法将数据集聚类成一定数量的类别,通常将聚类数注释为K,K-means的四个步骤是:
(1)初始化:从数据集中随机选择K个数据点作为K簇的中心。
(2)分布:将数据集内的每个点分配到最近的中心。
(3)更新:根据集群分配计算新中心,新中心是集群中所有点的平均点。
(4)重复:重复这些步骤,直到在这一轮中没有更新中心,并且集群已经聚合。
K表示需要指定分类K的数量。如果K选择不当,将导致不恰当的分类结果。因此,选择合适的聚类数对K-means的计算结果至关重要。
K-means的另一个缺点是,K-means只能使用欧几里得距离。虽然欧几里得距离便于计算,但它不能考虑两个特征之间的差异,这意味着它对待所有特征都是一样的。在现实中,有时会导致表现不佳。
总而言之,K-means方法在处理大数据方面有其优点和缺点:K-means方法简单,时间复杂度低,即n(nd*k+1logn)。
1.1 决策树算法
决策树[10-11]是机器学习中常用的算法,完整的决策树由三种元素组成:
(1)决策节点:指明被用于分割的特征。
(2)机会节点:表示每个特征的可能值。
(3)叶子结点:记录实际的类别。
决策树算法主要可分为两个步骤:
(1)树生成:根据训练集生成树。需要确定分割中需要使用哪个特性,并确定结果属于哪个类别。
(2)分类:从决策树的根目录对新记录进行分类,并将其与每个决策节点进行比较,并将结果移动到相应的分支。重复此过程,当数据到达叶节点后,叶节点的类别是该节点的新类别。
1.2 随机森林
随机森林算法[12-13]是一种分类算法,包含多个决策树,其中每棵树都有一个投票权,最终结果是投票权最高的树。
在生成决策树时,可以使用特征选择和修剪来避免过度拟合。但是,当特性的数量很大时,问题就很难避免了。而随机森林由多个决策树组成,可以有效地避免这些问题。
2 系统模型
受异常流量影响,网络流量数据分布会发生改变。如何在大量的网络数据中精确地识别出异常流量,是本文主要研究的问题。
本文提出了一种基于大数据分析的异常流量检测模型。通过并行运行正常流量分类器和异常流量分类器,并将待识别的流量数据输入这两个分类器,再将分类的输出结果输入到表决器,最后依据表决规则输出该流量数据的识别结果。
2.1 正常流量分类模型
正常流量分类模型使用分类和聚类算法来区分正常和异常流量,而不是涉及特定的异常行为。该模型包括以下两个阶段。
(1)训练阶段:训练模型使用标记为正常或异常的数据,训练之后的模型应用于测试阶段。
(2)测试阶段:测试阶段与实际检测阶段相似。该模型使用未标记的数据,将流量数据分类为正常或异常数据,并对其进行标记。
正常流量选择模型一般采用K均值聚类算法、KNN、决策树和随机森林分类算法。传统上,在使用K-means算法之前,设置类的数量非常重要,因为通常有多少类别是未知的。但是,为了区分正常和异常行为,正常流量分类模型采用K-means算法,如下所示。
(1)在训练阶段,利用标记信息将数据分为正常和异常。
(2)对这两个类别分别使用K-means算法,而不是同时对所有数据进行聚类,分别得到数据集的中心。
(3)利用数据集的中心和KNN聚类算法对测试数据进行分类。
2.2 异常流量分类模型
异常流量分类模型的目的是避免正常交通量过多,正常流量与异常流量分布严重不均而影响分类准确度。该模型将异常流量分为特定类别,并包括以下两个阶段。
(1)训练阶段:只使用异常数据来培训分类模型,以及每个数据标签特定的攻击组。使用分类算法学习分类规则。
(2)测试阶段:测试阶段类似于实际的检测过程,使用未标记的数据(包括正常行为数据)。分类模型根据分类规则将异常流量分类为特定的类别,并对每一个数据给出特定的标签。
异常流量分类模型采用决策树和随机森林分类算法。异常流量分类模型和正常流量分类模型是相互独立的,在训练阶段或测试阶段没有先后顺序之分。
2.3 表决器
表决器的作用在于利用合适的规则对正常流量分类器和异常流量分类器的结果进行调整,以提高对异常流量的识别率。
针对现有异常流量分类误报率高的问题,本文设计了一种利用正常流量分类结果修正异常流量分类结果的规则:
cn表示正常流量分类模型的测试结果,ca表示异常流量分类模型的测试结果,Ai表示第i个异常类。异常流量检测模型如图1所示。
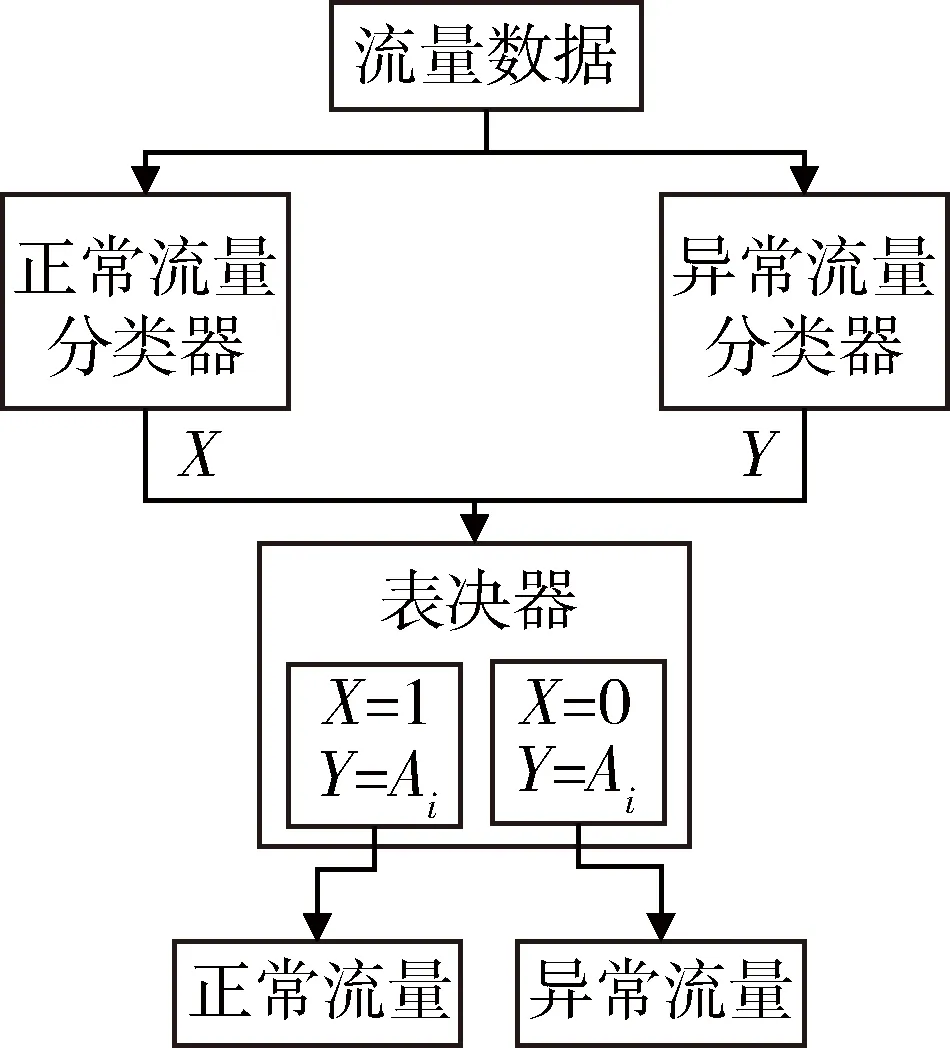
图1 异常流量检测模型
3 实验仿真
在使用基于大数据分析的异常检测模型检测三个子模型之前,需要对数据集进行训练模型的标签预处理。需要指出的是,正确选择特征是减小尺寸、提高运行效率的好方法。在仿真中,采用了三种不同的算法来验证模型的有效性。
3.1 数据集
本文采用KDDCUP99数据集来测试验证所提出的模型。KDDCUP99数据集是测试异常检测模型的广泛应用,它是由KDDCUP99获取和处理的。KDDCUP99数据集共有41个特征,分为三组:基本特征、内容特征和时间特征。
3.2 仿真结果
如表1、表2所示,设计了12组对比实验,每组实验都进行了大量重复实验,取平均值为最后结果。分别使用K-means(其中K-means1的正常类中心点为4,异常类中心点数为30;K-means2的正常类中心点数为100,异常类中心点数300)、决策树或随机森林作为3组对照组。Winner of KDDCUP99作为基线对比。

表1 对比实验设置
为得到“正常流量分类器”+“异常流量分类器”的效果,表2中专门设计了8组混合实验,具体细节见表2.
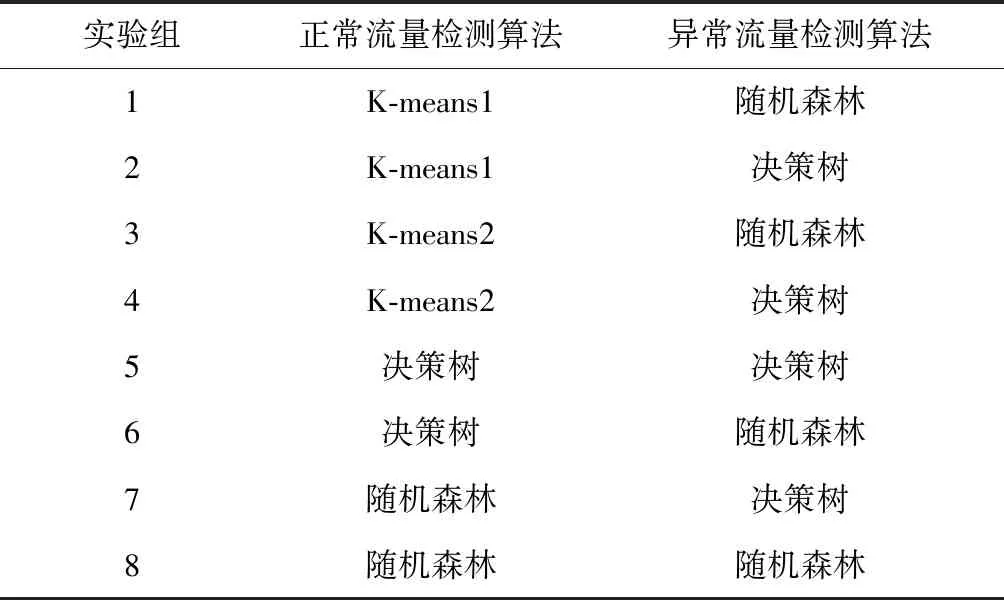
表2 模型算法设置
本文中,采用分类准确率作为分类效果的仿真指标,最终实验结果如表3所示。从表3的准确率结果中可以看出,单独的K-means算法、决策树算法、随机森林算法以及Winner of KDDCUP99在对正常流量和DoS流量的分类准确度很高,但是对U2R、R2L等异常流量的识别精度不够,尤其Winner of KDDCUP99算法对这些异常流量的识别准确率最低。
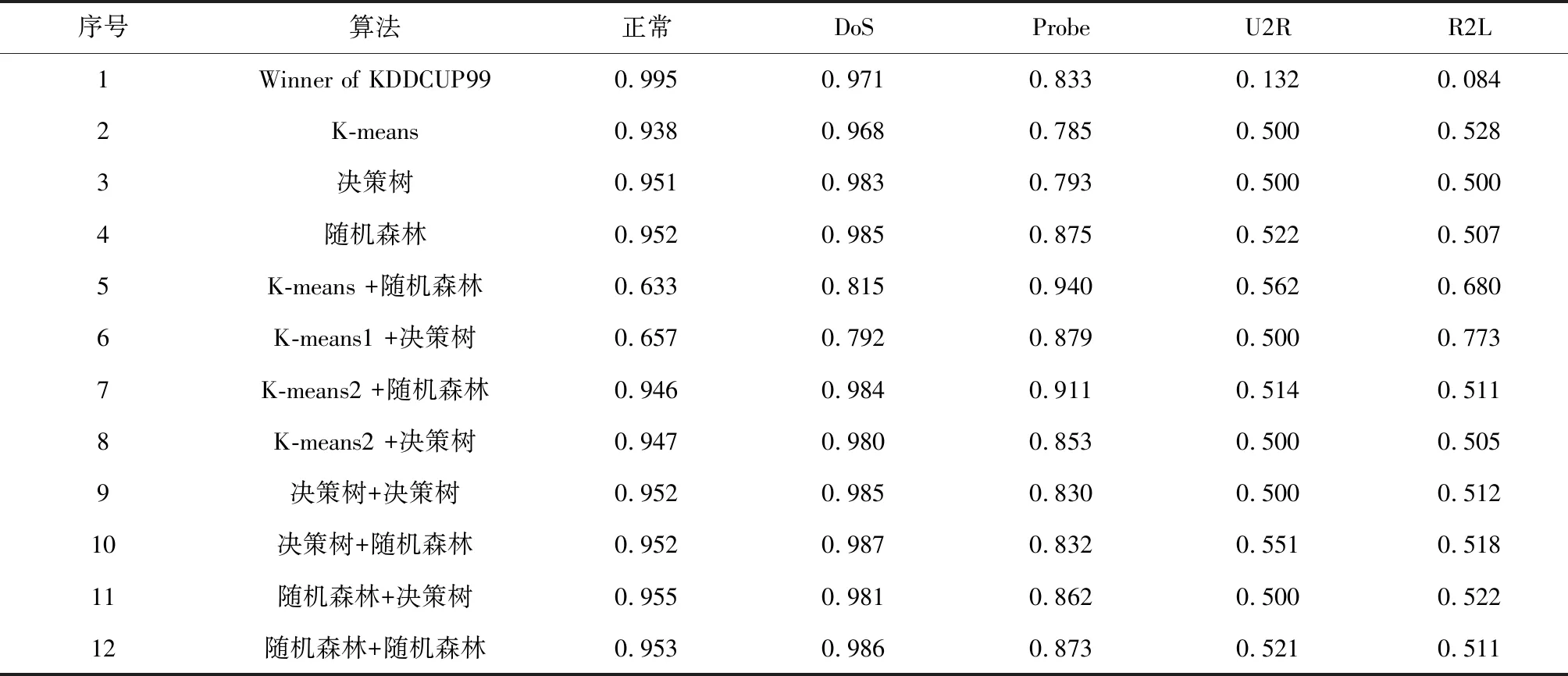
表3 分类准确率
在使用本文提出的模型后,通过对正常流量分类器和异常流量分类器搭配不同的算法,其分类结果均有所提升。同时通过对比第5、6、7、8四条结果,可以看出K-means算法在此时的分类效果大大受到聚类中心点的影响。
为了评估对异常流量分类的效果,本文采用漏报率(原本是异常流量数据却被分类为正常流量所占的比率)作为衡量的指标。表4展示了对比实验第3组实验的结果,通过与表5中的实验结果对比可以看出,所列出的四个异常流量类的漏报率都显著下降,验证了所提出的模型的有效性。

表4 对比实验第3组的漏报率
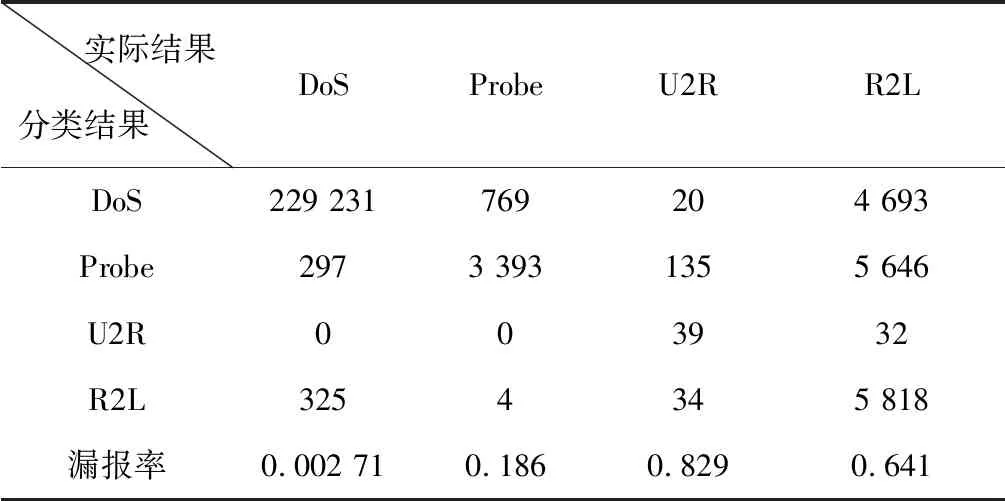
表5 实验组第8组的漏报率
4 结论
为了有效利用网络大数据,准确的识别和检测异常流量,本文设计了一种异常流量监测模型。实验结果显示,通过合理地选择各模块的算法,该模型对正常数据的检测率为95.5%,对DoS攻击的检测率为98.8%,对探针攻击的检测率为94.0%,对U2R攻击的检测率为55.1%,对R2L攻击的检测率为77.4%,提高了对异常流量的识别率,并降低了误报率。
