会话推荐系统
2019-09-09赵海燕赵佳斌陈庆奎
赵海燕,赵佳斌,陈庆奎,曹 健
1(上海理工大学 光电信息与计算机工程学院 上海市现代光学系统重点实验室 光学仪器与系统教育部工程研究中心,上海 200093)2(上海交通大学 计算机科学与技术系,上海 200030) E-mail:17702181056@163.com
1 引 言
作为解决信息过载[1]的主要工具之一,推荐系统得到了广泛的应用.推荐系统能在没有明确用户意图的情况下,帮助用户发现有价值的信息,对于物品而言,它也在一定程度上能够适应长尾效应现象[2].在应用需求的推动下,个性化推荐系统成了学术界和工业界热门的研究方向.基于会话的推荐系统(Session-based Recommender system)是个性化推荐系统的一个重要组成部分.
推荐问题通常被抽象成矩阵填充/重构问题[3],主要的思想是对用户-评分矩阵中的缺省值填充预测,随后进行协同过滤计算.这样的抽象方法适合训练有用户长期偏好的模型,然而很多情况下用户的信息和过去的行为是不可知的:1)在许多电商网站进行购物是不需要用户认证的;2)用户访问在线流媒体网站时很少有登录的习惯,匿名的方式占到了绝大多数;3)用户的兴趣和意图是不断变化的,长期用户的兴趣和意图是不断变化的,长期配置文件只能反映用户的一般偏好,无法及时更新推荐策略以适应这种变化,利用短期会话信息能弥补这样的不足.当用户的长期配置文件不存在时,就需要根据用户和站点交互的会话日志来做出推荐.这种仅依赖于用户当前进行的会话中的动作序列来预测用户下一个动作的问题被称之为基于会话的推荐.其中会话(session)指的是在给定时间内发生的用户与站点的交互,利用会话日志进行推荐主要的优势是能够推断新用户或者匿名用户的喜好.对于老用户,根据他的当前会话,推荐系统能够调整推荐策略适应用户的兴趣变化进而提升推荐效果.研究表明短期意图对推荐系统准确性的影响要大于用户的长期偏好[4].
目前,基于会话的推荐主要的算法包括:使用序列模式挖掘技术来预测用户的下一个行为,基于马尔可夫模型的方法,以及基于深度学习中的循环神经网络的方法.
2 与其他推荐方向的关系
在推荐的过程中,推荐系统不仅要考虑用户的长期兴趣,同时也应该结合用户当时所处的环境、短期意图、兴趣变化等额外的信息.文献[5]提出了上下文感知推荐系统的概念,将上下文信息融入到推荐系统中,从而将传统的“用户-物品”的二维评分效用模型扩展成了包含上下文信息的多维评分效用模型[5,6].
依据上下文的不同形式和内容,可以将上下文感知推荐系统进行不同的分类.本节中将对序列感知推荐和时间感知推荐作对比.
基于会话的推荐系统是序列感知推荐系统(sequence-aware recommender system)的一个分支,而序列感知推荐是指用户的上下文信息呈现出一种序列形式.根据不同的应用方向,序列感知推荐可以划分为4个类别:交互上下文情境适应、趋势发现、重复推荐和考虑顺序约束.
在诸如电子商务网站、在线流媒体网站的推荐中,用户当前的状态、情绪被称作是用户交互上下文[7].用户意图是由可观察的和不可观察的两种上下文信息共同驱动的[8].用户当前的情绪由于不能经直接观察得出,所以通常的做法是根据用户的近期行为和整个社区的行为模式分析得出.根据长期交互日志和短期交互日志所占的比重,又可以分为以下3种情况:
1)基于会话的推荐系统:这种情况下,只有用户的短期会话活动是已知的,即用户与系统之间的交互是被限制在有限的时间段内,只考虑用户的短期行为.推荐系统从会话点击中获取信息,主要针对新用户和匿名用户,典型的应用有视频推荐[9]、新闻/音乐推荐[10,11],在线的流媒体网站用户很少会注册登录访问,大多数用户都是以“游客”的方式观看收听,电商网站[12]会有源源不断的新用户进入,需要根据用户短期的交互会话做出推荐.
2)会话感知推荐系统:在这类问题设置中,知道用户最近会话行为的同时,还有了解用户的一般偏好或者过去的交互.主要是针对的是那些“回头客”,推荐系统不仅考虑了用户当前会话行为同时结合用户长期配置文件.长期兴趣推荐用户最终会购买的物品不考虑何时购买,短期会话考虑用户当前即时需求,预测近期甚至是下一个即将选购的商品,对两种不同的用户信息设置适当的权重[13].主要的应用有电子商务网站[14]和手机应用推荐[15]等.
3)基于最后N个交互的推荐:只考虑最后N个用户行为的推荐系统被称为基于最后N个交互的推荐系统.主要的应用是在基于位置的社交网络推荐,包括连续兴趣点的推荐[16-18]和音乐推荐[19].
时间感知推荐系统是将“时间”这一重要的上下文信息纳入到推荐系统中.在Netflix竞赛中,时间感知推荐系统开始受到人们的关注,通过时间因素发现用户兴趣的周期性变化[20],将原本的用户和物品的二维矩阵扩展到带有时间信息的高维矩阵,进而提高推荐结果的个性化和准确性.时间是动态变化的,伴随季节的更替及时间的流逝,用户和物品的关系也呈现出动态变化的特性.时间对推荐结果的影响主要体现在:1)用户的兴趣偏好会随时间变化;2)物品通常有自己的流行周期;3)时间本身的周期性,比如冬去春来、四季更替.与时间感知推荐系统相比,基于会话的推荐系统关注的重点是近期用户行为发生的顺序.而时间感知推荐系统往往考虑用户过去行为的时间信息,关注事件发生的时间点.
表1 与上下文感知推荐其他方向的关系
Table 1 Relationship with other context-aware recommendation approaches
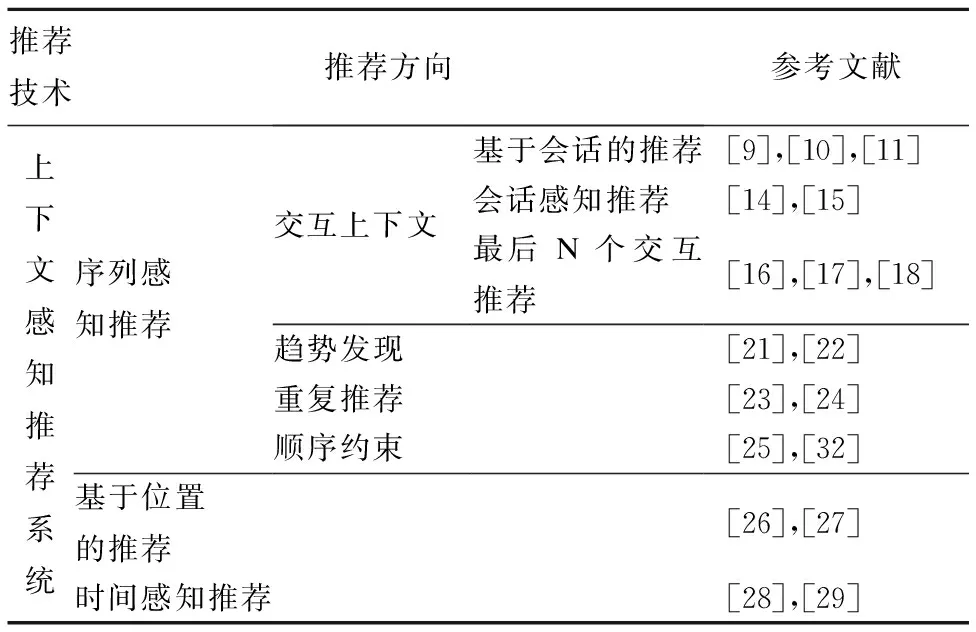
推荐技术推荐方向参考文献上下文感知推荐系统序列感知推荐基于位置的推荐时间感知推荐交互上下文趋势发现重复推荐顺序约束基于会话的推荐会话感知推荐最后N个交互推荐[9],[10],[11][14],[15][16],[17],[18][21],[22][23],[24][25],[32][26],[27][28],[29]
基于会话的推荐与其他推荐方向的关系如表1所示.
3 基于会话的推荐技术
推荐算法是推荐系统的核心,通过理解用户和物品以及物品和物品之间的关系向用户推荐新物品.推荐算法可以是基于长期偏好和短期兴趣,举例来说前者就是向特定的用户推荐特定的物品,而后者则是在购买了电脑主机后推荐相应的外设产品.
传统的推荐算法主要有协同过滤算法(collaborative filtering,简称 CF)、基于内容的推荐算法(content-based filtering,简称 CB)和混合推荐算法(hybrid filtering),旨在捕获用户长期偏好.协同过滤算法[30]主要通过分析用户对物品的偏好,发现物品之间的关联性,或者用户之间的关联性,然后再基于这些关联性进行推荐.协同过滤算法可以分为基于邻域的协同过滤和基于模型的协同过滤.基于邻域的协同过滤算法包括了基于物品的协同过滤和基于用户的协同过滤.前者把与目标用户喜欢的相似的物品推荐给目标用户,后者把同目标用户相似的用户所喜欢的物品推荐给该用户.基于模型的协同过滤是通过评分矩阵构建的模型来预测用户对物品的喜好程度,包括矩阵分解(Matrix Factorization)、监督学习(Supervised Learning)、非监督学习(Unsupervised Learning)等机器学习模型都被运用于基于模型的协同过滤.基于内容的推荐算法[31]是根据用户已经选择的对象,从推荐对象中选择其他特征相似的对象作为推荐结果,推荐过程中不考虑用户的其他模型,推荐效果依赖于特征工程的好坏.混合推荐算法按照不同的策略[32]将不同推荐类型或推荐算法进行组合并生成推荐,主要的做法是结合协同过滤推荐算法和基于内容的推荐算法[33,34].以上的方法都需要分析用户过去的兴趣偏好,使用的前提是识别用户,即需要创建用户配置文件跟踪用户.用户对物品的反馈包括显式反馈和隐式反馈[35],显式反馈主要反映为评分和评论,用户以一种明确且量化的方式来表明自己对物品的态度.而隐式反馈通常是购买历史、收藏夹、点击序列等,这类信息是用户在使用的过程中留下的自然行为,系统无法直接识别喜欢与否,需要推荐系统从中“揣摩”出用户偏好.
协同过滤和矩阵分解这样经典的推荐算法在预测用户评分问题上表现优异,但不适用于基于会话的推荐,主要原因如下:
1)存在大量的匿名用户和新用户,这个群体过去的行为和用户信息对系统而言是无法获取的即用户对物品的评分矩阵不存在;
2)会话信息是短期内用户的行为序列包括:购买、查看、点击、收听等,它是一种隐式反馈信息,难以量化度量;
3)很多用户都是“沉默的大多数”,在购买或者查阅后不会做出评价;
4)会话中即便存在显式评分,这样的评分也往往是滞后的.实现基于会话推荐主要方法有以下几类:频繁模式挖掘、最近邻、马尔可夫模型与强化学习和基于循环神经网络的方法.
基于会话的推荐问题可以表示为序列预测问题:设{x1,x2,…xn-1,xn}为一个点击会话,其中xi(1≤i≤n)是m个项目总数中点击项目的索引,输出对象y=M(x),其中y=[y1,…,ym]′∈Rm,将y视为对该会话中可能发生的所有下一个项目的排名,其中yi对应于项目i的得分.通常的做法是按照yi进行排序,根据需求取前k个项目.
3.1 频繁模式挖掘
频繁模式指的是频繁出现在数据集中的项集、序列或者子结构.例如在购物时分析哪些商品是经常被同时购买的,经典的案例就是“啤酒和尿布”,20世纪90年代的沃尔玛超市工作人员通过数据分析发现“啤酒”和“尿布”经常会出现在同一次购物中,将二者放在一起后,两样商品的销量都有显著的提升,主要的文献有[31,32,33,36]等.
文献[36]提出了逐项协同过滤推荐算法,该算法能扩展到海量数据并生成高质量的推荐.算法维护了一张相似项目表,寻找与用户购买物品及评分相似的物品做聚类,然后选出其中最受欢迎或者相关的一个.其中设置物品相似矩阵可作对用户会话预处理,把会话中经常一起点击的项目做相似项处理.在基于会话的推荐时,使用相似矩阵根据用户当前的点击项目做出推荐[37].缺点是只考虑用户最后一次的点击而忽略之前的行为信息,无法整合序列信息.然而会话中的上下文信息有助于发现用户当前需求,需要根据以前的点击项与当前会话中的相关性给出相应的推荐[38].
序列模式挖掘技术在识别频繁模式时会考虑到会话中行为的顺序性[39],将相同顺序出现的物品视为一种模式.文献[40]提出了基于个性化序列模式挖掘的推荐框架,强调了在顺序挖掘中兼顾用户的个性化.顺序模式挖掘技术在下一项(next-item)推荐中的主要思路是:许多用户在访问了项目i后接着访问j,则向刚访问了项目i的用户推荐j,这样的做法是可行的.基于这样的思想,可以将顺序模式挖掘技术应用于基于会话的推荐系统.文献[41]发现将用户访问网站的历史信息做更细粒度的划分并不能产生很好的个性化效果,进而提出了一种基于点击流的顺序和非顺序模式挖掘的可扩展框架用来预测用户下一个即将访问的网站.该框架包含了频繁项目集和序列模式两种数据结构能满足实时推荐的需求.在预测方面,更多的限制模式[42]如连续顺序模式有更好的效果,在个性化方面,一般顺序模式和频繁项集是比较有效的方案.文献[52]认为网站的结构特征例如拓扑结构、连通及动态生成程度对Web推荐中使用的顺序和非顺序模型会有显著影响,因而提出基于关联规则的个性化推荐框架来挖掘访问历史记录中的顺序和非顺序模式.文献[42]提出了一种MASP(移动应用程序序列挖掘)的方法来预测用户下一个即将使用的app,把用户的最近位置和最近使用的app作为预测的关键.MASP算法通过位置的变化和app的启动发现应用程序的顺序模式,创造性地结合了用户位置路径和app使用的虚拟路径,以最大支持度的方式选出下一个app.
3.2 k最近邻(K Nearest Neighbors,KNN)
基于邻域的方法[37,44]是利用物品和用户行为之间的相似性,通过比较用户会话的相似性应用于基于会话的推荐系统.k最近邻是一种分类算法,核心思想是对给定的一个物品能用与它最接近的k个邻居来表示.kNN的方法根据当前会话中的用户行为在训练集中寻找k个最相似的会话.基于最近邻的方法主要有两类,分别是基于物品的kNN和基于会话的kNN.
基于物品的kNN把与当前会话中最后一项在其他会话中共现的那些项中最相似的那一个作为输出.两个事件在不同的会话中频繁共现,那么我们认为这两个事件是相似的.一般采用余弦相似度,不容易受到流行度偏差的影响.为了能够较快做出响应,系统会提前计算所有项目的相似性,常用于电商[45]和音乐推荐[46].
基于会话的kNN在考虑当前会话中最后一个点击项的同时也会比较整个会话与其他会话的相似性,综合两者做出合理的推荐[47].受到在线推荐中时间的限制,需要预先处理训练会话集并在启动时创建内存索引数据结构(缓存)[48].
kNN的方法虽然简单,但十分有效,特别是在准确率方面有着不错的表现[49,50],常被用于目前十分流行的基于循环神经网络模型的对照方法[48,51].
3.3 马尔可夫模型和强化学习
马尔可夫模型是一种统计模型,在自然语言处理和生物基因序列分析领域有着出色的表现.其中马尔可夫过程是指过程中每个状态的转移只依赖于之前的n个状态,这个过程被称为n阶模型,其中n是影响转移状态的数目[52].一阶马尔科夫过程,即每个状态的转移只依赖于前一个状态,是最简单的马尔科夫过程.推荐是一个连续的过程[53],基于会话的推荐问题可以转化为有序序列预测问题,如此便可使用马尔可夫决策过程(MDP)这一顺序决策的随机模型.马尔可夫链(MC)是时间和状态都是离散的马尔科夫过程,能够捕获用户点击会话中的顺序模式.MC模型通过转化图的方式对用户会话中的顺序行为建模来预测用户的下一个行为.由于数据的稀疏性,马尔可夫链通常无法直接使用.文献[54]用隐马尔可夫模型来克服MC的缺陷.文献[55]采用了可分解个性化马尔可夫链(FPMC)的方法结合一阶马尔可夫链和矩阵分解的优点来模拟个性化顺序行为,在稀疏和密集数据上的表现均优于MF和MC.文献[56]进一步在FPMC的基础上,针对稀疏性问题和数据的长尾分布,采用用户长期偏好和当前会话中的顺序行为的方法来表示用户,例如在电影推荐中,用户的一贯偏好是科幻片,但是在他观看了哈利波特I之后应该向该用户推荐哈利波特II.马尔可夫链在提取用户短期偏好方面有着良好的表现,但是,受马尔可夫链特性的限制即下一个动作仅依赖于有限个先前的行为.文献[56]用基于相似性模型(FISM)来弥补这个缺点.文献[57]提出混合变量记忆马尔可夫模型(MVMM)来预测用户下一项感兴趣的项目,并选择N-gram模型作为基准模型.
马尔可夫决策过程(MDP)则是对马尔可夫链的扩展,它结合了马尔可夫过程和确定性动态规划的最优策过程,具有马尔可夫性(无后效性)[58].MDP有两大优势:
1)考虑了每项推荐的长期影响;
2)考虑每项推荐的预期价值.例如在歌曲推荐方面,系统会监测用户对所推曲目的反映,是收听还是跳过,从而设立奖励机制.
文献[59]首次使用马尔可夫决策过程对顺序数据推荐问题进行建模,用到了强化学习的方法来学习最优策略.文献[60]利用强化学习对MDP中的显式偏好和隐式反馈进行利用和组合.
3.4 基于循环神经网络的方法
前期的研究[61,62]成功地将循环神经网络(RNN)应用在序列数据建模问题.RNN是一种具有非线性动态特性的分布式隐状态模型[63],可以有效地模拟整个用户交互会话(点击、查看),能对会话建模以发现其中的主题思想,是基于会话推荐问题的自然选择.
文献[51]首次将循环神经网络(RNN)应用于推荐系统,不仅证明了RNN能应用于基于会话的推荐问题,而且针对基于会话推荐的这项特定任务,设计了带有GRU(Gated Recurrent Unit)的RNN模型(GRU4REC).在训练RNN时采用了排名损失(ranking loss)旨在将模型的关注点集中到用户可能感兴趣的顶级项目上.在两个不同数据集上的实验结果也表明采用了RNN的策略相较于以往的方法,推荐效果有了明显的改进.文献[48]进一步认为文献[42]中的GRU4REC方法的有效性问题没有得到解决,故通过使用基于会话的kNN结合启发式的手段对合适近邻进行采样,验证了GRU4REC方法的真实有效,发现RNN方法确实能够捕获kNN方法无法识别的数据中的序列模式.文献[64]又提出了在GRU4REC上引入四条优化方法,包括数据增强技术、设置时间阈值来适应变化、使用特权信息(关于点击项目的属性)和输出嵌入.文献[65]中则通过排名损失函数对RNN进行优化.
用户的会话点击不仅有序列特征,通常还有项目的文本和图像特征,文献[9]探究了融合项目属性特征的RNN框架p-RNN(并行RNN),它根据点击会话和点击项目的特征进行联合会话建模,框架的输入是项目ID和项目特征,输出是下一个点击项的评分.
用户在浏览的过程中,在某一物品上停留的时间长度能从侧面反映出对该物品的喜好程度,是隐式反馈的一种表现形式,停留时间越长则表示越感兴趣,反之亦然.文献[66]探究了这种隐式反馈在会话推荐中的价值,在RNN框架中加入用户在物品上的停留时间,通过设定阈值的方式来判断用户对特定物品的感兴趣程度.
有的情况下,用户会登录或者网站对用户有其他形式的标识,文献[76]便考虑了存在用户信息文档的情况,提出了一种层次化的RNN模型,将存在用户历史信息的处理成会话感知推荐问题,将匿名/新用户处理成基于会话的推荐问题.为了突出在基于会话的推荐中更具个性化这一特性,文献[68]考虑到在商业系统中,用户静态上下文(年龄、性别、位置)是容易获取的,故提出增强RNN模型(ARNN)无缝集成用户静态上下文到RNN中.
表2 不同推荐方法的特点比较
Table 2 Comparison of characteristics of different recommendation methods
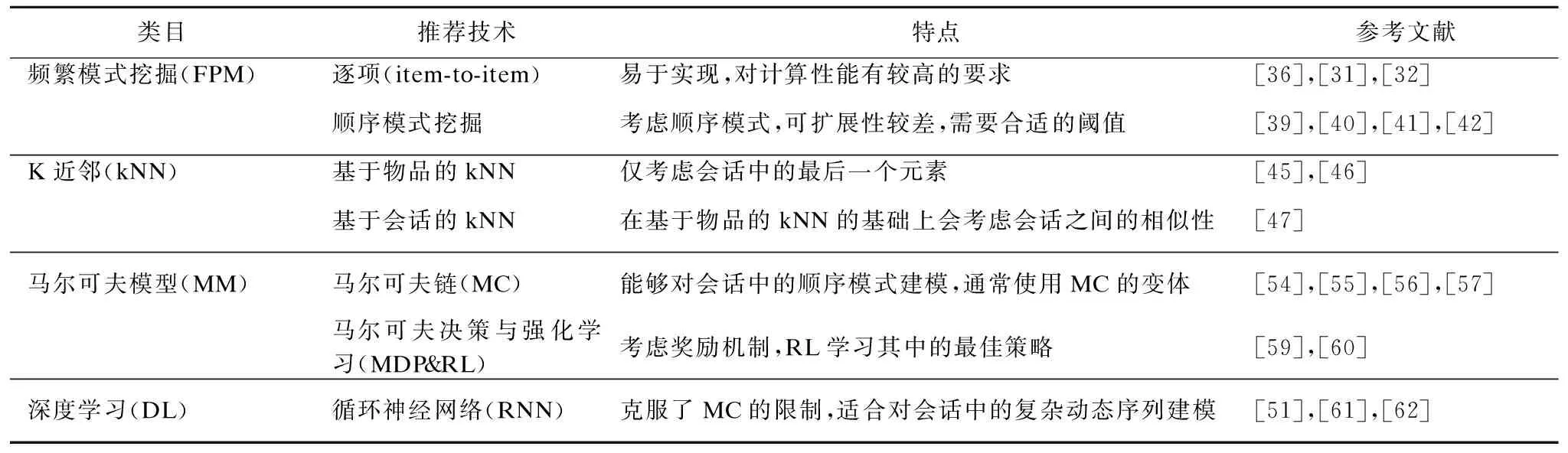
类目推荐技术特点参考文献频繁模式挖掘(FPM)逐项(item-to-item)易于实现,对计算性能有较高的要求[36],[31],[32]顺序模式挖掘考虑顺序模式,可扩展性较差,需要合适的阈值[39],[40],[41],[42]K近邻(kNN)基于物品的kNN仅考虑会话中的最后一个元素[45],[46]基于会话的kNN在基于物品的kNN的基础上会考虑会话之间的相似性[47]马尔可夫模型(MM)马尔可夫链(MC)能够对会话中的顺序模式建模,通常使用MC的变体[54],[55],[56],[57]马尔可夫决策与强化学习(MDP&RL)考虑奖励机制,RL学习其中的最佳策略[59],[60]深度学习(DL)循环神经网络(RNN)克服了MC的限制,适合对会话中的复杂动态序列建模[51],[61],[62]
新闻推荐也是基于会话推荐的重要应用方向,它更关注消息的时效性和新鲜度.文献[69]提出一种新的基于循环神经网络的架构,以不同的粒度级别来组合长/短期用户偏好,其中长期用户偏好代表了用户稳定的兴趣,而短期偏好则代表了用户当前的需求.基于会话推荐的不同方法之间的特点如表2所示.
4 数据集和评价指标
4.1 数据集
在研究中,经常使用的含序列特性的数据集主要来自3个领域,分别是电商、音乐和新闻.以下简单介绍几个常用的数据集: RecSys Challenge 2015的数据集(1)http://2015.recsyschallenge.com/,主要内容是某个用户在访问电子商务网站的会话期间执行的一系列点击事件.数据包中包含训练数据和测试数据,训练数据有两个文件:点击事件yoochoose-clicks.dat和购买行为yoochoose-buys.dat.点击事件包括:会话ID;时间戳;商品ID;商品类别.购买行为包括:会话ID;时间戳;物料ID;价格;数量.测试文件与点击事件文件结构相同.这些数据是在2014年的几个月内收集的,反映了某欧洲在线零售商中用户的点击和购买情况.
Amazon数据集:来自Amazon.com(2)https://www.amazon.com/,是最大的数据集之一,其中包括1996年5月至2014年7月的评论文本和时间戳.其中不同类别的产品构建为不同的独立数据集[70],该数据集包含近600万个对象,超过1.8亿个关系.这些关系是用户访问亚马逊网站并记录其提供的产品推荐的结果.
30MUSIC和NOWPLAYING:30MUSIC数据集是来自last.fm(3)http://www.last.fm/api互联网广播电台的收听历史,包括含有时间信息的收听会话、播放列表和部分用户的评分[71].NOWPLAYING(4)http://www.nowplayingplugin.com数据集是依赖于Twitter创建的有关用户音乐收听行为的数据集并不断更新[72].
4.2 数据集的划分
在传统的基于矩阵填充的推荐问题中,划分训练集和测试集一般采用随机抽样的方法遵循互斥的原则.对于会话感知推荐系统应该采用会话级别的划分方式避免分离单个用户的会话;在社区级和用户级的划分中,应当优先选择用户级的划分手法,如此可以保证向新用户提供求推荐[73].
4.3 评价指标
不同于传统推荐系统要求的输出目标为一个/组物品的按评分高低的排序,基于会话的推荐问题的目标是预测当前会话下用户的下一个动作,具体表现为购物中下一个要购买的商品,收听会话中下一首想播放的曲目等.数据有序列性即无法将会话事件随机分配给训练集和测试集,所以使用滑动窗口的方式来替代原本的交叉验证方法[48].使用的评价指标主要包括命中率(HR)、准确率(Precision)、召回率(Recall)、和平均倒排序值(MRR)[48,76,64].
文献[74]认为对于预测下一项的问题,命中率能够反映该推荐系统的性能,因为我们只关注是否找到了合适的项目.
(1)
其中分母|GT|是所有的测试集合,分子NumberofHits@K是每个用户top-K推荐列表中属于测试集合的个数的总和.
准确率代表了用户对于系统所推荐商品感兴趣的概率,就是所推荐的物品有多少是准确的[75].召回率表示用户感兴趣的商品被系统推荐的概率即有多少准确的物品被系统成功推荐[75].待预测商品可能存在的四种情况如表3所示.
Ntp表示系统推荐且用户喜欢,Nfn表示系统推荐但用户不喜欢,Nfp表示用户喜欢但系统没推荐,Ntn用户不喜欢且系统没推荐,L为推荐列表长度.Bu是测试集中用户u喜欢的商品数,则准确率和召回率定义为:

(2)
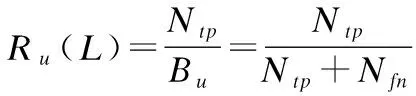
(3)
表3 待预测商品有四种可能的情况
Table 3 Four possible scenarios for the goods to be forecasted

用户喜好系统推荐系统不推荐喜欢NtpNfn不喜欢NfpNtn
MRR是把准确推荐项在推荐系统给出结果的排序位置的倒数作为它的准确度,再对所有的问题求平均.
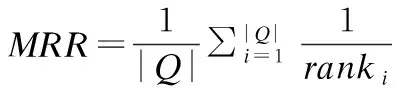
(4)
其中|Q|是查询个数,ranki是对第i个查询,第一个相关的结果所在的排列位置.
5 未来研究方向
伴随智能手机的普及,人们喜欢利用碎片化的时间通过手机进行各种操作,如浏览新闻、阅读文章、选购商品等.手机上的应用更适合于基于会话的推荐,因为相对于PC端,手机用户在某一时间内总是在一个应用中进行操作.由于手机上的传感器较多,因此能够获取更多的上下文信息(地点、用户的运动状态甚至用户的情绪),所以在移动端,结合上下文信息进行基于会话的推荐是未来的应用方向.
为了能够更好地获取用户需求,需要引入多种类型的数据,甚至包括声音、图像、视频、各种传感器信息.如何融合这些异构的多元数据提高会话推荐的准确性将是重要的方向.
人们的选择从根本上其意图的体现.用户不同的行为可能反映用户不同的需求和意图,例如在访问电商网站时会有搜索、查看、加入购物车、添加愿望清单等操作,如何综合考虑不同行为的效果从而进一步揣摩用户意图,并将意图与偏好相结合,是值得研究人员讨论的问题.
从算法角度看,自从Hidasi B等人[42]创造性地将RNN用于推荐系统以来,由于RNN在利用会话中的顺序信息相较于马尔可夫模型和顺序模式挖掘有着更为突出的表现,RNN成了该问题的“自然选择”,近期许多研究围绕对RNN模型的改进展开,例如考虑特征信息、使用损失函数进行优化[9,56]等.未来的研究可以把RNN模型作为基础,开发新的模型以更好地利用会话中的顺序模式.但是在算法研究中其他深度学习模型也将引入,例如文献[67]提出用卷积神经网络(CNN)来解决会话推荐问题.因此,如何结合不同的场景采用不同的深度学习模型值得研究.
6 总 结
互联网使得人们的各种海量信息都被记录下来.预测用户感兴趣的下一个项目、让用户能够在短时间内快速获取到有价值的内容,能让服务提供商提供有针对性的服务从而提高用户体验,这正是基于会话推荐的任务所在.基于会话的推荐的主要优势是仅依靠用户的短期会话来识别用户偏好,因而对于用户的兴趣变化十分敏感且相较于用户的长期偏好的获取准确性更高.该方法不仅能面向新用户和匿名用户,对于新上线的手机app、电商或是在线流媒体网站,能够根据少量的用户交互信息做出合理的推荐,从而可在短时间内提升访客满意度、网站销售额及点击量.可以预计,会话推荐的研究和应用将会得到进一步的重视.
