融合语义与图结构的短文本特征提取算法
2019-09-09马慧芳刘晓倩伍诗萌
马慧芳,刘晓倩,马 兰,伍诗萌
1(西北师范大学 计算机科学与工程学院,兰州 730070)2(桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004) E-mail:mahuifang@yeah.net
1 引 言
随着信息时代的飞速发展,微博、微信、说说、新闻、团购、邮件、手机短信等大量互联网平台兴起,给人们带来便利的交流环境,同时也将多种形式的短文本数据大量的引入到了人们的日常生活之中.与传统文本不同,这些短文本主要表现为简略的描述说明、观点评论、简单对答或情感抒发等,文本长度一般不超过140个字符.当前社会中短文本的数量多,信息量大,其中包罗了人们对各类社会现象或商品的反映、评价,对众多领域有着非常重要的作用,因此从海量的短文本数据中快速并准确地获取有用的信息,特征提取技术发挥着非常重要的作用[1].
传统的特征提取算法大多适用于长文本,且短文本较之长文本具有信息量巨大、特征稀疏等显著特点,因此提出一种有效的针对短文本的特征提取算法至关重要.现有的短文本特征提取算法可归纳为以下三类:
1)基于统计信息的算法:主要从词频、位置等角度考虑特征词的重要性,常见的算法有TFIDF算法[2,3],N-Gram算法[4]等.杨震等[5]提出一种基于通过词出现间距的内在与外在模式的信息熵差进行关键词排序的方法,该方法认为特征词的出现受话题中的关键词位置的统计特征和文本中话题簇的统计属性两方面影响.已有的工作[6]将同一短文本中两个词语之间的间隔词数作为共现距离[7],计算词语之间相关度进而体现词语间语义关联.但其不足之处在于未考虑到词语间的隐含语义;
2)基于图的特征提取算法:该类算法建立在词频统计基础上,将词语及其语义关系映射到文本结构图,提取出若干重要的顶点即为关键词.刘啸剑等[8]利用LDA主题模型,计算出词与词之间的相似性作为词与词之间的权重,并构建一个带权无向词图,选择短语作为图的节点从而提取出特征词项.该方法的缺点在于仅仅考虑了图的结构,而忽略了像节点属性之类的外部信息;
3)基于语义的算法:采用语义词典或者词汇链方法来获取词汇间的语义知识来提取文本特征词项.该算法提高了提取的准确率,但是依赖于背景知识库、词典、词表等,无法提取出不包含于知识库的词或词组,对文本格式要求严格.
针对现有方法的不足,本文提出一种融合语义与图结构的短文本特征提取算法(Short Text Feature Extraction Algorithm Based on Semantic and Graph Structure,SFESGS),该算法以构造图的方式来表示文本,并利用语义耦合关系以及图结构特征计算词对间的相似度对文本图中的边加权,然后设计一种随机游走的方法将两种边的加权方案有效地结合起来进行迭代计算出节点的重要性,实现对文本特征的提取.最后,本文选取中英文短文本作为实验数据集,对算法进行了验证.实验结果表明,本文所提出的算法可行且有效.
2 相关理论
2.1 词对内部语义耦合
词对内部语义耦合[9]是为了研究词项之间的显式语义关系.假设出现在同一文本中的词语具有共现关系,如果词对的共现频率越高,它们的关联性越强.因此,词项之间的显式关系可以通过它们在所有文本(文本集)中的共现频率进行估计.
定义1.(TPF-IDF)TPF是一对词项出现在同一文本的次数,IDF表示一对词项至少出现一次的文本数,TPF-IDF反映了成对词项在语料库中对一个文本的重要性.其加权方案计算公式如下:
TPF-IDF((ti,tj),d,D)=TPF((ti,tj),d)×IDF((ti,tj),D)
(1)
(2)
其中(ti,tj) 代表一对词项,|D|是文本总数,d是文本集D中一个单一的文本.
对于∀(tk,ti)∈D(k,i∈[1,N],k≠i),可以得出:
(3)
表示词对(tk,ti)在文本集D中的概率,TPF-IDF(tk,ti) 表示词对(tk,ti)的TPF-IDF.
则所有词对中给定词语Ti的概率分布定义如下:
PIa(ti)=(PIa(t1|ti),PIa(t2|ti),
K,PIa(tk|ti),K,PIa(tN|ti))
(4)
定义2.(词对内部耦合)给定一个文本集D,(ti,tj)为文本集D中的词对,则词对(ti,tj)的内部的耦合关系(IaR)表示如下:
IaR(ti,tj)=RS(PIa(ti),PIa(tj))
(5)
其中RS为关系强度函数,本文选择余弦相似度作为关系强度函数来计算词对间的耦合关系.
2.2 图的结构特征
受到文献[10]的启发,顶点的属性不仅可以从外部数据获得,还可以从图的内部结构信息中获得.基于结构特征的相似度计算方法允许将图的结构信息(例如距离两步的邻居顶点的总和)直接建模到属性中以提高性能.对于每个顶点,本文选择了4个内部属性计算词项间的相似度,详见表1.
表1 文本图结构内部属性
Table 1 Internal properties of textual structure

属性说明属性1同配性(同配性=顶点的度邻居顶点度的平均值)属性2顶点的度属性3距离2的邻居顶点数属性4距离3的邻居顶点数
为了避免大数值,本文取所有内部属性的对数值.
3 融合语义与图结构的短文本特征提取算法
本文在语义耦合及图结构特征相结合的启发下,提出了一种融合语义与图结构的短文本特征提取算法.如图1所示.
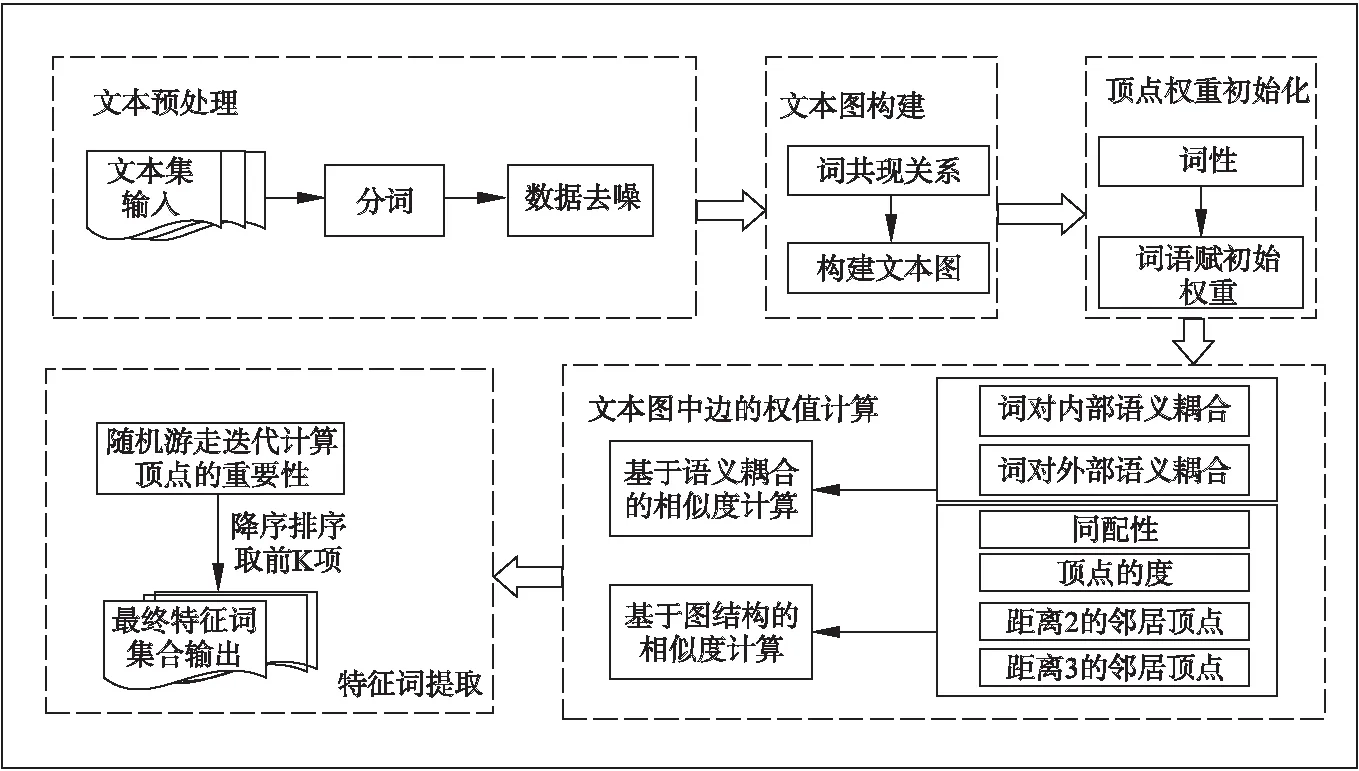
图1 融合语义与图结构的短文本特征提取算法总流程Fig.1 Short text feature extraction algorithm based on semantic and graph structure
首先进行文本预处理,包括分词、词性标注等;然后根据所有邻边规则构建文本图、根据词性对文本图的顶点权重进行初始化;接着利用词语间内部耦合及外部耦合关系以及文本图的结构特征计算词语间的相似度作为文本图中边的权值;最后设计一种随机游走方法将两种边的加权方法有效地综合起来进行迭代提取出文本集的特征词项排序结果.本方法不仅通过语义耦合充分捕获文本词语间表面的和潜在的语义信息,而且考虑到了文本图的结构特征,并将二者有效地结合起来,通过迭代计算得到词语的排名情况.
3.1 文本图构建
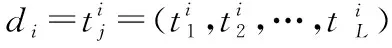
在文本图构建过程中,一个标记对应一个顶点,边定义了标记之间的共现关系.给定一个标记集T来定义图G=(V,E)的顶点和边,其中V={t1,t2,…,tn}表示顶点集,E={e1,1,e2,2,…,ei,j}表示边集.顶点分配是对属性向量进行完整的读取并为每个标记创建一个顶点的过程.本文中,文本图的边根据所有邻边[10]规则进行构建:在一个任意大小的窗口中创建所有能够连接标记的边,即对于给定的某个窗口内的每个标记间都需要创建一个边.同时,这些标记的读取顺序跟它们出现在原始文本中的序列相同.
3.2 顶点权重初始化
构建完文本图之后,需要计算出顶点重要性的权值.SFESGS算法根据词语词性赋予初始权值.
一篇文本中,名词和动词构成了它的核心,它们的简单组合可以作为整个文本的简单表示.另外,形容词和副词对文本内容的表达也起到一定的作用.因此,名词、动词、形容词和副词被视作能表达文本内容的内容词,其中名词和动词的权重大于形容词和副词的权重.词性因子的量化公式如公式(6)所示:

(6)
即当词语为名词或者动词时,则该词初始权重为0.8;当词语为形容词或者副词时,该词的初始权重为0.6;当词语为其他词性时,该词的初始权重为0.
3.3 文本图中边的权值计算
本文提出了两种对边的加权方法:基于语义耦合的词项间相似度计算和基于结构特征的词项间相似度计算,计算得出的词项间相似度即为两顶点之间边的权值.
3.3.1 基于语义耦合的相似度计算
假定一个文本集由边和顶点组成的图来反映词语之间的关系,2.1节中介绍的词对内部耦合仅仅捕获了图中相邻两个顶点间的显式关系,未考虑到全图中其他词语间的相互作用.因此,提出一种基于图论的捕获词项间隐式关系的方法.
对于∀(tk,ti)∈D(k,i∈[1,N],k≠i),有:
(7)
(8)
公式(7)体现了词ti与词tk的相似程度,距离越近,词ti与词tk之间越相似,pL(ti,tk)表示词ti与词tk之间的最短路径.
对于给定的ti其概率分布如下:
PIe(ti)=(PIe(t1|ti),PIe(t2|ti),K,PIe(tk|ti),K,PIe(tN|ti))
(9)
前文中提到词对(ti,tj)的内部耦合关系(IaR)表示如下:
IaR(ti,tj)=RS(PIa(ti),PIa(tj))
(10)
其中RS为关系强度函数,本文选择余弦相似度作为关系强度函数来计算词对间的耦合关系.
定义3.(词对外部耦合)给定一个文本集D,在文本集D中的词对(ti,tj)之间的外部耦合(IeR)表示如下:
IeR(ti,tj)=RS(PIe(ti),PIe(tj))
(11)
词对间内部耦合表征两个词在同一篇文本中的相关性大小,而词对间外部耦合挖掘出两个词不在同一篇文本中出现但可能相关的特性.所以,通过综合词对间的内部耦合和外部耦合,可以充分挖掘出词语间全部的语义信息.文本集D中词对(ti,tj)的语义耦合相似度计算见公式(12).
SCS(ti,tj)=(1-α)×IaR(ti,tj)+α×IeR(ti,tj)
(12)
其中,IaR(ti,tj)和IeR(ti,tj)分别表示词对(ti,tj)的内部耦合关系和外部耦合关系,α∈[0,1]是决定内部耦合关系和外部耦合关系权重的参数.本文α的取值设定为0.65.
SCS(ti,tj)的值在0-1之间,0表明两个词之间是完全没有关系的,1表示两个词是完全一样的,SCS(ti,tj)的值越高两个词之间的相似度越高.
3.3.2 基于图结构特征的相似度计算
基于结构特征的相似度计算过程中,顶点(ti,tj)之间边的权重用相应顶点属性(xi,xj)之间的相似度Sij来表示,Sij>0.
本文选择径向基核函数(RBF)作为顶点属性之间的相似度定义:
(13)
其中正参数γ控制属性距离的影响,RBF核函数相当于先从xi和xj投影的两个无限维矢量的内积φ(xi)Tφ(xj).因此Sij可以捕获xi和xj之间的非线性相似性.
3.4 特征提取
本文提出的特征提取算法是设计一种随机游走方法将3.3节中提到的两种对边的加权方法有效地综合起来进行迭代计算,得到文本特征词项集合排序的结果.
对于已经构建好的文本图G,将顶点间的相似度作为顶点间边的权重,利用语义耦合的方法计算顶点间的相似度得到图G1,利用结构特征的方法计算顶点间的相似度得到图G2,分别计算图G1和G2的转移矩阵P和Q.由于图G1和G2皆为无向图,则将图G1和G2中的边(i,j)可以视为两个有向边(i,j)和(j,i),P和Q为L*L维的矩阵,其中P(i,j)为语义耦合计算得出的相似度,Q(i,j)为结构特征计算得出的相似度.然后进行随机游走迭代计算每个顶点的权值,权值的大小由高到低进行排序,取前k个作为文本集的特征词项集合,则顶点权值计算公式为:
π(t+1)=(1-d)Qπ(t)+dPπ(t)
(14)
(15)
d表示阻尼系数,一般取0.85,起到了平滑整个算法的作用,每一次顶点之间的跳转,都有d的概率按照顶点连接关系继续跳转.
由于本文中图中顶点被赋予了初始权重,因此π0=∂′,∂′为归一化后的∂.πt为迭代t次后的特征词项权重向量.
4 实 验
4.1 实验数据集及预处理
实验数据分别选用了CSCD中的5类共2450篇文章标题作为中文数据集,CCF会议推荐列表中的A类会议与B类会议中的5类共2000篇文章标题,作为英文数据集进行实验.
对数据集进行预处理,包括数据去噪、分词、停用词过滤、词干提取、词性标注等处理.其中,中文分词和词性标注是通过java调用中科院分词系统(NLPIR)的函数来实现,词干提取采用经典的波特算法.本文方法得出的结果以特征词向量形式表示,且采用k-NN和SVM分类器对实验结果进行分类验证.
4.2 评价指标
本文选择F值(F-measure)作为算法的评价指标:
(16)
(17)
其中Pr为精确率,Re为召回率,其计算公式如下:
(18)
(19)
其中,TP、TN、FP、FN分别为真正(事实上是正样本,被判定为正样本)、真负(事实上是正样本,被判定为负样本)、假正(事实上是负样本,被判定为正样本)、假负(事实上是负样本,被判定为负样本).
4.3 实验结果与相关分析
为了验证本文提出方法的有效性,实验主要从以下两个方面进行首先比较本文方法与其他特征提取方法得到的特征词集;然后,将不同方法提取出的特征词集应用到SVM和k-NN分类器中,得到不同算法对短文本分类的结果.
本文选择只考虑语义耦合不考虑图结构特征的特征提取方法、只考虑图结构特征但不考虑语义耦合的特征提取方法以及TKG2|W1|cc[11]方法与本文方法得到的特征集合进行比较,验证使用本文所提出的特征提取算法的有效性.
本文选择以上三种方法作为本文方法的对比方法是基于以下考虑:
1)由于本文方法是通过融合词对语义耦合关系以及文本图结构特征改进而来的,只考虑语义耦合不考虑图结构特征的特征提取方法与只考虑图结构特征但不考虑语义耦合的特征提取方法与本文方法最为相似;
2)TKG2|W1|cc方法也是一种基于图的特征的提取算法,且本文方法构建文本图的规则与文献[11]中TKG2方法的构建规则相同.
4.3.1 特征词典大小对短文本分类的影响
为验证得出的关键词集对短文本分类的影响,本文分别取特征词项集中的前30、60、100、110、130、160、180、200、230、250、280和300个特征词项作为特征词典,并分别利用SVM和k-NN分类器进行测试.SVM分类中采用线性核函数libsvm网格参数寻优对训练参数进行优化,使模型更为契合.k-NN分类器训练模型过程中,特征词典大小一定时,近邻数为80时得到的模型分类性能较好.
为了得出最适合本文的分类器,本文以中文数据集为例对分类器的效果进行比较.由图2所示,本文方法得出的关键词集在SVM和k-NN分类器两种分类器上均可以对短文本进行有效分类且SVM分类器的分类效果更佳,与本文方法更为符合.随着特征词典长度逐渐增加,使用训练出的模型进行分类,准确率和F-measure值先呈现增长趋势后在特征词典数目为200时达到峰值并趋于稳定.使用k-NN分类器训练出的模型分类,准确率和F-measure值呈现出先增长后下降的波动趋势,在特征词典数目为110时达到峰值.
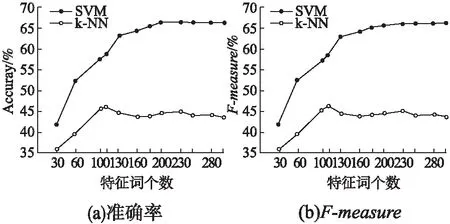
图2 特征词典大小对短文本分类的影响Fig.2 Effect of feature dictionary size for short text classification
4.3.2 特征词典对比
本文将4种特征提取方法得到的特征词典在文本分类任务上进行对比,以此来验证本文方法得到的特征词典的准确性.以处理后的软件工程和通信安全为例,选取前10个词为例,如表2和表3给出了不同算法分别在中英文数据集上抽取出的特征词项.可以看出,KEGS方法得到的特征词典由于未考虑语义信息,效果较差,并不能代表短文本类别特征.KES方法和TKG2|W1|cc算法将词项表示为文本图形式但却都忽略了文档本身所携带的结构属性因素,得到的结果也有待提升.由此可以证明词项之间的语义信息与词语本身的属性特征均不容忽视.显然,本文算法充分考虑了词语间的隐含语义并综合考虑了文本图自身的结构特征,得到的结果相比之下更为合理.
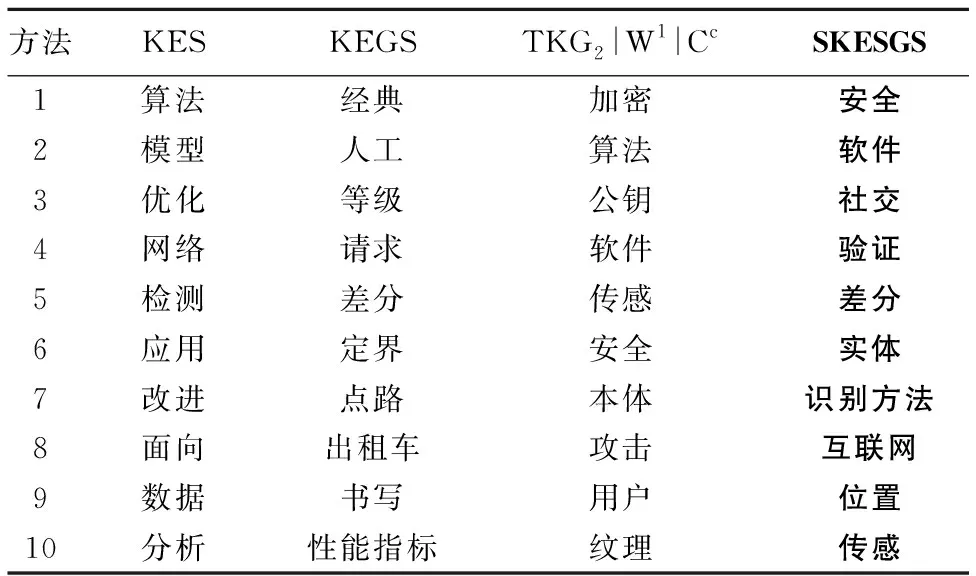
表2 中文数据集上不同算法抽取出的特征词项Table 2 Feature terms extracted by different algorithms on Chinese datasets
表3 英文数据集上不同算法抽取出的关键词
Table 3 Keywords extracted by different algorithms on
English datasets

方法KESKEGS TKG2|W1|CcSKESGS1designtwo-jointactivityattack2networkimpacttopicprobabilistic3baseseminallyelasticcluster4optimalsubpixelopticallive5interactvisual inter-actfemtocellsensor6learnmechanicradioencrypt7datarepetitioncooperativemechanic8analyzetransmittalefficiencydevice9modelnotecomputerlayer10efficiencysphericalfirewallimpact
4.3.3 不同特征提取方法对短文本分类的影响
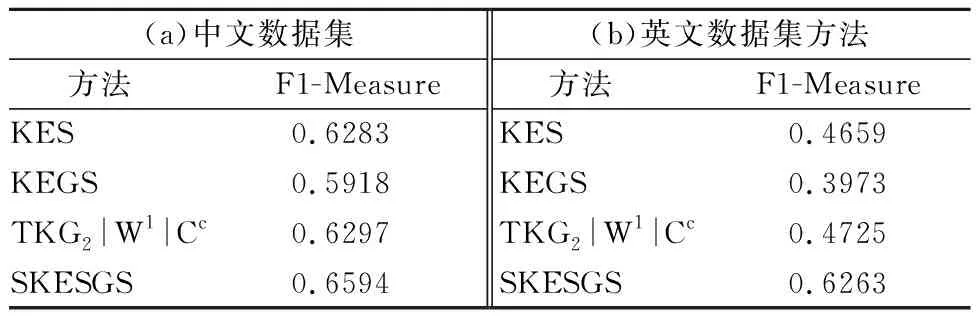
由4.3.1可知,本文方法在SVM分类器上分类效果优于k-NN分类器且在特征词典长度为200时分类准确率最高.故本文选取SVM分类器分别在中英文数据集上进行实验,验证特征词项数目为200时不同方法对短文本分类的影响,其F-measure值如表4.
表4 不同特征提取算法的分类性能
Table 4 Classification performance of different feature extraction method
(a)中文数据集(b)英文数据集方法方法 F1-Measure方法 F1-MeasureKES0.6283KES0.4659KEGS0.5918KEGS0.3973TKG2|W1|Cc0.6297TKG2|W1|Cc0.4725SKESGS0.6594SKESGS0.6263
本文方法在中英文数据集上的分类F-measure值均大于其余3种方法,足以证明本文方法对短文本分类更为有效且适用于多种语言.由此可得,词语之间的隐含语义和文本图中其自身的结构特征对短文本分类的影响较大,且使用本文方法得出的特征词项也更为准确.
5 结束语
针对现有的短文本特征提取算法未充分考虑词语之间的隐含语义以及图的结构特征,本文提出一种新的短文本特征提取算法,即融合语义与图结构的短文本特征提取算法.该方法利用词语间的共现关系和词语在文本集中距离来计算两个词语之间的语义相关度,解决了传统短文本特征提取算法忽略词语间内在语义关联的问题,并结合图的结构特征,使词语间的相关度更为贴切.最后,分别在中、英文数据集上实验,证明该方法提取出的特征词项能对短文本实现有效地分类.
