基于隐马尔科夫模型集成学习的广播关键词检测
2019-09-10杜淼黄天淏边彤颜逸为余勤雒瑞森
杜 淼 黄天淏 边 彤 颜逸为 余 勤 雒瑞森



摘 要:由于无线电技术的日益成熟,盗用正常广播频段进行其他活动的非法广播对国民经济和安全造成相当大的危害,因此对非法广播的监测非常重要。本文集成隐马尔科夫模型对广播关键词进行识别,进而监测非法广播。在试验中,首先对采集的非法广播进行人工切割与标定用于训练,然后研究基于集成学习的方法组合多个模型,使用投票规则得到最终结果。将集成学习的PocketSphinx系统与单一模型进行比较,试验结果显示,与单一模型84.8%的识别率相比,集成的PocketSphinx系统识别率达到92%,并且具有更好的稳定性。
关键词:关键词识别;PocketSphinx;隐马尔科夫模型;集成学习
中图分类号:TN912.34 文献标识码:A 文章编号:1003-5168(2019)35-0008-04
Application of Hidden Markov Model with Ensemble Learning
in Broadcast Keyword Detection
DU Miao1 HUANG Tianhao BIAN Tong1 YAN Yiwei1 YU Qin1 LUO Ruisen1
(1.College of Electrical Engineering, Sichuan University,Chengdu Sichuan 610000;2. College of Electronic Engineering and Automation, Guilin University of Electronic Technology,Guilin Guangxi 541004)
Abstract: Due to the increasing maturity of radio technology, illegal broadcasts that use the normal broadcast band for other activities have caused considerable harm to the national economy and security, so the monitoring of illegal broadcasts is very important. This paper integrated hidden Markov models to identify broadcast keywords, and then monitored illegal broadcasts. In the experiment, the illegal broadcasts collected were first manually cut and calibrated for training, then the method based on ensemble learning was used to combine multiple models, and the voting rules were used to obtain the final results. Comparing the integrated learning PocketSphinx system with a single model, the experimental results show that compared with the single model's 84.8% recognition rate, the integrated PocketSphinx system has a recognition rate of 92% and has better stability.
Keywords: keyword recognition;PocketSphinx;Hidden Markov Model;ensemble learning
隨着无线电技术应用的成熟,部分不法分子采用盗用调频广播的手段进行非法活动,扰乱正常广播秩序,对国民经济和安全造成了严重威胁。在实际的应用过程中,非法广播关键词识别往往存在诸多复杂问题,例如,存在设备和环境影响产生的噪声,没有标准数据集进行训练,人声混合等。因此,本文的研究环境是一个非常复杂的实际应用场景。隐马尔科夫模型(Hidden Markov Model,简称HMM)可分为:离散隐马尔科夫模型(DHMM)、连续隐马尔科夫模型(CHMM)和半连续隐马尔科夫模型(SCHMM)[1]。SCHMM作为DHMM和CHMM的折衷方法,尽量避免DHMM因矢量化信息造成信息损失和CHMM由于待估计参数过多需要大量训练集[2,3]。
由于实际的非法广播信号中存在噪声、不同人声和方言等问题,所以本研究采用集成学习的方法提高模型的鲁棒性。将不同模型结合可能会带来以下好处[4]:从统计学角度来看,由于学习任务假设空间很大,可能有多个假设在训练集上达到同等性能,结合多个模型,避免误选而导致泛化能力不佳的问题;从计算角度来看,多次运行的结合,可以降低陷入局部极小点的风险;结合多个模型,可以扩大假设空间,有可能更好地接近未在假设空间内的最优解。
为了更好地检测非法广播中的关键词,本文在PocketSphinx系统[5]上使用集成学习的方法,将多个模型识别的关键词结果通过投票机制获得最终的识别结果,最后通过非法广播试验证明采用集成学习的方法能获得更高的识别率。
1 相关背景工作
为了监测广播是否非法,打击非法频段的广播,本文将利用集成学习的PocketSphinx系统对广播进行关键词识别。
1.1 SCHMM模型
隐马尔科夫模型是一种时间序列的概率模型。该模型描述了由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。在语音系统中,通常以音素[6]为基本识别单位。从语音中提取音素特征,状态之间的转移表示了音素之间的关系和链上每个状态的一个概率分布。SCHMM可以表示为:
[λ={π,A,B}] (1)
式中,[π]为SCHMM的初始化参数;A为状态转移矩阵;B为观察值概率矩阵。
[A=a0N×N],N为模型的状态数,记N的状态为[s1,...,sN],记[t]时刻马尔科夫链所处状态为[qt],显然[qt∈(s1,...,sN)],则:
[ai,j=P(qt+1=si|qi=si) 1≤i , j≤N] (2)
[B=bjkN×M],其中,[bjk]满足以下条件:
[bjk=P(oi=vk|qt=sj) 1≤j≤N ,1≤k≤M] (3)
HMM是一個双重随机过程,在概率统计学的基础上解决实际应用中的三个问题:评估问题、解码问题、学习问题。HMM的参数[λ={π,A,B}]通过Baum-Welch算法利用观测到的数据进行估计,由估算的HMM组成分类器,实现对观测序列的分类。
1.2 PocketSphinx
PocketSphinx是一种轻量级的语音识别系统,其主要基于隐马尔科夫模型,程序主要使用C语言进行编写。PocketSphinx是一种应用在大词汇量连续语音识别系统的开源项目,由于其成本低且开源,所以本文将对PocketSphinx系统在非法广播中的关键词检测进行应用与开发。PocketSphinx语音识别系统是一种包含多种技术的系统。其中,MFCC特征提取为Mel Frequency Cepstral Coefficents,是一种能准确包络语音短时功率谱的一种方法[6]。
1.3 集成学习
集成学习通过将多个分类器进行结合来完成学习任务,通常可以获得比单一分类器更显著的优势[7]。集成学习的一般结构为:先产生一组“个体学习器”,再使用某种策略将它们结合起来,其中个体学习器一般由训练集数据产生。在学习任务中,最优点可能不存在整个假设空间中,使用单一模型进行训练时,无论如何训练都不可能获得最优解,通过结合多个模型,有可能学习得到更好的近似[7]。
2 试验数据与方法
本试验将集成学习应用到PocketSphinx系统,使用截取的关键词片段对模型进行训练。为了进一步提高PocketSphinx系统在广播检测中的识别率,本节使用了集成学习的方法,目的是训练对不同关键词敏感的模型,提高非法广播的识别率。本文对非法广播的判断依据为,如果广播中出现了试验中定义的非法关键词,则认为广播为非法广播,具体试验过程将在本节详细展示。
2.1 试验数据
本次数据进行识别的关键词使用了首字母表示,如广播-gb。本试验的原始广播数据长短不一,所以使用软件Audacity对原始数据集进行了人工切割,将原始的广播数据切分成1min左右的数据,图1展示了切分割好的一个非法广播语音中的部分,时间长度为1min,其中红色虚线框部分为非法关键词cdkf、lglc,其他部分为广播的其他内容。
图1 一条广播语音中的信息
2.2 试验方法
本试验研究了一个模型的训练过程,先将语音数据进行归一化,减少语音大小对识别效果的影响;将每个关键词设置不同权重,对模型进行训练,得到训练好的单一模型;使用模型对测试集进行识别,得到识别后的文本信息。其中,关键词权重设置越高,表示对识别该关键词越严格;反之,表示越容易。使用集成学习时,本文将生成多个模型进行试验,最后将每个模型生成的文本信息通过投票的方式判断测试语音是否非法。
3 试验结果
3.1 单一模型
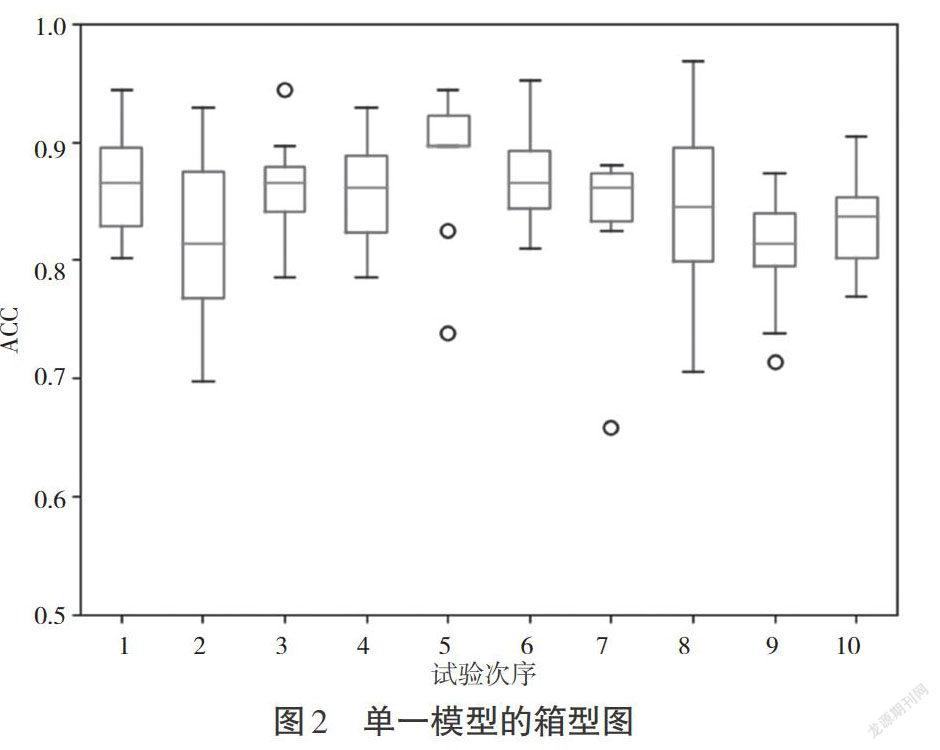
在训练中,以[0,20]中随机抽取的值作为关键词权重,得到新的单一模型,通过100次试验,得到平均识别率为84.8%。箱型图是一种用作显示数据分散情况的统计图,直观展示了异常值等数据分布特征,本试验将使用箱型图进行展示,图2展示了100次试验的结果。其中,横轴为试验次序(将100次试验平均分成10次进行),纵轴为识别率(ACC)。
图2 单一模型的箱型图
3.2 多个模型
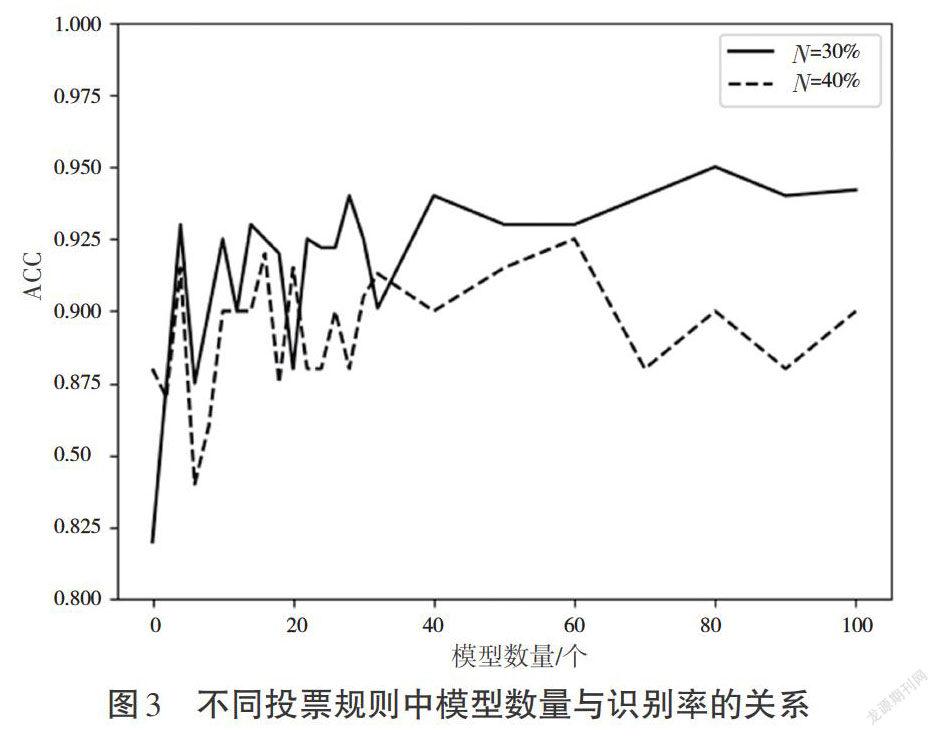
为了训练多个不同的模型,本试验从[0,20]中随机抽取值作为关键词权重,并重复抽取多次训练多个权值不同的模型。使用多个模型对测试语音进行识别,最后得到多个语音文本,再使用投票规则,最后计算识别率。本次试验模型数量为(1,100],投票规则为识别的关键词数量大于模型数量(超出比例为[N]),则认为出现了该关键词。本文通过固定模型数量(5,10,20),每种集成模型连续进行10次试验,得到试验结果,如图3和图4所示。其中,横轴(Number)为集成的模型数量,纵轴(ACC)为通过投票规则后的识别率。
<E:\新建文件夹\2月份\未做\河南科技201935\内文排版文件-河南科技(创新驱动)2019年第35期\Image\10-图3.pdf>[模型数量/个][ACC][N][N]
图3 不同投票规则中模型数量与识别率的关系
图4 多个模型组合的箱型图
4 讨论
4.1 集成学习对识别率的提高
集成学习对识别率的提高表现在两个方面:一是最低识别率的提高;二是总体识别率的提高。通过图2单一模型的箱型图可以看到,整个假设空间中存在识别率为97%的解,但是从统计的均值来看,单一模型的识别率在81%~87%,中位数在85%上下浮动,并且大量数据在90%以下,使用单一模型进行识别可能面临陷入识别率较低点的风险。由图2可以明显看到,试验中出现较多的异常值点。通过单一模型的多次试验可以得出,本次试验数据中存在识别率较高的点,但是随机抽取权重后的模型识别率不高,整个系统的识别率不稳定。从图3可以看出,采用集成学习后,整体识别率提高,有效地减小假设空间,使平均识别率提高,并且随着集成模型的增加,识别率逐渐稳定在90%以上。通过图4多次试验可以看到,随着模型的增加,数据逐渐集中,并且识别率有了明显的提高。
4.2 集成模型数量的影响
4.2.1 集成模型数量对识别率的影响。由于训练片段与测试集的不同,为了得到较好的识别率,关键词的权重在每个测试集中的权重也不相同。图4展示了多个模型组合的箱型图,每个集成学习箱型图进行了10次试验。从图4中可以看到,通过集成学习,整个系统的平均识别率达到92%,高于单一模型84.8%的识别率,其中中位数上升到93%,大量数据保持在90%以上。通過图3与图4的试验结果可以看到,集成学习方法可以有效地减小假设空间,使平均识别率提高到92%。
4.2.2 集成模型数量对识别稳定性的影响。由图2可知,单一模型试验频繁出现异常值点,说明单一模型容易进入一个局部糟糕的点,系统稳定性较差。由图4可知,模型数量为20时出现了一个异常值点,但是该点识别率高于单一模型的平均识别率,整个系统在识别率上展示了较强的稳定性。同时,使用集成学习使模型减少了陷入糟糕局部解的风险,使数据集中较好的识别率接近识别率较高的点。
5 结语
本文将集成学习的PocketSphinx系统用于广播关键词检测,这是一种监测非法广播的有效手段。本文的试验数据为实地采集数据,在本文使用的数据集和关键词中,通过集成学习试验结果与单一模型试验结果可以发现,集成学习PocketSphinx系统在识别率和稳定性上的效果明显。试验结果表明,集成不同权重的PocketSphinx模型可以有效提高关键词的识别率和系统的稳定性。但是,由于本文采集数据中噪声低的数据较少,所以本试验没有从训练数据来调整模型的多样性。本文使用的广播数据为中文数据,但是非法广播关键词的检测可以应用不同语种,为了更好地打击违法犯罪行为,利用语音关键词识别对更多地区进行广播监测将是非常必要的手段。本文使用集成学习的PocketSphinx模型可以进一步提高中文关键词识别率和系统稳定性,并在其他语言的关键词识别方面具有一定的参考价值。
参考文献:
[1]向东,刘虎,陈先桥,等.半连续隐马尔科夫模型脱机阿拉伯手写识别[J].武汉理工大学学报(信息与管理工程版),2011(3):349-353.
[2]严斌峰,朱小燕,张智江,等.基于邻接空间的鲁棒语音识别方法[J].软件学报,2007(4):878-883.
[3]高家宝,来羽.一种新的HMM/SVM混合语音识别模型[J].控制工程,2016(11):1802-1807.
[4]Dietterich T G.Ensemble methods in machine learning[C]//International workshop on multiple classifier systems.2000.
[5]袁翔.基于Sphinx的机器人语音识别系统构建与研究[J].电脑知识与技术,2017(7):154-155.
[6]邵明强,徐志京.基于改进MFCC特征的语音识别算法[J].微型机与应用,2017(21):48-50.
[7]余恩泽,努尔布力,于清.一种基于集成学习的钓鱼网站检测方法[J].计算机工程与应用,2019(18):81-88.
