基于聚类的人名消歧研究综述
2019-09-10展金梅陈君涛
展金梅 陈君涛


摘 要:人名消歧问题属于文本聚类范围,但有其自身的特殊性,即参与聚类的文本集采用向量空间模型表示以后具有较高的维度,导致数据在聚类过程中效率低下、计算内存开销过高。为了深入分析人名消歧研究中聚类算法的整体应用情况,从中国知网期刊数据库收集2006-2018年10月相关文献进行了统计和分析,介绍了利用聚类算法进行人名消歧研究的一般流程,阐述了聚类算法在人名消歧研究的应用、聚类评价指标和聚类结果评价,详细介绍相关研究成果及代表文献,为研究人员提供参考和借鉴。
关键词:聚类;人名消歧;研究综述
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2019)10-0088-04
Abstract:Name disambiguation belongs to the scope of text clustering,but it has its own particularity:the set of text clustering represented by vector space model has a higher dimension,which leads to inefficiency and high computational memory in clustering process. In order to deeply analyze the overall application of clustering algorithm in the research of name disambiguation,the paper collected the related literature from the database of CNKI from October 2006 to October 2018 to statistics and analyze. Also,introduces the general process of using clustering algorithm in the researching name disambiguation,expounds the application of clustering evaluation in researching name disambiguation,clustering evaluation and evaluation of clustering result. Finally,the paper introduces in detail research results and representative literature,which provides reference for researchers of name disambiguation.
Keywords:clustering;name disambiguation;research summary
0 引 言
隨着计算机技术的发展,互联网技术的普及,向搜索工具提交人名信息查询进行信息检索已经成为人们获取人物信息的主要方法。由于人名歧义问题十分普遍,以致于用户很难在结果数据中准确有效地定位、获取和管理所需的人物信息。此外,由于中文文本的复杂性,中文人名消歧被认为比英文人名消歧更加困难,中文人名消歧逐渐成为国内研究学者关注的问题。在命名实体中,人名具有很强的歧义性,无论在文本还是在网页中,都会出现不同的人物拥有同一个姓名的现象,人名消歧是语义社会网络系统中较难处理的问题之一。
人名消歧问题属于文本聚类范围,但有着其自身的特殊性,即参与聚类的文本集采用向量空间模型表示以后具有较高的维度,导致数据在聚类过程中效率低下,计算内存开销过高。自1998年Bagga,Baldwin将人名消歧作为实体共指中的一部分进行了探讨之后,研究学者开始关注和研究人名消歧的问题。开始分析K-means、DBSCAN等算法的运行特点,改进和优化原算法运行速度过慢和系统内存开销过大的缺点,在人名消歧方面取得了较好的研究成果。本文旨在综述聚类算法在人名消歧研究中的应用现状,对相关研究文献进行可视化的分析,为研究人员提供参考和借鉴。
1 文献发表情况分析
为了了解聚类算法在人名消歧研究领域中的应用现状,本文在中国知网期刊数据库中进行主题检索,时间限制为2006至2018年10月。为了较好地显示检索结果,文章从中国知网上截取了可视化的文献发表年限趋势图。同时,对检索结果进行了简单统计。
在中国知网期刊数据库以“人名消歧”为主题词进行检索,共检索到论文104篇,以“人名消歧”和“聚类”为主题进行检索,检索结果为65篇。2006-2018年10月每年论文发表量如图1所示。首先从检索结果可知,从2008年开始国内研究学者初步涉及人名消歧的研究领域,至2010年每年的发文量有所增加。中国中文信息学会从2010开始每2年召开一次学术会议,这对学者研究热情和论文发表量有着一定的影响。
其次,通在中国知网上进行主题词搜索后所列举的相关的主题词可以反映出相关研究的关键词和学者关注的热点词汇。
2 利用聚类算法进行人名消歧研究的一般流程
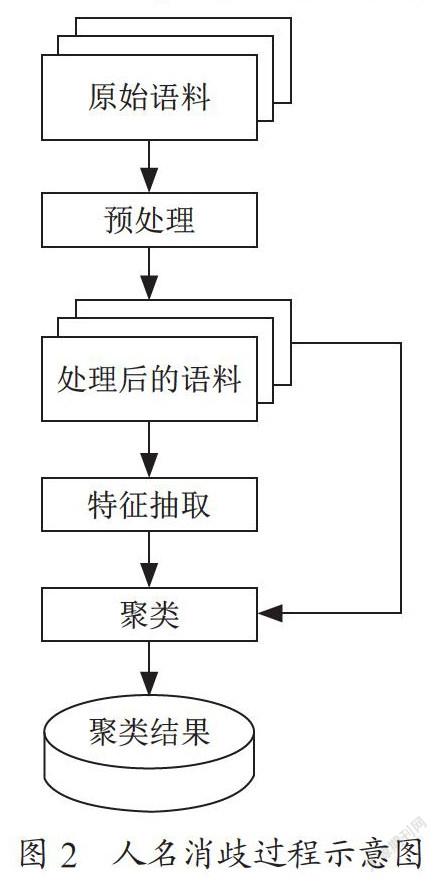
章顺瑞等[1]在对多文档中文人名消歧工作中利用层次聚类算法进行了研究。他们通过特征权重的计算,并使用TF/IDF的计算方法来构建识别人名的规则,并对中文人名消歧的流程进行了描述,具体操作步骤如下:
第一步:对原始语料进行预处理,包括中文分词、词性标注、人名识别和语料归类等。
第二步:对处理后的语料进行特征抽取或聚类处理。CB6E18A6-CA0D-42C0-9C0F-28C54F624F8F
第三步:采用向量空间模型表示所选取的特征,并利用层次聚类算法对特征向量所表示的文本进行聚类。
第四步:对聚类结果进行评测,评估消歧质量。
根据上述描述,人名消歧过程示意图如图2所示。
2.1 数据来源
人名消歧的早期研究主要是针对新闻类型的文本信息以及学术论文的自动处理(如引文分析)中人名歧义问题进行的。随着互联网的快速发展,人名消歧的研究热点逐渐转向网络搜索中的人名歧义问题。2007年,WePS评测研讨会与语义评测研讨会(SemEval07)联合开展了一项针对网络人名消歧的评测任务,WePS评测研讨会还分别在2009年和2010年开展了两届关于网络人名消歧的评测。
相比于英文,中文人名消歧研究工作开展较晚。2010年,CIPS-SIGHAN联合学术会议CLP2010首次开展了中文跨文本人名消歧任务评测。2012年,CLP2012在CLP2010人名消歧的基础上,增加了把人名消歧的结果映射到现实中具体人物实体的任务。CLP2012提供的人名消歧评测语料中包含知识库(KnowledgeBase,KB)、未标记文本集。2014年,CLP2014发布四个评测任务,分别是:中文分词、中文拼写检查、简体中文句法分析、中文人物属性抽取。每项评测任务都发布了相对应的语料库及评价指标。2016年,CLP2016则在CLP2014的基础上发布了中文篇章分析、传闻跟踪、虚词用法自动识别、多层次中文深度句义分析评测。从此次发布的任务可以看出,CLP2016丰富了中文消歧研究的深度,表现在从词句扩大到篇章,从句法分析细化到虚词用法,从人物属性提取延伸到传闻跟踪和深度句义分析。
2.2 数据预处理
待研究数据收集后,原始数据不能直接用于聚类,需要对数据进行预处理。数据预处理是指对数据进行清洗并转换成适合数据挖掘的形式的过程,主要包括数据清洗、数据转换和丰富、数据整合以及数据归约等任务[2],在数据特征提取操作过程中,需要从研究数据中选取具有相同人名的不同命名实体(NE)或一般词语的特征。命名实体特征如人名、地名、组织机构。一般词语如名词、动词等。
2.3 人名聚类算法
将原始数据预处理结束后,使用聚类算法对其进行分析,达到人名消歧的目的。当前研究者进行数据聚类的研究算法有:最长公共子序列、层次聚类、多步骤聚类、DBSCAN算法[3]、k-means算法[4]、聚类集成算法[5]等。
Wagner等[6]在1974年提出最长公共子序列(Longest Common Subsequence,LCS),即一个数列S,如果分别是两个或多个已知数列的子序列,且是所有符合此条件序列中最长的,则S称为已知序列的最长公共子序列。熊李艳等利用向量空间模型对所抽取的特征进行向量表示,使得每篇包含人名的文档都由一组特征向量所代表。向量空间模型利用所选取的特征将文档形式化为N维空间向量,空间中的每一维都是选取的特征词语。然后通过计算特征向量之间的相似度决定聚类对象[7]。任景华运用中文自然语言处理和信息抽取系统识别命名实体和实体关系,生成实体信息对象(Entity Profile),采用实体信息对象(EP)中的个人信息特征,实体关系和上下文相关信息在Hadoop平台上基于凝聚的层次聚类方法解决了实体消歧问题[8]。有的学者针对实体知识库的具体情况,将知识库实体与汉语命名实体经过多步骤的层次聚类,从而获得较好的聚类性能[9]。有的学者则针对知识库中单条实体特征稀疏和相似度阈值人工设置不精确的情况,采用分步聚的手段,利用文本检索的方法解决单条实体特征稀疏的问题,获得初步聚类结果;再采用自适应阈值层次聚类算法实现人名消歧[10]。通过对句义结构分析,以不同人名实体具有不同的社会关系网,而人名实体间关系为实体在句中语义角色间依赖关系所表现出的基本思想,依据句子本身的语义结构特点来提取人名实体之间在句中的以关系特征为依赖条件的关联关系,结合相关人物的职业、机构名和人物属性特征对关系类型特征进行聚类,由此实现人名消歧。
在基于密度的DBSCAN算法上,通过对DBSCAN算法初始参数选择进行优化,把对算法中的EPs值的确定转换为用户对数据中噪音水平的估计,使参数的决定更具有客观性,从而更容易通过数据集中实现人名消歧,解决了电子数据库中文献著者的人名消歧问题。通过改进文本聚类算法k-means来关注网页里的人名消歧的问题。基于经典的k-means算法如果选择了一个差的随机初始聚類中心,算法会遇到局部收敛的问题,因此提出一种基于最大最小原则改进的k-means算法来进行人名消歧。根据不同聚类算法的优缺点的不同,依据人名中的上下文特征、实体特征和社会关系特征,利用不同的聚类算法对三个特征构成的相似度短阵进行划分,利用均方误差邻接矩阵聚类对其进行集成,达到人名消歧,由此,提出聚类集成的人名消歧算法。
2.4 聚类评价指标
因实验数据的来源不同,研究人员选用的评测工具也不一样。目前,用于人名消歧评价工具主要有P-IP指标、B-Cubed指标和SemEvalWePS提供的评测工具。下面将分别列举评测试工具的算法。
式(4)~(6)中,Pre为精确率,Rec为召回率,S为标准聚类结果集合,d表示文档,Si∈S表示标准结果类别集合中的一个类,R为实际聚类结果集合,Ri∈R表示实际结果类别集合中的其中一类,|Si|和|Ri|分别为集体的Si和Ri大小。
SemEvalWePS提供的评测方法:
其中,,Ci表示要评估的结果,Lj表示为标注的正确结果,F则表示为准确率和召回率的调和系数。
上述三种评测方法分别均计算了聚类结果的准确率、召回率和F值。
2.5 聚类集成结果评价方法CB6E18A6-CA0D-42C0-9C0F-28C54F624F8F
目前,常用的评价聚类集成方法有:标准化互信息(NMI);变化的信息(VI);Adjusted Rand Index(ARI)。
(1)标准化互信息(NMI)。Strehl和Ghosh[3]提出了标准化互信息(Normalized Mutual Information,NMI),用来衡量多个候选聚类结果之间的相似性。与λ(a)相对应的熵可以表示为:
式(13)返回出来的是一个度量值,但是如果考虑到聚类过程中数据集的大小不一致且聚类的簇的数目不一致时,其原始的定义则不适用了。为此,Wu等人在VI的基础上提出NVI(标准版的VI),可解决上述问题。其定义如下:
可以看出,NVI和NMI之间很相近,且这两种方法的值都介于0和1之间,其中,0表示两个聚类完全不一致,1表示两个聚类达到最大的一致性。
(3)Adjusted Rand Index(ARI)。Hubert和Arabie提出ARI的定义如下:
3 结 论
人名消歧问题是本属于命名实体消歧的一个分支,属于文本聚类的范围。本文通过中国知网发表的文献数据分析了国内学者对人名消歧研究的情况,列举了人名消歧工作过程中应用到的研究算法、人名消歧流程、研究数据来源、聚类评价指标和聚类结果评价方法并对此进行了阐述。可望使读者对人名消歧工作形成基本的初步认识,由此将人名消歧工作应用到更多的不同语种之中。
参考文献:
[1] 章顺瑞,游宏梁.基于层次聚类算法的中文人名消歧 [J].现代图书情报技术,2010(11):64-68.
[2] 熊李艳,赵毅,黄卫春,等.基于句义结构分析的中文人名消歧 [J].计算机应用研究,2016,33(10):2898-2901.
[3] 任景华.利用优化的DBSCAN算法进行文献著者人名消歧 [J].图书馆理论与实践,2014(12):61-65.
[4] 杨欣欣,李培峰,朱巧明,等.一种基于改进的K-means算法的人名消歧系统的设计与实现 [J].计算机与数字工程,2010,38(8):10-12+17.
[5] 阳怡林,周杰,李弼程.基于聚类集成的人名消歧算法 [J].计算机应用研究,2016,33(9):2716-2720.
[6] 林翠萍,吴扬扬.采用改进最长公共子序列的人名消歧 [J].华侨大学学报(自然科学版),2016,37(2):201-206.
[7] 朱翔,史晓东,陈毅东.基于层次聚类的中文人名消歧方法研究 [J].心智与计算,2010,4(4):236-241.
[8] 张菲菲,李宗海,周晓辉,等.基于层次聚类的跨文本中文人名消歧研究 [J].计算机工程与应用,2014,50(6):106-111.
[9] 李广一,王厚峰.基于多步聚类的汉语命名实体识别和歧义消解 [J].中文信息学报,2013,27(5):29-34+42.
[10] 阳怡林,周杰,李弼程,等.基于分步聚类的人名消歧算法 [J].數据采集与处理,2016,31(1):213-222.
作者简介:展金梅(1983-),女,汉族,甘肃靖远人,讲师,硕士,研究方向:计算机应用、自然算法研究。CB6E18A6-CA0D-42C0-9C0F-28C54F624F8F
