基于机器学习的异构多核处理器系统在线映射方法
2019-08-27安鑫张影康安陈田李建华
安鑫 张影 康安 陈田 李建华


摘 要:异构多核处理器(HMPs)平台已成为现代嵌入式系统的主流解决方案,其中在线映射或调度对充分发挥其高性能和低功耗的优势起着至关重要的作用。针对HMPs的应用任务动态映射问题,提出了一种基于机器学习预测模型的在线映射调度解决方案。一方面,构建了一个可以快速高效地预测和评估不同映射方案性能的机器学习模型,为在线调度提供支持;另一方面,将该机器学习模型整合到遗传算法中以高效地找到(接近)最优的资源分配方案。最后,通过一个M-JPEG解码器验证了所提方法的有效性。实验结果表明,该方法的平均执行时间相较于常见的轮询调度和抽样调度方法分别降低了28%和19%左右。
关键词:异构多核处理器;机器学习;动态资源分配;性能预测;映射和调度
中图分类号: TP302.7
文献标志码:A
Abstract: Heterogeneous Multi-core Processors (HMPs) platform has become the mainstream solution for modern embedded system design, and online mapping or scheduling plays a vital role in making full use of the advantages of high performance and low power consumption. Aiming at the dynamic mapping problem of application tasks in HMPs, a mapping and scheduling approach based on machine learning prediction model was proposed. On the one hand, a machine learning model was constructed to predict and evaluate the performance of different mapping strategies rapidly and efficiently, so as to provide support for online scheduling. On the other hand, the machine learning model was integrated with genetic algorithm to find out the optimal resource allocation strategy efficiently. Finally, an Motion-Join Photographic Experts Group (M-JPEG) decoder was used to verify the effectiveness of the proposed approach. The experimental results show that, compared with the Round Robin Scheduler (RRS) and sampling scheduling approaches, the proposed online mapping/scheduling approach has reduced the average execution time by about 19% and 28% respectively.
Key words: Heterogeneous Multi-core Processors (HMPs); machine learning; dynamic resource allocation; performance prediction; mapping and scheduling
0 引言
為了满足现代嵌入式系统对高性能、低功耗的需求,异构多核处理器(Heterogeneous Multi-core Processors, HMPs)已经得到了广泛使用,如ARM big.Little移动设备[1]和新款iPhone XS配备的A12仿生异构多核处理芯片[2]。该类处理器能够将高时钟频率、复杂指令集的大核和低时钟频率、简单指令集的小核相结合,以此来满足不同运行场景的需要[3]。另一方面,为了进一步提高现代嵌入式系统的能效,动态电压和频率调整(Dynamic Voltage and Frequency Scaling, DVFS)技术应运而生,它通过根据需要调整核心频率来实现节能需求,在现代处理器中也得到了普遍的应用[4]。然而,要充分利用HMPs和DVFS技术来提高系统的性能并降低功耗,需要解决的一个很重要的问题就是任务的动态映射(或调度)问题。动态映射问题是指在系统运行过程中,当系统运行环境发生变化时如何为系统中的应用任务进行相应的资源分配和调度,从而使其达到优化性能和功耗等方面的要求。
解决动态映射问题的关键是要能够在环境发生变化后对可能的资源分配和调度方案进行性能等方面的评估,并从中选择最优或者接近最优的映射调度方案。传统的性能评估方法可以概括为两类:一类是通过为系统建立抽象的数学评估模型(又称为成本模型)来进行计算,另一类是通过对系统进行仿真模拟来获得[5]。成本模型可以通过建立相关模型对系统不同调度方案的性能或者功耗进行高效评估,然而其准确性依赖于模型本身及其相关参数的准确性,而这些参数对于大部分系统来说一方面是动态可变的,另一方面往往难以准确获得,从而导致该类方法精度不足;而基于仿真模拟的方法,为了提高评估准确性,需要尽可能地对系统的实现细节进行实现和模拟,从而导致该类方法比较耗时,不适于在线对大量的调度方案进行快速评估。因此,如何创建一种既能结合成本模型的快速高效、又能兼顾模拟仿真模型准确性的方法,在提高准确性的同时提高评估准确性,从而为系统动态进行分配资源和调度提供支持也就成为了业界一直以来的研究热点。
机器学习和深度学习技术目前在自然语言处理、图像识别、推荐系统与博弈等领域取得了很大的成功[6]。这也吸引了嵌入式系统设计领域专家和学者的浓厚兴趣,特别是面对设计复杂度日益增长的问题,机器学习技术可以从过去解决问題的经验中学习知识,以快速高效的方式找到高质量的设计方案,这无疑大大减轻了设计人员的工作负担。目前,已经有基于机器学习技术来解决异构多核系统调度问题的方法被提出并取得了良好的效果。这方面的工作主要有两类:一类工作是针对调度方案的性能和/或功耗预测,如文献[7-8];另外一类是针对任务的动态调度,如文献[9-10]。然而,尽管过去几年机器学习技术获得越来越多的关注,但它在改善异构多核系统性能方面仍处于早期阶段[6]。大部分工作考虑系统运行时的细节信息(如中央处理器的利用率、内存和通信互连的使用情况),但是这些细粒度信息通常不易得到而且获取的代价较大,不能很好地解决在线映射调度兼顾高效和准确性的问题;另外目前大部分工作针对的是独立任务的动态资源分配和调度问题,并没有考虑任务之间依赖关系所带来的问题复杂度。
针对具有DVFS功能的HMPs系统应用任务动态映射问题,本文提出了一种基于机器学习模型对运行时映射选择进行快速高效评估的动态映射调度解决方案。一方面该方案仅利用少许易获取的运行时信息(比如映射位置),另一方面该方案可以处理采用有向无环图(Directed Acyclic Graph, DAG)描述的应用任务映射问题,从而能够在动态调度中考虑任务依赖关系可能带来的差异。具体而言,本文的工作主要包含以下两个方面:
1)本文通过采用机器学习技术构造系统性能预测模型来对不同映射方案和每个核的频率值进行高效性能评估,并通过实验验证了其准确性。
2)提出了一种结合遗传算法(Genetic Algorithm, GA)和机器学习预测模型的运行时动态映射方法,并通过实验与当前常用的动态映射方法和最优化的映射方法进行了比较和分析。
1 相关工作
随着当前嵌入式系统设计复杂性的增加,处理器上核的数目不断地增长,如何设计和实现应用程序的映射和调度已经成为研究的热点之一。而并行程序的映射和调度是一个众所周知的NP完全问题(Non-deterministic Polynomial complete problem)[11],这意味着详尽地探索所有的映射选择从而找到最优的映射方案是非常耗时的,也是不可行的。因此,目前关于映射问题的研究大多数是基于启发式算法[12-14]来找到一个近似的最优解。文献[15]中对嵌入式系统设计空间的快速探索和评估的设计技术进行了详细的介绍。本文主要关注结合机器学习技术来解决异构多处理器的任务调度问题的技术和方法,故接下来主要讨论基于机器学习模型来处理映射性能预测和动态调度的相关研究。
文献[16]通过学习不同应用程序行为在不同核上的功耗来构建一个回归预测模型,从而提出了一个可以优化系统功耗的频率电压动态调节管理解决方案。文献[17]提出了基于机器学习的方法来优化用一种面向多核的StreamIt语言编写的应用程序,从而在动态的多核上执行时找到最佳的映射方式。为了最大限度地提高系统的性能,该研究分别使用K-邻近算法和线性回归算法来构建模型,用来预测应用程序划分的最佳线程数以及每个线程所需要的最佳内核数。文献[18]提出了一种多核平台的执行时间和能耗的预测方法,将不同映射方案通过编码的方式采用人工神经网络(Artificial Neural Network, ANN)算法进行训练,从而帮助设计者找到最优的资源分配。
文献[19]通过选择和提取开放运算语言(Open Computing Language, OpenCL)程序的静态和动态特征,及其在核上的运行时性能来对支持向量机(Support Vector Machine, SVM)模型进行训练,训练后的模型用来预测未知应用程序出现时所对应映射的目标核的类型。然而,该模型没有考虑多核的情况,只是将处理核的类型划分为一个中央处理器和一个图形处理器。在后续的研究工作文献[20]中,考虑更多的处理核的类型,使用多个SVM模型进行训练,根据优化目标来确定运行时处理核的配置。
文献[21]提出了一个基于ANN的应用程序动态资源分配技术,每个ANN都输入一些细粒度的资源信息和程序最近行为,包括二级缓存空间、片外带宽、功率预算、在一级缓存中读/写命中,以及读丢失/写丢失的数量,根据这些输入信息,ANN将预测出应用程序的性能,从而得到最优调度方案。相似的,文献[6]提出了一种最大化吞吐量的调度模型,并采用ANN技术为不同应用调度提供精确的性能预测,从而提高异构多核系统的调度效率。
文献[22]建立了基于反馈神经网络和径向基神经网络的模型来预测多核处理器的性能和功耗,通过选取对性能影响比较大的参数,如发射宽度、二级缓存大小和二级缓存命中延迟等,来预测不同调度策略下的性能值,以此来提高设计空间的探索效率。文献[23]提出了一个基于SVM的任务分配模型,通过分析处理器和任务的特征(如任务的类型、数据量大小、并行化程度)以及当前运行状态,来预测任务的最优分配方案。
文献[9]研究了多线程应用程序在异构多核体系结构上的调度问题,并建立了五种基于机器学习算法的预测模型,该算法可以预测最优的线程数和相应的电压和频率值,以此最大限度地提高能源效率。在运行时从应用程序分析中提取的一组输入特性,根据类别可分为内存、指令和分支。在创建模型之后,实验结果表明,与基于回归模型和基于决策树模型的分类器相比,多层感知器这种较复杂的预测器具有更高的精度,但是与此同时会有更高的时间开销。
可以看到,当前大部分工作构建机器学习模型均依赖于系统运行时的细节信息(如二级缓存状态),而这些细粒度信息获取的代价较大,从而导致在线映射调度方法开销过大;另外这些工作要么只针对多核系统的映射问题,要么只针对DVFS动态调节,而本文则同时考虑两者的动态管理。
2 基于机器学习的在线映射方法
本部分介绍本文提出的基于机器学习的在线映射方法,其中2.1部分介绍该方法的整体框架,2.2部分介绍对映射方案进行快速性能预测的模型构建过程,2.3部分介绍本文所采用的在线映射方法搜索方案——遗传算法。
2.1 整体框架
本文提出的基于机器学习的在线映射方法整体设计框架如图1所示,分为:1)离线训练(图1(a)),即映射方案性能预测模型构建;2)在线调度(图1(b)),即运行时动态映射方案搜索、评估和选择。
在离线训练阶段,考虑DAG描述的系统应用和基于二维片上网络(Network on Chip, NoC)的异构多核处理器运行平台,而且每个核在运行时是可以进行动态频率调整的。在这个阶段,希望采用机器学习方法来对系统的映射方案进行学习并最终获得相应的性能预测模型。为了产生相应的训练数据集,首先使用CLASSY(CLock AnalysiS System)模拟器[24]来模拟和分析不同映射方案的执行时间等性能指标从而得到初始数据,然后对初始训练集进行预处理。得到训练集后通过选择合适的机器学习方法就可以对性能预测模型进行构建。
在线调度阶段,对于给定的应用程序和执行平台,当运行时发生不可预知的动态事件(如某个运行核由于负载过高或故障等原因不可用、某两个核之间的通信断开)时,在线调度器需要对这种动态变化作出快速的响应,也就是对资源进行重新分配和调度,从而满足系统对性能、功耗等方面的需求,比如性能最优化。为了做到这一点,在线调度器一方面需要通过启发式算法对当前状态下的资源分配方案进行快速高效的搜索,另一方面需要同时对不同方案进行性能评估(通过离线训练得到的预测模型进行),并最终从中选取最优的映射决策。
2.2 离线训练——性能预测模型构建
对应用程序在异构多核系统上的不同映射方案进行性能预测可以看作一个线性回归问题,鉴于该问题的复杂性,本文选用已得到广泛使用的ANN进行预测模型的学习和构建。
2.2.1 人工神经网络
人工神经网络(ANN),又称为多层前馈神经网络,它是由“M-P神经元模型”为基础发展而来[25]。 ANN的结构如图2所示,它由输入层、隐藏层和输出层组成,各层神经元与相邻层神经元之间相互全相联。输入层神经元用来接收外界的输入参数,通过各层连接的权值与对应的输入参数相乘,再与该层其他神经元传入连接的结果相加,它们的和会被传递到神经元的激活函数中(如修正线性函数),最后将这些神经元的输出作为输入传递到下一层隐藏神经元或输出神经元中。在训练期间,ANN可以通过Adam(Adaptive moment estimation)优化算法[26]来调整权值,以此找到一个最优的极小值使得实际输出与网络计算输出之间的预测误差最小化。
2.2.2 预测模型建模
采用人工神经网络模型来对映射方案的性能指标进行预测,关键在于识别对性能结果产生影响的关键信息或特征。考虑到运行时信息获取的难易程度以及动态映射对高效性的需求,本文采用任务在异构多核系统的映射位置以及所映射核的频率值作为模型的输入信息。下面介绍本文所采用的输入信息编码方式。
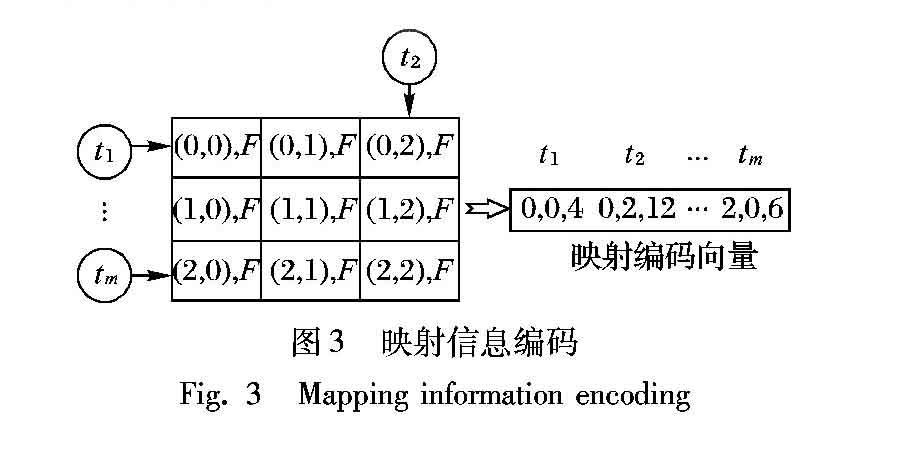
图3给出了一个由m个任务(t1,t2,…,tm)构成的应用在由9个核构成的二维片上网络(Network on Chip, NoC)(3×3)异构多核系统上的映射编码方式。异构多核系统中的核根据位置用二维笛卡儿坐标进行表示,并且每个核有F={fk|k=1,2,…,|F|}种频率可供选择,图中箭头表示当前任务映射到哪个核上。每一种映射方案可以表示为一个映射编码向量,该向量由t1, t2,…,tm所映射的目标核的位置坐标以及所选择的频率组合而成。
此外,在将含有映射位置和频率的编码输入信息给预测模型训练之前,为了提高梯度收敛的速度,需要对频率进行特征缩放处理。本文所采用的方法是对每个核的频率值都除以固定的数,从而保证频率的范围处在0到20之间。以图3中所示的映射方案为例,当任务t1映射到坐标为(0,0)、频率为40MHz的核上,任务t2映射到坐标为(0,2)、频率为120MHz的核上,任务tm映射到坐標为(2,0)、频率为60MHz的核上时,通过把它们的频率都除以10,可以得到映射编码(0,0,4,0,2,12,… ,2,0,6)。
2.2.3 性能评估标准
度量不同学习模型的泛化能力,不仅要有高效的实验预测方法,还要有衡量模拟器泛化能力的评估标准。回归问题常用的预测度量标准是计算真实值与实际值之间的均方误差(Mean Squared Error, MSE),MSE值越低,预测模型准确度越高。然而,本文的目标是能够在运行时从多个映射方案中选择一个相对最好的映射方案, 因而得到一个可以对映射方案的性能值进行正确排序的模型就足够了。当预测模型的MSE值很低的时候这种相对大小是可以保证的,而MSE值很高的时候并不能说明这种相对大小就一定不能够得到保证。因而,为了得到一个可以对若干个映射方案性能值相对大小进行预测的模型,需要一种可以对预测数值的相对大小(或者趋势)进行评估的方法。本文采用常用的趋势预测指标皮尔逊相关系数(Person Correlation Coefficient, PCC)来进行评估,表示如下:
其中:N表示测试样本的个数;Pi表示预测模型预测的性能值;Ei表示模拟器运行得到的真实值;P和E分别表示预测样本和真实样本的平均值;σP和σE分别表示预测样本和真实样本的标准差。r的值介于-1和1之间,当r的绝对值越接近1,表示预测值越接近真实值,性能预测模型越好。
2.3 在线调度
在系统运行过程中,当运行环境发生变化时,在线调度模块需要能够对相应的可选映射方案进行高效的搜索、评估,并选择最优或者接近最优的解决方案。在2.2节构建的映射方案预测模型基础上,还需要一个可以高效地引导、并选择尽可能最优映射方案的搜索机制。鉴于该类问题搜索空间的庞大,本文采用文献[27]中的一个遗传算法(GA)来在线对系统的映射空间进行搜索,鉴于篇幅限制该算法细节不再详述。
如图1(b)中所示,在线调度模块的基本工作流程包括:1)当应用程序启动后,算法GA迭代搜索映射方案空间,并根据搜索目标和预测模型对各个映射方案的性能预测结果来确定初始映射方案,然后对初始方案在运行平台上进行相应部署;2)每当系统运行状态发生变化时,如某个运行核由于负载过高或故障等原因不可用时,在线搜索、评估当前系统状态下可行的映射方案,并从中选择最优的映射方案重新进行部署。
3 CLASSY模拟工具
本文使用文献[24,28]的CLASSY模拟器来分析异构多核处理器上不同映射方案的性能指标,该模拟器是基于Lee等[29]针对嵌入式系统建模(Model of Computation)所提出的Tagged Model构建的。
为了采用Tagged Model对应用程序运行行为进行描述,CLASSY定义了两个集合:一个逻辑时刻的离散集合T(包含最小元素τmin且与一个偏序相关联)和一个值域集合V(表示事件的运行时间或功耗)。二元组(τ,υ),其中τ∈T,υ∈V,表示一个事件e。事件e可以是任务运行过程中的某次运算或者某次信息传输等,一个连续的事件集合就构成一个任务t的行为bt,可以用bt={ e0,e1,…} 表示。基于事件e和任务行为bt的定义,可以对应用程序行为进行以下定义。
定义1 给定一个任务集合T构成的应用程序,则其行为可用一对(∪bt(t∈T),)表示,其中∪bt(t∈T)表示所有任务t∈T中事件的集合,表示事件之间的偏序关系。
图4给出了一个由三个任务T={t0,t1,t2}组成的应用程序的行为bT,其中bt0={e00,e10},bt1={e01,e11},bt2={e02,e12}。图4中的箭头表示事件间的优先关系(比如某个人物的运算需要等待其他任务的计算结果),如箭头从事件e00指向事件e02则表示为e00e02,而两个事件之间没有箭头连接意味着它们之间没有优先关系约束,如事件e10和事件e01。
针对异构多核处理器平台,该模拟器采用了基于同步时钟的模型来进行模拟,并可以对各个处理核在不同运行频率下的行为进行区别。给定相应的应用和平台描述后,该模拟器就可以对不同的映射调度方案进行性能分析和评估。此外,它还提供了一种动态映射调度模拟机制,允许用户通过整合自己的动态映射算法来对运行时的不同调度选择进行时间等方面的性能评估。鉴于篇幅限制,这方面的具体细节不再详述。
4 实验与结果分析
为了验证本文提出的基于机器学习的在线映射调度方法的效果和效率(即响应时间),分别进行两方面的实验:1)4.2节的实验验证所构建机器学习预测模型的准确度和效率;2)4.3节的实验验证整合遗传算法和预测模型的在线映射调度算法的效果和效率。
4.1 实验设置
本文采用的应用实例是文献[27]中使用的M-JPEG(Motion-Join Photographic Experts Group)解码器(如图5所示),该应用程序由5个任务组成,包括Demux、VLD、IQZZ、IDCT和Libu;所使用的运行平台是一个2×3的二维NoC异构多核平台(如图6所示),该平台由五个核{p1,p2,… ,p5}组成,其中核p1、p2、p3分配到第一行,分别用二维笛卡儿坐标(0,0)、(0,1)和(0,2)表示,该行核有两种频率可供选择{40MHz,80MHz},核p4、p5分配到第二行,分别用坐标(1,0)和(1,1)表示,该行核可供选择的频率是{60MHz,120MHz}。本文所运行实验的机器配置为CPU: Intel Core i5-6600 3.4GHz、内存:32GB。
4.2 预测模型的准确性验证
在这部分中,我们将分别介绍构建性能预测模型的数据集获取、所采用ANN算法进行模型训练的参数设置和对所获取模型的验证分析结果。
4.2.1 数据集获取
对于4.1节给出的M-JEPG应用程序和执行平台,采用ClASSY模拟器来产生所需要的数据集。首先,随机生成30000种映射方案作为数据集,然后将以上数据集划分为训练集和测试集。按照机器学习模型训练和验证常用的划分方法,将总数据集的65%(即19500种)用来训练模型,剩下的35%(即10500种)作为测试集用来评估该模型在未知数据上的预测能力。
4.2.2 ANN算法参数设置
本文使用人工神经网络(ANN)算法来学习得到目标性能预测模型。为此,本文使用Pytorch软件包对人工神经网络模型进行训练,使用高斯分布来随机初始化权值矩阵,训练过程中采用Adam优化方法迭代更新参数。根据多次实验测试优化相关超参数,表1给出了最终相关超参数的详细设置。
4.2.3 ANN性能预测模型的验证
图7给出了经过学习后得到的人工神经网絡预测模型在所有测试集数据上的预测情况,其中,横轴(X轴)表示由CLASSY模拟器得到的实际值,纵轴(Y轴)表示由预测模型给出的预测值。图7中每一个点表示测试集中的一种映射方案,每一个点的位置表示实际值和预测值的相对偏差。当相关系数为1时,则所有的数据点都将收敛到X=Y的函数曲线上,表示预测值与实际值相等。从图7可以看出,本文所获得的ANN预测模型的预测效果很接近X=Y函数曲线,预测效果非常好。另外,通过计算得到该预测模型的预测值和实际值之间的皮尔逊相关系数值:0.97,非常接近1,因而这两组数据是非常相关的,从而可以验证本文得到的人工神经网络预测模型可以对映射方案性能值的相对大小进行准确的预测。
此外,在本实验中对ANN模型离线训练所需时间是4min,生成预测模型的大小是4KB,而采用该模型进行预测的响应时间为2.4ms。
4.3 动态调度方案效果验证
为了验证本文动态调度方案的效果,通过随机生成一个固定长度系统运行时的事件序列,例如某个运行核由于负载过高或故障等原因不可用、某两个核之间的通信断开等,来进行实验。考虑到采用遗传算法不同参数对算法的影响,首先通过实验评估不同参数的效果和开销,然后将本文方法分别与常见的轮询调度(Round Robin Scheduler, RRS)[30] 、抽样调度和通过遍历所有方案获得的最优化方法进行对比实验。
4.3.1 算法参数评估实验
对于遗传算法,需要考虑如下参数:1)种群规模(population),每一代种群染色体总数;2)迭代(iteration),种群交叉变异迭代的次数;3)基因(gene),用于表示个体的特征;4)交叉概率(P_cross),在循环中进行交叉操作所用到的概率;5)变异概率(P_mutation),从个体群中产生变异的概率。表2给出了M-JPEG解码器在保持执行平台不变的情况下,种群规模(#popu.)和迭代次数(,#inter.)的选取对算法开销和执行时间的影响(交叉概率和变异概率根据若干实验验证分别选取效果最好的0.8和0.003)。
从表2中可以看出,随着迭代次数和种群规模不断变大,其方案效果越来越好(执行时间越来越短),然而相应的实践开销也越来越大。综合考虑执行时间和算法开销,在后面的实验中均采用种群规模为1000,迭代次数为10。
4.3.2 方案效果比较实验
图8给出了四种调度方法在100个随机事件序列场景下得到的平均执行时间,其中每个随机事件序列包括10个事件(如某个运行核由于负载过高或故障等原因不可用、某两个核之间的通信断开等),并且事件发生的时间是随机的。
从图8中可以看出:轮询调度的执行时间最长,主要原因在于轮询调度将任务的请求轮流分配给每个核,但是这种调度方式通常忽略了任务和每个核各自的特点和需求,无法充分发挥异构多核处理器的优势,因而效果最差。抽样调度是从1000个候选的映射方案中抽选最优的调度方案并执行调度,这种调度方式的表现往往会优于轮询调度,但是其调度结果受到随机抽样的约束。最优调度是探索每一种系统动态场景中所有的映射方案,从而选出最优的调度方法,该调度模型无疑是最优的,但是遍历所有可能性并进行性能评估的时间开销过大(本实验中平均需要2.83min),不适合解决动态映射调度问题。而本文的调度模型是通过遗传算法和机器学习相结合的方式,相较于轮询和抽样调度,遗传算法通过不断迭代的方式能够高效地引导搜索的方向,相较于最优调度,基于机器学习的性能预测模型能够在缩短在线搜索评估开销的同时给出接近最优调度的效果,本实验中每次调度调整平均需要时间为0.93s。
在本实验中,本文提出的基于机器学习预测模型的在线映射调度方法在平均執行时间方面相较于常用的轮询调度和抽样调度方法能够分别降低了28%和19%,并达到接近最优的解决方案。
5 结语
本文提出了一种基于机器学习预测模型的在线映射方法:一方面通过采用机器学习技术来构造系统性能预测模型来,从而对不同映射方案和每个核的频率值进行高效的性能评估;另一方面,将其与遗传算法进行整合构造了一个在线的映射调度方法。实验结果表明,所提方法在平均执行时间方面相较于常用的轮询调度和抽样调度方法能够分别降低了28%和19%,并接近最优的解决方案。
下一步的研究分两方面进行:一方面希望采用更广泛多样的案例来验证该在线映射方法的效果;另一方面由于目前采用的模拟工具对于异构多核系统中每个核之间的通信开销以及任务迁移的开销精确度不足,我们希望在进一步研究基础上,使用更加精确的模拟工具或者是基于实际的异构多核平台(比如ARM big.Little)来进行实验。此外,在接下来的工作中,我们还将考虑通过改进在线调度算法来进一步提高映射效果。
参考文献 (References)
[1] GREENHALGH A P. Big. LITTLE processing with ARM cortexTM-A15 & cortex-A7 [EB/OL]. [2018-09-19]. https://www.arm.com/files/downloads/b-igLITTLE Final Final.pdf.
[2] Apple Inc. A12-bionic [EB/OL]. [2018-09-12]. https://www.apple.com/cn/iphone-xs/a12-bionic/.
[3] LI C V, PETRUCCI V, MOSSE D. Predicting thread profiles across core types via machine learning on heterogeneous multiprocessors [C]// Proceedings of the 2016 VI Brazilian Symposium on Computing Systems Engineering. Piscataway, NJ: IEEE, 2016: 56-62.
[4] LE SUEUR E, HEISER G. Dynamic voltage and frequency scaling: The laws of diminishing returns [C]// HotPower 2010: Proceedings of the 2010 International Conference on Power Aware Computing and Systems. Berkeley, CA: USENIX Association, 2010: Article No. 1-8.
[5] GOLI M, MCCALL J, BROWN C, et al. Mapping parallel programs to heterogeneous CPU/GPU architectures using a Monte Carlo tree search [C]// CEC 2013: Proceedings of the 2013 IEEE Congress on Evolutionary Computation. Piscataway, NJ: IEEE, 2013: 2932-2939.
[6] NEMIROVSKY D, ARKOSE T, MARKOVIC N, et al. A machine learning approach for performance prediction and scheduling on heterogeneous CPUs [C]// Proceedings of the 2017 IEEE 29th International Symposium on Computer Architecture and High Performance Computing. Piscataway, NJ: IEEE, 2017: 121-128.
[7] ZHANG Y Q, LAURENZANO M A, MARS J, et al. SMiTe: precise QoS prediction on real-system SMT processors to improve utilization in warehouse scale computers [C]// Proceedings of the 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture. Washington, DC: IEEE Computer Society, 2014: 406-418.
[8] MICHALSKA M, CASALE-BRUNET S, BEZATI E, et al. High-precision performance estimation for the design space exploration of dynamic dataflow programs [J]. IEEE Transactions on Multi-Scale Computing Systems, 2018, 4(2): 127-140.
[9] SAYADI H, PATEL N, SASAN A, et al. Machine learning-based approaches for energy-efficiency prediction and scheduling in composite cores architectures [C]// Proceedings of the 2017 35th IEEE International Conference on Computer Design. Piscataway, NJ: IEEE, 2017: 129-136.
[10] WANG L, LIU S L, LU C, et al. Stable matching scheduler for single-ISA heterogeneous multi-core processors [C]// APPT 2015: Proceedings of the 2015 International Workshop on Advanced Parallel Processing Technologies, LNCS 9231. Cham: Springer, 2015: 45-59.
[11] ULLMAN J D. NP-complete scheduling problems [J]. Journal of Computer and System Sciences, 1975, 10(3): 384-393.
[12] ROY P, ALAM M M U, DAS N. Heuristic based task scheduling in multiprocessor systems with genetic algorithm by choosing the eligible processor [J]. International Journal of Distributed and Parallel Systems, 2012, 3(4): 111-121.
[13] CHATTERJEE N, PAUL S, MUKHERJEE P, et al. Deadline and energy aware dynamic task mapping and scheduling for network-on-chip based multi-core platform [J]. Journal of Systems Architecture, 2017, 74: 61-77.
[14] GHARSELLAOUI H, KTATA I, KHARROUBI N, et al. Real-time reconfigurable scheduling of multiprocessor embedded systems using hybrid genetic based approach [C]// Proceedings of the 2015 IEEE/ACIS 14th International Conference on Computer and Information Science. Piscataway, NJ: IEEE, 2015: 605-609.
[15] SINGH A K, SHAFIQUE M, KUMAR A, et al. Mapping on multi/many-core systems: survey of current and emerging trends [C]// DAC 2013: Proceedings of the 2013 50th ACM/EDAC/IEEE Design automation conference. Piscataway, NJ: IEEE, 2013: 1-10.
[16] CAI E, JUAN D C, GARG S, et al. Learning-based power/performance optimization for many-core systems with extended-range voltage/frequency scaling [J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2016, 35(8): 1318-1331.
[17] MICOLET P J, SMITH A, DUBACH C. A machine learning approach to mapping streaming workloads to dynamic multicore processors [C]// LCTES 2016: Proceedings of the 2016 17th ACM SIGPLAN/SIGBED Conference on Languages, Compilers, Tools, and Theory for Embedded Systems. New York: ACM, 2016: 113-122.
[18] GAMATIE A, URSU R, SELVA M, et al. Performance prediction of application mapping in manycore systems with artificial neural networks [C]// Proceedings of the 2016 IEEE 10th International Symposium on Embedded Multicore/Many-core Systems-on-Chip. Piscataway, NJ: IEEE, 2016: 185-192.
[19] WEN Y, WANG Z, OBOYLE M F P. Smart multi-task scheduling for OpenCL programs on CPU/GPU heterogeneous platforms [C]// HiPC 2014: Proceedings of the 2014 21st International Conference on High Performance Computing. Piscataway, NJ: IEEE, 2014: 1-10.
[20] TAYLOR B, MARCO V S, WANG Z. Adaptive optimization for OpenCL programs on embedded heterogeneous systems [C]// LCTES 2017: Proceedings of the 18th ACM SIGPLAN/SIGBED Conference on Languages, Compilers, and Tools for Embedded Systems. New York: ACM, 2017: 11-20.
[21] BITIRGEN R, IPEK E, MARTINEZ J F. Coordinated management of multiple interacting resources in chip multiprocessors: a machine learning approach [C]// MICRO 41: Proceedings of the 41st annual IEEE/ACM International Symposium on Microarchitecture. Washington, DC: IEEE Computer Society, 2008: 318-329.
[22] 袁景凌,繆旭阳,杨敏龙,等.基于神经网络的多核功耗预测策略[J].计算机科学,2014,41(6A):47-51.(JIAO J L, MIAO X Y, YANG M L, et al. Neural network based power prediction strategy for multi-core architecture [J]. Computer Science, 2014, 41(6A): 47-51.)
[23] 王彦华,乔建忠,林树宽,等.基于SVM的CPU-GPU异构系统任务分配模型[J].东北大学学报(自然科学版),2016,37(8):1089-1094.(WANG Y H, QIAO J Z, LIN S K, et al. A Task allocation model for CPU-GPU heterogeneous system based on SVMs [J]. Journal of Northeastern University (Natural Science), 2016, 37(8): 1089-1094.)
[24] AN X, BOUMEDIEN S, GAMATIE A, et al. CLASSY: a clock analysis system for rapid prototyping of embedded applications on MPSoCs [C]// SCOPES 2012: Proceedings of the 2012 15th International Workshop on Software and Compilers for Embedded Systems. New York: ACM, 2012: 3-12.
[25] HAYKIN S S. Neural Networks: a Comprehensive Foundation [M]. Upper Saddle River, NJ: Prentice Hall, 1994: 133-147.
[26] KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2018-09-19]. https://www.docin.com/p-1725989690.html. Proceedings of the 2014 International Conference on Learning Representations.arXiv preprint arXiv.1412.6980, 2014.
[27] HOLLAND J H. Adaptation in Natural and Artificial Systems: an Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence [M]. Cambridge, MA: MIT press, 1992: 32-58.
[28] AN X, GAMATIE A, RUTTEN E. High-level design space exploration for adaptive applications on multiprocessor systems-on-chip [J]. Journal of Systems Architecture, 2015, 61(3/4): 172-184.
[29] LEE E A, SANGIOVANNI-VINCENTELLI A. A framework for comparing models of computation [J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 1998, 17(12): 1217-1229.
[30] MARKOVIC N, NEMIROVSKY D, MILUTINOVIC V, et al. Hardware round-robin scheduler for single-ISA asymmetric multi-core [C]// Euro-Par 2015: Proceedings of the 2015 European Conference on Parallel Processing, LNCS 9233. Berlin: Springer, 2015: 122-134.
