长文本武侠小说外号识别研究
2019-09-06赵晓磊程恒超
唐 锋,梁 循,赵晓磊,张 旋,程恒超
0 引言
中文长文本武侠小说是一类具有鲜明中华文化元素的小说,多以侠客和义士为主人公并描写他们身怀绝技、侠肝义胆等行为。本文的长文本武侠小说的外号指在武侠小说中除了人物真实姓名外人们对其的称呼。
外号,也叫绰号、诨号,指姓名以外,根据此人的外貌、体型或特征等,给其起的另一称呼,以表达亲昵、玩笑之意或憎恶、讽刺之感,在修辞手法中叫做借代。贾崇柏认为“人的本名多是抽象符号,人物外号却往往是本人特征的具体化和形象化,外号代本名就是以具体代抽象。它容易唤起人们的联想,比本名给人留下的印象要深得多。”[1]
根据武侠小说中人物外号所包含的文字含义,并对组成人物外号的文字通过统计分析和整理,武侠小说中的人物外号可以分为五大类: 武功招式类、门派类、外貌特征类、地理位置类和武器类。武功招式类的外号,例如,“大手印”“阴阳手”等;门派类的外号,例如,“峨眉掌门”“丐帮帮主”“逍遥门主”等;外貌特征类的外号,例如,“黄衫客”“黑眉墨手”等;地理位置类的外号,例如,“京师第一高手”“江北三魔”等;武器类外号,例如,“无极剑”“八方刀”“精魔刀”等。
下面按照引言中对武侠外号的分类,对五类外号进行详细描述。
(一) 武功招式类外号
由于武侠小说自身的特性,描写的各种义士侠客往往都身怀绝技,使作品中的人物形象更加丰满,给读者留下深刻的印象。因此,根据武功招式给人物起外号称为武侠小说中最常见的一种类型。如金庸小说《射雕英雄传》中裘千仞的外号“铁掌水上飘”,灵智上人的外号“大手印”;又如司马翎小说《霸海屠龙》中钟抚仙的外号“太乙神指”,李听音的外号“阴阳手”等等。
(二) 门派类外号
在武侠小说中,各路能人异士、侠客英雄大多都会分属于各个武林门派,使得门派成为武侠小说中不可或缺的一个元素。例如,在金庸小说中就能够众多武侠门派,例如,武当派、峨眉派、少林派、崆峒派、华山派、五毒教、丐帮、明教、天山派、全真教、逍遥派等等。众多的武林门派也展漏出众多的武林高手,为了体现出人物所属门派以及在门派中的武功高招或地位,小说中的人物外号有一部分体现了这种门派类别。如卧龙生小说《飞燕惊龙》中的齐元同的外号之一是“天龙帮红旗坛主”,参元通的外号之一是“崆峒派掌门”;又比如金庸小说《笑傲江湖》中恒山三位掌门师太江湖外号“恒山三师太”,《天龙八部》中丁春秋的外号“星宿老怪”,《倚天屠龙记》中武当七侠、魔教四王等都在外号中体现了他们的门派。
(三) 外貌特征类外号
通过描述人外貌特征来描写人物也是一种常见手法。在武侠小说中的外号中也经常可以见到为了展现人物的外貌体征在外号名中凸显人物的外型的情况。如金庸小说《碧血剑》中单铁生的外号“独眼神龙”、何红药的外号“黑衣老乞婆”,从外号就可以知道单铁生是一个只有一只眼的人物而何红药则身着黑色外衣;又比如金庸另外一部小说《神雕侠侣》中段智兴的一个外号是白眉僧,从外号就可以知道段智兴是一位有着白眉的僧人。
(四) 地理位置类外号
武侠小说中的人物外号还有一类是在外号中体现人物所处的区域位置。此类外号使读者能够对小说中的人物记忆深刻,在读者脑海中将人物外号与对应的区域对应起来。如司马翎小说《帝疆争雄记》里面湛百亥的外号“鲁南刀怪”,栾洛的外号“东海狂人”;又比如金庸小说《书剑恩仇录》中袁士霄的外号“天池怪侠”,常赫志和常伯志的外号“西川双侠”等等都可以从外号窥见他们是哪个地方的人物。
(五) 武器类外号
武侠小说中还有一种元素格外吸引人的眼球,就是各式各样的武器,不同人物使用的武器风格迥异。古人所说的“十八般武艺”是指十八种武器,一般是指弓、弩、枪、棍、刀、剑、矛、盾、斧、钺、戟、殳、鞭、锏、锤、叉、钯、戈。但是中国武术中出现的兵器远不止十八种,这就使得各种奇门兵器和形形色色的暗器成为武侠小说中一个亮点,也使得武器成为武林高手的特征之一。如司马翎小说《霸海屠龙》中袁琦的外号“毒剑”,邵坤的外号“六甲刀”,凌志扬的外号“钱塘一剑”;又比如萧瑟的小说《霸王神枪》中林英豪的外号“破风神剑”,杨子威的外号“崩雷神剑”或是金庸小说《飞狐外传》中的商剑鸣外号八卦刀等等。武器与武侠始终有着不可分割的联系,这种联系在外号中得以体现。
将外号进行分类能更好地构建后文中武侠外号高频词典,使武侠外号高频词能够被更清晰地分类。
广义地说,绰号识别是一类特殊的同义词识别。Han等在2017年的KDD会议上提出了对同义词自动提取提出了DPE框架[2]。目前在中文信息处理领域,对外号识别尚未有深入研究,本文希望在这个细化领域有所贡献。从大的方面来看,外号识别与中文命名实体识别有相似之处,但也有不同。命名实体识别(NER)是指识别文中具有特定意义的实体,主要包括人名、地名、机构名等。目前,中文命名实体识别也主要集中在人名、地名、机构名、时间、日期、货币和百分比这几大类[3]。对于识别外号的这个领域尚未有相关研究,也没有将外号的识别与真实姓名对应起来。
本文提出未登录词扩展识别筛选方法来对观察窗口内的文本进行扩展查找外号。同时,统计武侠小说外号中出现频率高和频率较低的字词作为武侠小说的高频词词典和低频指示字典,以对候选文本进行筛选;再以固定句式法则通过外号指示词对文本进行二次查找外号,补充之前查找的字符串集。若对同一个人名,通过固定句式法则查找的外号与对观察窗口内的文本进行扩展查找的外号有重复,使通过固定句式法则查找的外号优先级更高。最后将两种方法得到的外号取并集,最后得到识别出的外号集合。
1 相关工作
目前,对于外号这种类型的命名实体识别(Named Entity Recognition, NER)在中文信息处理领域还没有深入的研究。从宏观上看,外号识别是信息抽取和中文命名实体识别的一个分支。信息抽取的任务是从大量数据中准确、快速地获取目标信息,提高信息的利用率。在信息抽取领域内,命名实体识别、指代消解、关系抽取和事件抽取为其四个主要方面。[4]中文命名实体识别仍然存在许多难题。与英文命名实体识别相比,中文命名实体识别的难点主要包括: 汉语中的“字”的边界是确定的,但“词”的边界是模糊的;汉语中存在大量的嵌套、简称、缩略语等复杂结构[5]。目前,国内外众多学者在自动分词和命名实体识别研究领域做了大量工作,但从实际分词和识别效果上看,结果往往不是很好。因为对于不同领域的语料库,通用的处理方法不能在特定情境下进行准确的识别,所以对于细分领域的命名实体需要有更细化的方法来进行识别。
国内在中文命名实体识别方面,黄德根提出了基于统计的方法来识别人名[6], 宋柔提出了基于语料库和规则库的中文人名识别方法[7]。
近年来,在命名实体识别领域,很多研究者将NER任务规约成一种序列标注任务[8]。对于每一个输入到模型中的字,首先对其进行标注判定,根据判定的类别来对命名实体的边界和类型进行判断。序列标注任务中常用的是序列标注,此策略中S表示自字本身就是一个实体,B表示该字是命名实体的起始位置,E表示命名实体的结尾,O表示该字不属于命名实体的一部分[9]。在进行序列标注任务时,有一些机器学习的方法可以被应用其中。最常见的可以分为有监督的机器学习方法、半监督的机器学习方法和无监督的学习方法[10]。有监督的学习方法有支持向量机(Support Vector Machine, SVM)[11]、最大熵模型(Maximum Entropy, ME)[12]、隐马尔可夫模型(Hidden Markov Model, HMM)[13]、条件随机场(Conditional Random Field, CRF)[14]、决策树(Decision Tree, DT)[15]等。
除了基于统计机器学习的方法外,还有基于规则的方法和当前火热的深度学习下的命名实体识别[16]。
基于规则的命名实体识别方法是早期在MUC会议之后提出的NER研究的热门方向。其中,Collins等[17]提出的先定义Decision List规则集再根据语料进行迭代并产生新的规则的方式使得其在人名、地名、机构名等三种典型的命名实体识别类别上的识别准确率达到了91%。同时,也有学者提出将规则与统计模型相结合,在识别地名的时候不加人地名词典也可以取得很好的效果[18]。但是,基于规则的命名实体识别方法的弊端,在于识别准确率的提升意味着需要更多的规则,这样导致普适性不是很好。
深度学习属于近期火热的研究方向,其源于神经网络模型的技术也成为了机器学习领域新的研究热点。在NER领域,使用词向量的表示方法使得在大规模文本中异构的文本被统一用特征表示成为可能[19]。除了使用词向量作为特征,很多学者也寻求借鉴长短期记忆网络(LSTM)、深层神经网络(DNN)[20]、混合神经网络(HNN)[21]等方法来对现有的词向量作为特征的方法和模型进行改进。例如,Lample等[22]提出的LSTM和基于转换的两种神经网络模型,在四种语言上均获得目前较好的NER效果。
识别外号并将外号与真实人名对应起来可以算做一类命名实体识别和中文信息分析相结合的任务,但与之前识别人名、地名、机构名时间、日期、货币和百分比等实体相比还是有不同的地方: 第一,外号不独立,必须与真实人名联系起来;第二,外号识别过程中会出现不唯一性,同一个真实人名可能存在一个或多个外号,这也增加了外号识别的难度;第三,以上几类中文命名实体的识别已经有很多相关数据集及标注集,但本文研究的外号识别国内尚未有深入研究。
我们借鉴了未登录词的扩展识别方法,在外号识别上延伸了相关识别规则,并对可能的外号子串进行筛选;同时,本文还将引入“固定句式法”来对武侠小说中的外号进行识别。
本文主要工作如下: ①提出基于未登录词扩展识别筛选方法,对外号进行识别; ②提出武侠小说外号指示词,并引入“固定句式法则”对外号进行识别; ③建立武侠外号高频词典和低频指示字典,对竞争外号子串进行筛选确定候选外号子串。
本文的组织结构如下: 引言介绍外号识别的研究背景以及武侠小说中外号的分类;第一节介绍中文命名实体识别的相关工作以及外号识别的难点;第二节主要介绍外号识别的相关定义以及方法概述;第三节在收集到的数据集上进行实验并与标注集进行对比分析;最后为本文的结论与展望。
2 识别方法
2.1 相关定义
定义1基准名(Base Name, BN),指在小说中出现的主要人物的姓名,也就是姓氏与名字相结合不能省略其中一部分。
这里将文中出现人物的姓名作为BN。例如,在《射雕英雄传》中“郭靖”也被称为“郭大侠”,但此处以“郭靖”作为BN;又比如《笑傲江湖》中,“任盈盈”也被称为“盈盈”。虽“盈盈”出现频数远大于“任盈盈”,但在外号识别时,“盈盈”会作为外号,所以此处会取“任盈盈”为BN。对于第i(i≥1,i∈N)个外号的基准名定义为BNi。
定义2候选的外号字符串词总集合定义为C。对于每个不同的BNi(i=1,2,3,…),其候选的外号字符串集合定义为Ci(i=1,2,3,…);对于每个集合Ci(i=1,2,3,…),其中的元素定义为Cij(i,j=1,2,3,…),Cij表示第i个基准名的第j个候选外号。
定义3竞争外号子串(Competent Nickname Substring, CNS)。在对BNi的候选外号子串进行迭代筛选的时候,若某次迭代出现了两个或多个Cij的数量相同的外号子串,这些子串则称为竞争外号子串。
确定BN的候选外号子串需要根据Cij中包含武侠高频词数目的多少。需要注意的是,如果CNS所包含的武侠高频词也相同,则共同作为候选外号子串进行迭代,直到某个子串所含武侠高频词数目大于另外的竞争外号子串。当迭代三次后,若仍然有候选外号子串所含武侠高频词数目相同,则将候选子串作为BNi的外号。
定义4武侠外号高频词(Knight-errant Nickname High-frequency Word, KNHW)。武侠高频词是指武侠小说外号中出现频率大于10%的字或词,同时还包括一些虽然频率未10%的字词但也包含在天气及气候、颜色和金属等分类中的字或词。
在整理并分析武侠小说出现的外号时,发现由于外号本身是反映人的特征,故在创作一个武侠人物的外号时,往往会包括一些常用的字词。通过对武侠小说外号的统计和整理,我们可以将这些出现频率较高的字词定义为武侠高频词。
定义5武侠外号高频词典(Knight-errant Nickname High-frequency Dictionary, KNHD)。武侠高频词词典是根据定义4中的武侠外号高频词组成的词典。
KNHD包括天气及气候武侠高频词词典、数字武侠高频词词典、颜色和金属武侠高频词词典、玄幻类武侠高频词词典、身体部位武侠高频词词典、方位武侠高频词词典、动物武侠高频词词典、形容人的武侠高频词词典等词典组成武侠高频词词典。
比如天气及气候武侠高频词词典,包含如: 风、雨、雪、雷、电、霜、冻、寒等武侠高频词,在小说中包括此种类型的外号如: 潇湘夜雨、西门飘雪、奔雷手等;又如动物武侠高频词词典,包含如: 龙、虎、狼、马、狗、狐、狮等武侠高频词,在小说中与此相关的外号如: 伏虎金刚、雪山飞狐、鬼门龙王等。
定义6候选外号子串(Optional Nickname Substring, ONS)。候选外号子串指的是在寻找BN的外号时最有可能是BN的外号的子串。并对ONS进行迭代,以找出BN的外号。
定义7观察窗口(Observation Window,OW)。观察窗口是指在选取标识词语后,选择当前位置的前后n(n>0)个位置上的字、词、字母、数字、标点和其标识表示的集合。即以当前位置的前后n个位置范围内的子串及其标记作为观察窗口: (…w-n/tag-n,…,w-1/tag-1,w0/tag0,w1/tag1,…,wn/tagn,…,其中wi(i=-n, -n+1,…,-1,0,1,…,n)表示第i个位置上的字符,tagi(i=-n,-n+1,…,-1,0,1,…,n)表示第i个位置上字符的标记)。本文中OW在选取ONS时和对CNS进行扩展时会被使用,在NI定位到文中具体句子时也会使用。
定义8外号指示词(Nickname Indicator,NI)。外号指示词是指在武侠小说中出现外号时常常出现的词。本文选取了“外号”“绰号”“人称”“号称”“称作”等词汇作为NI。
在后文中有对15篇武侠小说的NI及OW的出现频数进行统计,结果表明外号指示词频数与外号频数有很强的相关性。
定义9低频指示字典(Low-frequency Pointer Dictionary, LPD)。低频指示字是指在通过未登录词扩展识别筛选方法识别外号状态下提取ONS时,有些字符诸如助词类的出现频率较低,基本未在外号中出现过的字的集合。
例如,的、是、做、么、了、呀、呵、啊、吗、嘛……这些字在现有武侠小说中的外号中出现频率很低或从未出现,若遇到这些字在提取ONS时一般忽略。
定义10固定句式法则(Fixed Sentence Principle, FSP)。固定句式法则是指在统计并定位了NI之后,在OW中对外号进行查找时,要根据一些固定句式或特征来进行外号识别。
由于单纯的分词不能准确找到外号,容易将外号拆分开,故将外号出现的句子进行整理归纳。然后提炼出一些句式,在这些句式中外号出现的几率很大,那么称这些句式为固定句式。根据这些句式去寻找外号的方法称为固定句式法则。而在遇到这些句式时,对字符串进行摘取作为ONS。如《碧血剑》中 ,搜寻“外号”这个NI,在OW中会出现,例如,
(1) 木桑道人外号“千变万劫”。
(2) 他年轻之时,因轻功卓绝,身法变幻无穷,江湖上送他个外号,叫做“千变万化草上飞”。
(3) 袁承志道: “刘大哥,你外号五丁手,五丁开山想必拳力掌力甚是了得。
(4) 焦公礼道: “这位恩公姓夏,外号叫做金蛇郎君。”
(5) 谁叫他外号盖孟尝呢?哈哈!
(6) 他师父是华山派穆老祖师的徒弟,外号叫“铜笔铁算盘”。
(7) 原来这外号不大雅致,叫作“飞天魔女”。
可以发现,文中在出现“外号”这个NI的时候,真实的外号也经常会随之出现。那么,从这些句式里面就可以提炼出FSP:
(1) NI+“”/‘’,引号内部为ONS
(2) NI+…+“叫(作/做)”+ ONS
(3) “你/他/我/”+“外号”+ ONS
诸如这种类型的句式将其纳入FSP,用于识别外号。
2.2 未登录词扩展识别筛选方法
本文对外号的查找方法是通过未登录词扩展识别筛选方法并引入KNHD和LPD来对ONS进行筛选;第二步是通过FSP对外号再次查找并与之前的ONS取并集确定识别的外号。
如表1所示,以《笑傲江湖》中莫大先生的外号“潇湘夜雨”为例来说明未登录词扩展识别筛选方法。每次迭代统计BME出现的次数,若前后两次迭代BME次数不同停止迭代,或者遇到双引号、单引号时停止迭代。
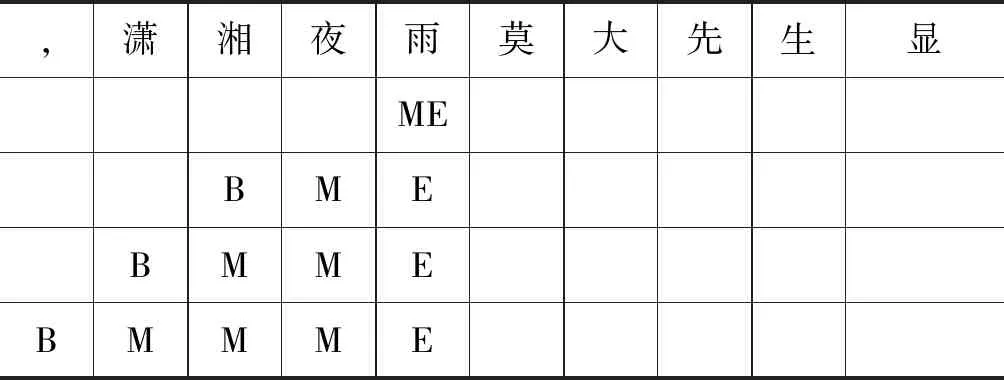
表1 外号实体识别扩展搜索示例
如表1所示,第一次迭代时,“夜雨”的总次数为7次,并未出现低频指示字;第二次迭代时“湘夜雨”的总次数为7次,第三次迭代时“潇湘夜雨”的总次数为7次,第四次遇到双引号即停止迭代。于是认为此时的BMME,即“潇湘夜雨”为莫大先生的外号。
根据表1的示例可以得出未登录词扩展识别筛选(OOV extension Recognition and Screening, ORS)方法。
在对ORS方法进行说明之前,本文作了以下约定:
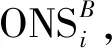
算法1(ORS):
(1) 按照已知的基准名(BN)词典进行搜索,筛选出BN前面只包含中文字符、以及BN前一个字符为“’”“””的字符串集合C,其中Ci(i=1,2,3,…)表示第i个基准名符合条件的字符串。
(2) 按照以下方式进行标注: 词首(B)、词中(M)、词尾(E)并结合KNHD和LPD初筛合格的字符串,初始时B、M、E均在BN的前一个字符。
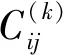


算法2是FSP搜索的算法描述,FSP根据NI和固定句式对ONS进行搜索。在通过NI确定好OW之后,通过固定句式来对ONS进行提取,这就是基于固定句式法则的外号搜索策略(Fixed Sentence Principle Search, FSP )。通过算法2可以将算法1中有些未发现的ONS提取出来并在优先级上取更高。

算法2 FSP搜索输入:小说数据集,{NI}输出:{ONSBi}forNIi∈NI: 当NIi出现: 将OWi加入到OWforow∈OW: 根据FSP搜索ONS 将ONSBi加入到{ONSBi}
如表2所示,将武侠高频词分类进行整理,分为动物、身体部位、天气、古时特殊称谓、武器、方位、数字、玄幻、颜色、植物和自然景观等几类。表2是武侠高频词表的节选,按照类别列出。当在选取ONS的时候,根据KNHD对CNS进行筛选。
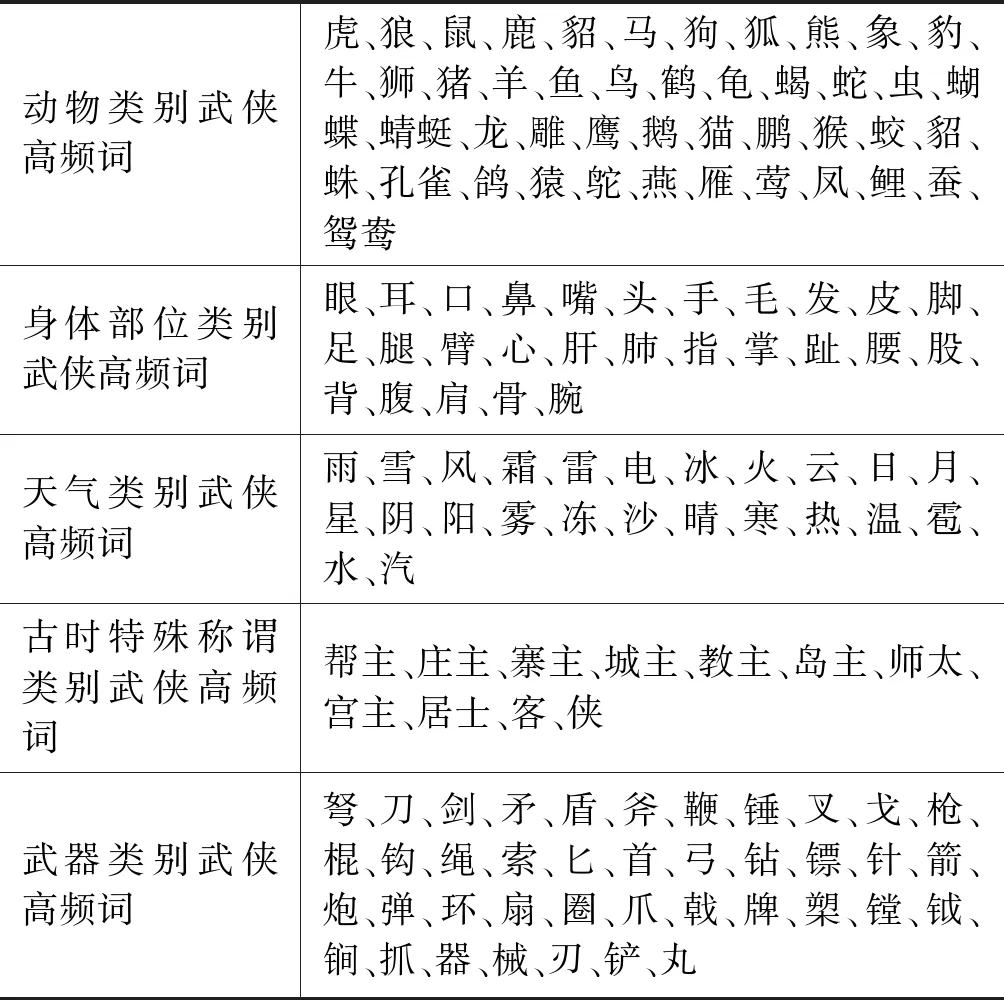
表2 KNHD按类别分类和统计(节选)
表3是低频指示字典LPD的节选,若在筛选CNS的时候发现有其中的指示字,应该将其过滤掉。

表3 低频指示字典LPD(节选)
表4是节选了部分FSP,如果在通过定位NI所在的OW内发现了FSP,则按照FSP的规则对ONS进行提取。
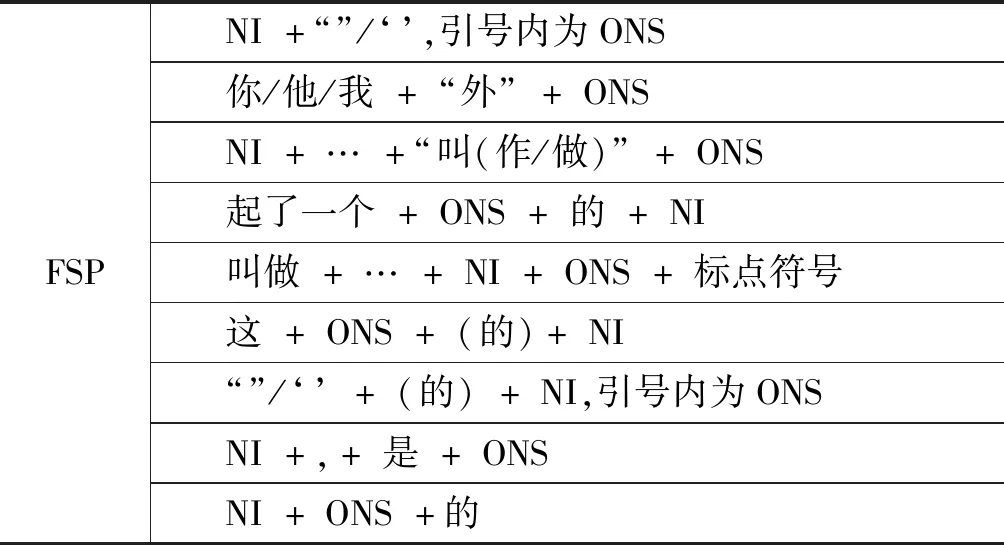
表4 FSP(节选)
3 实验研究
3.1 实验设置
(1) 数据集
为了评估本文提出的方法以及高频词词典在武侠小说外号识别上的可行性和有效性,实验选取豆瓣读书排名前一百的部分武侠小说作为数据集进行实验。在选取文本时尽量兼顾文本篇幅和文本传播影响力,由于中文长文本武侠小说大于100万字的比较少,所以有一部分小说选取了几十万字的中长文本;同时,文本兼顾了传播影响力,这对后面的人名及外号标识提供了可能。由于目前没有有效的标注数据集,在收集到的33部小说中,根据网上搜寻到的人名和外号给这些小说做标注,得到人名和外号的标注集。
(2) 评价指标
在本实验中,我们将33部小说的人名数据集作为测试集,得出的外号与已有的外号集作比对,并计算准确率、召回率和F-测度值三个指标。
(3) 实验结果
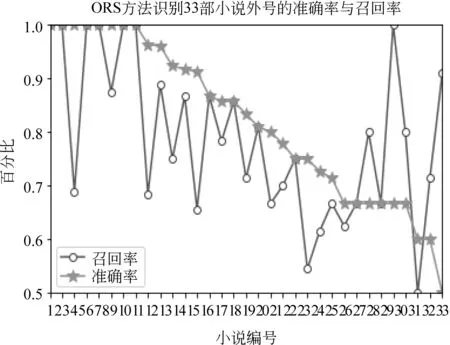
图1 ORS方法对33部小说外号识别准确率与召回率
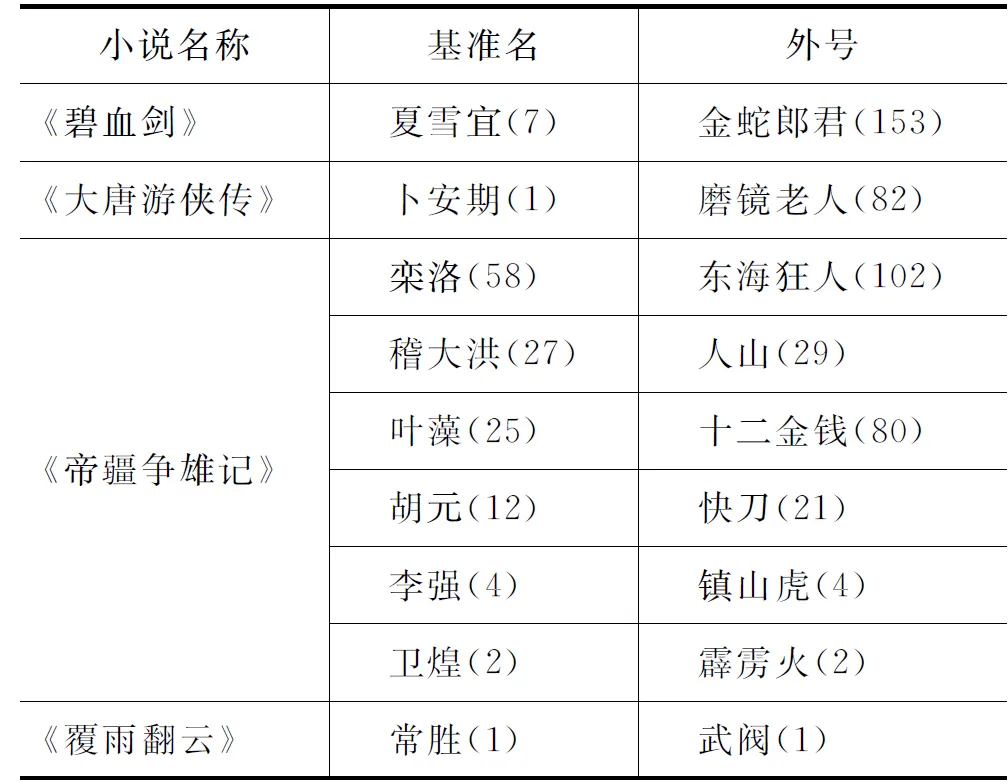
从图1可以看出利用ORS方法对33部小说外号识别的准确率与召回率66.7%以上的占到了29部,其中识别准确率最低的是《雪山飞狐》,为50%。回到原文中发现《雪山飞狐》中人物未准确识别的有曹云奇(腾龙剑)、周云阳(回龙剑)、田青文(锦毛貂)、陶百岁(镇关东)、郑三娘(双刀)等人物。他们的BN在文中出现的频数分别为229、41、103、81、48;但他们的外号出现的频数分别为1、1、1、5、9。其中,BN出现的频数远大于外号出现的频数,这使得通过ORS方法识别外号的难度增大;另一个原因就是本部小说中外号以非常规符号“「」”代替了很多单/双引号被标识,使得外号没有被准确识别,在FSP中需要加入非常规符号“「」”。
表5统计了33部武侠小说利用ORS方法以及ORS方法与FSP结合的方法识别人物外号的准确率、召回率和F-测度值。其中第2-4列是ORS方法识别人物外号的准确率、召回率和F-测度值;第5—7列是ORS方法与FSP结合的方法识别人物外号的准确率、召回率和F-测度值。利用ORS方法对33部武侠小说外号识别的准确率均值是82.18%,召回率均值是89.60%,F-测度值均值是87.90%。
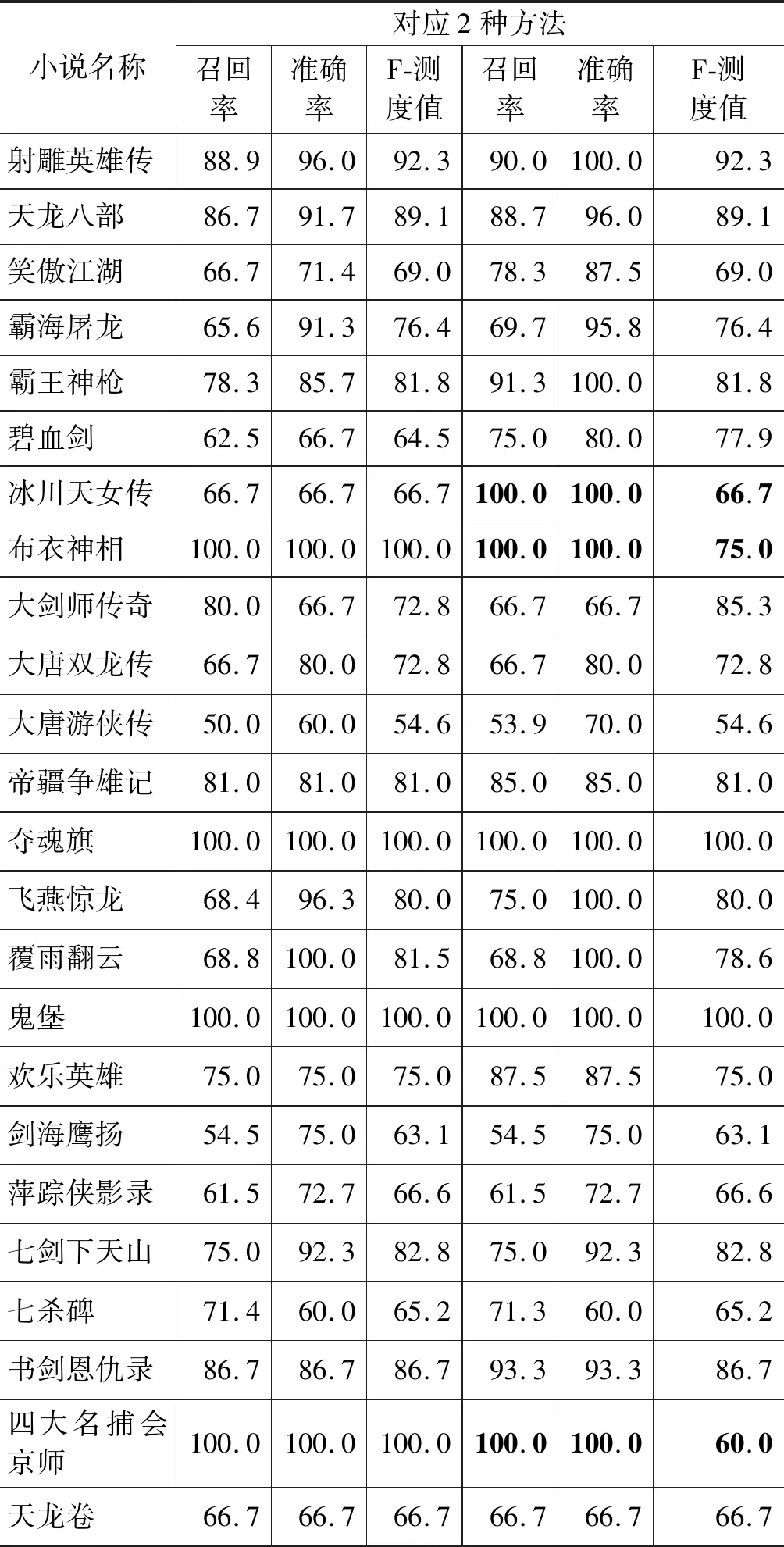
表5 ORS方法以及ORS方法与FSP结合的方法对33部武侠小说外号识别准确率、召回率和可信度
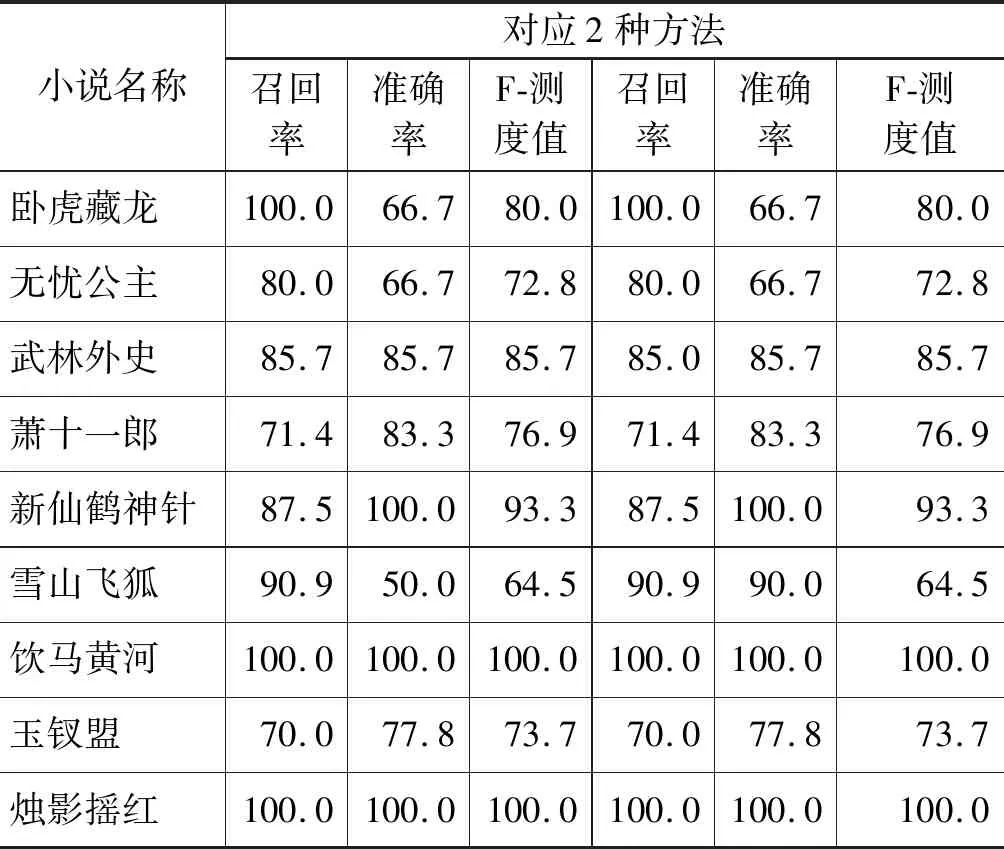
续表
表6可以看出《射雕英雄传》识别结果中“黎生”的外号识别有误。通过ORS算法识别的“黎生”外号是“刀光中”,但黎生的真实外号是“江东蛇王”。出现识别错误的原因是“江东蛇王”在文中只出现了一次,频数太低导致外号无法准确识别。但在引入了外号指示词来识别之后,与之前结果取并集可以识别出“江东蛇王”,之后通过约定3去除“刀光中”这个噪音字符串。
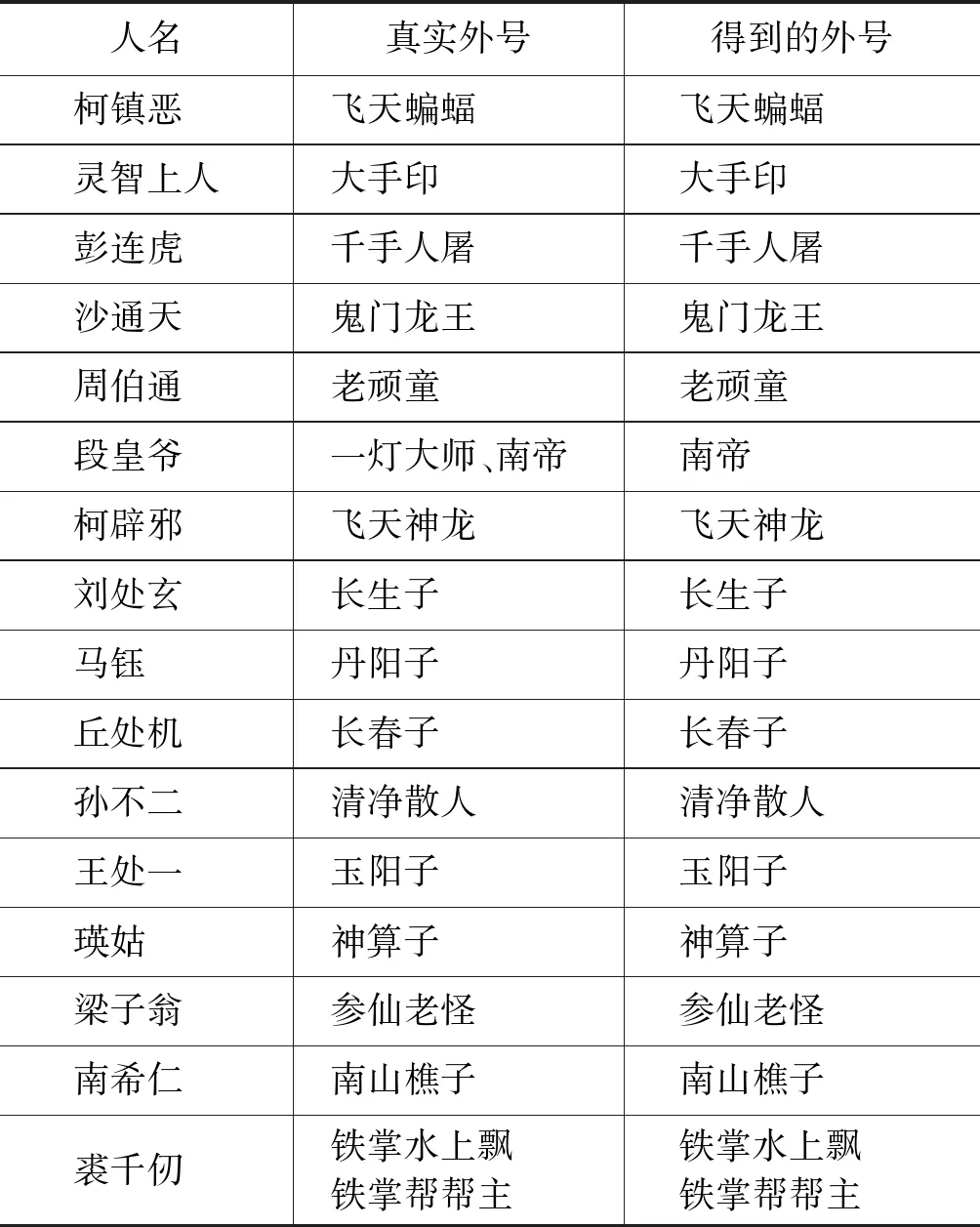
表6 《射雕英雄传》中识别的外号与真实外号

续表
图2是选取的15部小说指示词、OW内外号、基准名和外号名频数统计。其中,基准名和外号名频数统计对应图二中的折线图,对应的坐标轴是右边纵坐标轴和下边横坐标轴;指示词和OW内外号频数统计对应图2中的直方图,对应的坐标轴是左边纵坐标轴和上边横坐标轴。如图2中折线图所示,选取的15部武侠小说中人名和外号名的频数分布基本符合我们的常规认知,即小说中主要人物出现次数会远大于次要人物;从图中也可以看出15部小说中人物原名与外号名出现频数相差较大,所以在利用ORS算法来对外号进行识别的时候会有很多“噪音”字符串。这也印证了引入KNHD和LPD的必要性,有利于对“噪音”字符串的去除以及对真实外号的提取。同时,如表7所示,在实验中,若小说中人物外号出现次数比原名出现频数多,则这些外号都可以被正确识别。这可以通过对ORS算法的分析解释,因人名所在的观察窗口的字符串除了外号还有很多“噪音”字符串。但是,外号频数若大于人名频数,人名所在的观察窗口的字符串为外号的概率会增大,则通过ORS方法往往能找出人名对应的外号。
如图2中直方图所示,以选取的15部武侠小说为例,对文中出现的“外号”、“绰号”、“人称”、“称作”、“号称”5个NI做了统计并统计在出现这5个NI的OW中出现外号的频数,这里OW选取的是整句话,以句号为起止符号。可以发现在出现NI时,OW中外号出现的频数也很大,这印证了通过FSP方法来进行外号查找的合理性和有效性。从图3中也可以发现NI在不同小说中出现的类别有差异,其中“称作”出现频数较低,其余的NI在不同的小说中频数各异。
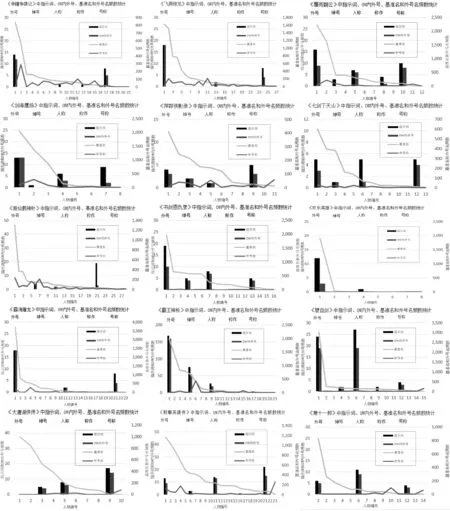
图2 15部小说中指示词、OW内外号、基准名和外号名频数统计
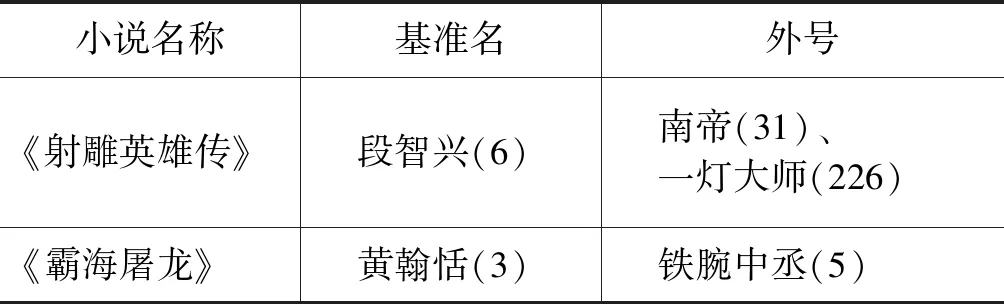
表7 小说中人物外号频数不小于基准名频数的统计(节选)
续表
续表
图3是加入了FSP之后对33部小说外号识别的准确率与召回率。可以发现相对于单纯的ORS方法,加入FSP之后,外号识别的准确率与召回率都有提升。其中,未识别出来的外号经过分析是由于外号出现频数过少(一般少于5次),所以很难有效提取出外号。例如,《卧虎藏龙》中的“高朗秋”的外号“西席先生”在全文只出现一次并且所在的OW内未出现NI;《七杀碑》中的“杨展”的外号“华阳伯”全文出现一次,“刘道贞”的外号“赛伯温”出现两次。频数过少导致很难通过上述方法找出外号。从图3可以发现在加入了FSP之后有12部小说的标注集中人名的外号全部识别,识别率达到80%的也占了23部,相对于单纯的ORS方法有所提升;最低识别率也提升至60%。
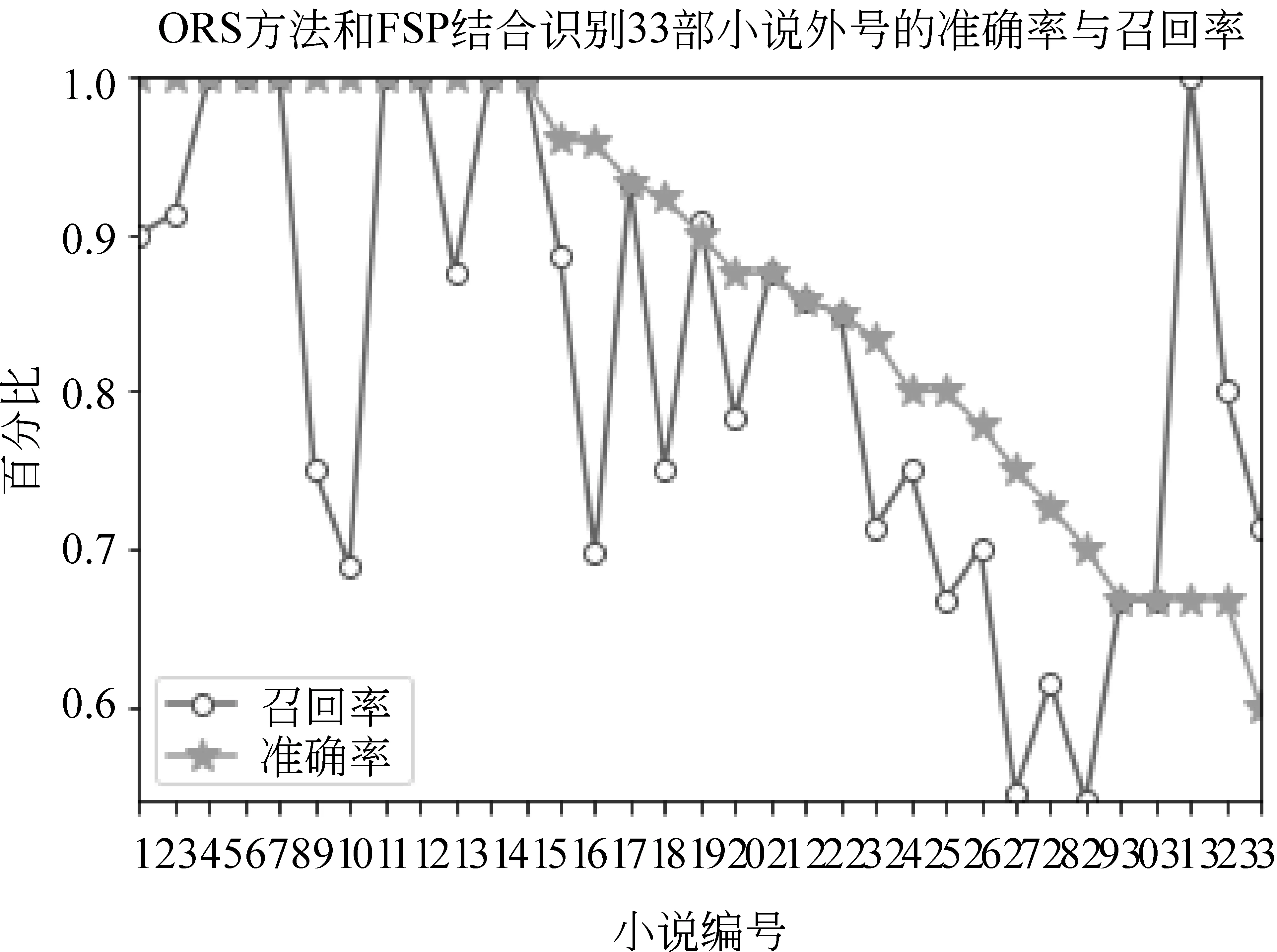
图3 ORS方法与FSP结合对33部小说外号识别的准确率与召回率
表5第5—7列是加入了FSP之后对33部武侠小说人物外号识别的准确率、召回率和F-测度值。利用ORS方法与FSP相结合对33部武侠小说外号识别的准确率均值是87.23%,召回率均值是93.77%。相对于Han等[2]提出的DPE框架热启动模式下在wiki数据集上对同义词的平均识别率62.25%有所提升。原因在于特定领域的同义词识别相对于不设限领域的同义词识别会采用更特定的方式,使识别准确率提升。
4 总结与展望
本文研究如何从武侠小说中找到人物的外号,并与人物的本名对应起来。这个研究任务属于一种前人未研究过的命名实体识别类型,识别的方法主要是引入武侠高频词和武侠高频词词典,利用基于未登录词扩展识别筛选方法对CNS的筛选从而确定ONS,然后对ONS进行扩展。同时,提出武侠小说外号指示词NI的概念对外号进行二次识别并与之前的识别结果相结合。对33部武侠小说的实验结果验证了方法的可行性和有效性。
武侠小说中的外号识别与当前互联网上一些关键词的变体也存在如下相似之处。
(1) 难以构建完整的语料库。由于武侠小说和互联网上词汇的不断增多,难以将所有的语料收集起来,词汇的变形数量是无穷的。
(2) 都有一个主体,变体可以是一个也可以是多个。对于武侠小说,人物基准名就是主体,外号就是主体的变体;而互联网上一些关键词也有主体与变体,比如一些敏感词识别。例如,“fuck”是主体,则“f***”、“fuk”、“motherfucker”都是其变体。
武侠文本中的外号识别方法可以为关键词的变体识别提供一些思路,通过未登录词扩展方法和对变体中高频词的搭建也能够帮助识别互联网上关键词的变体,同时对同义词识别和舆情管理等研究方向也具有借鉴意义。
本文是Han等提出的同义词自动提取[2]的一种具体实现。本文方法的实际意义在于对外号识别这个中文命名实体识别的新领域进行了探索,并通过对中长文本武侠小说的外号梳理构建了武侠高频词典KNHD和低频指示字典LPD来对ONS进行筛选。同时,提出外号指示词NI的概念并引入FSP来对外号进行识别。提出的方法对以后中文命名实体识别中特定领域的未登录词识别以及同义词自动提取亦有借鉴意义。
