风速时间序列复杂度分析
2019-08-29王勇马惠群王起峰
王勇,马惠群,王起峰
(山东电力工程咨询院有限公司,山东 济南,250013)
风力系统是一个复杂的系统,准确的风速资料对风资源评估以及电力系统的调度运行具有极其重要的作用。风速的复杂度分析是十分重要的问题。然而,大部分学者将研究重心放在了短期风速的预测上[1-2],并未对实际观测数据进行足够的分析。气象站与测风塔由于下垫面及周围环境的不同,其统计规律虽基本一致,但二者有着明显的不同。而样本熵[3-4]可以用来刻画时间序列的复杂度,广义极值理论[5]则可以看出相似数据分布的不一致性。因此,本文采用广义极值分布理论和多尺度熵模型对测风塔不同高度以及气象站逐时风速序列进行复杂度分析,以研究其统计规律的异同性。
1 广义极值分布理论
经典的极值理论指出,无论随机过程母体如何分布,其大量相互独立的数据样本极值均会服从三种分布形式的一种。可以总结为统一的广义极值分布[6],如下:
(1)
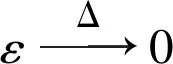
2 多尺度熵模型
多尺度熵方法[7]是一种可以分析多尺度时间序列的方法,该方法刻画时间序列在不同时间尺度上的无规则和复杂程度。
1)给定一个一维离散时间序列,构件连续粗粒化的时间序列;
2)样本熵的计算方法为:
①对于一个N时间序列{u(j):1≤j≤N},对其重新构造m维矢量{Um(i):1≤i≤N-m+1};
②对于每一个标量i,计算每一个矢量u(i)与u(j)的距离,其最大距离定义为:
d[u(i),u(j)]=max[|u(i+k)-u(j+k)|]0≤k≤m-1
(2)
③定义B为矢量Um(i)与矢量Um(j)距离容限r范围内的个数,A为Um+1(i)与Um+1(j)距离容限r范围内的个数,则样本熵的计算公式为
(3)
本文中m取值为2,r取值为0.2*SD(方差)。
3)多尺度熵值体现了序列在不同的时间尺度上的无规则性。熵值越小,说明序列值在时间尺度上的自相似性越高,序列复杂度越低。
3 实例分析
3.1 广义极值分析
以山东一风电场为例,本风电场前期设立测风塔一座,分别在80m、70m、50m、30m和10m五个高度设置了风速仪。本文收集了测风塔1年的逐时风速数据,并收集气象站同期逐时数据进行研究。风速数据统计特征值见表1和图1。
由图1和表1可知,随着高度的减小,风速均值和均方差均不断减小,气象站比测风塔10m的均值和均方差都小。偏态系数和峰度系数则随着高度的减小不断变大,气象站统计值基本位于30m和10m之间。
表1 测风塔不同高度及气象站风速数据统计特征值
Table 1 Statistical eigenvalues of wind speed data at different heights of wind towers and meteorological stations

项目个数平均值均方差偏态系数峰度系数80m87606.2532.9930.6653.90570m87606.0422.9190.6854.08550m87605.6342.6990.8114.79230m87604.9802.4501.1595.95610m87603.7012.2961.5476.579气象站87602.5951.6871.4255.948

图1 测风塔不同高度及气象站风速数据统计特征值Fig.1 Statistical eigenvalues of wind speed data at different heights of wind towers and meteorological stations
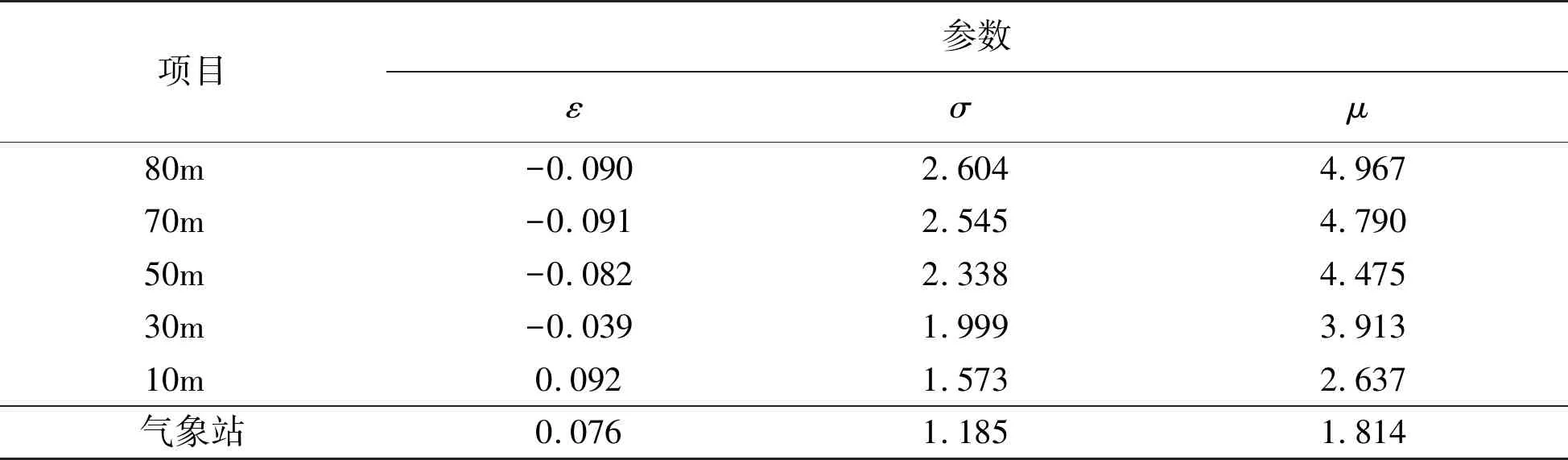
采用极大似然法计算广义极值分布的参数,见表2,测风塔不同高度及气象站风速分布曲线见图2。
表2 广义极值分布参数表
Table 2 Generalized extreme value distribution parameters table
项目参数εσμ80m -0.0902.6044.96770m -0.0912.5454.79050m -0.0822.3384.47530m -0.0391.9993.91310m 0.0921.5732.637气象站0.0761.1851.814
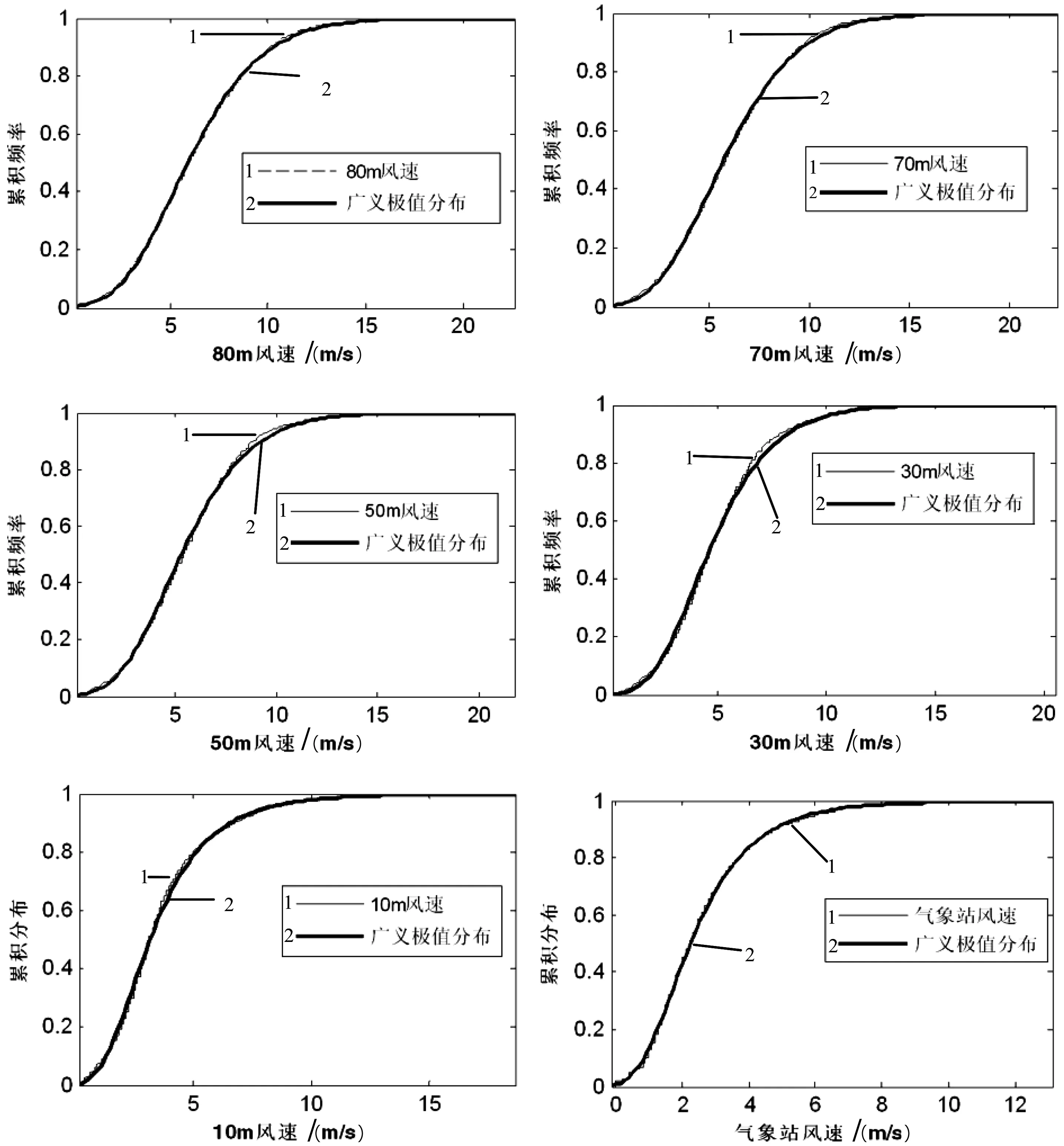
图2 广义极值分布图Fig.2 Generalized extreme value distribution graph
由图2和表2可知:
1)80m、70m、50m和30m高度的风速数据广义极值参数ε是小于0的,也就是说这几个高度的风速数据比较符合极值II型,Frechet分布;而10m高度风速和气象站风速数据广义极值参数ε是大于0的,也就是说这两组风速数据比较符合极值III型,Weibull分布。
2)从参数来看,80m、70m、50m和30m的ε基本成上升趋势,即随着高度的降低,ε不断增大,越来越靠近0,也就是越来越像极值I,Gumbel分布靠拢;气象站参数ε小于测风塔10m高度处的ε;σ和μ是随着高度的减小而减小的。
3)从分布的拟合性来看,80m、70m、50m和30m的风速分布随着高度的降低拟合度越来越差,且在风速较大处风速数据的累积频率均大于广义极值分布,而风速较小处风速数据的累积频率均小于广义极值分布,二者重合风速随着高度的不断降低而降低;10m风速和气象站风速则成相反的趋势,即在风速较大处风速数据的累积频率均小于广义极值分布,而风速较小处风速数据的累积频率均大于广义极值分布,气象站风速拟合程度比10m风速拟合程度要高。
3.2 多尺度熵分析
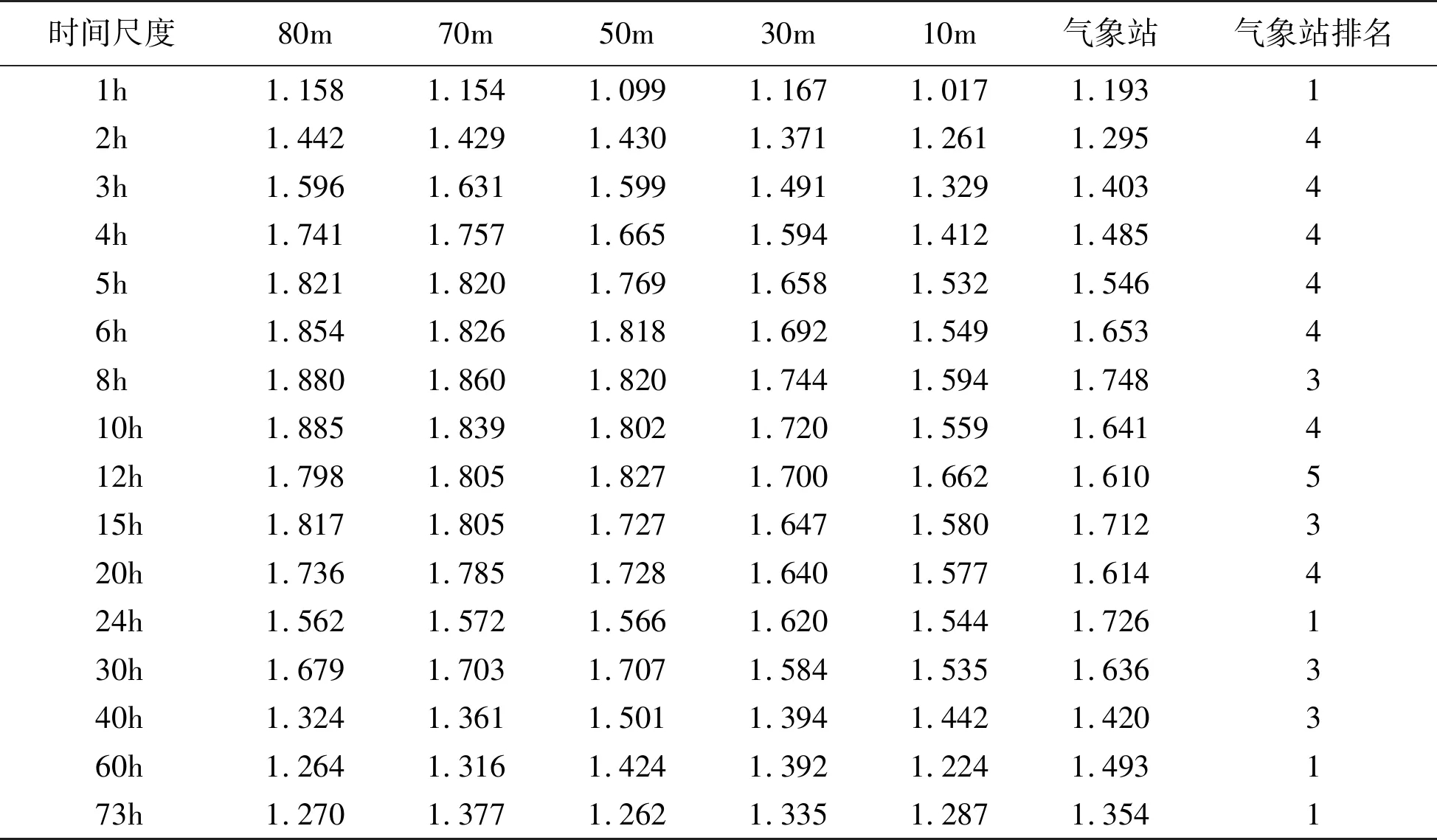
由于每组数据均为8 760个,因此,在进行多尺度熵计算时,本文选取100h以内可以被8 760h整除的小时数作为研究对象,将8 760h数据按时序平均分成若干份,计算每份的平均值作为粗粒化的时间序列,具体选择的粗粒化时间长度分别为1h、2h、3h、4h、5h、6h、8h、10h、12h、15h、20h、24h、30h、40h、60h和73h。采用公式(2)和公式(3)分别计算不同时间尺度下风速序列多尺度熵值,见表3和图3。
表3 不同时间尺度下风速序列多尺度熵值
Table 3 Multi-scale entropy value of wind velocity series at different time scales
时间尺度80m70m50m30m10m气象站气象站排名1h1.1581.1541.0991.1671.0171.19312h1.4421.4291.4301.3711.2611.29543h1.5961.6311.5991.4911.3291.40344h1.7411.7571.6651.5941.4121.48545h1.8211.8201.7691.6581.5321.54646h1.8541.8261.8181.6921.5491.65348h1.8801.8601.8201.7441.5941.748310h1.8851.8391.8021.7201.5591.641412h1.7981.8051.8271.7001.6621.610515h1.8171.8051.7271.6471.5801.712320h1.7361.7851.7281.6401.5771.614424h1.5621.5721.5661.6201.5441.726130h1.6791.7031.7071.5841.5351.636340h1.3241.3611.5011.3941.4421.420360h1.2641.3161.4241.3921.2241.493173h1.2701.3771.2621.3351.2871.3541
由表3和图3可知:

图3 不同时间尺度下风速序列样本熵值Fig.3 Sample entropy value of wind velocity series at different time scales
1)研究范围内不同高度处风速的样本熵基本在时间长度为8~12h间达到最大值。
2)在样本熵达到最大值之前,基本成增加的趋势,而后呈现减小的趋势;气象站数据锯齿状形式(高低间隔)更加明显;
3)气象站风速数据样本熵大于测风塔相同时间尺度的样本熵。
4 结论
本文以山东某风电场和相邻气象站一个测风年的逐时数据为基础,采用广义极值分布和多尺度熵模型进行风速时间序列复杂性分析,得到结论如下:
1)测风塔除10m高度外的风速数据更符合Frechet分布;而10m高度和气象站风速数据更符合Weibull分布;
2)随着时间尺度的增大,不同高度风速数据的复杂度首先变高,在8~12h处样本熵达到最大值,然后复杂度逐渐降低;随着高度的增加,其复杂度呈增长的趋势;
3)气象站风速数据样本熵大于测风塔,且其呈现锯齿状的规律。
