改进蚁群算法的Storm任务调度优化
2019-08-29
(西安理工大学 自动化与信息工程学院,西安 710048)
0 引言
随着大数据时代的到来和互联网的飞速发展,我们生活中的一切都被数据所记录,这些数据量已经超过了我们的想象。为了分析和处理这些数据,学者们提出了许多种类的分布式框架,如Hadoop中的MapReduce框架等,但是大多数框架都是批处理框架。尽管这些框架擅长批处理,但其处理速度都难以保证延时低于5秒。这类批处理框架无法满足许多项目当中对结果需要实时反馈的要求,这时Storm流计算框架应运而生。Storm是一个免费开源、分布式、高容错的实时计算系统,可以使持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求;Storm经常用于实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域;Storm的部署管理简单,而且Storm对于流数据处理的优势也是其它框架无法比拟的。
Apache Storm的默认任务调度机制是采用Round-Robin(轮询)的方法,即Storm提交的拓扑作业按照总的任务数量平均分配给各个节点。其忽略了不同节点间的性能、负载及节点间的通信问题,使得各个节点间的资源不能充分利用。结果导致Storm工作时效率下降。所以Storm能够合理快速的处理数据,其任务调度非常重要。针对Storm任务调度存在的优化问题,国内外已有学者对其进行研究。文献[1]提出一个实现资源系统感知的资源调度优化算法R-Storm,R-Storm是通过把资源分为两类,针对内存的计算资源和网络的计算资源,根据两种资源对不同节点的分配来实现调度任务,最终实现资源利用率最大化、提高总体吞吐量同时最小化网络延迟。文献[2]提出一个根据流量感知的资源调度优化算法T-Storm,T-Storm利用加速数据处理用于分配和重新分配任务的有效流量感知调度,动态地减少节点间和进程间的流量,同时确保没有工作节点过载。文献[3]提出一种实时高效资源调度和优化框架,称为重新流(Re-Stream),重新流描绘了能量消耗和响应之间的数学关系,利用分布式模型对数据流图进行建模,重新分配利用高效的启发式和关键路径调度机制完成任务调度优化。文献[4]提出了一种低复杂度的随机调度方法和优化框架—云集群中的图,这些图表随着时间的推移而变化,进而任务调度的优化。文献[5]提出一种分层阶段调度算法,该算法是通过降低进程和进程节点与节点之间的开销来完成优化调度。文献[6]提出了一种基于Topology的优化调度策略。该策略比Storm自带的默认调度策略拥有更高的流事件处理效率,且实施在分支结构较多的Topology上效果比Storm默认调度策略更优。文献[7]提出了基于启发式均衡图划分算法的调度策略,通过对Storm建立调度模型,将负载检测作为调度器的输入实现动态并行参数优化和重调度优化,最终减少集群节点间的数据发送率,并且保持节点间负载均衡。虽然以上这些算法对任务调度都有一定的效果,但是与各自还有些不足存在。
文献[1,2,3]中的算法中的配置完全依赖工作人员去自己设定,不能通过算法自身反馈来获得,不利于于实际应用;文献[4]中的算法不能完全移植到storm系统当中;文献[5]没有考虑到自身计算开销的大小;文献[6]中的算法没有考虑跨界点传输时的通信问题;文献[7]再划分图时,没有考虑虑顶点权重,负载均衡上存在问题。在已有文献中对于Storm默认调度算法优化中尚存在问题,针对这些问题本文提出本文提出一种改进蚁群算法的storm任务调度优化算法。结合storm拓扑与蚁群算法,本文通过大量实验得出蚁群算法在storm任务调度中迭代次数、启发因子的最优取值范围,再引入Sigmoid函数对信息素挥发因子进行改进,信息素会随迭代次数的变化自适应调节,最后把各节点的资源(CPU、内存、磁盘等)与蚁群算法中信息素联系起来从而优化了storm任务调度。
1 Apache storm
1.1 Storm作业模型
Storm是Twitter开源的实时数据流计算系统,已经收录到Apache的孵化器中,由Clojure和Java语言开发。其借鉴了Hadoop的计算模型,Hadoop运行的是一个Job,而Storm运行的是一个Topology,Job是有生命周期的,而Topology是个Service,并且是不会停止的Job。图1展示了一个简单的Storm拓扑,包括一层输入spout和两层bolt。为了保持性能,Storm可以根据需要增加blot的并行性。拓扑是Storm的计算组织机制。它是用有向无环图(DAG)来表示的。众所周知,图是由顶点(节点)以边相互连接而成的结构。在这里,边是有向的,这意味着数据只能沿着边单向流动。这里的图是无环的,说明边的连接不会形成回路。否则,数据会在拓扑中无限流动。
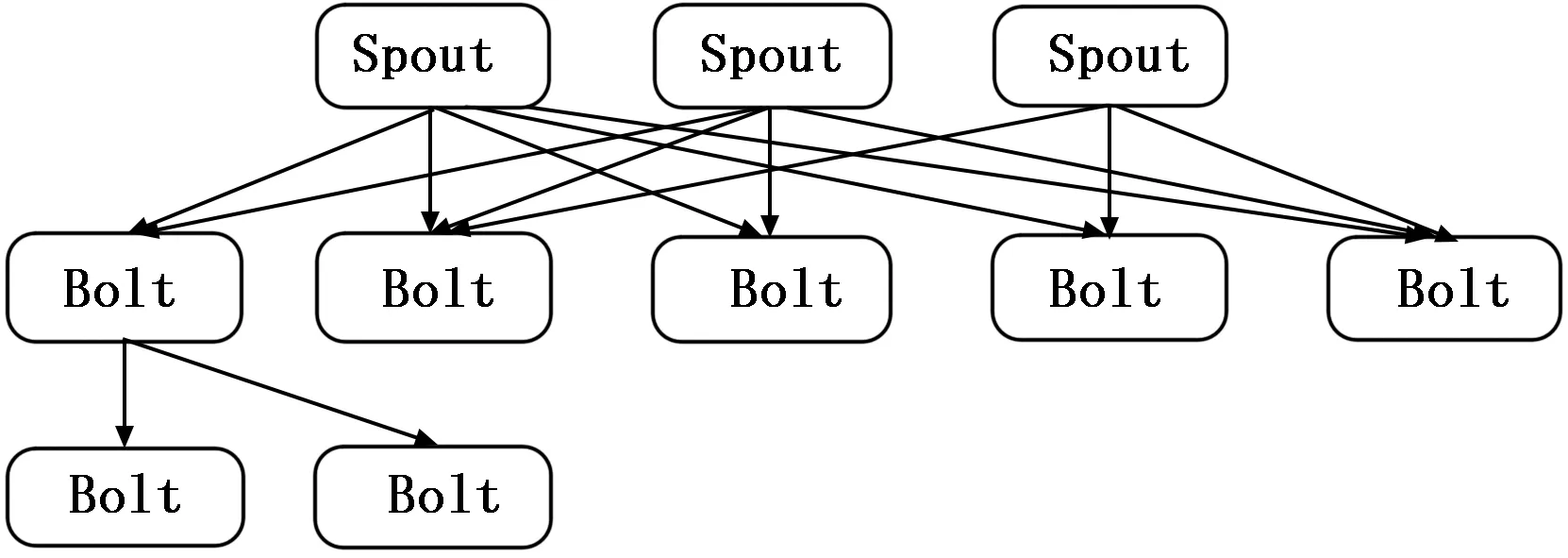
图1 Storm拓扑
1.2 Storm默认调度策略
在Storm 集群中,Storm提交的拓扑作业按照总的任务数量平均分配到Supervisor的一作节点上,但是它忽略了不同节点的负载不同、性能不同,节点间的通信和进程间的通信问题。因此,Storm默认调度可能导致高性能的工作节点的资源空闲,低性能的工作节点负载过重等问题以至于资源不能有效的利用。
2 标准蚁群算法
在蚁群算法中设蚂蚁的数量为m,从第一个节点开始出发,每一只蚂蚁都根据转移概率来选择下一个节点,该节点到下一个节点的转移概率公式为:
(1)
式中,ηis为(i,j)相关的启发函数,τis表示节点i到节点j之间路径的信息素浓度,初始时刻各路径的信息素浓度相同。α为信息素浓度启发因子,代表信息素浓度的相对重要程度,该因子越大,蚂蚁越倾向于选择其它蚂蚁走过的路程;β为启发函数启发因子,表示启发函数的重要程度。
为了防止信息素无限制累加,引入信息素挥发机制,当蚂蚁完成一次从起点到终点搜索后,对每一条边上面的信息素浓度进行更新操作。具体为:
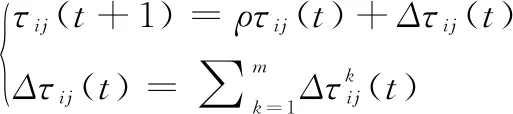
(2)
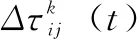

(3)
式中,Q为常数,表示信息强度;Lk为第k只蚂蚁在本次迭代中走过的路径。
3 蚁群算法的改进
3.1 更改启发因子α与β
启发因子反映蚂蚁在运动过程中所积累的信息量,指导蚁群搜索过程中的相对重要程度,其值越大,蚂蚁选择以前走过路径的可能性就越大,搜索的随机性减弱;而当启发因子值过小时,则易使蚂蚁的搜索过早限于局部最优[8]。通过设置更改启发因子,得出启发因子α与β在storm任务调度中的最佳取值范围,从而增加算法合理的搜索指向性。实验结果分析具体在第5节有具体阐述,此处不再赘述。
3.2 挥发因子的ρ改进
信息素挥发因子ρ的的取值不仅影响到蚁群算法的搜索性能,而且不利于算法的收敛。ρ性质为:ρ过大时,信息素挥发快;反之,ρ过小时,信息素挥发慢。在蚁群算法搜索的过程中,随着迭代次数的不断增加,信息素会在某些路径上累积,所以引入挥发因子ρ对其削弱。基于最初信息素累积不明显到迭代完成时累积过大的这种特性,我们引入Sigmoid函数,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的阈值函数,将变量映射到0到1之间。依Sigmoid函数这种性质我们将Sigmoid函数和信息素挥发因子ρ联系起来,蚁群算法的迭代次数为自变量,信息素挥发因子ρ为因变量。这样做刚好契合当蚁群算法在storm任务调度中的作用,在前期挥发因子对信息素的浓度削弱小,而到后期会增大对信息素的浓度削弱程度,随着迭代次数的改变挥发因子ρ自适应改变。信息素挥发因子ρ的表达式如(4):
(4)
式中,x代表迭代次数,当a取迭代次数的二分之一时效果最好,b可以控制s形曲线的胖瘦,引入变量b可以在工程当中去调节b的取值从而达到优化的目的。在第5节测出最优迭代次数,根据最优迭代次数计算出b的最优取值。信息素挥发因子ρ与迭代次数x的关系如图2所示。
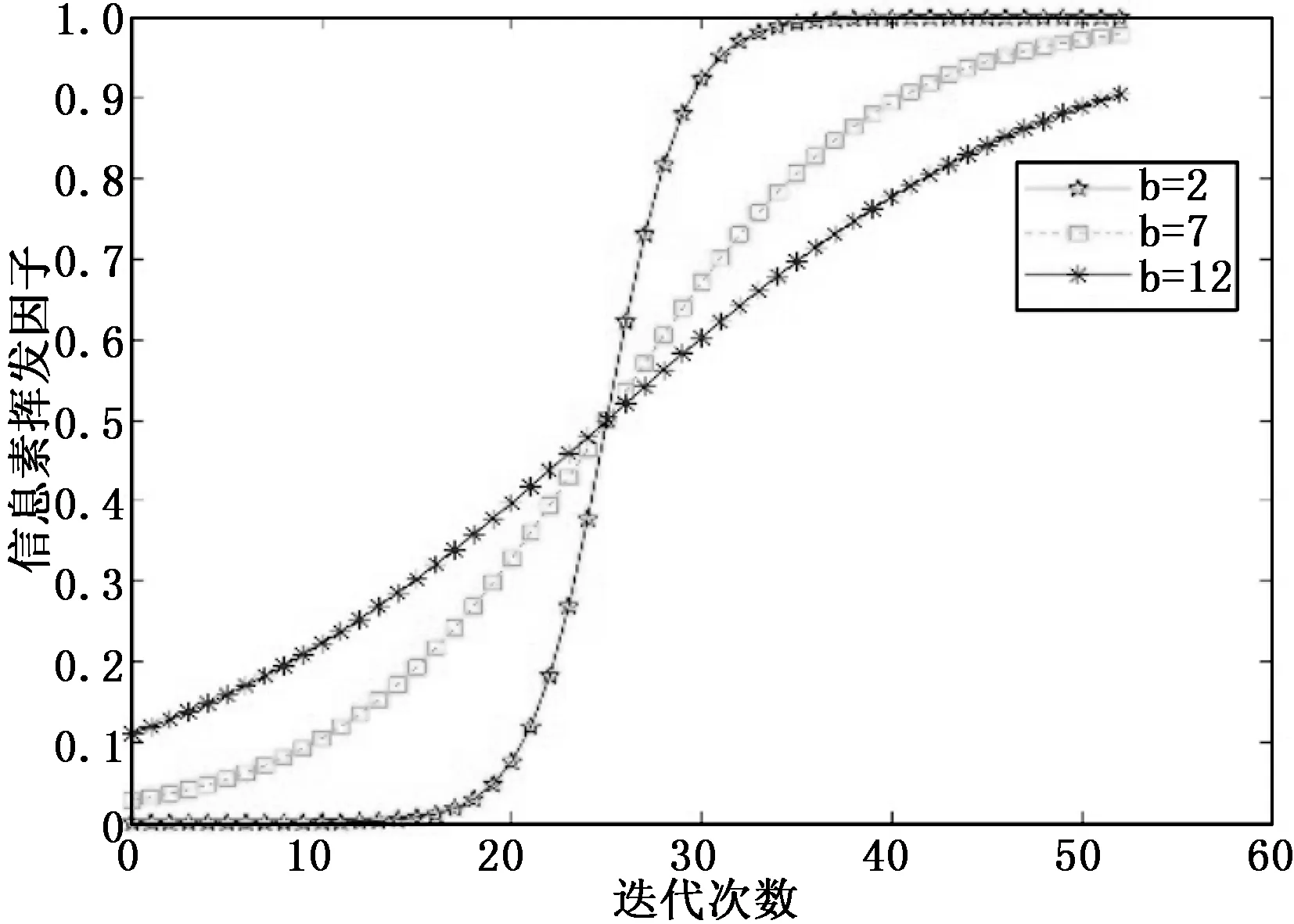
图2 Sigmoid函数
在第5节测出蚁群算法的最优迭代次数为50次左右,从而根据Sigmoid函数特性去设定(4)式中a取25。实验尝试了b的取值对算法结果的影响,找到b的最优取值为6左右。
3.3 改进信息素浓度更新策略和负载均衡的优化
ZooKeeper是Google开源的实现的分布式应用程序协调服务大数据组件,它可以为分布式应用提供一致性服务,包括:配置维护、域名服务、分布式同步、组服务等。Zookeeper可以得到各个节点的心跳信息,Nimbus周期性的利用Zookeeper上关于各个节点的可用资源情况。设节点上CPU信息素用c表示,内存信息素用m表示,磁盘信息素用d表示,网络信息素用n表示。为了防止超负载,把每一个参数的最大值设定为、、、。此时节点的信息素为该节点的各类信息素加权和,分别用e、f、g、h代表CPU、内存、磁盘、网络资源的权重,可以通过改变某类信息素的权重来增强或削弱该类资源对计算的影响。
(5)
蚁群算法在计算过程中会使得某些节点资源累积过高(表现为信息素累积较高),这些节点会始终被分配任务;另外那些节点因为信息素浓度较低没有被分配任务从而造成负载不均衡。为此,引入控制负载因子s,sc表示已经完成任务量,ssun表示任务的总量,τk代表已经完成了sc任务时的信息素,负载因子s通过优化了信息素浓度来防止负载不均衡。
(6)
4 算法描述
4.1 算法预完成时间
在Storm任务调度中上,将Topology中的n个tasks线程分配到m个Supervisors工作节点上,有n>m。设:n个任务集表示为T={t1,t2,…,tn},其中ti(i=1,2,…,n)表示第i个task线程;用SV={sv1,sv1,…,svj}表示m个Supervisor节点集和,其中svj(j=1,2,…,m)表示第j个Supervisor节点。设etij为任务ti在节点svj上的预测完成时间,Ti代表i线程所需资源(CPU,内存等)的多少,Rj代表j节点当前所剩余的资源。则整个Topology的tasks分配到Supervisor节点上的预测完成时间可组成矩阵ET[n,m] 可表示为:

(7)
式中,etij=Ti/Rj。
4.2 改进后蚁群算法的概率计算公式
蚁群算法中蚂蚁由节点h转移到节点j的状态转移概率公式如(8):
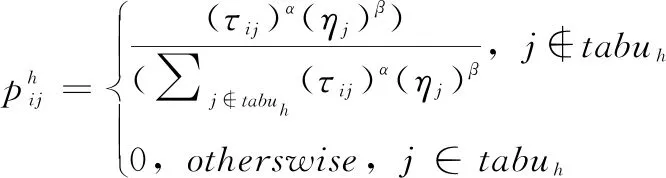
(8)
式中,τij为从节点i到节点j的信息素;ηj=1/eti,其中eti为ti任务的预期完成时间;α和β为启发因子;tabuh(h=1,2,…m)为不允许蚂蚁在走的节点,tabuh会随着作业进行而不断的改变。
4.3 算法步骤
第一步:初始化所有参数;
第二步:设置最大迭代次数;
第三步:将任务分配到各个节点;
第四步:依据状态转移概率选择下一节点;
第五步:算法达到最大迭代次数输出结果,否则转移到第三步。
5 实验结果和分析
5.1 实验环境
集群由8台物理机器组成:master、slave1、slave2、slave3、slave4、slave5、slave6、slave7;每个节点配置4个slot;每一个节点的资源配置都为2.7 GHz CPU,4 GB内存,2 TB硬盘,10 Gbit带宽的LAN。各个节点IP等信息如图3所示。主服务进程部署在master节点,子服务进程都在其余7个slave节点上。经过调研和测试采用以下版本组合系统整体稳定性比较高,基础框架版本分别是:Centos:6.5、Hadoop:2.7.3、ZooKeeper:3.4.6、Hbase:1.2.4、Kafka:0.72、Storm:0.82、Storm-kafka:0.8.0-wip4。
图3 集群信息
本实验选择使用RandomTextWriter[9]生成随机单词文本作为测试数据(数据量大小可以人为改变),做WordCount单词统计任务。因为单词是随机生成的,所以各单词出现的频率不尽相同,因此在实际生产环境中具有一定的代表性。
5.2 通过测试寻找迭代次数
夏兰[8]在交通地理最佳路径的研究中中指出蚁群算法的最优在65次左右;侯守明等[10]在云任务调度优化中指出蚁群算法的最优在60次左右;尧海昌[11]在轨道交通集群调度问题中指出蚁群算法迭代次数最佳在57次左右。为了分析蚁群算法迭代次数与任务完成时间的关系。基于上述文献于此我们把迭代次数从1依次递增到90,寻找最佳迭代次数。使用RandomTextWriter随机生成300 MB测试数据,对传统蚁群算法和改进的蚁群算法进行测试,测试结果如图4、图5所示。
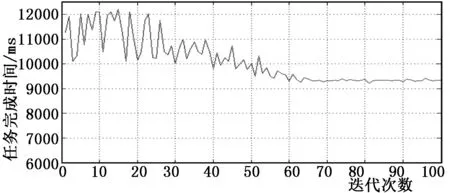
图4 传统蚁群算法的收敛速度与任务完成时间

图5 改进蚁群算法的收敛速度与任务完成时间
综合分析图4与图5可知,传统蚁群算法在迭代次数达到62次时开始收敛;改进蚁群算法在迭代次数达到49次时开始收敛;两者相比较改进蚁群算法收敛速度快。传统蚁群算法在收敛后任务完成时间大约为9 300 ms;改进蚁群算法在收敛后任务完成时间大约为7 300 ms;两者相比较改进蚁群算法完成任务时间快,大约比传统蚁群算法提高了21.5%。
5.3 测试寻找启发因子α与β的最佳取值
简琤峰等[7]在Storm启发式均衡图划分调度优化问题中指出α的最佳范围在0.5~2.5之间,β的最佳范围在4~5.5之间。尧海昌等[11]在基于蚁群算法的轨道交通集群调度算法研究中指出α的最佳范围在3~5之间,β的最佳范围在5~7之间。张志文[12]在AGV路径规划与避障问题中指出α的最佳范围在2~3之间,β的最佳范围在2~4之间。上述文献并没有指定α与β分别具体取什么值时效果最优,为此进行实验测试。使用RandomTextWriter随机生成600 MB测试数据,对改进的蚁群算法进行测试。首先进行粗粒度筛选,让α与β分别由1到10以1为间隔取值,计算出任务完成时间。统计结果得出当α∈[3,7],β∈,[2,6]时任务完成时间最短。其次细粒度筛选,分别让α、β从以0.1为间隔从α∈[3,7],β∈,[2,6]中取值计算出任务完成时间实验结果如图6所示。

图6 启发因子α与β的最佳取值
在图6中x轴代表启发因子α,y轴代表启发因子β,z轴代表平均任务完成时间。由图6可以看出,α=4,β∈,[2,3,5]时算法最优,此时任务完成时间大约在14 200 ms。当α与β分别取6和5,7和6左右时,任务完成时间对应为15 500 ms与16 700 ms,此时由于α与β取值过大造成出现局部最优解;该问题与文献[13]在蚁群算法中参数α、β、ρ设置的研究中得到的结果不谋而合。由实验可知改进蚁群算法在Storm任务调度中α=4,β∈,[2,3,5]时算法达到最优效果。
5.4 负载均衡对比
对于负载均衡我们来用对比测试各节点的CPU利用率来反映各个节点的负载情况。而WordCount业务逻辑处理随机单词的数据集可保证Topology上所有任务节点间的逻辑连线都有大量流事件经过,因此实验可客观展示出不同调度策略在流事件处理过程的各节点在实验当中CPU的使用情况。本实验使用RandomTextWriter随机生成300 MB测试数据,对Storm默认的轮询调度算法和改进的蚁群算法进行测试。图7为Storm默认的轮询调度算法和改进的蚁群算法在运行程序时集群中各个节点CPU的使用情况。

图7 各节点cpu利用率
根据图7我们可以得到Storm默认的轮询调度算法在运行WordCount单词统计任务时,节点之间的CPU利用率的的标准差为0.052,均值为0.461。由标准差和均值可以看出Storm默认的轮询调度算法执行时,各工作节点的负载不均现象较为严重,其中slave7工作节点的CPU负载最高,slave4工作节点的CPU负载最低,二者差值为34%。执行改进的蚁群算法时,节点之间的CPU利用率的标准差仅为0.017,均值为0.342。从以上实验数据可以得出改进的蚁群算法和Storm默认轮的询调度算法相比CPU使用标准差降低了3.5%,平均CPU负载降低了26%。
5.5 任务完成时间分析
在试验中,使用RandomTextWriter随机生成测试数据,生成200 MB、300 MB、400 MB、500 MB、600 MB的随机单词文本数据集进行实验。默认的轮询调度算法和改进的蚁群算法相应规模大小的任务完成时间关系图如图8所示。
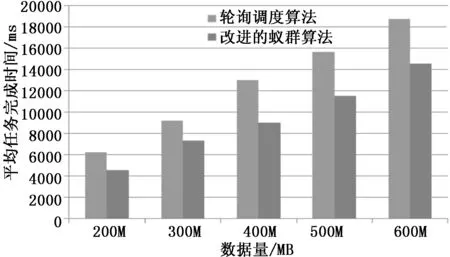
图8 算法完成时间对比
由图8可以看出改进的蚁群算法比默认的轮询调度算法在任务完成时间方面降低了大约21.6%,且随着任务量的增加,轮询调度算法完成时间与改进的蚁群算法差距越来越大。
6 结束语
本文针对Storm的默认任务调度机制中资源分配不合理而导致处理数据延迟问题,提出了改进蚁群算法在Storm任务调度中的优化方案。通过实验找出蚁群算法在Storm任务调度中的最佳迭代次数;测试得出启发因子α与β的最佳取值;引入Sigmoid函数改进了挥发因子ρ,使其可以在算法运行时自适应的去调节。在文最后中将改进的蚁群算法和Storm默认的轮询调度算法做比较,得出改进的蚁群算法比Storm默认的轮询调度算法在平均CPU负载降低了26%同时CPU使用标准差降低了3.5%,在算法效率上Storm默认的轮询调度算法提高了21.6%。得出改进蚁群算法的Storm任务调度明显优于Storm默认的任务调度。
