基于密集神经网络的灰度图像着色算法
2019-08-27张娜秦品乐曾建潮李启
张娜 秦品乐 曾建潮 李启


摘 要:针对在灰度图像着色领域中,传统算法信息提取率不高、着色效果不理想的问题,提出了基于密集神经网络的灰度图像着色算法,以实现改善着色效果,让人眼更好地观察图片信息的目的。利用密集神经网络的信息提取高效性,构建并训练了一个端到端的深度学习模型,对图像中的各类信息及特征进行提取。训练网络时与原图像进行对比,以逐渐减小网络输出结果的信息、分类等各类型的损失。训练完成后,只需向网络输入一张灰度图片,即可生成一张颜色饱满、鲜明逼真的彩色图片。实验结果表明,引入密集网络后,可有效改善着色过程中的漏色、细节信息损失、对比度低等问题,所提算法着色效果较基于VGG网络及U-Net、双流网络结构、残差网络(ResNet)等性能优异的先进着色算法而言取得了显著的改进。
关键词:图像着色;密集神经网络;灰度图像;特征利用;信息损失
中图分类号:TP391.4
文献标志码:A
Abstract: Aiming at the problem of low information extraction rate of traditional methods and the unideal coloring effect in the grayscale image colorization field, a grayscale image colorization algorithm based on dense neural network was proposed to improve the colorization effect and make the information of image be better observed by human eyes. With making full use of the high information extraction efficiency of dense neural network, an end-to-end deep learning model was built and trained to extract multiple types of information and features in the image. During the training, the loss of the network output result (such as information loss and classification loss) was gradually reduced by comparing with the original image. After the training, with only a grayscale image input into the trained network, a full and vibrant vivid color image was able to be obtained. The experimental results show that the introduction of dense network can effectively alleviate the problems such as color leakage, loss of detail information and low contrast, during the colorization process. The coloring effect has achieved significant improvement compared with the current advanced coloring methods based on Visual Geometry Group (VGG)-net, U-Net, dual stream network structure, Residual Network (ResNet), etc.
Key words:
image coloring; dense neural network; grayscale image; feature utilization; information loss
0 引言
色彩信息是图像所包含的一种重要信息,能够结合图中场景的语义及物体表面纹理信息,共同展現丰富的层次感。研究表明,人眼对彩色强度及其变换具有很高的敏感度,彩色图像较灰度图像而言,更便于人眼观察信息;且从人的心理层面而言,彩色图像能给与观察者以更加愉悦、明快的感受,从而有助于理解图像的内容,从中获取更加全面、丰富的信息,提高图像使用价值。因此,将灰度图像通过一定算法转换为彩色图像,获得更好的观察效果是非常有意义的。灰度图像着色(即伪彩色处理)技术,即是在上述需求下产生的,通过一种指定的规则,对灰度值赋以颜色[1],实现还原、增强或改变图像的色彩信息。
目前,主要存在着三类图像着色的方法。
1)基于用户引导下的颜色传播类算法。在灰度图像着色领域出现较早,由用户进行关键部位或区域的指导性着色,并按照设定的算法或转换规范进行颜色扩展。其中,Levin等[2]提出了全局优化着色算法,支持图像先验定义,用户在着色后,生成与着色笔迹匹配的彩色图像;Lagodzinski等[3-4]提出了一种新颖的着色方法,利用形态距离变换和图像结构自动传播用户在灰度图像内所写的颜色。上述方法可取得不错的效果,但由于不同的颜色区域需要明确指示,通常需要密集的用户交互,且对与色度深浅等属性无法较好地进行表征与实现,也容易出现由于标注不当、灰度值过于相近等原因产生的颜色渗漏问题。
2)基于指定函数或参数的颜色映射算法。通过设定的着色函数,将灰度值与彩色值之间建立某种映射关系,实现由灰色向彩色的变换。Shah等[5]在基于优化的着色方法基础上,使用三个相关系数来评估其在信息损失方面的性能;Li等[6]也使用了基于阈值应用着色技术,该类方法对阈值选取依赖性较高,且得到的着色效果颜色数目有限,效果较为生硬。
3)基于数据驱动的图像着色方法。此类方法在早期主要有基于实例图像参考法及类比法。Welsh等[7]提出可将灰度图像的亮度及纹理信息与实例参考图像进行对比,实现灰度图像的着色;Liu等[8]提出可直接从互联网中搜索与目标灰度图相关的彩色参考实例图像进行着色;Liu等[9]及Morimoto等[10]通过颜色转换和图像分析,实现对目标灰度图像着色。此类方法在目标灰度图与参考图像中内容相似的较高时,效果非常不错,但查找参考图像及匹配过程非常耗时,当着色目标或场景非常复杂或罕见时,着色效果就更难以得到保证。Irony等[11]则利用纹理特征匹配,首先对参考图像和灰度图像进行图像分割处理,参照参考图像,对灰度图像中具有相似纹理的部分赋以相同的色彩,虽然也可取得不错效果,但分割处理操作也增加了图像处理负担。
深度学习方法的发展及高性能图形处理器(Graphics Processing Unit, GPU)的出现,为基于数据驱动的图像着色方法开辟了新的方向。该类方法利用神经网络,搭建不同的网络架构,通过卷积操作对图像的内容和特征进行提取及分析,寻找灰度图像到彩色图像之间的映射关系,从而训练出相应的模型,实现着色。Cheng等[12]通过为大规模数据建模,采用基于联合双边滤波的后处理方式,利用自适应图像聚类技术来整合图像全局信息;Deshpande等[13]通过训练色度图中的二次目标函数,通过最小化目标函数实现图像着色。此类网络结构较为简单,其着色效果比较有限。Zhang等[14]提出通过VGG(Visual Geometry Group)卷积神经网络[15]来提取图像特征,预测每个像素的颜色直方图来为图像着色,后又提出了新的思路,利用U-Net网络[16]进行信息提取,并结合用户交互进行着色[17];Lizuka等[18]构建了双流结构网络,同时提取图像的全局分类信息及局部特征信息,将两类信息进行融合,实现对像素颜色的预测。此三类方法较之前的方法已取得了较大改善,但由于其网络均在图像处理过程中均进行了下采样及上采样操作,存在一定程度的信息丢失。Qin等[19]采用残差网络[20]进行细节特征的提取,结合分类信息指导,在一定程度上改善了信息损失,但仍存在细节着色不完善、漏色等问题。
通过对现有灰度图像着色算法进行广泛研究分析,可以看出,现有的灰度图像着色已经可以实现给定一幅灰度图像,通过一定算法得出一幅彩色图像,但基本都存在如下共性问题:
1)细节信息还原度不高。由于对应映射关系效率有限,特征提取的过程中存在着一定程度的信息损失,导致图像中的部分内容(尤其是较小的物体)不能被赋予适当的颜色。
2)物体边界清晰度不高。在一定程度上存在着“漏色”的问题,在物体边界处,容易存在颜色渗漏。
3)用户交互的依赖性较强。需要借由用户做出大量辅助操作,往往容易引入较多的随机性误差,且不利于将用户从繁杂的参数调整工作中解放出来。
综合考虑上述因素,为了充分利用图像细节信息、轮廓信息等低阶语义信息,本文采用自适应性强、用户依赖低的密集神经网络,搭建着色网络,并且构造了着色网络损失函数以及评价指标。经实验验证和理论分析,本文算法与传统方法相比,可以明显改善细节信息损失、边界不清晰的问题,同时不需要用户干预,得到的着色模型细节更加完善、丰富。
1 相关理论
1.1 卷积神经网络
卷积神经网络在图像识别、语音分析、自然语言处理等领域已经成为研究热点,该网络具有特征共享性,可有效降低网络的复杂性,在解决特征提取及特征映射问题时可发挥非常有效的作用。特别是在图像分析与处理应用中,可直接将图像输入网络,避免了特征提取和分类过程中数据重建的复杂度。目前已经有AlexNet(Alex Network)[21]、VGG、GoogleNet[22]、残差网络(Residual Network, ResNet)等不同结构的基于卷积神经网络的优秀网络,在图像分类任务中已经将Top5错误率降到5%以下。
1.2 跨层级连接思想
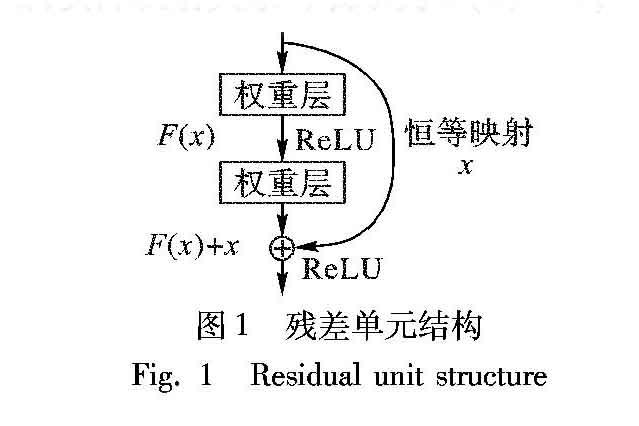
在深度学习网络中,随着网络深度的加深,梯度消失问题会愈加明显,因此产生了较大的信息损失。目前,很多研究学者都针对此问题提出了解决方案,如ResNet、Highway Networks[23]、Stochastic depth[24]、FractalNets[25]等,此類算法的网络结构各有差别,但其核心都在于——创建早期层级到后期层级之间的短连接路径,在较小的代价下,利用较早层级提取到的信息,提高整体信息利用率。其中,ResNet由于其较好的性能和结构的简单性,为较多研究者所采用。该网络通过在残差块的输出和输入之间引入一个短连接,而不是简单地堆叠网络,实际映射关系可表示为F(x)+x,如图 1所示。
1.3 密集神经网络
与传统的网络结构不同,密集神经网络DenseNet(Densely connected convolutional Network)[26]不是通过极其深或者宽的网络来获得更好的性能,而是通过特征重用来提升网络的性能及潜力,产生易于训练和参数效率高的压缩模型。残差神经网络(ResNet)虽然也利用了跳层连接的思想,但其仅利用了上一层输入作为信息补充,并未充分利用早期层级特征。而密集网络通过连接不同层级的特征图,将传统模型中未曾利用或充分利用的前期层级的特征均引入新的层级中,充分利用了低层级卷积层对位置信息、形状信息的敏感性,增加后续层输入的变化,将更加有效地提高效率,这也是DenseNet和ResNet之间的主要区别。DenseNet相较于ResNet及早期其他类型网络,具备更高的信息利用率。密集网络主体结构如图2所示。
2 本文算法
本文算法引入密集神经网络,利用其信息提取率和特征利用率高的特性,结合分类指导及损失优化,使输出彩色图像的细节特征更为丰富、轮廓更为清晰,进而达到更好的着色效果。
2.1 设计网络结构
2.1.1 总体网络结构
现有的基于深度学习的灰度图像着色网络主要是通过构建卷积神经网络,对图像的细节纹理特征进行提取,着色效果尚可,但因没有适当的方式来学习正确的图像全局上下文信息(如场景是属于室内还是室外等),着色网络可能出现明显的错误。Lizuka等[18]将图片的类别信息也融入网络,用图片的类别信息来协同训练模型,对整个着色网络起到了分类指导作用。Qin等[19]在此原理基础上进行网络设计,也获得了不错的效果,也证实了双流结构的有效性。
本文汲取Lizuka等[18]、Qin等[19]算法的优点,总体采用双流架构,主要由分类子网络和特征提取子网络构成,通过整合特征信息和分类信息,实现由灰度图像到彩色图像的转换。分类子网络采用VGG网络获取图像的分类信息;在设计特征提取子网络时,为了解决传统深度学习算法容易出现的梯度消失及底层特征利用率不足的问题,采用了密集神经网络。网络将纹理细节信息及分类信息融合后进行特征再提取,根据得到的综合特征进行色彩预计,并与彩色图像进行对比,计算色彩、信息量等损失,经过多次优化训练后得到最终着色模型。网络结构如图 3所示。
2.1.2 特征提取部分
输入图像的L通道(此部分即为灰度图,大小为H ×W×1)进入特征提取部分,经过一层卷积后,将依次进入4个密集块。每一个密集块中的不同卷积层与其后续的卷积层进行密集连接(块内每层均为k个feature map,本文设置k=12)。鉴于密集网络的稠密性,每一个3×3卷积前设置了一个1×1卷积(结构如表1中的Dense-block部分),此操作可减少输入的feature map数量,可实现降维效果,减少计算量,同时还可融合各个通道的特征。
在每两个Dense-block之间,增加了1×1的卷积操作(即图3中的Transition层),该操作可减少上一个Dense-block输出的feature map数量(本文网络设置为减少到一半),这将有效避免网络过于庞大,减少进入下一个Dense-block后的计算负担。
图像在经过具有上述特征的网络后,大量细节特征及纹理信息将被提取出,由于密集块中的卷积层都与前面的每一层保持连接,低级的信息也将被有效利用,有效减少了信息损失,并改善了梯度弥散的问题。
2.1.3 分类指导部分
图像进入分类指导网络后,网络将逐步通过卷积操作提取图像的分类信息,全连接层fc1将提取到的特征重构为1×4096的特征向量,再经由fc2、fc3整合后得到维度为1×64的特征向量,作为辅助信息进入fusion层,帮助判别图像内容的类别。fc4和fc5层和输入图像的标签进行对比,经过损失优化,训练分类网络
2.1.4 融合及输出部分
特征提取网络及分类指导网络均完成信息提取后,可将二者进行融合,进一步充分利用分类特征及细节纹理特征。由于特征提取部分和分类提取部分所得的特征图维度不同(前者即Dense-block4,为由密集块组成的特征提取网络产生的特征图,尺寸仍为输入网络时的H×W(H=W=256),通道数为383;而后者即fc3,为VGG分类子网络经卷积操作、全连接操作及重构整合后形成的一维特征向量,尺寸为1×64),在融合时需要进行统一维度,将两部分信息将重构为具有相同维度的feature map,即将fc3层扩展重构为与Dense-block4特征图相同的大小H×W,通道数为64。二者尺寸统一后完成通道连接融合,形成尺寸为H×W,通道数为447的特征图Fusion_out,经卷积操作后成为fusion层(维度为H×W×128),随后进入Dense-block5进行特征再提取,最后经卷积操作后成为得到H×W×2的输出output,此部分即为网络所给出的色彩部分预测值(ab通道),与黑白通道(L通道)进行融合,转化为RGB颜色空间,就形成了一副彩色图像。
2.2 构造损失函数
网络的损失将作为调整权重的重要参考内容。为更好地调节网络的特征提取能力及分类性能,本文综合了特征提取子网络的特征提取损失(L1)及分类指导子网络的分类损失(L2),共同构成总网络的损失(Loss)。两部分损失均独立反馈给网络,彼此不交互影响。
2.2.1 特征提取损失L1
2.2.2 分类损失L2
分类指导部分,输入图像的分类信息作为指导标签ylabel,指导网络的预测结果为yout,采用交叉熵(Cross-Entropy)来衡量网络预测的分类与真实分类的损失,即如式(7)所示:
L2=1n∑ni=1[-∑iylabeli log (youti)](7)
在对youti求log函数值时,如果youti的值为0,会出现log(youti)值为无穷,本文在计算时,令小于1E-10的数都等于1E-10。
3 实验结果与分析
3.1 实验数据集及环境
作为有监督的着色网络,本文提出的网络需要大量有分类标签的彩色图像作为训练数据集,故采用MIT Places Database[27](含205個场景分类、250多万张图片)、ImageNet[28](含1000个场景分类、120多万张图片)两种数据集对网络进行训练。采用HDF5对数据集进行处理,生成一个“.h5”类型的data文件,不再需要依次读取大量单幅图片,方便运行与维护。
本文提出的着色网络需要进行大量的矩阵计算,故为提高训练效率,采用GPU进行训练,GPU型号为NVIDIA Tesla M40。在方法实现时,采用Python编程环境,基于TensorFlow[29]架构进行网络搭建。
3.2 评价指标
对灰度图像进行着色的目的,主要是希望从着色结果中获得较灰度图像而言更丰富的信息, 那么,着色结果是否清晰,包含的信息量是否充分,即可视为衡量着色算法优劣的重要指标。
传统的图像客观评价指标采用的是峰值信噪比(Peak Signal-to-Noise Ratio, PSNR),分值越高即认为若质量越好,如式(8)所示,其中MSE计算方式如式(4)所示。
PSNR=10×lg(2n-1)MSE(8)
此标准主要针对的是新图与原图像素之间的像素差异性,分数无法和人眼看到的视觉品质完全一致,有可能PSNR较高者看起来反而比PSNR较低者差,不能较好地描述信息量丰富程度。为此本文引入了评价图像所含信息充分程度的广为采用的量化指标——图像熵(Image Entropy)。熵指的是某一特定体系的混乱的程度,对图像而言,图像熵越大,图像包含的信息更丰富。通过计算整张图片彩色通道的信息熵,判断图像包含的信息量。利用图像熵,可从客观角度评价着色结果与人眼主观感受是否一致。其计算方式如式(9)所示:
InEn=-∑ci=0P(i)lb P(i) (9)
其中:InEn表示图像熵值;P(i)表示值为i的颜色在整幅图像中出现的概率。
本文构造了基于信息熵的评价标准,通过计算着色图像的信息熵,结合主观观察结果,从而判断信息丰富程度, 同时,主观观察结果也将验证指标的有效性。
由于本文提出的网络主要是基于Lab空间对图像ab通道的色值进行预估,不对图像的L通道(反映图像的灰度信息)进行重复的计算及处理,故为提高效率,本文在评价着色效果时,仅考虑彩色通道所包含的信息。
3.3 实验结果
3.3.1 有原图参考下的着色效果对比
为了验证本文所提算法的有效性及优异性,现选取了部分代表性的图片,与现有表现优异的算法(如Zhang等[14]提出的基于VGG的着色算法,Lizuka等[18]提出的双流结构算法,Qin等[19]提出的基于残差网络算法)进行比较,从是否漏色、色彩对比度、细节信息损失程度等方面对上述算法着色效果进行比较,具体如图5所示。着色效果对比中,Zhang等[14]算法、Lizuka等[18]算法的着色效果均来自其对外公示网站的着色结果,Qin等[19]算法的着色效果采用其最终版着色模型。
是否漏色 对图像中的物体着色时,需要准确地识别物体的边界,否则将会发生颜色漏色,如图5中组(e)箭头指出部分,Zhang等[14]算法、Lizuka等[18]算法将天空的色彩渗漏到地面上,使得着色效果不太理想,本文算法在此方面表现较好。
色彩对比度 在对灰度图像着色时要注意彩色图像中物体的颜色是各不相同的,图5中组(a)~(d)中Zhang等[14]算法、Lizuka等[18]算法的着色结果倾向于整体赋予暖黄色色调,各个物体之间的颜色没有较好地区分开来,特别是天花板的颜色也混入主色调。 Qin等[19]算法着色效果物体区分度有了一定改善,但不如本文算法着色结果色彩对比度更鲜明,本文算法所得图像的色彩对比度就饱和度更高,各个物体的颜色彼此独立,不受整体色调蔓延影响,如本文算法组(a)及组(c)中的地板更接近于真实的木地板色泽纹理;组(b)中的床上用品颜色更为鮮艳。
细节信息损失程度 在整体着色能达到一定效果时,细节信息可否良好还原即成为了重要衡量指标。为对比细节效果,将图5中组(b)和组(d)的细节进行放大对比,详见图6。图6(a)中(即图5组(b)中虚线框圈出的床头挂画中的绿色植物),本文算法准确地赋予了应有的绿色,但其他三种并没有合理地着色,与主色调融为一体;图6(b)中本文算法相对于其他算法而言,较好地为盆栽植物及挂画中的景物赋予了绿色。从对比效果可看出,本文算法在实现整体着色时,不会忽略细节部分,具备更好的细节处理能力,能较好地对细节部位予以着色。
此外,为客观评价各个算法的性能优劣,本文采用了3.2节中所述的图像熵InEn作为评价指标,计算方式如式(9)所示,同时列出了采用式(8)中PSNR值,即峰值信噪比计算的结果,对比结果详见表4。表4中图像熵指标采用加粗的方式表示性能最好的算法,由图像熵的定义可知,熵值更大的,表示信息量更丰富;峰值信噪比指标也采用加粗的方式表示性能最好的算法,按照定义,峰值信噪比越高,图像质量越好。
从图5性能对比可以看出,采用本文所用评价指标图像熵InEn,其评价结果与人眼所观察的效果基本一致,这在客观上说明了本文算法的优异性,同时也印证了本文采用评价指标的有效性,而采用PSNR方式进行客观评价,按此指标最高的为图像质量最好的,但实际效果并非如此。
3.3.2 老照片及黑白图像着色效果对比
为了验证本文算法的普适性,现选取了部分老照片及黑白图像进行着色效果比较,对比如图7所示。
Zhang等[14]算法、Lizuka等[18]算法存在些许着色不均匀、漏色的问题,如图7(a)的门柱和地面;图7(b)、(c)中天空在湖水中的倒影应为蓝色色调,Zhang等[14]算法着色为绿色;图7(c)中山体在水中的倒影,只有本文算法没有被旁边绿色植物的倒影影响变为绿色;图7(d)中,Zhang等[14]算法、Lizuka等[18]算法、Qin等[19]算法的文字牌匾及屋顶均存在一定程度的漏色、色调暗沉等问题,本文算法则表现良好。
从上述老照片及黑白照片着色效果来看,本文提出的算法较Zhang等[14]算法、Lizuka等[18]算法、Qin等[19]算法而言,较少出现漏色现象,细节更为丰富,对比度也更好。
3.3.3 信息损失对比
从图5和图7的着色效果对比中可以得知,Qin等[19]提出的基于残差神经网络的着色算法较之前的表现优秀的深度学习着色算法而言,在一定程度上减少了信息损失,着色效果也有所改善。将本文算法与其进行对比,通过随机选取5000张图片,按照本文3.2节中的评价指标,比较两种着色方法的信息熵,即InEn值,Qin等[19]算法的算法均值为8.60,而本文算法均值为10.34,图8为数据对比。上述的实验结果可以客观地反映出,本文着色算法较Qin等[19]的算法取得了明显改善,信息量更丰富,着色效果更好。
4 結语
本文提出了一种基于密集神经网络的灰度图像着色算法,该算法通过密集模块构成的子网络和VGG分类子网络分别对图像的细节特征纹理及分类信息进行提取,二者融合后实现对彩色结果的预测与输出。通过实验证明,本文算法较现有的优秀灰度图像着色算法而言,信息量可提高1%~20%,色泽和对比度等方面也取得了较大的改善,漏色程度也明显减小,运用于老照片及黑白照片等方面也可取得不错的效果。
本文将密集神经网络引入图像着色任务中,尚未针对性地研究引入后续层级的低级层级特征中,哪些层级对后期层级及网络输出有较大的影响,是否有必要全部加入后期层级,无差别地将前期层级提取的特征融入到后期层级中,可能存在一定的“冗余连接”,造成了该网络的稠密性,从而对于运行设备性能要求较高,网络训练时间也较长。同时,由于采用的数据集并未涵盖所有图像类别,本文所提的算法对于未学习过的图像着色效果还不太理想。
在下一阶段的研究中,首先可考虑通过优化密集网络部分及整体网络架构,尝试通过引入自适应学习特征权重类的方式,或自适应剪枝算法,判别早期特征的重要程度,降低网络稠密性,提高整体效率;同时,可尽量多地尝试更多种图像类别,进一步强化算法的普适性与实用性。
参考文献 (References)
[1] 冈萨雷斯,伍兹.数字图像处理[M].3版.阮秋琦,译.北京:电子工业出版社,2007:484-486.(GONZALEZ R C, WOODS R E. Digital Image Processing [M]. 3rd ed. RUAN Q Q, translated. Beijing: Publishing House of Electronics Industry, 2007: 484-486.)
[2] LEVIN A, LISCHINSKI D, WEISS Y. Colorization using optimization [J]. ACM Transactions on Graphics, 2004, 23(3): 689-694.
[3] LAGODZINSKI P, SMOLKA B. Medical image colorization [J]. Journal of Medical Informatics & Technologies, 2007(11): 47-57.
[4] LAGODZINSKI P, SMOLKA B. Colorization of medical images [J]. China Healthcare Innovation, 2009, 15(4): 13-23.
[5] SHAH A A, MIKITA G, SHAH K M. Medical image colorization using optimization technique [J]. Acta Medica Okayama, 2013, 62(141): 235-248.
[6] LI F, ZHU L, ZHANG L, et al. Pseudo-colorization of medical images based on two-stage transfer model [J]. Chinese Journal of Stereology and Image Analysis, 2013, 18(2): 135-144.
[7] WELSH T, ASHIKHMIN M, MUELLER K. Transferring color to greyscale images [J]. ACM Transactions on Graphics, 2002, 21(3): 277-280.
[8] LIU X, WAN L, QU Y, et al. Intrinsic colorization [J]. ACM Transactions on Graphics, 2008, 27(5): Article No. 152.
[9] LIU Y, COHEN M, UYTTENDAELE M, et al. AutoStyle: automatic style transfer from image collections to users images [J]. Computer Graphics Forum, 2014, 33(4): 21-31.
[10] MORIMOTO Y, TAGUCHI Y, NAEMURA T. Automatic colorization of grayscale images using multiple images on the Web [C]// Proceedings of ACM SIGGRAPH 2009. New York: ACM, 2009: Article No. 59.
[11] IRONY R, COHEN-OR D, LISCHINSKI D. Colorization by example [C]// Proceedings of the 16th Eurographics Conference on Rendering Techniques. Aire-la-Ville, Switzerland: Eurographics Association, 2005: 201-210.
[12] CHENG Z, YANG Q, SHENG B. Deep colorization [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 415-423.
[13] DESHPANDE A, ROCK J, FORSYTH D. Learning large-scale automatic image colorization [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 567-575.
[14] ZHANG R, ISOLA P, EFROS A A. Colorful image colorization [C]// ECCV2016: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam: Springer International Publishing, 2016: 649-666.
[15] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J/OL]. arXiv Preprint, 2014, 2014: arXiv.1409.1556 (2014-09-04) [2018-08-10]. http://arxiv.org/abs/1409.1556.
[16] RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation [C]// MICCAI 2015: Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention. Berlin: Springer International Publishing, 2015: 234-241.
[17] ZHANG R, ZHU J Y, ISOLA P, et al. Real-time user-guided image colorization with learned deep priors [J]. ACM Transactions on Graphics, 2017, 36(4): Article No. 119.
[18] LIZUKA S, SIMOSERRA E, ISHIKAWA H. Let there be color!: joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification [J]. ACM Transactions on Graphics, 2016, 35(4): Article No. 110.
[19] QIN P L, CHENG Z R, CUI Y H, et al. Research on image colorization algorithm based on residual neural network [C]// CCCV 2017: Proceedings of the 2017 CCF Chinese Conference on Computer Vision, CCIS 771. Berlin: Springer, 2017: 608-621.
[20] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 770-778.
[21] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2012: 1097-1105.
[22] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// CVPR 2015: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 1-9.
[23] SRIVASTAVA R K, GREFF K, SCHMIDHUBER J. Highway networks [J/OL]. arXiv Preprint, 2015, 2015: arXiv.1505.00387 (2015-03-03) [2018-08-10]. https://arxiv.org/abs/1505.00387.
[24] HUANG G, SUN Y, LIU Z, et al. Deep networks with stochastic depth [C]// ECCV 2016: Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 646-661.
[25] LARSSON G, MAIRE M, SHAKHNAROVICH G. FractalNet: ultra-deep neural networks without residuals [J/OL]. arXiv Preprint, 2016, 2016: arXiv.1605.07648 (2016-05-24) [2018-08-16]. https://arxiv.org/abs/1605.07648.
[26] HUANG G, LIU Z, LAURENS V D M, et al. Densely connected convolutional networks [C]// CVPR 2017: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 2261-2269.
[27] ZHOU B, LAPEDRIZA A, XIAO J, et al. Learning deep features for scene recognition using places database [C]// NIPS 2014: Proceedings of the 2014 27th International Conference on Neural Information Processing Systems. Cambridge, CA: MIT Press, 2014: 487-495.
[28] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// CVPR 2009: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 248-255.
[29] ABADI M, AGARWAL A, BARHAM P, et al. TensorFlow: large-scale machine learning on heterogeneous distributed systems [J/OL]. arXiv Preprint, 2016, 2016: arXiv.1603.04467 [2018-08-14]. https://arxiv.org/abs/1603.04467.
