基于M估计的改进Pauta准则在监测数据粗差识别中的研究及应用
2019-08-31李艳玲
李 兴,李艳玲,张 鹏,杨 哲
(1. 四川大学 水力学与山区河流开发保护国家重点实验室 水利水电学院,成都 610065;2. 中国市政工程西南设计研究总院有限公司 第一设计研究院,成都 610081)
0 引 言
进入21世纪以来,随着监测技术、计算机技术和通讯网络技术的不断发展,测点个数与观测频次随之增多,监测数据量增长明显[1],序列类型也较为丰富。精确识别监测序列中的异常数据是科学准确分析评价大坝安全状况和运行性态的前提和保障,而针对目前多类型的数据序列,虽然统计学方法[2,3]、小波分析[4],四分点法[5]和抗差最小二乘法[6]等逐渐应用在粗差识别中,但依然存在适用性低、漏判和误判等问题。经典的统计判别法Pauta准则由于其使用简便而被广泛应用[7],但对监测序列中含有较多离群数据如多点离群、台阶型、震荡型数据极易出现异常值漏判的问题。李丽敏[8]等基于Pauta准则采用自学习和平滑处理检测异常数据;毛亚纯[9]和赵键[10]等学者在Pauta准则的基础上提出数据跳跃法,但这些方法对含有较多离群点数据的适用性较低。为此,本文针对大坝安全监测数据粗差识别的Pauta准则存在的异常值漏判的问题,引入稳健M估计,以位置M估计量和基于位置M估计量的尺度估计量代替均值和标准差重新构造控制函数进行粗差识别。将改进Pauta准则应用于耿达水电站不同类型的测点序列,通过对比原始序列、人工剔除离群点序列和基于M估计量的参数估计与粗差识别结果探究了Pauta准则改进的可行性和合理性;并分析对比存在离群点序列和正常序列探究了改进Pauta准则的适用性。
1 基于M估计量的Pauta准则改进方法
采用Pauta准则识别粗差的前提条件是测值序列服从正态分布N(μ,σ2),且样本数据量较大[11],其控制函数如式(1)所示:
μ(Xi,n)-3σ(Xi,μ,n)≤Xi≤μ(Xi,n)+3σ(Xi,μ,n)
(1)
式中:Xi为实测值;μ为数据序列均值;σ为标准差;n为观测值个数。
大坝安全监测数据一般样本量较大,但通常会由于监测仪器故障、外界环境因素扰动而导致监测序列中存在离群点,从而偏离Pauta准则关于正态分布的假定,出现异常值漏判问题。本文引入M估计量改进总体位置参数和总体尺度参数以代替传统的均值μ和标准差σ,从而提高Pauta准则的耐抗性和稳定性。
1.1 总体参数改进
(1)总体位置参数改进。M估计量是一种加权均值,其权重依赖于数据,可充分利用监测数据序列的有效信息,基于权重函数ω的加权均值Tn为[12]:
(2)
MAD=mediani{|xi-M|}
(3)
式中:xi为样本序列观测量;n为序列样本个数;c为细调常数;M为样本序列中位数;median(·)函数返回给定序列的中位数;Sn是辅助尺度估计,通常取中位数离差MAD,即各个观测量到中位数M的距离的中位数。
(2)总体尺度参数改进。标准差是数据序列最常用的尺度估计量,但由于标准差的运算需要均值 ,对样本中的离群点同样缺乏耐抗性与稳健性[13]。因此基于以上M估计量有尺度估计[14]:
(4)
式中:ψ函数为目标函数的导函数;ψ′函数为ψ函数的导函数。
(3)M估计函数选取。Huber(1972)、Andrews(1972)、Hampel(1974)和Tukey(1977)等人均提出了不同的目标函数形式[15],本文在对比不同权函数形式的基础上引入Tukey双权估计量,其目标函数ρ(u)、ψ函数ψ(u)、ψ′函数ψ′(u)和权重函数ω(u)如图1所示。

图1 Tukey双权 M 估计量函数图Fig.1 Function diagrams of Tukey Tukey Bisquare
1.2 控制函数改进
由鲁棒性更好的位置M估计量Tn和基于位置M估计量的尺度估计量ST代替均值μ和标准差σ重新构造控制函数,则式(1)可以改写为:
Tn-3ST≤Xi≤Tn+3ST
(5)
因此,基于M估计量的Pauta准则可计算得到实测值的控制上下限“T±3ST”,当实测值Xi在控制范围以内,则判断其为正常值;否则为异常值。
2 工程应用
耿达水电站位于岷江上游右岸支流渔子溪上,主要建筑物由拦河闸、非溢流坝、沉沙池等水工建筑物组成,其监测项目主要包括环境量监测、大坝变形监测、坝基扬压力监测、绕坝渗流监测等。监测数据离群类型主要可以分为单点及多点离群型数据、台阶型数据和震荡型数据,因此本文选取典型“多点离群型”测点L14(水平位移)、“台阶型”测点GL09(垂直位移)、“震荡型”测点UP05(扬压力)和“正常序列”测点EX14(水平位移)为例进行分析,各测点序列基本特性如表1所示。
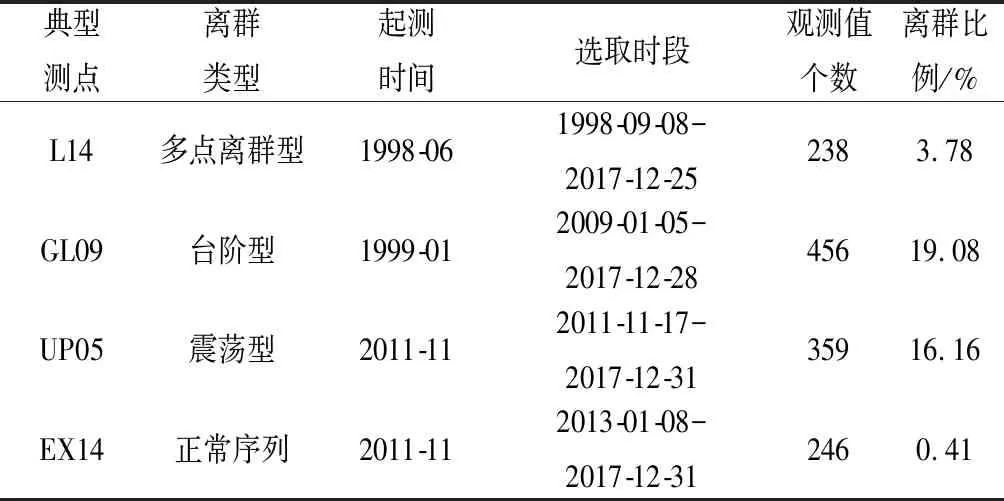
表1 典型测点序列特性Tab.1 Characteristics of typical measuring point sequences
2.1 总体参数改进效果
(1)总体位置参数改进效果。分别计算测点L14、测点GL09、测点UP05原始数据序列的均值、人工剔除离群点序列均值和位置M估计量,如表2示。可以看出含离群点序列的Tukey双权估计量非常接近于人工剔除离群点序列的均值,而原始序列均值与剔除离群点序列的均值相差较远;对比测点EX14数据序列的均值和M估计量计算结果发现,两种位置参数估计值相差不大。因此,可以明显看出基于残差平方和的目标函数计算的均值对离群点非常敏感, M估计量的抗扰动性明显优于均值。

表2 典型测点M估计量与均值对比表Tab.2 Comparison of M-estimator and mean of typical measuring points
(2)总体尺度参数改进效果。再分别计算上述各典型测点原始数据序列的标准差、基于位置M估计量的尺度估计量,并将其与剔除离群点后计算的标准差进行对比,如表3示。可以看出,含离群点序列的基于位置M估计量的尺度估计量计算结果非常接近于人工剔除离群点序列的标准差,而保留离群点的原始序列计算的标准差偏差较大;对比测点EX14的标准差和基于位置M估计量的尺度估计量发现,两种尺度估计的计算结果几乎一致。因此,基于位置M估计量的尺度估计量的抗扰动性明显优于标准差。
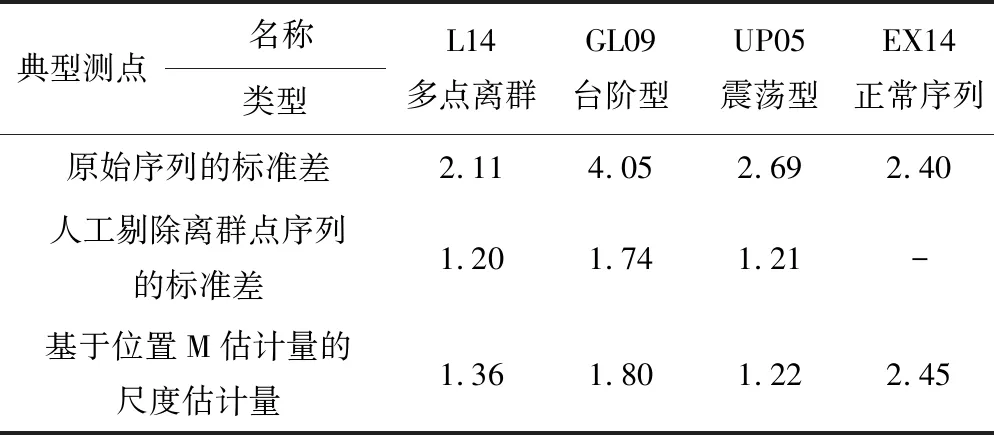
表3 典型测点基于位置M估计量的尺度估计量与标准差对比表Tab.3 Comparison of the scale estimator based on location M-estimation and standard deviation of typical measuring points
综上,M估计量和基于位置M估计量根据样本距离中心程度的远近赋予不同的权重而具有较强抵抗离群点的能力,可得到正常模式下的最佳估计值;并且当无离群点时两种方法的参数估计结果一致。
2.2 粗差识别效果
由改进的Pauta准则计算上述典型测点的控制限,并将其与传统的Pauta准则控制限进行对比,进行粗差识别,各测点实测值和控制限过程线如图2-图5所示。

图2 测点L14实测值及控制限过程线(多点离群型)Fig.2 Actual values and control limits of measuring point L14 (Multipoint-outliers type)
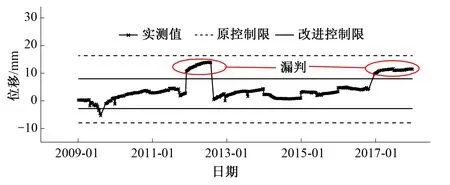
图3 测点GL09实测值及控制限过程线(台阶型)Fig.3 Actual values and control limits of measuring point GL09 (Step type)
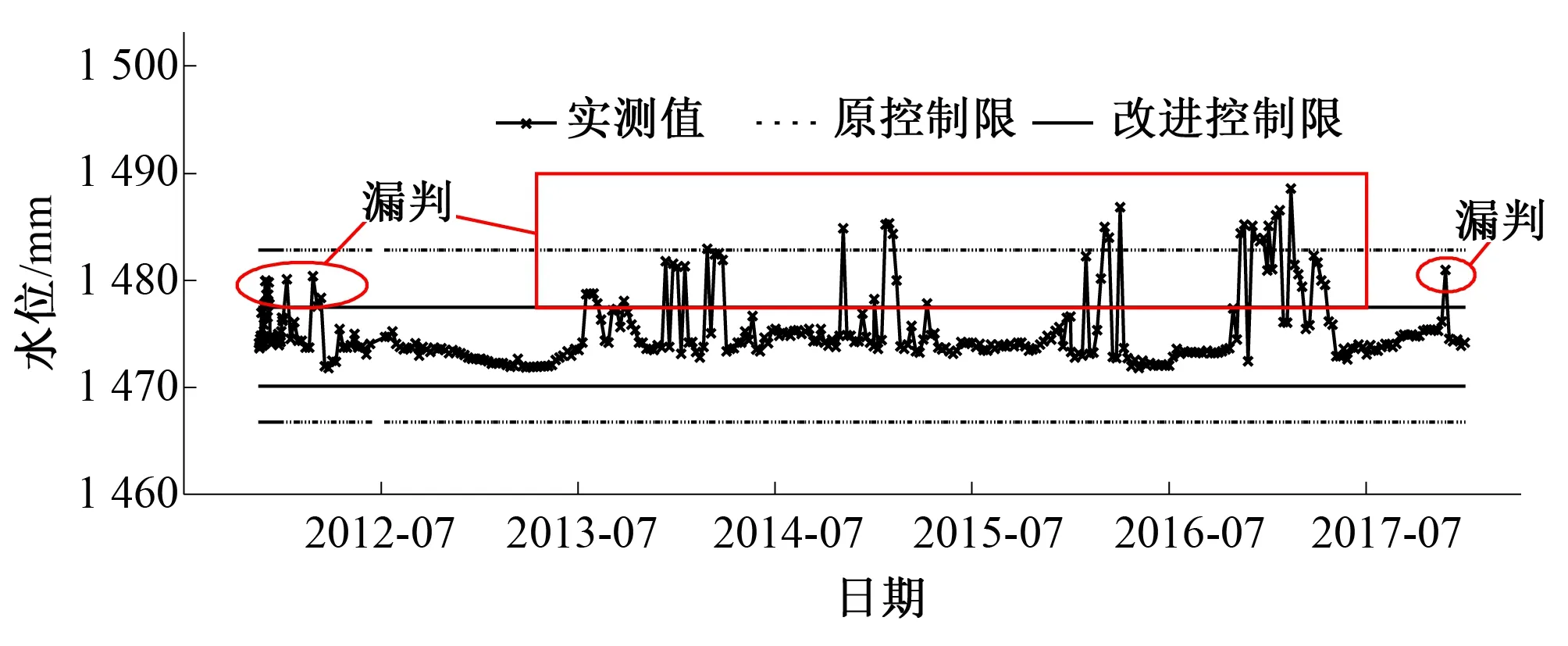
图4 测点UP05实测值及控制限过程线(震荡型)Fig.4 Actual values and control limits of measuring point UP05 (Oscillatory type)

图5 测点EX14实测值及控制限过程线(正常序列)Fig.5 Actual values and control limits of measuring point EX14 (Normal sequence)
当监测数据无可避免地存在较多离群点时,监测序列将不再符合Pauta准则关于正态分布的假定,均值和标准差不再反映数据序列特性规律,由此计算的控制限“μ±3σ”将会被拉向离群点而变宽,使得传统Pauta准则出现异常数据漏判的问题,如测点L14在2009年10月6日出现的测值-5.90,测点GL09在2017年12月31日出现的测值11.41以及测点UP05在2017年11月26日出现的测值1 480.97采用传统Pauta准则时均未被识别为异常突变,而采用改进的Pauta准则则消减了离群点的不利影响,有效解决了传统方法的漏判问题,粗差识别精度大大提高,计算结果如表4示。
对于正常测值序列,两种准则的控制限差别不大,识别效果一致。如正常序列测点EX14在2017年12月31日出现的异常突变值15.15,传统Pauta准则与改进准则均识别为异常测值,如图5和表4示。因此,改进的Pauta准则可同时适用于服从正态分布和含有较多离群数据而偏离正态分布的数据序列,适用性较强。

表4 传统Pauta准则与改进Pauta准则粗差识别效果对比表Tab.4 Comparison of gross error identification effect of traditional and improved Pauta criterion
3 结 论
本文针对大坝安全监测数据粗差识别中常用的Pauta准则进行了较为深入的研究,通过对传统方法的改进,为识别监测数据中的异常数据提供了一种高效合理的方法,并将其运用于耿达水电站,得到的结论如下:
(1)针对传统Pauta准则粗差识别中的异常值漏判问题,引入稳健M估计构造了新的控制函数,位置M估计量和基于位置M估计量的尺度估计量消除了离群点对均值和标准差计算的不利影响,控制限的设置更加合理。
(2)通过对比分析耿达水电站不同离群类型的典型测点原始序列、剔除离群点序列、原始序列基于M估计量以及离群序列和正常序列的总体参数计算结果发现,当实际监测数据含有较多离群点时基于M估计的参数估计不会严重偏离真实水平;当实际监测数据无离群点时,基于M估计的参数估计与传统方法基本一致。
(3)通过对比分析耿达水电站不同类型的典型测点采用传统Pauta准则和改进准则的识别效果发现,实际监测数据偏离正态分布时改进Pauta准则可以有效减少异常值漏判问题;当实际监测数据服从正态分布时,两种方法识别效果一致。
□
