适用于Hadoop云平台的洪水淹没分析并行算法
2019-09-10刘小生黄秋锋赵爱国
刘小生 黄秋锋 赵爱国







摘要:数字高程模型(Digital Elevation Model, DEM)特殊的数据结构有利于数据在计算机中进行计算,但其数据量大,受计算机性能的限制,无法满足大规模洪水淹没分析的需要。针对单机计算能力有限以及有源淹没分析递归算法占用计算机资源较多的问题,提出了一种利用Hadoop云平台进行洪水淹没分析的并行算法。该算法对研究区域DEM按规则格网的思想进行划分,将大规模的研究区分割成多个规则的小区域。在指定水位下,对每个小区域进行数据压缩,计算每个栅格单元的淹没值,并将同一行中相连的淹没栅格序列记为淹没块,每个淹没块包含该栅格序列所属的区块号、行号、起始列号、终止列号以及淹没标记;当不同行或不同区域中的淹没块相互连通时,需对其淹没标记进行一致性设计。最终,根据淹没点所在淹没块的淹没标记提取出淹没点所在的淹没区,即为实际的淹没范围。实验结果表明,在指定淹没水位下,通过该算法可以快速提取淹没范围以及实现淹没水深的计算。
关 键 词:洪水淹没分析; 并行运算; 图像处理; Hadoop; 数字高程模型
1 研究背景
受到极端天气的影响,洪涝灾害爆发率越来越高,其强大的破坏性严重地威胁着国民经济和人民财产安全,为此,开展准确的洪水淹没分析可为防洪救灾工作提供强有力地科学依据[1]。如何高效率地进行洪水淹没分析与预报,是防洪救灾工作的重要环节[2]。目前,国际上的洪水淹没分析主要以两种方式为主,包括分布式架构的水文模型和数字高程模型(DEM)结合GIS技术[3]。分布式架构水文模型考虑到了水循环的基本过程[4-5],包括蒸散发量、植物截留、地表下渗和土壤饱和度等,能够较真实地反映洪水的淹没过程;但是其针对性较强,普适性较差,并受地区和环境等因素的限制,数据采集困难,而且模型构建较为复杂。在数据缺失的地区,分布式架构的水文模型的可用性更低。
相关研究者发现,地形因素是形成洪水淹没区的主要因素,而数字高程模型能够真实地表达地面起伏情况[6-8]。因此,利用数字高程模型和GIS 技术相结合的方式进行洪水淹没分析,可以弥补分布式水文模型在数据缺少时的不足,而且数据采集更为容易,技术实现手段更为简单。比如,刘仁义等[9]基于种子蔓延算法而提出的“无源淹没”和“有源淹没”算法;杨军等[10]利用DEM数据进行的洪水淹没分析和可视化表达。
基于DEM数据的特殊结构和数据量较大的特点,许多学者在进行洪水淹没分析时,大多采用了递归算法,比如种子点蔓延法或八邻域蔓延法[11]、分块种子蔓延法[12]以及条带压缩法等[13]。尽管这些算法具有许多众所周知的优点,但是由于算法运行时占用的计算机资源较多,而且当递归深度达到一定时,计算效率就会大幅下降,不稳定性就会越来越高,因此无法满足大规模DEM数据处理的需要。为此,本文利用Hadoop云平台能够动态地扩展数据处理节点和支撑海量数据处理的特点[14-15],提出了一种基于DEM数据和GIS技术进行大规模洪水淹没分析的并行算法。
2 算法描述
本文构建的Hadoop云平台下的洪水淹没分析并行算法,以解决大规模DEM数据在洪水淹没分析中的应用问题为目的。针对大范围研究区,首先按规格格网的方法对其进行划分,按从左到右、从上往下的顺序对其进行编号;当研究区足够大,可以环绕整个地球、首尾相连时,需要考虑同一行首尾两个数据块的连通性。由于数据量巨大,考虑到计算不便等问题,采用数据压缩的方式对数据的每一行进行压缩;在给定淹没水位的情况下,计算每个栅格的淹没水深,将同一行的淹没栅格序列记为一个淹没块,该淹没块包含淹没栅格序列所属的淹没块编号、行号、起始列号、终止列号以及淹没块标记等。将相互连通的淹没块的淹没标记设置成一样,从而将研究区分割成不相连的几个区域。对于有源淹没分析,根据给定的淹没点源,由其所在淹没块的淹没标记提取出所属的淹没区域,并确定最终的淹没范围。其核心理论与关键步骤详述如下。
2.1 DEM数据分块
在进行大规模洪水淹没分析时,用单一的DEM数据块表示,其数据量巨大,无法在计算机中进行有效的处理。因此,为满足大规模DEM数据在计算机中处理的需要,有必要对DEM数据进行划分。本文采用规则格网的方式对研究区进行划分。南北方向以赤道为界,记为dx,向北为正,向南为负,纬度每增加1°,dx加1;东西方向以本初子午线为界,记为dy,向东为正,向西为负,经度每增加1°,dy加1。此时,当研究区域在东经180°附近,同时跨越东西半球时,需要对不同DEM分块之间的连通性进行判断。
第7期 刘小生,等:适用于Hadoop云平台的洪水淹没分析并行算法 人 民 长 江2019年 2.2 淹没块
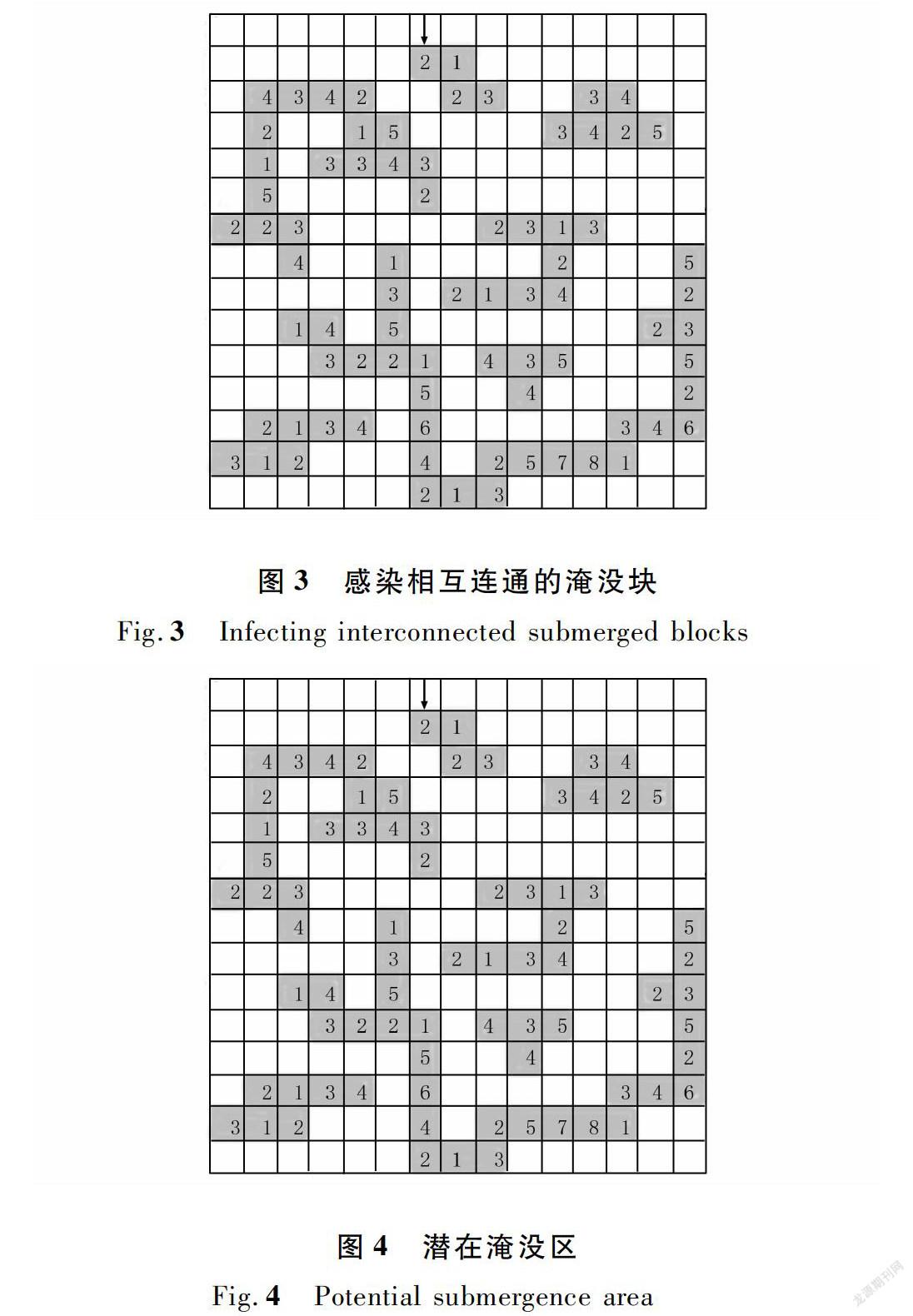
淹没块Cell作为区域感染法的最小单位,记录的是同一行中相连淹没栅格所在的行号、起始列号、终止列号以及淹没标记,用(x, startY, endY,floodMark)表示。其中,淹没标记floodMark需具有唯一性,除了记录淹没块所在的行列号,还应记录该淹没块所在的DEM在研究区域中的行列号,用dx:dy:x:startY:endY表示。假设某区域存在潜在淹没区如图1所示,其中颜色较深的部分代表潜在的淹没区,数字代表潜在的淹没水深,整個DEM数据块左上角坐标为(25,120)。
在给定的淹没水位下,从DEM数据块的第一行开始,依次判断每一行中的栅格单元高程值是否小于指定淹没水位。若该栅格单元的高程值不小于淹没水位,则跳过当前的栅格,继续判断下一个栅格单元的高程值,直到遇到一个栅格单元高程值小于淹没水位时,新建一个淹没块,并标记该淹没块的行号x为当前栅格所在的行号;该淹没块的起始列号startY为该栅格所在的列号,然后继续判断下一个栅格单元P的高程值;若P为该行最后一个栅格单元且其高程值小于淹没水位时,记录该淹没块的终止列号endY为P所在的列号;若P的高程值大于或等于淹没水位,则标记该淹没块的终止列号为P所在列号减1。
2.3 淹没块连通域判读
(1) 单个DEM数据块中,若2个淹没块位于第i行和第i+1行中,而且存在其中一个淹没块的终止列号在另一个淹没块的起始列号和终止列号之间,则判定这2个淹没块连通,否则认为这2个淹没块彼此相互分离。
(2) 当2个淹没块位于不同的2个DEM数据块(dem1和dem2)时,若dem1与dem2左右相邻,2个淹没块所处的行号相同,而且左淹没块的终止列号等于左DEM数据块的宽度减1,右淹没块的起始列号等于0,则认为2个淹没块连通。
(3) 若dem1与dem2上下相邻,且上淹没块的行号等于上DEM数据块的高度减1,下淹没块的行号等于0,而且存在某个淹没块的终止列号在另一个淹没块的起始列号和终止列号之间,则判定这2个淹没块连通。
2.4 淹没区分割
不同的淹没区通过淹没标记进行划分,对具有相同淹没标记的淹没块划分为同一淹没区。在同一块DEM数据中,对第i行中的每一个淹没块,分别判断其与第i+1行的每一个淹没块的连通情况,将相互连通的淹没块的淹没标记改成相同的标记。如图3所示,以第一个淹没块(1,6,7,25∶120∶1∶6∶7)为淹没源,分别遍历下一行的每一个淹没块,当遇到与淹没源相连通的淹没块(2,7,8,25∶120∶2∶7∶8)时,将DEM数据中所有具有淹没源标记(25∶120∶1∶6∶7)的淹没块的标记改成与淹没源相连通的淹没块的淹没标记(25∶120∶2∶7∶8)。最终形成如图4所示淹没区。
当存在多个DEM数据块时,若2个DEM数据块左右相邻,分别提取左DEM每行的最后一个淹没块,右DEM每行的第一个淹没块,分别判断所提取的左DEM数据块中的淹没块是否与右DEM数据块中淹没块是否相互连通。若连通,则将DEM数据中每个具有与淹没源标记相同的淹没块改成与淹没源相连通淹没块的标记;若两个DEM数据块上下相邻,则分别提取上DEM最后一行的淹没块以及下DEM第一行的淹没块,若存在相连通的2个淹没块,则将具有淹没源标记的淹没块的标记改成与淹没源相连通淹没块的标记,其算法如图5所示。
3 算法实现
传统的洪水淹没分析算法建立在单机环境中,受计算机性能的限制,无法满足大规模DEM数据处理的需要。本文采用Hadoop云计算平台的MapReduce框架[16-18],采用分而治之的方法。将研究区域划分成一序列规则的DEM数据块,以每一块DEM数据块作为一个分片,设计相应的map和reduce函数[19],其处理流程如图6所示。
在进行无源淹没分析时,各数据块彼此独立,不需要考虑其关联性,通过Map过程,可以很好地实现DEM数据的并行处理问题。在进行有源淹没分析时,由于同一个淹没区可能跨越多个DEM数据块,在对研究区域进行分解处理后,需要考虑其关联性,即实现Reduce过程。但由于每个DEM文件的数据量都比较大,当传输到同一个Reduce节点时,其处理效率类似于在单机中进行处理。为了减少数据迁移成本和计算量,本文在进行有源淹没分析时,通过Map过程提取淹没块、并对淹没块进行压缩的方式,减少了数据量,从而实现了更大量DEM数据的计算问题。考虑到MapReduce的处理流程,首先对淹没块和DEM数据类进行设计,然后实现MapReduce键值对的设计。
3.1 淹没块设计
作为洪水淹没分析的最小单位,淹没块是实现DEM数据压缩的关键。为了识别淹没块在研究区域中的具体位置以及对不同淹没块进行比较,对每个淹没块需要标记淹没块所在的行号、起始列号、终止列号和属于不同淹没区的淹没标记等信息,而且需要继承Comparable接口以实现淹没块大小的比较,其基本结构如图7所示。
3.2 DEM类设计
以geotiff格式存储在HDFS中的DEM数据无法像访问本地文件系统一样进行访问。基于HDFS流式数据访问模式,本文将每个DEM数据块以BytesWritable的方式读取到内存中,读取DEM数据块的基本信息,如坐标信息、投影信息与像素值等。其基本结构如图8所示。
3.3 MapReduce的键值对设计
MapReduce处理的是形式的数据,并不能直接对文件流进行处理,只有经过序列化的类型才能够充当这个框架中的键或者值。只有继承Hadoop的序列化接口Writable才可以作为值类型,而继承自WritableComparable接口的类型既可以作为键类型,也可以作为值类型。由于淹没块在数据处理时只做内部分析用,而且DEM数据的数据量太大,因此无论是淹没块还是DEM都无法直接作为键值对。在进行洪水淹没分析时,以DEM数据块的路径作为Map的输入key,以DEM数据块的数据流作为Map的输入value,将处理后的每个DEM数据块的所有淹没块Table作为map过程的输出value。其基本结构如图9所示。
图9中,fileName代表DEM数据块在HDFS中的文件名,dx、dy代表其所在的行列号,Row代表每行所有淹没块的集合。在Reduce过程中,进行淹没区的合并,并根据淹没源Point所在淹没块的淹没标记来提取淹没源所属的淹没区,舍去不包含淹没区的Table,并将余下的Table传递到下一个Map过程中;由fileName读取DEM数据,根据淹没块及淹没水位修改其像素值,并输出到指定的位置。
4 算法测试分析
为了验证本文所提出的洪水淹没分析并行算法的有效性,采用的实验系统配置环境如下:Centos7操作系统由2个2.6GHz的IntelR Core TM i7-6700HQ的CPU、4G的运行内存和100G的磁盘构成,运行的Hadoop云计算平台包含一个主节点hqf0和2个子節点hqf1和hqf2,其中的主节点hqf0开启NameNode、JobHistoryServer和ResourceManager服务;第一个子节点hqf1开启SecondNameNode、DataNode和NodeManager服务;第二个子节点开启DataNode和NodeManager服务。由于集群节点在同一个机架上,而且数据节点只存在2个,因此,将文件块的副本数设置为1。尽管DEM数据在HDFS中能够进行分块存储,但DEM数据量巨大,受子节点计算性能的限制,大DEM数据块在单个节点中的处理效率低下。因此,在Hadoop集群中对DEM数据进行处理时,有必要对DEM数据进行分割。本文采用地理空间数据云上按规则划分的DEM数据,其分辨率为30 m,尺寸大小为360 1×360 1。
在开展洪水淹没分析时,对每一个DEM数据块启动一个Map任务进行处理,将处理完的淹没块数据在同一个Reduce任务中进行汇总,根据淹没点的淹没标记提取相连的淹没区,重置DEM数据的淹没值,并由Map任务将属于淹没区的DEM数据写入到指定的位置。其详细的运行情况如表1所示。
由于每个DEM数据块中淹没块的数量各不相同,在运行环境一致的情况下,其处理时间各不相同。淹没块多的DEM数据块,压缩率低,洪水淹没范围较大,淹没区情况复杂,连通性较差,所需要的处理时间较多。受压缩率的影响,当淹没块数据量超过Reduce计算节点的计算能力时,需分批执行DEM数据的处理。在Reduce节点计算性能允许的情况下,对大规模DEM数据的处理,适当增加子节点,可以减少淹没块计算与淹没区提取的总时间,但其数据汇总时间并不会减少;在子节点一定的情况下,若DEM数据量少于或等于子节点数,其Map过程所需要的时间与淹没块最多的DEM数据块处理所需要的时间成正比,其Reduce过程随着DEM数据量的增加而增加,而且受到DEM数据块中淹没块数量的影响。
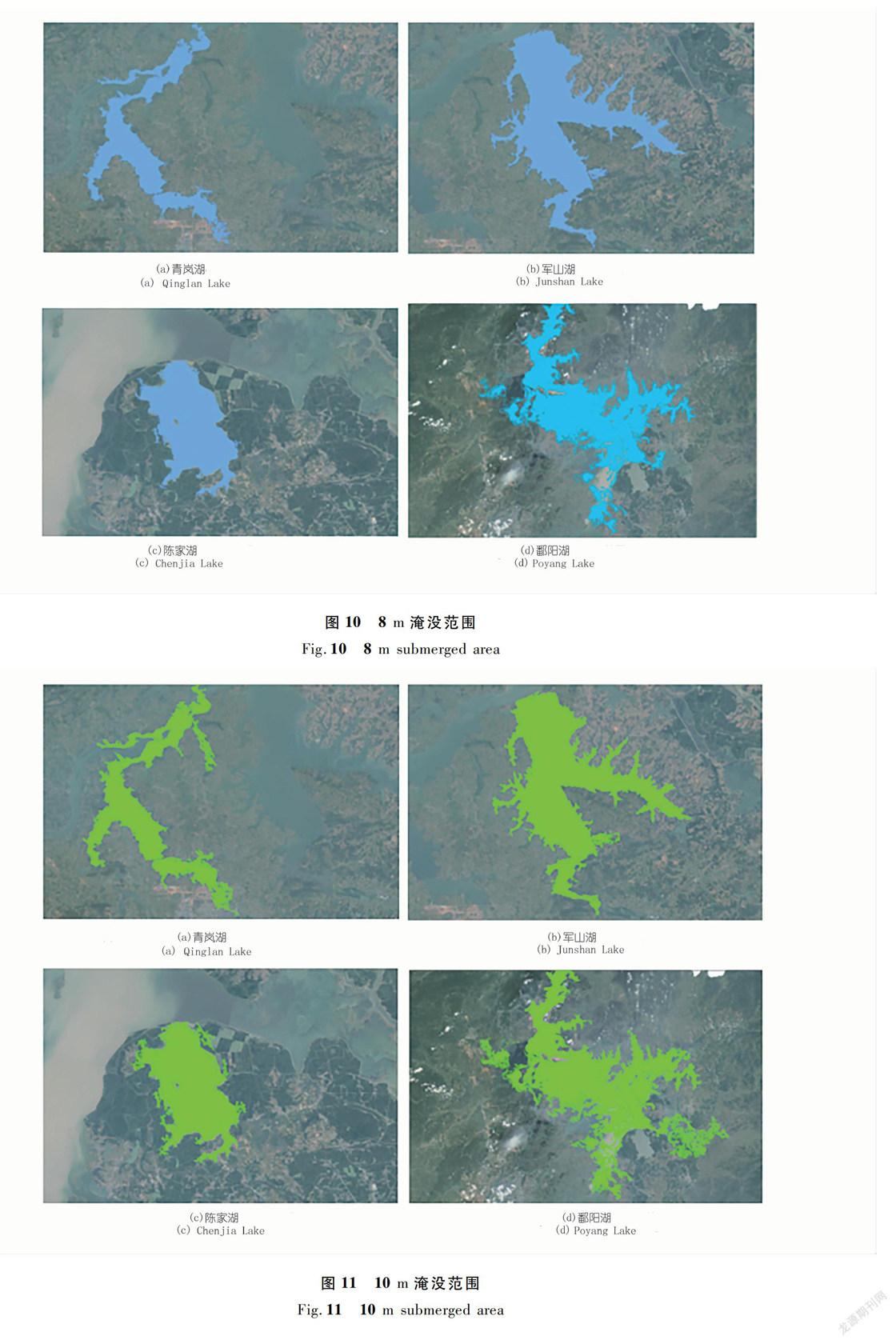
以江西省内的青岚湖、军山湖、陈家湖和鄱阳湖为例,提取出8 m和10 m淹没水位下的淹没范围,结合某个时期(2010年3月)的遥感影像,对其淹没效果进行模拟并对其淹没范围的变化情况进行分析,如图10~12所示。
由表1以及圖10~12的淹没分析结果可知,本文研究过程中,对较大规模的流域或者研究区所采用的方法具有较好的模拟效果,并且该方法能够较好地识别出湖中的孤岛,如图13所示。
5 结 论
本文针对DEM数据量大、单机环境计算力有限,以及现存洪水淹没分析算法无法满足分布式洪水淹没分析的需要,提出了一种能够适用于Hadoop云平台的洪水淹没分析并行算法。该算法具有以下优势:
(1) 能够解决在Hadoop云平台上利用大规模DEM数据进行洪水淹没分析时所存在的问题。
(2) 在没有指定淹没点时,该算法能够同时而且快速地提取出研究区中所有的淹没区;在给定淹没点时,该算法能够较快地提取出淹没点所在的淹没区。
(3) 在进行洪水淹没分析时,该算法能够快速地计算出每个淹没栅格的淹没水深并提取出洪水的最终淹没范围。
参考文献:
[1] 唐震,李勇,茅昌平,等.基于ArcGIS Engine的洪水淹没模拟系统构建[J].人民长江,2016,47(S2):1-3,51.
[2] 王嘉芃,刘婷,俞志强,等.基于COSMO-SkyMed和SPOT-5的城镇洪水淹没信息快速提取研究[J].遥感技术与应用,2016,31(3):564-571.
[3] 李琼,廖蔚.基于开源Hadoop的洪水淹没[J].江西测绘,2017(4):61-64.
[4] 王船海,闫红飞,马腾飞.分布式架构水文模型[J].河海大学学报:自然科学版,2009(5):550-555.
[5] 芮孝芳.论流域水文模型[J].水利水电科技进展,2017,37(4):1-7.
[6] 郭利华,龙毅.基于DEM的洪水淹没分析[J].测绘通报,2002(11):25-27,30.
[7] 张东华,刘荣,张咏新,等.一种基于DEM的洪水有源淹没算法的设计与实现[J].东华理工大学学报(自然科学版),2009,32(2):181-184.
[8] 汤国安,李发源,刘学军.数字高程模型教程(第3版)[M].北京:科学出版社,2016.
[9] 刘仁义,刘南.基于GIS的复杂地形洪水淹没区计算方法[J].地理学报,2001(1):1-6.
[10] 杨军,贾鹏,周廷刚,等.基于DEM的洪水淹没模拟分析及虚拟现实表达[J].西南大学学报(自然科学版),2011(10):143-148.
[11] 赵秀英,王耀强,李洪玉,等.基于DEM的有源淹没算法设计与实现:以种子蔓延法为例[J].科技导报,2012(8):61-64.
[12] 杨启贵,王汉东.一种大区域洪水淹没范围快速提取的分块种子蔓延算法[J].华中师范大学学报(自然科学版),2015,49(4):603-607.
[13] 周佳.时间序列无失真压缩算法的研究[D].西安:西安电子科技大学,2011.
[14] 陈吉荣,乐嘉锦.基于Hadoop生态系统的大数据解决方案综述[J].计算机工程与科学,2013(10):25-35.
[15] 李倩,施霞萍.基于Hadoop MapReduce图像处理的数据类型设计[J].软件导刊,2012,11(4):182-183.
[16] 于金良,朱志祥,李聪颖.Hadoop MapReduce新旧架构的对比研究综述[J].计算机与数字工程,2017(1):83-87.
[17] 刘义,陈荦,景宁,等.利用MapReduce进行批量遥感影像瓦片金字塔构建[J].武汉大学学报(信息科学版),2013(3):278-282.
[18] 黄山,王波涛,王国仁,等.MapReduce优化技术综述[J].计算机科学与探索,2013(10):885-905.
[19] Miss J Vini,Rachel Nallathamby,Rene Robin C R.A Novel Approach for Replica Synchronization in Hadoop Distributed File Systems[J].Procedia Computer Science,2015(50):590-595.
(编辑:赵秋云)
