LKJ人机界面单元显示字符识别的方法
2019-08-28杨清祥白鸿钧
陈 宇,杨清祥,白鸿钧
(河南思维轨道交通技术研究院有限公司,郑州 450001)
列车运行监控装置(LKJ)是中国自主研发的列车运行控制系统体系的核心设备和重要组成部分,在保证列车运行安全方面发挥着重要作用[1]。人机界面(DMI)单元是LKJ中的用户交互设备[2],其显示信息的正确与否直接关系到LKJ能否安全控车。为鉴别DMI显示信息的完整性和正确性,需采用图像识别的方式对DMI显示的字符信息进行辨别,通过与后台信息进行对比,来判断DMI显示结果的正确性。因此,如何对DMI显示字符信息的准确性和完整性进行识别是一个亟待解决的问题。
1 图像字符识别方法
在图像字符识别领域,目前主要采用光学字符识别(OCR,Optical Character Recognition)[3]技术中的单元模式匹配法(Pattern Matching)[4]和特征提取法(Feature Extraction)[5]。
1.1 单元模式匹配法
单元模式匹配法是将每一个字符采用不严格、最为近似的方式与预先保存的标准字体和字号的位图进行比较,将最为相似的字符认定为目标字符;该方式在被识别的内容中出现不同字体时,会导致正确的字符反而不是最近似的错误识别。
1.2 特征提取法
特征提取法是先将单个字符分解成水平线、斜线、曲线等不同的字符特征,然后将这些字符特征与预先保存的字符特征进行比较,将特征最为接近的字符认定为目标字符。该方式拆分难度大、识别时间长,同时,对于汉字特征极为相似或基本相同的字符,识别准确率较低。
鉴于OCR技术在识别中存在不能完全正确识别及识别速率不高的情况,结合DMI显示字符信息的特性,本文设计了一种基于点阵对比方式进行字符识别的方法,此方法是一种完全对比的识别方法,通过将图像字符的点阵数据与字库中的点阵数据进行对比,只有完全吻合时,才判断是目标字符。
2 系统功能设计
对图像字符的识别主要分为图像二值化、字符串定位与剪裁、字符分割、字符识别4个过程,如图1所示。

图1 字符识别流程图
2.1 图像二值化
图像二值化是将一幅彩色图像转换成为只有黑和白两种颜色的图像,并且使文字和背景各用一种颜色,如图2所示。
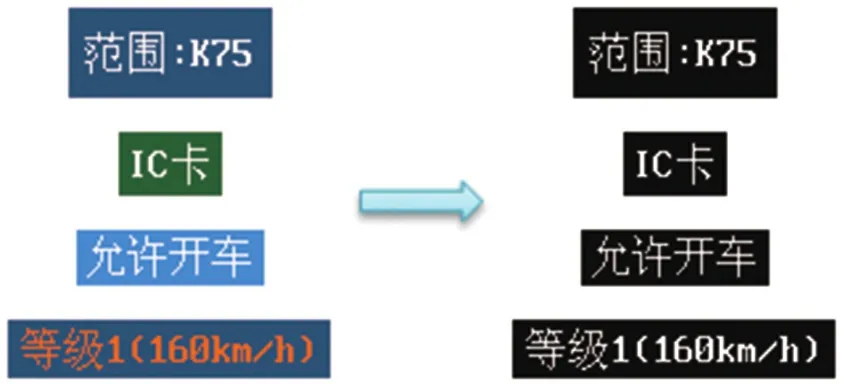
图2 图像二值化转换图
图像字符二值化的主要目的包括以下两点。
(1)被识别图像上的颜色通常多于两种,甚至字体颜色也存在多种的情况。二值化能够将字体颜色转换成白色,背景颜色转换成黑色。
(2)仅有黑白两种颜色的图像,图像尺寸较小,且颜色对比较为明显,便于对字符进行识别。
图像二值化过程主要包含色彩转换、阀值计算、像素二值化、颜色反转4个步骤。
2.1.1 色彩转换
彩色图像中的每个像素都是由红、绿、蓝3种颜色分量组合而成,每种颜色分量按照不同的比例混合,能够搭配出各种各样的颜色。色彩转换的目的是将彩色图像转成灰度图像。

图3 图像颜色分量提取
遍历图像中的每个像素,针对每个像素分别取出它的红、绿、蓝3个颜色分量,如图3所示,假设像素i红、绿、蓝3个颜色的颜色分量分别为Ri、Gi、Bi,如式(1),计算得到灰度值Di:
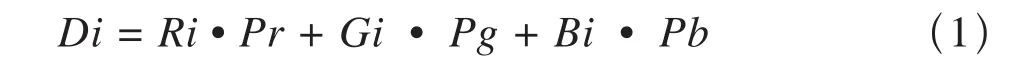
式中:Pr、Pg、Pb分别是红、绿、蓝3个颜色分量的乘法系数,表示红、绿、蓝3个颜色分量对于转换后的黑白图像所起的作用程度,取值范围介于0.0~1.0之间,且三者相加的和应等于1.0。
若将Pr、Pg、Pb三者的值都设置为0.333,则像素转换后的灰度值为红、绿、蓝3个颜色分量的平均值,也可以如式(2)所示。

将整幅图像中每个像素转换完毕之后,即可得到一张只包含有灰度分量的灰度图像,如图4所示。

图4 色彩转换示意图
2.1.2 阈值计算
阈值的作用是将图像中大于阈值的灰度变为一种颜色(通常为白色),而将小于阈值的灰度变为另一种颜色(通常为黑色)。阈值计算的方法很多,这里选用最简单的方法,即统计出灰度图像中的最大灰度值(Dmax)和最小灰度值(Dmin),然后计算二者的平均值T作为阈值,如式(3)所示。
2.1.3 像素二值化
为了使图像变为黑白图像,即前景字体颜色变为白色、背景颜色变为黑色,使用式(3)中计算的阈值,遍历灰度图像中的每个像素,将图像中大于阈值的灰度变为白色,小于阈值的灰度变为黑色,如图5所示。
2.1.4 颜色反转

图5 像素二值化示意图
在某些情况下,经过像素二值化处理后,可能出现背景颜色为白色、前景字体颜色变成了黑色的相反情况。此时,需要将黑白两种颜色进行反转。
首先判断二值化后的图像是否需要反转。判断的方法是,分别统计白色像素和黑色像素的数量,比较黑白像素数量的多少。如果黑色像素少于白色则需要做反转,否则,如果白色像素少于黑色像素则不需要做反转。当判断的结果是需要反转时,遍历二值化后的图像中每个像素,将黑白颜色依次互换。
2.2 字符串定位与剪裁
字符串定位与剪裁是指将字符串的最小图像范围之外的部分剪裁掉,只保留包含有字符串的最小区域。目的是尽量减小图像中其他区域对图像字符识别的影响,并降低在识别过程中的计算时间,如图6所示。
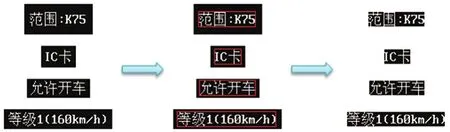
图6 字符串定位与剪裁示意图
字符串定位与剪裁过程需计算出图像中字体所在区域的外接矩形,再将这个矩形区域剪裁出来,仅保留矩形区域内部的内容。
字符串定位与剪裁过程的步骤如下。
(1)先依次遍历二值化后图像的每一行,统计出每一行中前景色(白色)像素的数量[7],如图7所示。

图7 前景色像素数量统计
(2)遍历完所有行后,得到一个一维数组,数组中的每一个元素对应二值化后图像的每一行,表示每一行中前景色(白色)像素的数量。图7对应的数组为[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 15, 5, 18, 33, 14, 27,17, 26, 17, 17, 17, 21, 19, 5, 20, 3, 0, 0, 0, 0, 0, 0, 0,0, 0]。
(3)在数组中找出第1个不为零的元素和最后1个不为零的元素,记录下这两个元素在数组中的序号,如图7中对应的序号分别为10和25, 这两个序号就是字体所在区域外接矩形的上边缘和下边缘。
(4)将上下边缘以外的图像裁掉,仅保留上下边缘之间的部分。如图7仅保留第10行~第25行之间的部分。
(5)效仿(1)~(4),找到字体所在区域外接矩形的左右边缘,并将左右边缘以外的图像剪掉。
通过(1)~(5),得到包含字符串的最小区域的图像。
2.3 字符分割
字符分割[8]采用一种递归的方法,通过不断尝试画分割线,并根据画出的分割线与字符串是否相交决定继续分割还是退回重新画分割线。以此来判别每个字符的边界范围,将字符串中每个字符所占据的区域计算出来,如图8所示。
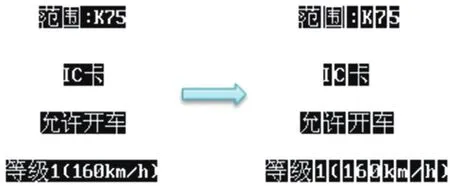
图8 字符分割示意图
2.3.1 字符分割的条件
字符分割需要字符串所使用的字库满足下列条件。
(1)字库中的全角字符所占区域的宽度和高度等于字号。如图8中字号是16号,则该字库中的全角字符所占区域的宽度和高度应等于16。这里指的是所占区域的宽度和高度,不是指字符本身的宽度和高度。
(2)字库中的半角字符所占区域的高度等于字号,宽度等于字号的一半。图8所使用的字库中的半角字符所占区域的高度和宽度分别等于16和8。
(3)字库中的每一个字符(包括全角和半角),所在区域的最左列和最右列必须为背景色。
2.3.2 字符分割流程
字符分割是在图像中针对每个字符找出一根对应的纵向分割线,使得分割线恰好落在两个字符之间,然后依据分割线将图像分割成若干块;为了便于理解,在图像的左右两边也画出了一条分割线,如图9所示。但针对左右两部分存在间隙的左右结构的汉字,应当避免被分割线一分为二,如川、和、好、如等。

图9 分割线示意图
在图像中找分割线之前,应先计算出相邻的两条分割线之间的正确距离,在上述字库的限制条件中已明确图像中字符宽度应等于字号或字号的一半,则相邻两条分割线之间的距离也应等于字号或字号的一半。如图9中任意两条相邻分割线之间的距离应等于16或8。
字符分割线的确定采用从左至右的递归方法,以不断向前迈步尝试和向后回退的方式来判别每个字符的边界范围,并划上分割线,具体分割步骤如下。
(1)设置变量N的初始值为1;
(2)在图像最左边的外侧第N像素处画一条分割线,由于这条分割线在字符左边缘外侧,假设字符的坐标从0开始,则它在图像上的横坐标是-N;
(3)从当前分割线向右方迈步,迈步的步长为字号或字号的一半,若第1次到达图像的此坐标处,则使用字号作为步长,若第2次到达图像的此坐标处则使用字号的一半作为步长,若第3次到达图像的此坐标处,则说明当前的分割线位置是错误的,将当前分割线取消,回退至前一次迈步位置,并重新执行本步骤,若此时已位于图像的最左边缘,应清除所有分割线,将N的值增加1,然后执行(2);
(4)在迈出后的位置尝试画一条分割线,如果分割线与字体不相交,即分割线所在的纵线上没有字体像素,则执行(5),否则,若分割线与字体相交,则执行(6);
(5)将这条分割线与前一条分割线之间的区域假定为一个字符,并将这个区域裁剪出来做字符识别尝试,若字符识别失败,则执行(6),否则,暂时认定本次迈步成功,并执行(7);
(6)进入此步骤,表明向前迈步失败,应将之前画的分割线取消,回退至前一次迈步位置,并重新执行(3);
(7)判断当前所在位置是否已达图像的最右端,如果未到达,执行(3),继续查找下一条分割线,若已达图像的最右端,则执行(8);
(8)进入此步骤,表明所有的分割线都已经成功搜索完毕,将每一次迈步过程中识别出的字符依次连接,形成字符串。
以上步骤流程如图10所示。
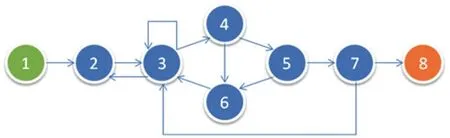
图10 字符分割流程图
2.4 字符识别
字符识别是将图像中每个字符区域的像素信息数据化,与字库中的数组比对,数组中每个字节都相等则输出这个字符,图像中所有字符识别完成连接起来,形成字符串。
字符识别过程主要包含字符居中、图像数据化、字库对照3个步骤。
2.4.1 字符居中
在字符分割过程得到的结果中,大多数情况图像中字符是居中的,但特定汉字、字母、标点符号是无法居中的,如下划线“_”上下不居中,中括号“[”和“]”左右不居中。因此需要对这些特殊字符图像做居中化处理。
2.4.2 图像数据化
进行至该步骤时,图像只包含此单个字符的前景色和背景色,图像的每个像素都是构成字符数据的必要点,以点阵样式呈现,此种图像为字符的点阵图像。把字符图像转化为二进制数据的转化方式如下。
(1)将图像中的前景色的点认为是1,将背景色的点认为是0。
(2)按照先列后行的顺序依次遍历图像中的每个点。
(3)在遍历每一行时,将行内的点认为是1 bit,组成相应的字节数据。
(4)在遍历完成每一行之后,即得到了图像的点阵数据,它存在形式是数组,数组中的每个字节表示8个点的信息。
2.4.3 字库对照
字库对照采用点阵对比的方法来对2.4.2中的字符点阵做识别。点阵对比是指,将数据化后的字符点阵数组分别与字库中的每个字符对应的点阵数组逐个作对比,若两数组的对应字节均相等,则认为此字符就是图像中的字符,取出它的GBK编码,识别成功,否则,认为识别失败[9-10]。
对原图像中的所有字符逐一进行比对,待图像中所有字符串均识别完成后,将每个字符的GBK编码依次连接,形成字符串,至此,字符识别全部完成。
3 系统开发与测试
3.1 开发平台环境
本方法主要是针对数据做转换和处理,不涉及到对操作系统的依赖,可以适用于多种操作系统和开发语言。操作系统可选用Windows或Linux,开发语言可选用C语言、C++语言、Java语言等。
本文选用的操作系统是Windows 7,开发语言是C++语言,并以Visual Studio 2013作为开发环境。
3.2 系统测试
开发完成后,使用该系统测试读取了600张LKJ界面的真实截图,并对识别后获得的结果进行人工核验。经验证字符识别的正确率可达到98%,单次识别时间小于1 s。
4 结束语
本文采用了基于点阵对比的方法,既能实现半角字符和全角字符混合排版识别,又不需要图像处理所必需的大规模计算,且字符识别速率及准确度均较高,能满足对DMI显示字符信息进行准确识别的应用需要。下一步,为适应更高识别速率的需求,在算法实现上可采用汇编编码,或者采用相关的硬件图形卡来辅助实现。该研究结果已在新一代列车运行监控装置(LKJ)软件仿真测试系统中成功应用,实现了对DMI显示字符信息的准确性、完整性的识别,显著提高了识别效率。
