基于机器学习的地层序列模拟*
2019-09-06周翠英张国豪杜子纯
周翠英 张国豪 杜子纯 刘 镇
(①中山大学土木工程学院 广州 510275)(②中山大学工学院 广州 510275)
0 引 言
地层结构是漫长的地质作用的结果,在时空分布上表现为不均匀、不规则性等,但在宏观上具有统计上的规律性。弄清地层结构及其规律是地质信息化的基础,同时不良地层的分布也是工程建设的重点关注对象。如何利用有限的钻孔资料进行地层结构及分布规律的研究,是地质学与工程地质领域中的重要课题。
地层结构与分布规律的研究,钻孔数据是基础,它可以提供准确的地层结构信息,但是成本高,耗时长,同时具有离散性。如何有效利用有限的钻孔数据进行地层分布规律的研究成为了人们普遍关注和探索的问题。选择不同的插值方法连接钻孔数据,绘制二维地质剖面或建立三维地质模型是模拟特定区域的地层情况的主要方法。其中,三维地质建模在地层构建上有多种选择,主要分为面模型与体模型。面模型有以数字高程表征地形空间特征的DEM模型(Song et al.,2018)和以不规则的三角网格表示地层分界面的TIN模型(Watson et al.,2015)。体模型通过体元进行三维地层实体的构造,以三棱柱模型(Zhang et al.,2015)和四面体模型为主,还有周翠英等(2006)提出的块体理论。无论二维剖面图或三维地质模型,钻孔连接的插值方法有多种选择,如线性插值、多项式插值、反距离插值与克里金插值等,模拟效果存在差异。模型建模与插值方法的选取受主观因素影响,具有局限性的同时缺乏科学合理性,因而无法推广应用。如何规避主观因素,利用智能的方法对地层分布进行模拟是地质信息化研究与工程设计建设中值得探索的问题。
机器学习近年来发展迅速,与传统的统计学观念相比,虽然两者的目的都是挖掘数据中潜在的信息,但统计学手段在探索数据规律的过程中会基于经验引入假设与建立模型,其结果具有较高的可解释性(Breiman, 2001)。机器学习手段则不对数据作假设,而是检验输出与数据标签的接近程度,通过BP(Back Propagation,误差反向传导)算法不断调整参数以获得更高的准确率。
当前,机器学习被广泛应用于不同研究领域当中,在图像识别、语言翻译、无人驾驶等方面取得了优秀的表现。在地质学与工程领域,Rodriguez-Galiano et al. (2015)在矿产勘查中应用决策树原理; 段友祥等(2016)和Wang et al. (2017)分别利用卷积神经网络和极限学习机(ELM)与主成分析(PCA)进行了储层厚度的预测; 季斌(2017)对比了多种机器学习算法进行了矿产预测; 黄宏伟等(2017)基于深度学习进行了隧道渗漏水图像识别; Bhattacharya et al. (2006)和Yang et al. (2015)进行了土壤分类的研究; 张涛(2016)利用多层感知器与BP神经网络研究了化学元素与岩浆岩、沉积岩岩性及沉积岩矿物的关系; 陈冠宇等(2016)、沙爱民等(2018)和程国建等(2016)分别利用卷积神经网络判断不良地质体、地表病害与岩石种类。另外,Zhang et al. (2011)基于高斯过程预测岩溶塌陷; Korup et al. (2014)和阙金声等(2016)进行了山体滑坡的相关研究。然而,目前国内外基于钻孔数据的地层分布机器学习研究正处于起步阶段,国内外相关研究少有报道。
针对上述问题,本文提出一种基于循环神经网络原理的地层序列机器学习模拟方法,它将钻孔数据处理为地层序列数据,建立地层类型序列与地层层厚序列模型,实现基于输入钻孔坐标,能够较为准确地判断相应位置的地层信息。该方法不依赖于数据假设与专家经验等主观因素,通过与实际钻孔数据对比表明,上述模型具有较好的可行性,可应用于地质信息化研究与工程规划、设计建造等方面。
1 地层序列模拟的机器学习理论基础
1.1 循环神经网络
地质体一般呈层状分布,具有先后关系,在空间上构成地层序列(宋仁波等, 2017)。循环神经网络(Recurrent Neural Networks, RNN)是用于处理序列问题的神经网络。图 1展示了RNN的结构,在“输入层-隐藏层-输出层”前馈神经网络的基础上,其隐藏层具有循环链接,每一时刻的输出与该时刻之前的历史输入相关联。

图 1 循环神经网络(RNN)结构图(Goodfellow, 2016)Fig. 1 Unfolding of RNN(Goodfellow et al., 2016)
其中,xt为第t时刻输入的地层信息;st为隐藏层神经元状态;ot为RNN输出的地层预测;W为权值矩阵;W(ss)为不同时刻隐藏层之间的连接;W(sx)和W(os)则分别为输入层与隐藏层、隐藏层与输出层之间的连接权值。用φ表示隐藏层的激活函数,用φ表示输出层的变换函数,RNN的前向传播过程如式(1)、(2)所示。
st=φ(W(sx)xt+W(ss)st-1)
(1)
ot=φ(W(os)st)
(2)
RNN的反向传导需在时间维度进行叠加,即时间反向传导算法(Back Propagation through Time, BPTT),如式(3)~式(7)所示(Goodfellow et al., 2016)。
(3)
(4)
(5)
(6)
(7)
其中,L表示损失函数,用于描述模型对于训练数据的学习情况;Lt表示任意时刻t的损失。RNN使损失最小化的过程即是训练过程。
1.2 地层序列导师驱动学习
RNN在每一时刻接收一个地层输入并给出输出。由于RNN具有“记忆性”,若当前时刻的输入存在误差,随着RNN不断的学习,误差将会不断累积。
导师驱动(Teacher Forcing)是一种任意时刻都采用正确序列作为输入的监督学习方法,如同导师指导学生进行学习,故称作导师驱动。然而频繁的外界干预会影响模型对于未知数据的泛化能力,在模型训练的过程中需要注意不同比例的导师驱动学习对模型的影响(Goodfellow et al., 2016)。
2 基于循环神经网络的地层数据重构
数据是研究的基础。在进行学习前,需根据数据特点、问题特征以及数据体量等因素将原始数据重构为计算机程序可表示的,方便读取利用的形式,因此进行归一化处理、地层序列填充与地层编码等。
2.1 数据归一化
在钻孔数据中,坐标与地层层厚之间数量级相差较大。为了保证收敛,数据需进行归一化处理,将取值范围压缩为0~1(王蕊颖等, 2013; 解明礼等, 2016; 黄震等, 2017)。对于任意数据x,其归一化计算方法为:

(8)
X为归一化的结果,是模型的数据输入。
2.2 地层序列填充
利用RNN进行地层序列学习时,批量训练要求所有地层序列长度相同,同时其输出结果也是等长的,而地层层数具有多种可能。
为此,引入终止标记(End of Sequence, EOS)作为虚拟地层,将地层序列填充为等长,同时作为地层序列结束的标记。在每一次训练中,RNN输出等长的地层序列,当终止标记出现时,采样过程停止,取终止标记出现前的所有序列作为预测地层序列。终止标记被当作地层的一种参与学习。
此外,RNN在初始时刻没有来自上一时刻的地层信息,因此还需为地层序列添加起始标记(Start of Sequence, SOS),作为RNN预测开始的信号。
2.3 地层编码
地层类别是离散的分类值,难以直接用程序表示。独热(One Hot)编码任意时候只有一位被激活。将每一种地层用唯一的数字标记(刘兴周, 2010; 温继伟等, 2013),并利用独热编码表示。
3 基于循环神经网络的地层序列模拟
3.1 地层类型序列模型的建立
RNN在初始时刻没有来自上一时刻的隐藏层状态。坐标信息是一个地层序列中所有地层的共同属性。在每一次训练前,利用坐标信息对RNN进行初始状态s0的赋值,以此使坐标指导地层序列模拟,如图 2所示。
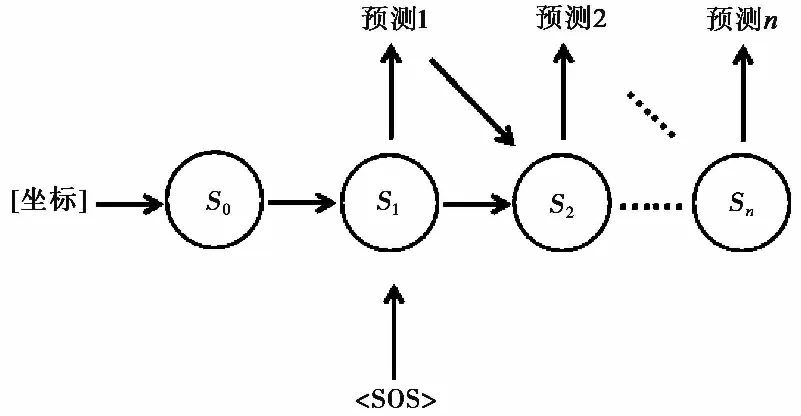
图 2 地层类型序列模拟过程Fig. 2 Stratigraphic type sequence simulation
在学习过程中,采用交叉熵损失函数描述模拟结果与真实地层之间的接近程度,如式(9)所示。
(9)
其中,y为真实地层,y′为RNN地层预测结果。
在模型进行验证时,除了地层准确率外,本文采用基于编辑距离的序列相似度作为评价标准(Duan et al., 2001)。
编辑距离表示两个序列之间,其中一个序列经过插入、删除和替换3种操作转化为另一个序列所需的最少操作数。编辑距离越小,则表示这两个序列越相似。序列相似度的计算公式如(10)所示。其中,S与T为待比较序列,D(S,T)为编辑距离。
(10)
3.2 地层层厚序列模型的建立
地层层厚序列模型需要以地层类型为基础,连接坐标、地层类型与地层层厚等信息。因此,采取seq2iseq(sequence to sequence,序列-序列)架构,利用两个串联的RNN分别作为编码器与解码器建立地层层厚模型(Sutskever et al., 2014; Cho et al., 2014)。如图 3所示,编码器负责处理地层类型信息,以其最后时刻的隐藏层状态作为解码器的初始状态,进而预测每一个地层类型对应的层厚区间。

图 3 地层层厚序列模拟过程Fig. 3 Stratigraphic thickness sequence simulation
3.3 地层序列模型
地层层厚序列模型在训练的过程中采用真实地层数据作为样本,而在实际应用场景中,地层数据是未知的。将地层类型序列模型与地层厚度序列模型相连接,以地层类型序列模型的模拟结果作为地层厚度序列模型的编码器输入,从而完整预测地层序列。
4 应用实例
4.1 应用区域及其数据简介
本文利用python语言,在Pytorch深度学习框架下进行地层序列模型的开发与验证。
研究区域位于江苏省某市,面积约为3882平方千米。研究区域内的土体主要为砂土类、黏性土类以及粉土类,局部地层具有淤泥、淤泥质土。本文共涉及钻孔数据1386个,全部终止于基岩面顶部,其位置分布见图 4。钻孔共涉及13种地层(表 1)。随机选取150个钻孔作为测试数据,其余用于训练。
图 4 研究区钻孔分布图Fig. 4 Borehole location
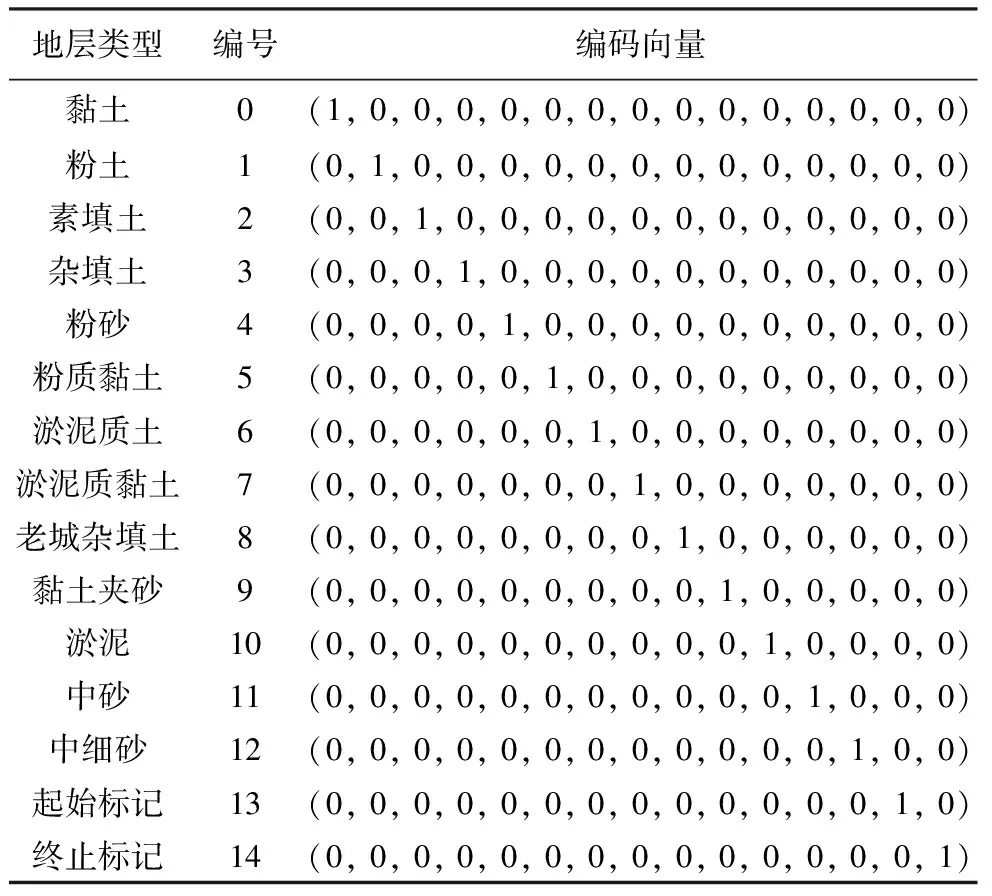
表 1 地层类型与编码Table 1 Strata numbers and one-hot vectors
4.2 地层模拟实验
对地层类型模型与地层层厚模型进行500个回合的训练,并在每次训练结束后利用测试钻孔数据检验模型的性能,测试结果如图 5~图9所示。
随着学习次数增多,模型的预测能力不断增强,同时进步的速度逐渐减小。最终,地层类型准确率为65.56%,平均预测序列相似度为76.14%,地层层厚准确率为66.58%,基本满足地层序列的模拟需求。
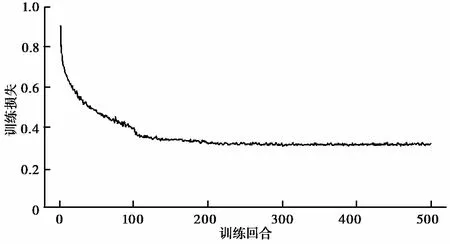
图 5 地层类型模型训练损失Fig. 5 Stratigraphic type model training loss
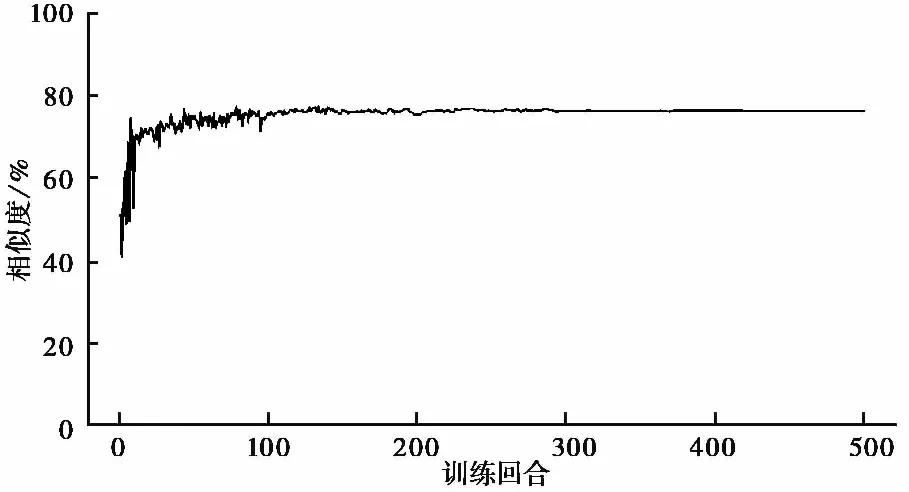
图 6 地层类型序列相似度Fig. 6 Stratigraphic type sequence similarity
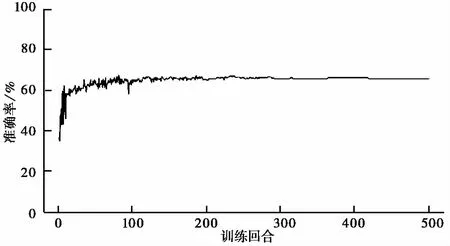
图 7 地层类型准确率Fig. 7 Stratigraphic type accuracy
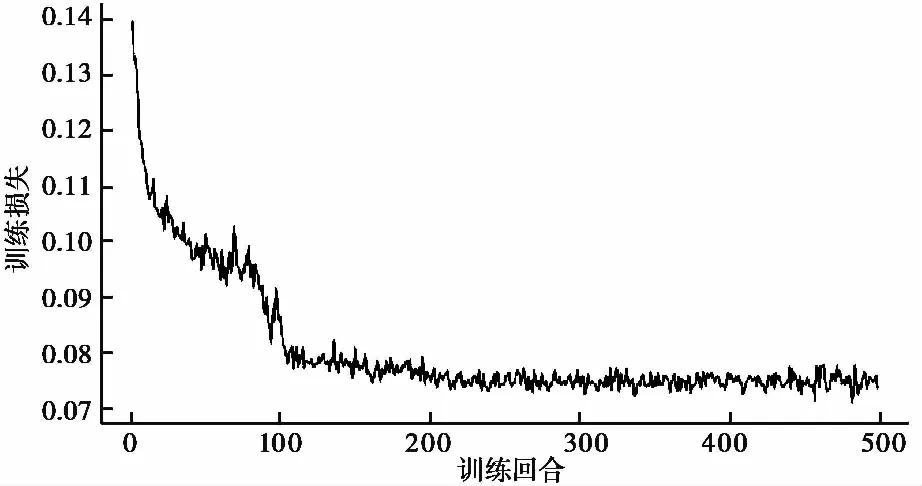
图 8 地层厚度模型训练损失Fig. 8 Stratigraphic thickness model training loss
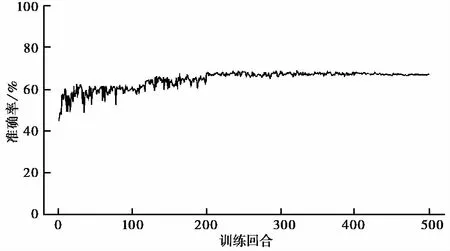
图 9 地层层厚准确率Fig. 9 Stratigraphic thickness accuracy
在此基础上,为验证导师驱动学习的效果,采用不同的比例进行了11组测试。测试结果见表 2。
观察模型的学习过程,以图 10与图 11为例,在采用导师驱动学习的训练回合,损失比无正确监督信号的训练回合小,随训练次数的变化也因此呈带状。同时,导师驱动学习的比例越高,模型做出预测的历史依据越可靠,在正确监督信号的指导下可以更好地拟合训练数据。
训练结束后,比例为70%的模型在地层类型准确率与序列相似度方面取得了最好的表现,分别为79.41%与68.88%; 比例为20%的模型在地层层厚准确率方面取得最佳表现,为77.60%。测试结果表明,导师驱动作为一种监督学习的手段,有助于进一步提高模型的测试表现,但其比例与模型预测性能之间不呈正相关。

表 2 地层类型与层厚实验结果Table 2 Results of stratigraphic type and thickness test
图 10 1/2导师驱动学习训练损失Fig. 10 Stratigraphic type model training loss under 1/2 teacher forcing training

图 11 完全导师驱动学习训练损失Fig. 11 Stratigraphic type model training loss under full teacher forcing training

表 3 地层序列模型实验结果Table 3 Results of stratigraphic sequence test
将地层类型模型的模拟结果作为地层层厚模型的输入,构建完整地层序列模型,结果见表 3。由于模型采用地层类型的输出作为编码器输入,因此实验结果的地层类型准确率、平均相似度与地层类型序列模型相同。层厚准确率稍有下降,为71.43%。
综上所述,基于循环神经网络的地层序列模型可以较准确地基于输入坐标预测真实地层情况,该方法的可行性得以验证。
5 结 论
(1)根据机器学习理论,提出一种基于循环神经网络的地层序列模拟方法,利用钻孔数据中地层序列信息进行学习并给出了钻孔数据的重构方案。经训练,该模型的地层类型相似度可以达到79.41%,地层层厚度预测准确率可以达到71.43%,能较为准确地模拟地层情况。与传统方法相比,机器学习手段对地层序列的模拟不需要依赖数据假设与专家经验等主观因素,方法上具有通用性,可为地层结构与分布研究提供新的思路与方法。
(2)通过进行不同比例的导师驱动学习,发现其有助于提升模型的预测能力,但不呈正相关。训练过程中过多地采用导师驱动学习会影响模型的预测表现。
