基于C4.5算法的移动手机客户应用*
2019-09-03刘欢苏勇
刘欢 苏勇
(江苏科技大学计算机学院 镇江 212003)
1 引言
数据挖掘[1]实质上就是一种在超级多的数据中得到重要信息的技术。到目前为止,通信流量业务的发展变得高速化而且多样化,经营竞争是越来越激烈,对移动的服务需求提出了更高、更新的要求。当前,智能手机的遍及使用使得用户的流量消费行为更加灵活、更加粘稠。那么如何充分挖掘这些数据中隐含的规律,提高移动公司对于手机客户流量的具体策划,有效拉拢到更多的客户以及保留更多的老客户,而不是仅仅进行一些基础的查询和统计制定出一个笼统的套餐给所有人。利用数据挖掘[2~3]在这些超级多的数据中及时的来发现有用的知识,提升流量的信息利用率,来满足不同类型的客户需求,实现精细化营销[3]变得十分重要。对于在数据挖掘技术当中分类分析是一项首要的技术,该方式的目标就是能够准确有效地获取这些信息,分类的主要方法是建立分类模型或分类函数。这些分类模型或者函数必须要具有数据集的特点,而这些模型则是可以从某个已知的类别中反映出某个未知的类别。C4.5算法是一种基于分类的算法,该算法易于理解、算法复杂度较低[5]。经典的C4.5算法在运行的的过程当中因为各种缘由,会致使以下一些缺点:1)准确率不高。2)在构造树的过程当中,对于数据集有必要要进行屡次的按照次序的扫描和排序,这样也就导致了算法效率不高。3)当内存不能被容纳时,训练将不能运行[6]。很多C4.5得优化算法为了削弱这些缺点而相继产生,如文献[7]提出的为改进C4.5算法的准确率而引进了一个平衡度系数,该值是由决策者依赖先验学问或是专业内知识来确定的,在特定的情况之下人为妥协了各属性信息的增益率,利用改良之后的算法来对构造出的决策树进行分类变得是更加的确切且合理。改进前后的算法再通过实例分析来进行了比较,证实了改进算法的有效性。文献[8~10]提出的对算法上计算每个属性中的元素的信息熵的时候进行重新的比较来改进C4.5算法,将多余的属性给去除掉,从而减少了算法的复杂度,进而提高了算法的准确率,但是同时也存在着建树的时候比较信息的时候导致算法低效以及面对连续的数据处理起来比较困难。在此基础上进行改进的一个算法为懒散式分类算法,该算法将训练和学习的阶段合并,只有在明确分类要求时才进行学习建立分类模型,相对而言时间消耗非常短以及时效性比较高,但是如果在分类的过程中数据规模比较大的话,就会导致时间开销增加。本文中采用的改进型的C4.5算法结合了懒散式分类算法时效性强、运算时间快的特点和C4.5分类算法的预测精确度的特点设计了一个新的算法,最后为决策者得出一个准确的趋势,保证结果的客观性。
2 C4.5算法
对于分类算法来讲C4.5算法是一种比较重要的算法,是决策树的核心算法,它的做法是用信息增益率取代了信息增益来对属性进行测试,这不仅支持了离散的属性,而且还支持了连续的属性,除此之外还对决策树进行了一些必须的的剪枝。
对于决策树来讲,信息增益率就是其的核心,它是在信息增益的基础上发展而来的,信息增益率的公式如下所示:

C4.5的处理过程如下:设T为样本集,c为连续型属性。首先是通过属性c的取值将样本集T从小到大进行排序,并且取到的值是互不相同的。将值进行排序后得到的序列为v1,v2,…,vn,i∈[1,n-1],同时还按照v=(vi+vi+1)/2和v进行划分的两个样本子集,其中,此时用gainv记录划分所得的信息增益。在序列v1,v2,…,vn中找出使得信息增益gainv最大的v。根据连续属性c划分的样本集T的信息增益为gainv,此时样本集H被划分为H1v和H2
v两个样本子集,这样的划分能够将连续属性c上的最终信息增益率求解出来。
算法构造决策树过程如下所示:
1)设样本训练集为T;
2)首先要进行的是判断T是否为空。如果为空的话,就返回一个失败的值现设为A(A是一个单节点);
3)如果T是由具有相同的属性类B的数据集构成的话,就返回带有B类标记的单节点;
4)如果碰到的是一个集合C为空值而这个值是无类别分类的并且含有连续属性的,那么返回T中一个样本数量最多的属性值;
5)将集合C中所有的元素都进行遍历;
6)如果集合C中的元素Ci为连续的属性,那么令Ci中最大值为D1,最小值为D2;
7)执行For循环,j初始值为2,每次执行完毕i加1,循环到i=n-2;
8)Dh=D1+i*(D1Dn)/n;
9)将Cj元素中最大的信息增益属性值赋值到D中,再设集合A元数中的信息增益最大的属性值为Y;
11)最后就是根据上面一个步骤中Y的结合的数值建立节点,并且将节点标记为 y1,y2,y3,y4,…,ym;
12)其余的子树也通过上述过程建立起来。
3 改进型的C4.5算法
C4.5分类算法通过之前所有的数据集建立一个全局模型,其中得到的分类结果也是非常容易理解的,在决策树中关于每一条从根节点到叶节点的路径都对应一种预测分类结果,由此可以看得出来算法精确度相对很高,但同时也增加了时间复杂度。结合之前分类法的优点,我们可以设计出一种算法,不但能够确保时效性强、运算时间快,而且还可以保证C4.5分类算法的预测精确度。该算法主要步骤如下:
1)按照已经存在的分类标准,训练集将会被划分为连续型数值类或离散型数值类输出。
2)再根据待分类预测的样本来遍历整个训练数据集:
(1)设置近邻阈值K。
(2)对于训练数据集中的每个样本寻找最近邻的K个数据点。
(3)输出K个近邻作为分类子集。
3)针对分类子集采用C4.5算法构造决策树的方法来执行。
4)终止算法。
在第2)步中的训练集的K个近邻点是通过计算欧氏距离而度量到的。如果求出来的距离越小的话,那么就表明训练集的数据对象相似度越大,越为近邻关系。对于划分的两个数值类型采取了不同的输出结果:首先是当类为连续性数值时,测试样本的最终输出为近邻的平均值。同样,当类是离散值的时候,测试样本的最终输出是在特征空间中最近邻样本中、同类别样本个数最多的那一个。
其中欧氏距离的计算公式为

4 实验结果

图1 数据集为1500时的实验数据
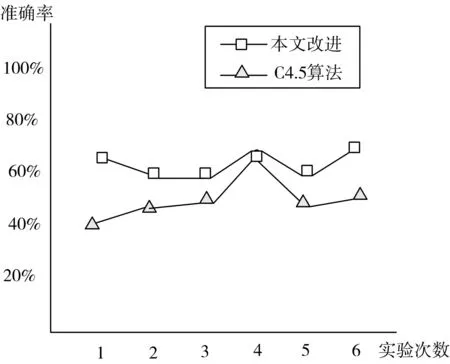
图2 数据集为2500时的实验数据
在某个时间段上某些方面流量使用情况的人工模拟数据集上的分类准确率如图1~2所示(图1和图2分别是数据集为1500,2500时的实验数据)。
经过对比,可以看到本文改进的C4.5算法相对于经典的C4.5算法具有较为准确的分类效果。
5 移动客户预测
根据上述方法,并且结合以往上网时间段、上网偏好等因素,我们可以得到不同的人群在不同的时间段的不同的上网偏好,移动公司的相关部门可以根据曲线图的趋势做出对应的决策,为客户提供个性化的服务,这样能够拉拢更多的客户,将会为移动公司带来巨大的利润。
6 结语
文中着重的是对算法上计算每个属性中的元素的信息熵的时候进行重新的比较来改进C4.5算法,去掉了不必要的属性,降低了算法的复杂度,进而提高了算法的准确率。研究的主要的目标是为了公司相关部门人员分配的参考,所以这边的分类中心就只需要几个。下一步的研究方向是针对本算法中的不足,研究如何将每个属性中的元素的信息熵重新的比较,并优化算法分类的准确率,以便为相关部门提供有力的参考依据。
