列车在站技术作业时间写实管理信息系统设计
2019-08-28杨廷宇倪少权陈钉均王柄达
杨廷宇,倪少权,陈钉均,王柄达
(1. 西南交通大学 交通运输与物流学院,成都 610031;2. 西南交通大学 全国铁路列车运行图编制研发培训中心,成都 610031;3. 综合交通运输智能化国家地方联合工程实验室,成都 610031;4. 中铁上海设计院集团有限公司,上海 200070)
当前,我国铁路制定的列车在站技术作业时间标准与实际作业时间存在不相符的情况,造成部分列车惯性晚点,降低了列车运行的正点率,影响铁路运输服务质量的进一步提高。现阶段,列车在站技术作业时间主要依靠专业写实人员到铁路现场查定,整个过程复杂、繁琐,且个体差异较大,已越来越不能满足铁路运营管理需求。随着既有铁路的提速和高速铁路的相继开通运营,对精确查定铁路行车技术作业时间的要求也越来越高,如何对技术作业写实数据进行自动化汇总、处理、计算,进而确定各种技术作业的时间标准,成为研究内容。
通过文献调研发现,国内学者在铁路行车技术作业时间的机理、流程及模拟仿真方面进行了广泛的研究,如王健[1]、罗常津[2]、张明[3], 何洁[4],张兰[5]等人从机制、方法、保障对策、算法等视角研究列车在站技术时间的方案,给出了概要设计;彭文高[6]、冉锋[7]、岳琦均[8]等人建立了虚拟仿真模型,验证铁路行车作业时间,提升了铁路行车的精度。这些研究都是针对某一个具体的技术作业时间,虽在理论层面形成了一系列的研究成果,却缺乏系统性,且对实际情况的技术条件考虑较少。国外学者的研究主要聚焦于实践,如Dewei Li[9]等人以荷兰火车站为例,基于到发线占用数据模型对列车中间站停站时间进行预估,模型对高峰期停站时间预测的准确率高达85.8%~88.5% ,对平峰期的预测准确率达到80.1%,证明了模型的高相关性。同时,也证明了可以不通过客流数据对列车停站时间进行预测。Wen-jun Chu[10]等人提出基于极限学习机(ELM,Extreme Learning Machine)模型对城市轨道交通列车停站时间进行了分析和预估,证实了其效果优于既有的其它两个模型。虽然国外学者的模型在精度层面有了显著提升,但是与我国铁路在站技术时间的统计分析存在较大的差异。近年来,也有学者提出利用微机联锁设备实现铁路技术作业时间获取与推算的半自动查定方法,但该方法缺少后端数据管理功能,无法投入高效使用,故仍有必要设计与开发出一套集数据获取、记录、汇编、分类与存储一体化的列车在站技术作业时间写实管理信息系统。
1 系统设计目标与需求分析
1.1 系统设计目标
列车在站技术作业时间写实管理信息系统涉及车、机、工、电、辆多个部门,需适应分工细、连续性强、各个部门作业相互制约等特点,其总体设计目标如下:
(1)实现列车在站技术作业时间实时采集、记录,同时,兼容传统的数据提交方式;
(2)提出列车在站技术作业时间数据汇总与分层管理办法;
(3)提出列车在站技术作业时间查定方法;
(4)实现基于用户权限的列车在站技术作业时间数据差异性共享。
1.2 系统需求分析
1.2.1 业务需求
列车在站技术作业时间写实管理信息系统的功能性需求可概括为“1主1辅3层次4应用”,系统功能层次如图1所示。“1主”为一条主线,即列车在站技术作业时间数据的采集、传输、处理、查询与反馈;“1辅”为系统辅助功能,即系统基础数据(如车站数据、行车数据)与系统基本信息(如用户信息、权限信息) 的管理与维护;“3层次”为操作员及其车间(科室)层、车站层、铁路局集团公司(简称:铁路局)层,铁路局层包含有多个车站,各车站又包括多个技术作业工种,每个工种对应一个科室(车间)及若干名技术作业人员;“4应用”为4类系统使用者—操作员(技术作业人员)、车间用户、车站管理员、铁路局管理员,他们分别对应系统的操作员及车间层、车站层和铁路局层。
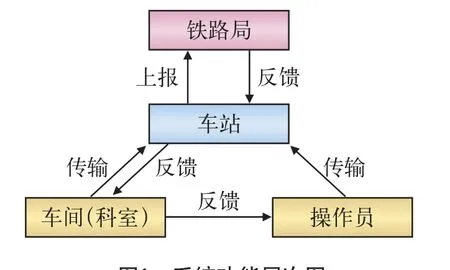
图1 系统功能层次图
1.2.2 数据库需求
(1)基础信息数据库:车站基本信息、行车信息和用户信息。车站基本信息包括:车站名、车站代码和车站时钟等;行车数据包括:车次号、停站代码、列车种类(性质)、计划到(发)点等;用户信息包括:用户工号、用户姓名、用户职务及用户单位等。
(2)技术作业时间数据库:各单项技术作业时间写实数据和列车在站技术作业全过程时间数据。以始发普速旅客列车为例,其在站技术作业由图2所示的列车始发技术检修作业、上水等平行的单项技术作业组成,每个单项技术作业的耗时即为单项技术作业时间,作业总时分即为列车在站技术作业全过程时间。
(3)业务报表数据库:用于储存各层用户的业务报表信息。
物理结构上看,各车站需要建立一个本地数据库(局部数据库),管理本站内部数据,同时,将处理好的数据向铁路局层提报。铁路局需要建立和管理一个汇总所有信息的全局数据库,还要满足所辖各站及车间工作人员间的环比查询需求,故需使用分布式数据库。该数据库还需充分考虑数据存储、维护和操作等功能性需求与访问权限、加密管理和日志管理等安全性需求。
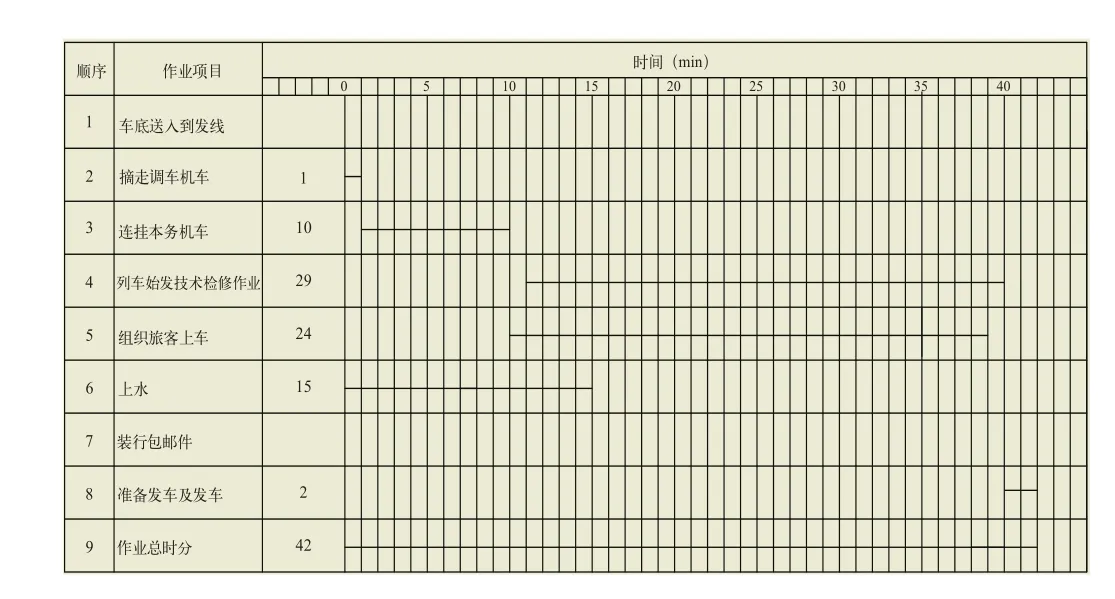
图2 始发普速旅客列车技术作业流程
2 系统架构
基于安全性要求高、人机交互频繁、用户群组固定等特点,列车在站技术作业时间写实管理信息系统采用C/S架构。
2.1 系统总体结构设计
系统总体呈如图3所示的“串-并行”结构。铁路局级、车站级与操作员级分别对应系统功能性需求的3个层次,而车间作为技术作业时间的最终查定与运用者,与前3个层级呈平行关系。
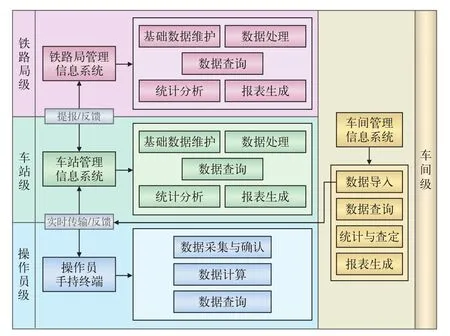
图3 系统总体结构图
2.1.1 铁路局级
(1)数据汇总与处理。接收所辖各车站发送的列车在站技术作业流程时间数据、单项技术作业时间写实数据,并对相关数据进行增加、删除和修改。
(2)数据查询。按车站、车次等形式查看各站单项技术作业时间写实数据和列车在站技术作业流程时间数据,结合车站信息、行车数据进行多表联合查询。
(3)数据统计与分析。统计分析同性质列车在铁路局内不同车站办理技术作业时间的差异,跟进重点车次在铁路局内各站办理技术作业的情况。
(4)向下辖各车站发送反馈信息。
2.1.2 车站级
(1)数据汇总。接收操作员或车间用户传输的各单项技术作业时间写实数据。
(2)数据处理。计算各列车在站技术作业时间,并对其进行增加、删除、修改。
(3)数据查询。查看铁路局内各站的各单项技术作业时间、列车在站技术作业流程时间数据,其中,本站数据可查看和修改,其它站数据仅供查看。
(4)数据统计与分析。统计本站各性质列车在站技术作业流程时间的平均值、中位值、极值、方差(标准差)等指标,并生成报表。
(5)数据提报。车站每隔固定时间(周/月)就要向铁路局层提报各单项技术作业时间写实数据和各列车在站技术作业流程时间数据。
(6)接收来自铁路局层的反馈信息,并向车间层发送反馈信息。
2.1.3 操作员级
(1)数据采集与确认。技术作业人员通过手持终端采集技术作业时间原始数据,并通过逻辑判断语句对时间数据进行初步检验,剔除不合理数据。
(2)数据处理。技术作业人员在一次采集完毕后,前端能自动计算本次技术作业的时间,并通过如自动弹出对话框的形式使技术作业人员即时地获取本次技术作业的时分。
(3)数据查询。操作员在自身权限范围内查看相关信息。
(4)数据实时传输。采集完毕后,技术作业时间写实数据能实时传输至所属的车站数据库,用以存储、处理和分析。
(5)接收车间用户的信息反馈。
2.1.4 车间级
(1)导入写实数据。手持终端设备故障条件下,允许通过接口手动导入用Excel等方式记录的技术作业时间写实数据。
(2)数据查询。在自身权限范围内查看本工种的技术作业时间历史数据,既包括本车间又包括其它站同一性质车间。
(3)数据统计和分析。车间用户可按作业员、车次、时段统计技术作业时间平均值、中位值、极值、方差(标准差)等指标,统计的结果能够灵活生成曲线、柱状图等形式的分析报表。
(4)接收来自车站层的反馈信息,并向操作员发送反馈信息。发送的反馈信息可分为个性化反馈信息和固定反馈信息。个性化反馈信息是车间用户针对指定技术作业员发送的消息,主要内容是对员工近一段时间工作的评价或提醒,提供意见咨询、发挥监督作用;固定反馈信息,即按固定时间面向全体员工发布的工作信息,如周报、月报,供每个技术作业员学习,提高工作素养。
2.2 系统分层结构设计
采用3层架构:(1)数据访问层,是系统构建的基础;(2)业务逻辑层,介绍系统构建的功能和关系结构;(3)表示层,即系统用户层。系统的分层结构如图4所示。
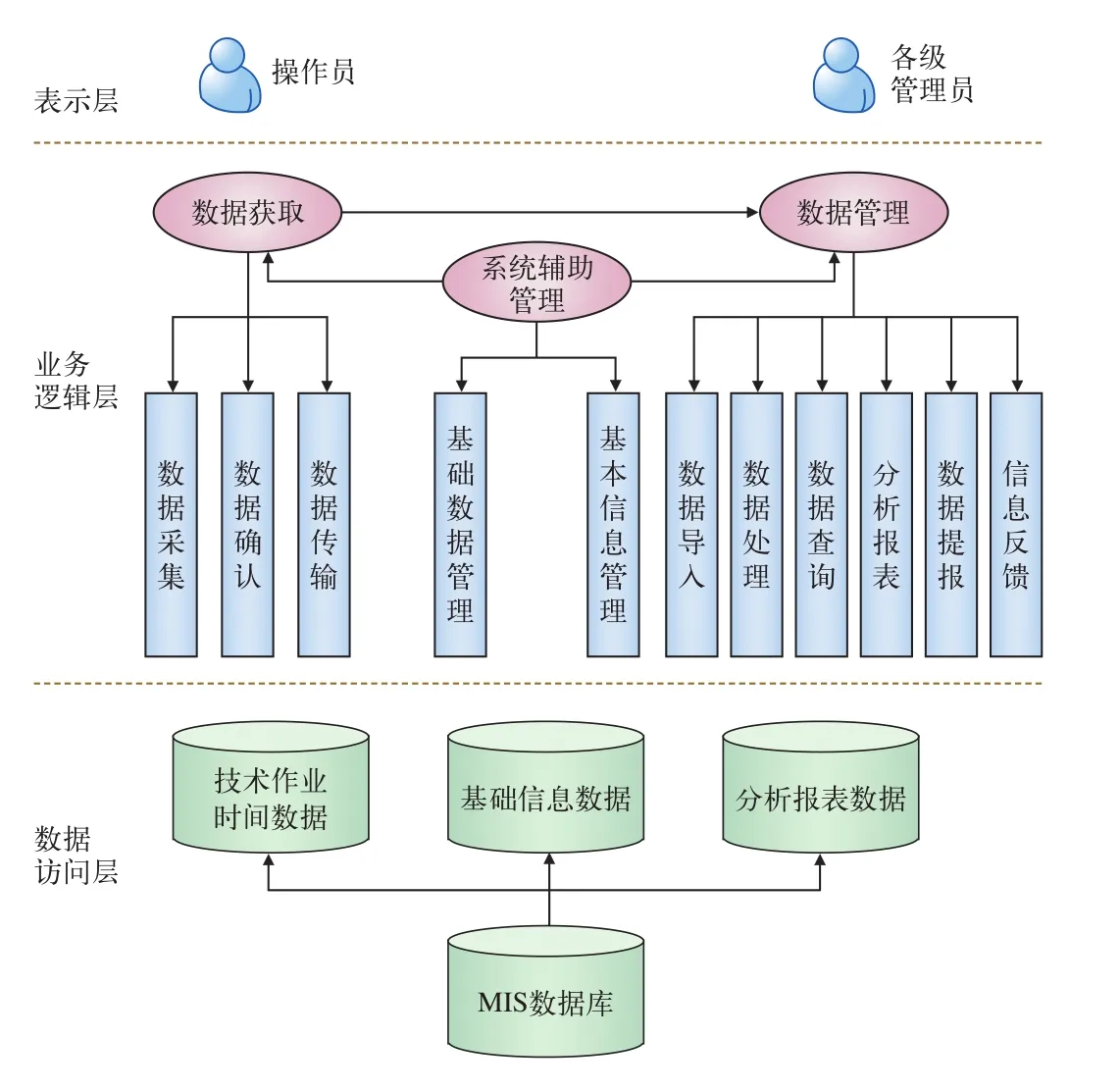
图4 系统分层结构图
(1)操作员与各级管理员两类用户是表示层人机交互的主要对象,不同身份用户可操作界面亦不相同。
(2)业务逻辑层主要实现基于系统辅助管理的数据获取和数据管理。
(3)数据访问层主要包含技术作业时间数据、基础信息数据、分析报表数据等。
3 系统功能
3.1 数据获取
依靠作业人员通过手持终端实时采集列车在站技术作业过程中各单项技术作业的开始时刻、结束时刻,同时,允许相应的车间级管理员手动导入。
3.2 数据汇总与处理
系统获取的原始数据为各单项技术作业的开始时刻、结束时刻,将原始数据通过识别与关联数据库、作差运算等技术手段,计算出时间间隔数据,即单项技术作业时间和列车在站技术作业全过程时间。采用分类汇总法,对关键词词段值相同的记录进行汇总。系统层级不同,汇总对象也不同,其具体对应关系如表1所示,此外,还包括数据基本表的定义、修改、删除和更新表中数据等功能。

表1 数据汇总层级及其对象
3.3 数据查询
数据查询分为本地查询和环比查询。本地查询的对象是用户所在单位的本地数据库,查询结果可供修改;环比查询(即联机查询)的对象是系统其它同层级、不同单位的数据,需要访问全局数据库,查询结果仅支持铁路局级管理员修改,其具体对应关系如表2所示。数据查询可按车站、员工、技术作业类型等多种条件进行,基于用户权限的多表联合查询技术是实现该功能的基础,用户查询权限如表3所示。
3.4 数据统计分析与业务报表生成
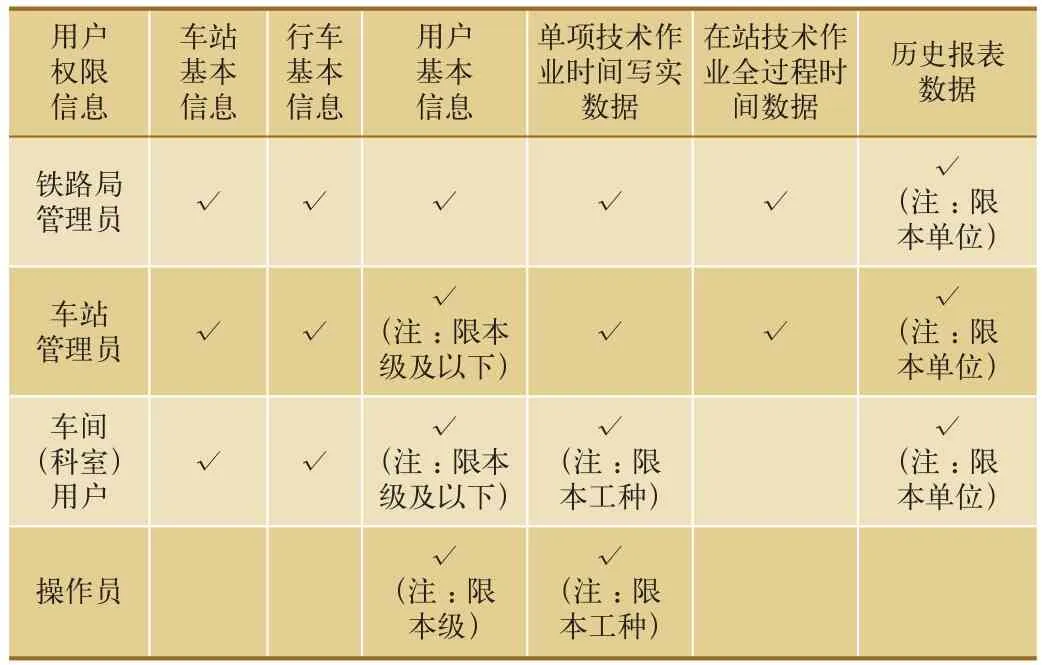
表2 不同级别用户对应的查询范围表

表3 不同层级的本地查询与环比查询对象
系统数据统计与分析工作基于数据查询功能展开,并生成业务报表。不同层级单位业务报表对应的核心任务与具体内容如表4所示。
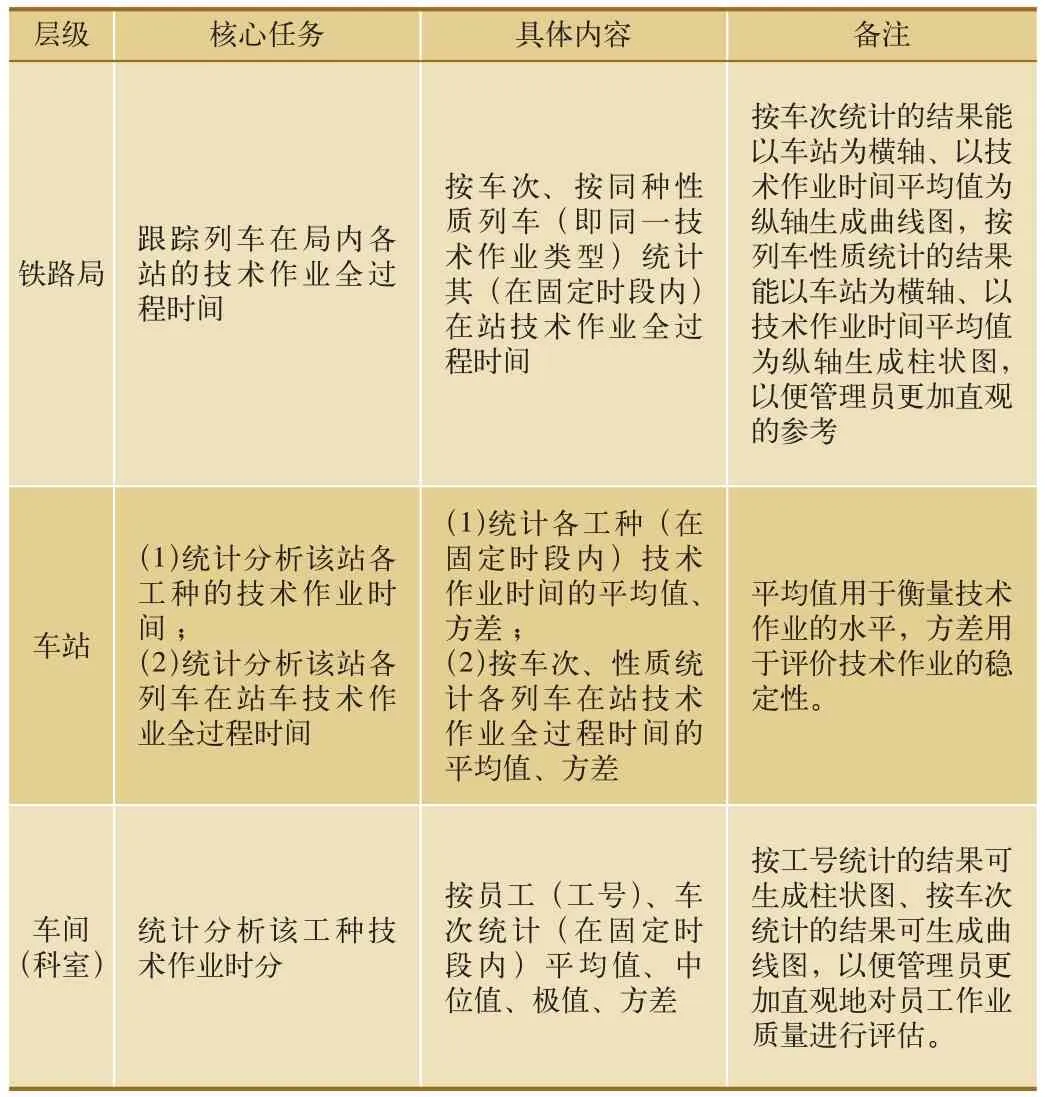
表4 不同层级单位业务报表的具体内容
3.5 系统辅助管理
(1)对所有基础数据进行核实、添加、删除、修改,如车站基本数据、行车基本数据、用户基本数据;(2)对系统基本功能进行管理,如用户操作、权限管理等。
4 关键技术
4.1 数据库设计
系统采用如图5所示的分布式数据库,将分散存储在多个网络节点上的数据有机统一起来,以获取更大的存储容量和更高的并发访问量。
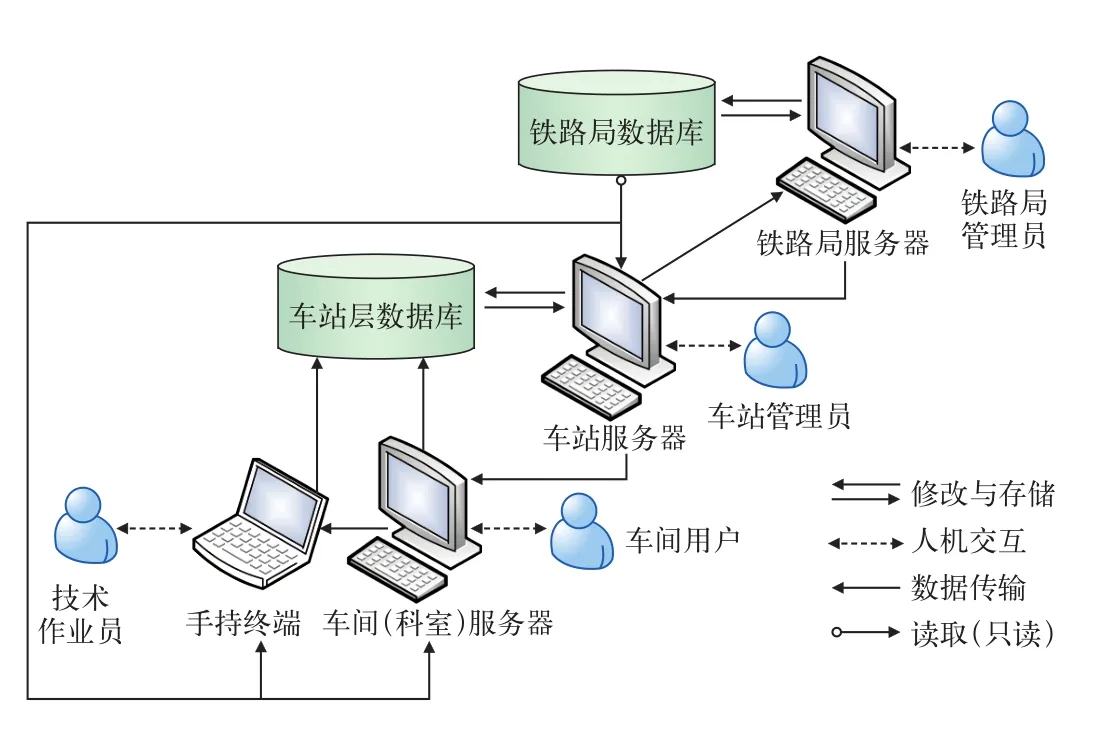
图5 系统数据库结构设计
基于设计,物理上分散的各车站需建立和管理一个局部数据库,铁路局将所有数据汇总管理后建立一个全局数据库。全局数据库可以供所有用户在自身权限内访问(只读),而局部数据库的数据既可以供本地用户查询,又可以供本地用户修改。
此外,系统需要设计合理的数据表结构,满足不同层级单位对技术作业时间存储与汇总的需要。以某站某列车在站技术作业为例,用结构体类型定义的数据结构描述如下:

ZYSJ;//作业时间}单项技术作业时间写实数据TYPEDEF STRUCT列车在站技术作业全过程时间

ZYSJ;//作业时间}列车在站技术作业全过程时间数据。
当进行车站层汇总时,系统以技术作业代码作为第1关键词,以工号作为第2关键词,以(车次号,时刻)作为第3关键词;当进行铁路局层汇总时,系统以车站代码作为第1关键词,以技术作业代码作为第2关键词,以(车次号,时刻)作为第3关键词,以工号作为第4关键词进行数据汇总。
4.2 分布式数据查询优化
系统为适应铁路点多、线长等特点,采用分布式数据库,实现数据查询“物理分散,逻辑集中”。受地域因素影响,查询速度是影响系统性能的关键,本系统采用的是基于代价的优化策略。以某车站用户要查询两个远程数据库(即其它车站)中的表remote a,remote b,以及一个当地数据库(即本站)的表local c中数据的操作为例,优化后的查询语句可以写为:
SELECT r.CC,r.XC_no,r.LCLX,r.Station_no,c.Begintime,c.Endtime
FROM (SELECT a.LCLX,a.Station_no,b.Begintime,b.Endtime
FROM remote a,remote b
WHERE a.XC_no=b.XC_no) r,local c
WHERE c.XC_no=r.XC_no
这种在多个远程站点通过构造行中视图的方法减少了查询数量与网络传输代价,进而提高了查询速度。
5 结束语
本文分析列车在站技术作业流程,以及技术作业时间写实管理信息系统的需求,设计系统总体结构和功能。后续的工作可考虑从以下方面展开:
(1)丰富系统功能,扩展系统应用范围,实现对移动设备场库内检修作业时间、列车行车间隔时间等其它类型的铁路技术作业时间的一体化管理;
(2)运用大数据技术与方法,进一步完善数据分析与管理功能等。
