客票电子支付数据审核系统的研究
2019-08-28梅巧玲李天翼
梅巧玲,李天翼,冯 焱
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
铁路客票开启电子支付业务以来,电子支付笔数不断增多,2019年春运期间,铁路12306互联网售票系统的每日最大售票能力提升至1 500万张,伴随着电子支付业务的并发压力不断增大。当用户在支付期间出现网络崩断、系统宕机、铁路客运组织调度或其他不可抗力的意外情况时,有可能引发用户遭遇重复支付、支付后未出票以及银行退款失败等现象,这对用户购票体验造成了极大的影响。
为了能够保证用户安全顺畅地完成电子支付流程,建立符合铁路特点的电子支付数据审核机制十分必要。当前,在大数据审核机制方面,银行、票务以及医院等行业都做出相应研究。在高并发银行ATM前置处理(ATMP)系统中,主要通过建立多指数冲正缓存机制加强系统鲁棒性,提高业务效率[1-3]。在票务方面,缓存服务器集群中的多个线程竞争访问权限,这有效降低了在高并发压力下外部票务系统的访问压力[4-6]。以上研究方案虽然一定程度上解决了电子数据审核问题,但是对于业务流程复杂以及业务量巨大的铁路客票电子支付数据来说,并不完全适合[7]。
本文主要研究在电子支付流程的动态业务环境中,进行规则引擎的定义和业务规则的配置,搭建电子支付数据审核体系。通过系统性能测试,验证了该电子支付数据审核机制可以为用户的电子支付体验提供安全顺畅的保障。
1 基于规则引擎的数据审核机制
在铁路12306互联网售票系统的支付业务中, 数据审核是确保支付数据真实性、可靠性、正确性和完整性的重要环节。在建立数据审核机制时,主要采用规则引擎实现电子支付数据的审核功能。
1.1 规则引擎
规则引擎技术是根据规则中设置的条件,对业务数据进行匹配,从而决定是否执行后续动作的技术。规则引擎是应用程序中的一个组成部件,它的作用是将应用程序代码中随着空间和时间动态变化的部分业务规则剥离出来,在事先定义的语义模块基础上编写业务规则决策方案。在系统需要时由业务管理人员进行配置和管理,对业务系统的数据进行输入和编辑,解释业务规则的同时根据业务规则做出决策引擎。规则管理系统根据业务系统提供查询的入口参数以及相应的业务需求信息,对请求信息进行处理反馈[8]。
规则管理系统向业务系统发送请求消息,业务系统再将请求转发给规则引擎。规则引擎根据服务号将请求信息分配给相应的服务处理模块,以作出准入判断:如果服务信息触发了服务的准入或拒绝条件,则系统不直接将判断结果反馈到业务接口;如果该请求不符合规则引擎的条件,则对业务系统进行规则触发,最终将决策结果反馈到业务系统[8]。规则的触发条件,系统对于符合规则条件的可按照规则设定的优先级别返回编码。业务规则可以分批管理,在每个批次中可以设定规则之间的优先等级,同时,对于不同的规则批次也可以设置优先级[8]。业务规则主要从售票业务规则、退票业务规则和改签业务规则3方面进行说明,如表1所示。
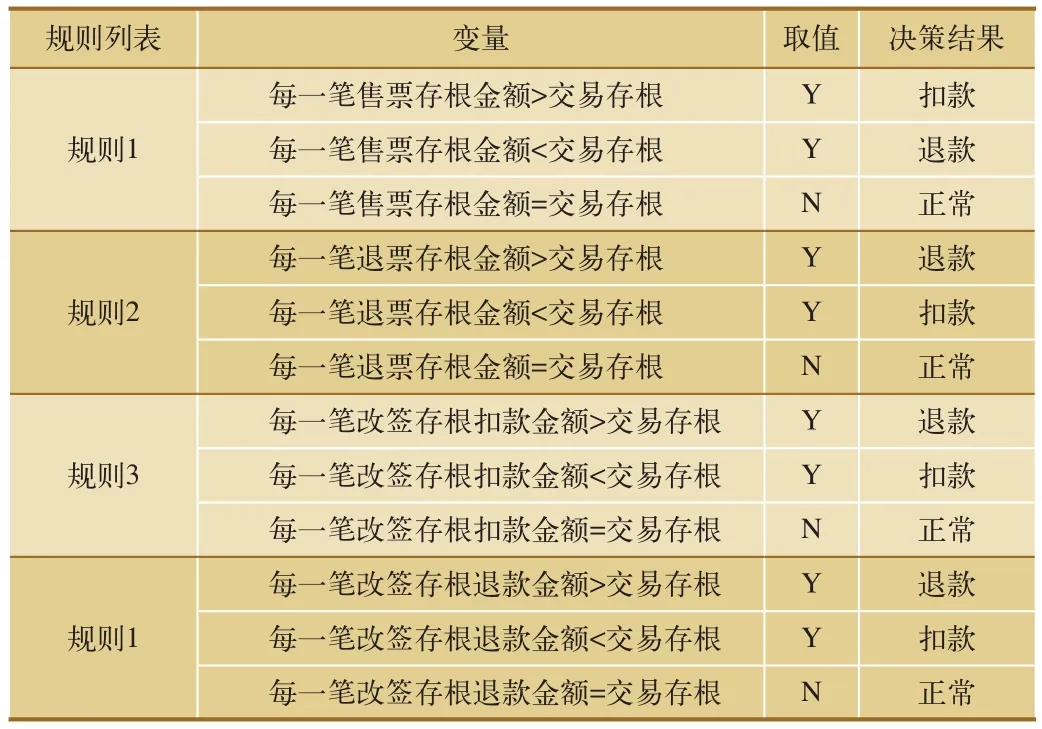
表1 业务规则列表
1.2 配置业务规则
业务规则判定流程如图1所示。由图1可知,每个规则中的条件可以通过优先级判断来设置,也可以设置成相同的优先级并行运算。
业务规则是用于维持业务结构和控制业务行为的业务描述。业务规则描述业务流程中核心的、有价值、有意义的对象、关系和活动[8]。业务规则主要包括两个方面:(1)建立特征审核规则;(2)建立数据审核规则。
(1)特征审核规则的作用是对电子支付数据进行合法性检查,如身份证、售票处代码、操作员账号、购票人信息、数据格式、数据长度、必填数据项等,这些内容需符合对象的基本特征格式。特征审核机制通过各种正确表达式在客户端和后端接口进行形式上的合法性验证。
(2)数据审核规则的功能是对电子支付数据根据业务规则进行校验审核。数据查看规则将电子支付数据与服务器端设定的业务规则进行验证,并根据比较结果来核实数据的正确性和合法性。
规则引擎可用于根据业务需求创建、修改和删除操作单个业务规则,是解析、调用、执行规则包的服务。每个规则应有相应的编码,编码可以由用户自行设定,在满足规则/不满足规则时也可以设定

图1 业务规则判定流程
2 数据审核系统及其功能
在大数据电子数据存储与负载均衡算法优化实现的基础下,搭建了如图2所示的电子支付业务数据审核系统。电子支付数据审核系统在旅客在购票支付环节中出现问题时,对支付数据进行审核校验功能,及时修复反馈故障。该系统分为4个模块,按照顺序分别为:(1)电子支付数据存储模块;(2)电子支付数据同步模块;(3)电子支付数据高效存储运算模块;(4)电子支付数据审核功能模块。
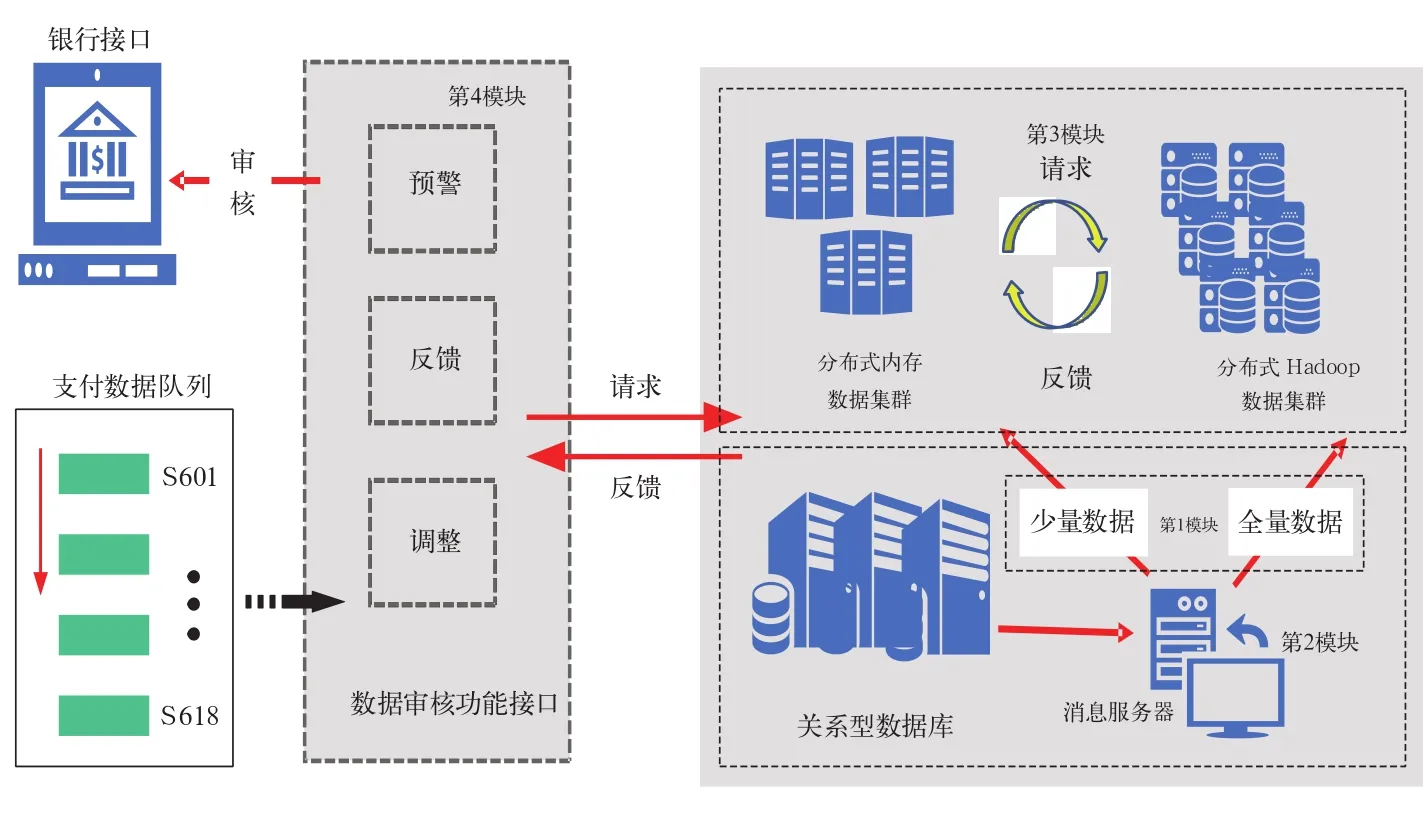
图2 电子支付数据审核系统架构图
2.1 电子支付数据存储模块
电子支付数据存储模块实现了电子支付数据存储,高频访问的数据放到内存中,全量数据放到分布式Hadoop集群中,这些数据都是由关系型数据库产生的。该模块使得电子支付业务数据有据可审,降低了位于最深层次安全网络结构中关系型数据库被直接操作与访问的次数。
2.2 电子支付数据同步模块
电子支付数据同步模块实现了电子支付业务数据同步,由关系型数据库产生后,将数据通过复制服务器、数据同步服务器以及消息服务器实时传输到集群中,将其少量数据和全量数据分别同步至分布式内存数据集群和分布式Hadoop数据集群中。
2.3 电子支付数据高效存储运算模块
电子支付数据高效存储运算模块实现电子支付数据的高效存储与运算两大重要功能,由分布式内存数据集群和分布式Hadoop集群组成,内存数据集群负责数据运算和存储,Hadoop集群负责数据存储,对接电子支付数据审核功能接口,对负载均衡优化算法分配的请求进行处理与反馈。为最大程度提高查询性能,将关系型数据库中的唯一索引设置为Hadoop集群的rowkey,客户端进行查询时,通过login_name模糊匹配,再通过订单号等其他条件拼接rowkey来获取数据。
2.4 电子支付数据审核功能模块
电子支付数据审核功能模块主要通过常用的计算机语言函数实现对电子支付数据预警、反馈和调整。当生成电子支付数据时,电子支付数据审核功能接口会按照电子支付数据关键字段队列以固定频率轮流进行数据对比,主要检查银行服务提供的数据是否与存储在关系型数据库的根数据相同。当用户在支付过程中出现重复支付以及退款失败等问题时,固定频率的轮询审核可以在用户提出投诉之前便提供消息预警与反馈,提示相关客服人员对该笔交易进行关注并处理,随后客服人员通过数据审核系统提供的接口进行调整操作。
3 系统相关技术
3.1 高频数据存储
铁路客票电子支付业务数据审核机制的审核信息以多字段信息的形式进行存储,为了能够快速地对海量数据信息进行增加、删除、修改、查询,使用分布式内存数据库和Hadoop技术作为数据库基础架构,数据结构采用金字塔数据关系模型,保证了数据审核系统的业务效率。图3所示为电子数据存储的金字塔形数据关系模式,该模式自上而下的数据集关系为上层属于下层的子集,少量高频数据存放在分布式内存数据库中,全量数据存储在Hadoop数据集群中,关系型数据集是上面两层数据的提供者,该金字塔型数据关系模式可以缩减内存数据集中的不必要信息,降低资源消耗,提高查询效率。
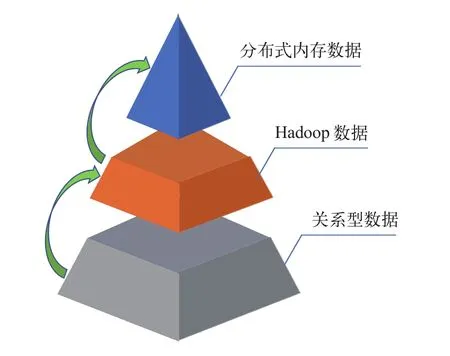
图3 电子支付数据金字塔存储模式
电子支付业务高频数据字段的存储运算模块通过分布式内存数据库技术实现,分布式内存集群由多个分散布局的Server节点构成,如图4所示,不同数据节点部署在不同的服务器上。Server节点由内联的多个存储区域构成,常用的数据比如车站数据、车次数据、停靠站数据,这些数据服从一致性Hash理论分别存储在不同的存储单元中,当需要对电子支付高频数据字段进行运算时,内存数据库集群可以同时调用多个节点进行计算,每个节点的运算对象只是从属于自身的数据存储区域,这在一定程度上可以避免数据被跨网络读取,所有Server节点运算汇总结果将被汇总到某一个节点上。
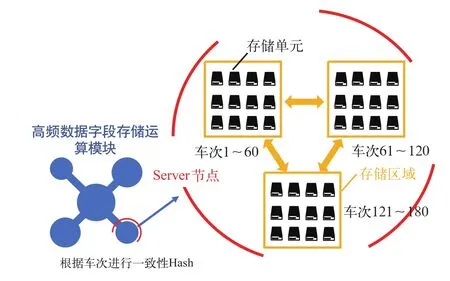
图4 高频数据字段存储方式
3.2 Hadoop数据存储
Hadoop数据集将电子支付业务数据切分成文件块,分散存储在Hadoop分布式文件系统(HDFSH)的不同DataNode节点上,使其服从列导向存储机制数据库的区域原则,同时,把电子支付业务数据的标志字段作为划分标准,利用HDFS将文件块分散地部署在不同的DataNode中。HDFS可以保证电子支付业务数据的存储准确性和一致性,因为NameNode存有数据的版本信息,当对DataNode中的电子支付业务数据进行读写操作时,会自动校验相同数据不同NameNode对应的版本是否一致,如果不一致则会触发恢复校正。为了能够在有限的资源内最大程度提升数据审核轮询性能,将列导向存储机制数据库的行键设置为关系型数据库的唯一索引。当数据审核系统轮询查找时,将通过电子数据的关键字段信息进行模糊匹配,再通过其他字段信息对行键进行完整拼接,从而获得查询目标。
3.3 负载均衡优化
铁路客票电子支付业务的服务器资源有限,必须使用符合铁路特色的负载均衡算法并合理搭配上述数据集群才能最大化展现服务器性能。目前,常用的简单负载均衡算法如表2所示,各均衡算法都有优缺点,需要根据服务器集群状况定制适宜的负载均衡策略。电子支付业务数据审核系统使用的服务器集群性能分为高、中、低3档,在处理同一请求过程中,不同性能挡位服务器的平均响应时间、当前带宽以及当前请求连接数均有差异[9-11],在此,提出了加权随机算法与基于平均响应时间、当前带宽、CPU利用率以及当前请求连接数4因素加权最小策略相结合的双层负载均衡动态反馈方案。

表2 常用负载均衡策略总结
4 系统性能测试
数据审核系统使用jmeter工具对其进行压力测试,其中,系统吞吐量(TPS)、CPU利用率以及响应时间(RT)是衡量系统性能的重要指标。旅客出行构成的电子支付业务量具备周期性规律,分别对10台服务器、30台服务器以及60台服务器进行系统性能测试。具体测试结果如图5所示。

图5 不同服务器数量集群CPU利用率、RT和TPS的变化趋势
从图5可以看出,在不同服务器数量的情况下,随着查询量TPS的增加,系统响应时间RT先呈现下降又出现向上增长趋势,从而得出服务器数量在30台左右时,系统平均响应时间良好,系统吞吐量也处于优良状态范围内,基本满足应用的要求。
5 结束语
为解决旅客在铁路客票电子支付业务流程中遭遇的重复支付、支付后未出票、银行退款失败等问题,运用分布式内存数据库技术以及Hadoop技术,搭建了电子支付数据审核系统。通过对不同部署服务器数目的数据审核系统进行压力测试,验证了该数据审核系统在CPU利用率处于正常状态下系统具备良好的吞吐量以及响应时间。在2019年春运期间,该系统试运行结果表明,电子支付数据审核系统具备提高铁路客票电子支付数据业务的能力,能够保障旅客拥有良好的出行购票体验。
