基于随机森林的SQL注入识别算法研究
2019-09-10陈拥华



摘 要:随着基于Web的应用程序越来越普及,攻击者常通过欺骗服务器管理者执行恶意的SQL命令,获取数据和用户密码等信息,而获取数据库控制权限。本文阐述了SQL注入攻击的类型和研究现状,探索利用机器学习方法对其进行检测识别的方法。对URL进行有效信息提取,将原始数据特征转换为机器可识别的数值型特征,设计随机森林算法模型和规则检验。实验证明当前检测模型具有较高的准确率和召回率。
关键词:SQL注入;机器学习;随机森林
中图分类号:TP309.7 文献标识码:A 文章编号:2096-4706(2019)15-0146-04
Research on SQL Injection Recognition Algorithms Based on Random Forest
CHEN Yonghua
(Information Center of Sichuan Business Department,Chengdu 610081,China)
Abstract:With Web-based applications are becoming more and more popular. Attackers often obtain database control rights by deceiving server administrators to execute malicious SQL commands,obtain data and user passwords,and so on. This paper describes the types and research status of SQL injection attacks,and explores the use of machine learning methods to detect and identify them. To extract effective information from URL,transform the original data features into machine-recognizable numerical features,and design random forest algorithm model and rule checking. Experiments show that the current detection model has high accuracy and recall rate.
Keywords:SQL injection;machine learning;random forest
0 引 言
Web前端與后台数据库的交互是通过传递请求与应答消息来实现的。这一前后端分离机制为Web网站带来了很强的灵活性的同时,也留下了前后端之间的传递的消息命令可能被恶意修改的安全隐患。SQL注入(SQL injection)[1]就是恶意攻击者利用这一漏洞,将特定的SQL语句插入到数据库查询代码中,根据程序返回的结果,获得某些其想得知的数据(如用户名、密码等)。随着B/S(Browser/Server)模式应用开发的发展,使用这种模式编写的应用程序越来越多,现如今,SQL注入攻击成为黑客对数据库进行攻击的常用手段之一。
目前防御SQL注入的方法主要分为两类,一种是在编码时考虑安全因素,尽量减少SQL注入漏洞的存在,另一种是在程序运行期间通过额外的措施检测SQL注入攻击从而保护运行安全。虽然在编码阶段,通过一定的编码技巧,可以减少部分SQL注入漏洞[2],但是这种方法会加大编码难度和系统的负荷,而且一些经验丰富的攻击者仍可以通过巧妙地构造各种SQL语句绕过这些防御措施,因此程序运行阶段和用户输入阶段的防御措施就显得尤为重要。
程序运行阶段的安全防御措施主要以各种入侵检测系统为主,需要采集的信息也不仅仅是应用程序本身,而需要扩展到用户的输入和网络流量上来。在基于程序分析的SQL注入检测系统中,程序分析是指对计算机程序进行自动分析的过程,主要包括静态分析和动态分析两种策略[3]。其中静态分析不需要运行具体程序,而是通过分析程序的源代码找到潜在的安全漏洞,具体实现方法有抽象解释、约束分析、词法分析和语法分析等。
近来,随着机器学习技术的发展,大量的研究人员开始采用机器学习方法进行SQL注入识别,如基于特征匹配的SQL注入检测系统和基于无监督的网络异常溯源算法的SQL注入检测系统。用户输入阶段的防御措施区别于传统的SQL注入检测模型,在对后台情况一无所知的情况下,仅通过分析用户的输入就可以检测出可能的SQL注入。文献[4]提出一种基于关联分析Adaboost+FP-growth算法的SQL注入检测技术。在算法层面上,挑选出两种算法用于设计SQL注入检测模型,其中Adaboost算法可以输出[0,1]之间的值,最适用于威胁分级思想,在Adaboost算法分类效果不佳时,则使用FP-growth算法辅助评分,尽可能提高机器学习模块的准确性。
本文在综合国内外研究的基础上,针对目前市场上SQL注入防御系统部署繁琐、误报漏报率高、效率难以满足在线检测的情况,提出一种基于随机森林算法的SQL检测模型,该模型区别于传统的SQL注入检测模型,该模型的最大优点在于不用写千变万化的规则,降低了误报的可能。实验结果表明本文提出的方法的检测性能优于当前其他机器学习模型。
1 随机森林模型
随机森林方法最初于2001年提出,其通过重复采样技术从原始训练样本数据集中随机提取k个样本生成n个新的训练样本数据集,对新产生的n个数据集生成n个决策树组成随机森林,测试数据的类别根据随机森林中所有决策树的分类结果总和确定。随机森林是决策树算法的一种改进,它结合了多个决策树。每棵树的建立取决于独立提取的样本。森林中的每棵树都具有相同的分布,分类错误取决于树的分类能力和它们之间的相关性。特征选择使用随机方法分割每个节点,然后比较在不同情况下产生的错误。单个树的分类能力可能很小,但在随机生成大量决策树之后,可以通过每个树的分类结果选择测试样本以选择最可能的分类。
基于决策树构建随机森林分类模型,随机森林模型对数据适应度非常高,基于大数据的训练效率高,能进行分布式的并行計算,且能够处理非常高维的数据,对于较稀疏的数据集也能很好地适应,因为引入随机性较多,基本不会过拟合。而在决策树中较为核心的方法为随机采样和特征分裂。随机采样使用了行列采样的方式,行为有放回的重复采样,列为无放回的采样方式。重复采样过程形成采样数据集,包含两部分数据,分别是训练数据集和评估数据集。
随机森林选择最佳的特征进行分裂时选择信息增益进行选择。因此信息增益在随机森林中是非常核心的一个步骤。信息增益计算如下:
info(D)=pilog2pi
gain(A)=info(D)-info(Dj)
其中,D为训练数据集,A为划分的属性,m为D的分类数目,pi为分类i的概率,j为基于A属性的v个不同取值。
2 基于随机森林的SQL注入识别
2.1 数据预处理
数据预处理的目的一方面是为了提高数据的质量,另一方面也是为了适应所做数据分析方法,在本文SQL注入识别中,除了常规的数据清洗、集成、变换、规约,还应包括如下两个预处理过程。
2.1.1 编码处理
URL(Uniform Resource Locator)是分析SQL注入的重要数据源,URL通常会被进行Base64编码、HTTP编码处理,因此进入模型提取特征之前需进行解码预处理。
2.1.2 信息提取
完成解码后,考虑到攻击通常只会出现在URL中的特定位置,以此继续对URL进行有效信息提取,提取主要考虑:
(1)首先删除URL域名。
(2)如域名后的URL是key-value形式(以多个“&”分隔),则只对vaue部分进行提取。
(3)对URL中可能出现的注释进行删除。
2.2 特征工程
特征工程是机器学习重要环节,直接影响到算法的检测结果。本文通过观察常见的SQL注入和正常的URL之间的区别,设计出以下4大类特征(常规特征、g检验特征、特殊符号特征、关键词特征),共计24种特征。
2.2.1 常规特征
(1)Parsed_len:使用sqlparse尝试SQL语句解析,看解析结果是否包含有效的SQL语句。
(2)Entropy:计算整个URL的信息熵,信息熵的计算公式为:
H(x)=-p(xi)log2 p(xi)
其中,x表示随机变量,与之相对应的是所有可能输出的集合,定义为符号集,随机变量的输出用x表示。p(x)表示输出概率函数。变量的不确定性越大,熵也越大,信息量也越大。
(3)Paren_match:计算URL中不匹配的括号个数。
(4)quotations:计算URL中不匹配的引号的个数。
2.2.2 G检验特征
(1)Gtest_mal:计算一个解析之后的Token属于反例的G检验值。统计n-gram(这里我们n取3)组成所属于的类别,然后统计出n-gram之后每个Token总的出现的次数,这里定义为t,然后在统计正常的数目,这里定义为g,计算n-gram划分之后每一个Token分别属于正常的数目和异常的数目记为,P=G*t。数据集总共的条目定义为T,然后得到一个“经验”e=P/T,那么具体的一个Token的得分就可以描述为:g_score=2.0*I*math.log(I/e),一个SQL语句通过解析,在通过3-gram就会得到多个Tokens,然后分别计算每个Token的值,然后取均值:sum(g_scores)/len(g_scores)。
(2)Gtest_leg:和Gtest_mal相似,不同之处在于统计Token总的出现为恶意的次数。
2.2.3 特殊符号特征
(1)pattern_symbols:计算URI(Universal Resource Identifier)中特殊符号的数量。
(2)pattern_funcs:计算URI中特殊函数的数量。
(3)pattern_encodes:计算URI中包含的特殊编码的数量。
(4)pattern_puncs:计算URI中包含的特殊操作符的数量。
(5)pattern_not_keywords:计算非SQL注入的特殊操作符的数量。
2.2.4 关键词特征
把解码后的数据去掉特殊字符,去掉多余的空格后用sqlparse解析,解析后的每个单词对应不同的repr_name,具体包括如下五类:
(1)把keyword分为4种类型,不同的词对应不同的权重,把相对重要的词归为一类,相对不重要的词归为不同的类。
(2)把Identifier分为2种类型,Sqlparse模块解析单个Token后,认为无用的词被划分为Identifier,但其中包含很多SQL中的关键词。提取关键词,把相对重要的词归为一类,相对不重要的词归为另一类。
(3)Case类型中还包括完整的SQL语句,提取单个Case语句后,再单独解析里面的SQL关键词。
(4)Where类型中可能还包括完整的SQL语句,因观测样本较少,暂未对Where语句做更多的关键词提取。
(5)Irregular_count:计算URL中大小写不规范词的数量。
2.3 算法
在数据预处理和特征工程后,就能采用随机森林进行SQL注入识别,基于决策树构建随机森林分类模型的算法流程如表1所示。
基于随机森林模型进行K折交叉训练,最终确定模型参数并将生成模型,进行下一步的模型預测。模型由默认的10棵树组成,训练数据和测试数据按照60%比40%划分。
3 性能测试与分析
3.1 数据来源
3.1.1 训练与验证数据
正样本包含一个数据文本samples.txt,共计1594996正例样本。负样本包含三个数据文本,共计215920负例样本。正样本数据明显高于负样本数据,采用欠采样的方式平衡数据集,平衡后的数据按照6:4的比例划分为训练集和测试集。
3.1.2 测试数据
测试数据分为漏报率测试数据和误报率测试数据。误报测试数据包括10余个数据文本,共计2785测试样本。误报测试数据包括14011000误报日志等5个数据文本,共计9245测试样本。
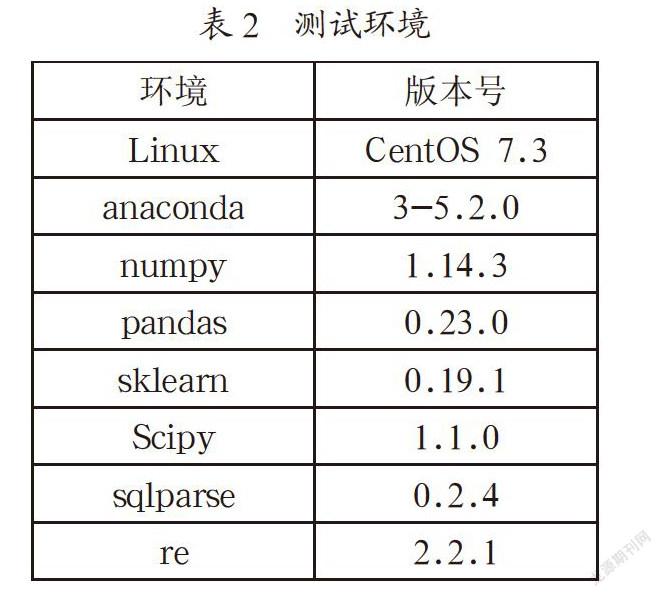
3.2 测试环境
在数据分析和模型建立之前需要搭建一套完整的环境,供测试和开发使用,需要对环境中各个软件和包进行说明。具体见表2所示。
3.3 模型调优
本文采用sklearn中的RandomForestClassifier类来实现随机森林模型,其含有大量可调参数,主要包括如下参数:
(1)max_features:RF划分时考虑的最大特征数。
(2)max_depth:决策树最大深度。
(3)min_samples_split:内部节点再划分所需最小样本数。
(4)min_samples_leaf:叶子节点最少样本数。
(5)min_weight_fraction_leaf:叶子节点最小的样本权重和。
(6)max_leaf_nodes:最大叶子节点数。
(7)min_impurity_split:节点划分最小不纯度。
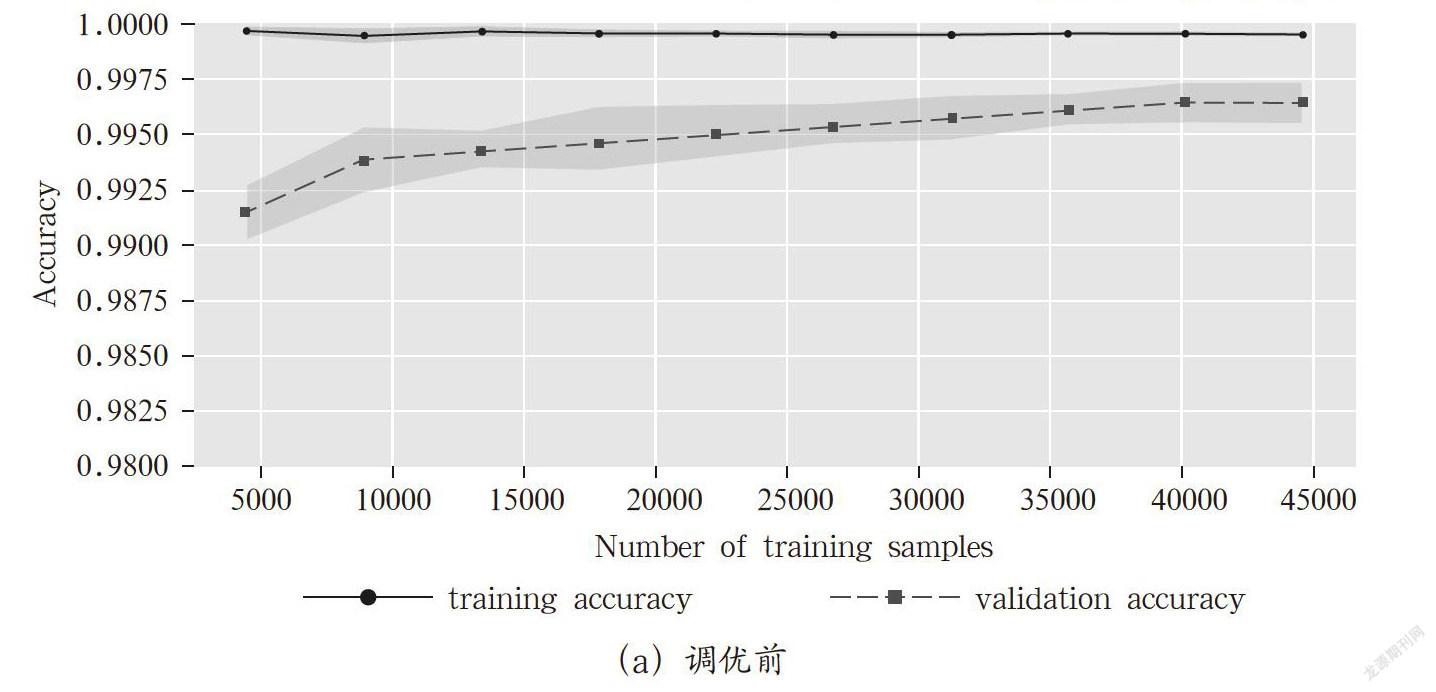
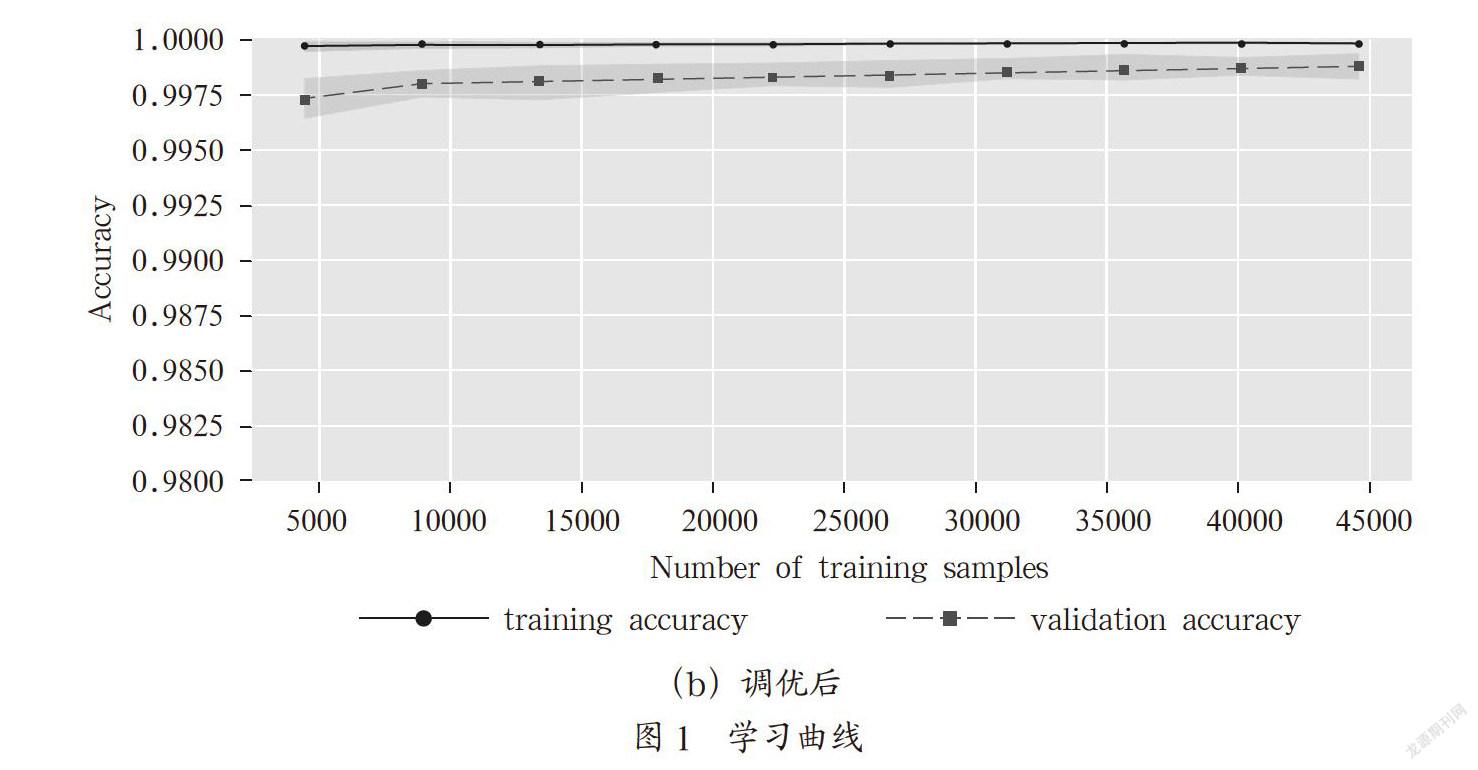
本文使用网格搜索对上述每个参数进行调优,调优前和调优后的学习曲线分别如图1所示。可见调优后,训练集和验证集的准确度都相差不大,在现有的数据集上已经相对减小了过拟合现象,提高了模型的泛化能力。
3.4 测试结果
本文采用漏报率、误报率指标分析各个算法的SQL注入识别性能。误报率和漏报率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价检测结果的质量。其定义如下:
误报率:FN/(TP+FN)
漏报率:FP/(FP+TN)
其中:
TP:预测为正,实际为正的样本数;
FP:预测为正,实际为负的样本数;
TN:预测为负,实际为负的样本数;
FN:预测为负,实际为正的样本数。
本文和近几年SQL注入检测的算法精度进行对比,比较结果如表3所示。
由表3可见,和其他方法相比,本文所使用的随机森林方法准确率最高,且漏报率和误报率最低,证实本文方法在SQL注入识别上的有效性。
4 结 论
本文使用随机森林算法做SQL注入检测。在随机森林算法建模前,加入Base64解码函数和HTTP解码函数,规范了数据集,减少了噪声对数据的干扰。特征构建过程中,通过一边训练模型一边观测模型效果和数据集的方式,最后将特征分为4大类,24种小类的特征进行模型训练。
相比其他算法,随机森林算法在大数据集上有着很大的优势:由于特征子集在算法中是随机选择的,每次训练不同的模型,选取的特征都不一样,能够处理很高维度的数据并且不用做特征选择;模型的泛化能力强,对于不同的噪声数据有着很好的区分能力;训练速度快,容易做成并行化方法。实验表明本文所提方法具有较高的准确率,且漏报率和误报率较低。
参考文献:
[1] 罗丽红,柯灵,杨华琼.web安全之SQL注入漏洞及其防御 [J].网络安全技术与应用,2017(11):81-82.
[2] 万欣.网络日志在网络信息安全中的应用 [J].网络空间安全,2018,9(3):78-81.
[3] 刘祎璠.基于静态分析的SQL注入漏洞检测方法研究 [D].长沙:湖南大学,2015.
[4] 郑彦,蒋磊.基于机器学习的SQL注入检测技术研究 [D].南京:南京邮电大学,2017.
作者简介:陈拥华(1971.08-),男,汉族,四川安岳人,工程师,工学学士,研究方向:网络安全、人工智能。
