基于Jupyter交互式分析平台的微服务架构①
2019-08-22贺宗平张晓东
贺宗平, 张晓东, 刘 玉
1(南京审计大学 信息化办公室,南京 211815)
2(南京审计大学 信息工程学院,南京 211815)
3(南京审计大学 实验中心,南京 211815)
1 引言
Jupyter Notebook是当前在数据科学领域非常受欢迎的交互式分析软件,支持Python、R、Julia、Scala、SQL等多种编程语言内核,具备即时编译、可视化和markdown语法编辑等功能[1],为数据分析、数值计算、统计建模、机器学习等方面提供了便捷. 尽管基于web的设计实现方式有许多局限性,Jupyter Notebook在数据科学领域得到了极为广泛应用,主要原因就在于其能够进行交互式、可视化的数据探索性分析,从最简单的点线图、地图以及复杂的D3.js可视化等,甚至可以在某些场景中替代BI工具的功能,这些特点相对于传统IDE编辑器具有颠覆性优势. 但是Jupyter Notebook是传统的单体服务架构模式,缺少多用户管理和访问认证等方面的功能,无法直接部署于计算集群上,难以充分利用和调度计算中心的计算资源.
当今的科研学术论文向着越来越复杂的方式演变,各个研究领域和研究内容对程序依赖度高,需要通过编程来处理数据、绘制图表以及统计分析等. 研究中的程序代码繁琐复杂,直接导致了研究结论难以被他人重复实现,科研的真正价值无法得到交流传播[2].Jupyter Notebook提供了一种混合的编辑方式,将程序代码运行、文字图表编辑等功能糅合在同一电子笔记中,打破了两者之间的隔离界限,将研究中的论述表达和实验分析等过程有机结合起来. 对于科研结论的交流、分享和传播的形式方法上,具有里程碑式的重要意义.
目前,国外一些大型研究机构、实验室以及超算中心开始提供面向多用户的Jupyter Notebook服务[3],目的就是将高性能计算集群资源充分利用起来,为研究人员提供一个性能优异、操作便捷的工具[4-6].
美国国家能源研究科学计算中心(NERSC)在其Cori超算集群上部署Jupyter,为其6000多用户提供了更便捷化的计算资源访问方式,NERSC在“Science Gateway”节点设置多用户管理环境,当用户登录后可以启动一个专属的项目环境,并且能够访问计算中心其他服务、文件和作业,直接访问大规模数据集、作业队列系统,允许用户提交作业,查询作业批处理运行情况. OpenMSI[7]是NERSC目前正在运行的基于云计算平台和Jupyter的质谱成像项目,研究人员可以在web浏览器中对质谱成像数据进行分析、展示和操作.
科罗拉多大学波尔得分校(CU-Boulder)计算研究中心为研究人员提供了大规模计算资源、海量存储等服务,此外还提供计算科学和数据管理方面的咨询服务. 为了更好地提供优质服务,CU-Boulder计算研究中心在其HPC集群上部署了支持并行计算的Jupyter环境,能够支持ipyparallel和MPI for Python.
欧洲原子能研究机构(CERN)开发了SWAN[8](Service for Web based ANalysis)交互式数据分析平台,在集群中通过Docker镜像构建Jupyter Notebook应用,并且支持其内部开发的CERNBox数据云存储服务,使得代码、数据集、文档在其组织内部安全无缝地实现同步和共享,如图1.
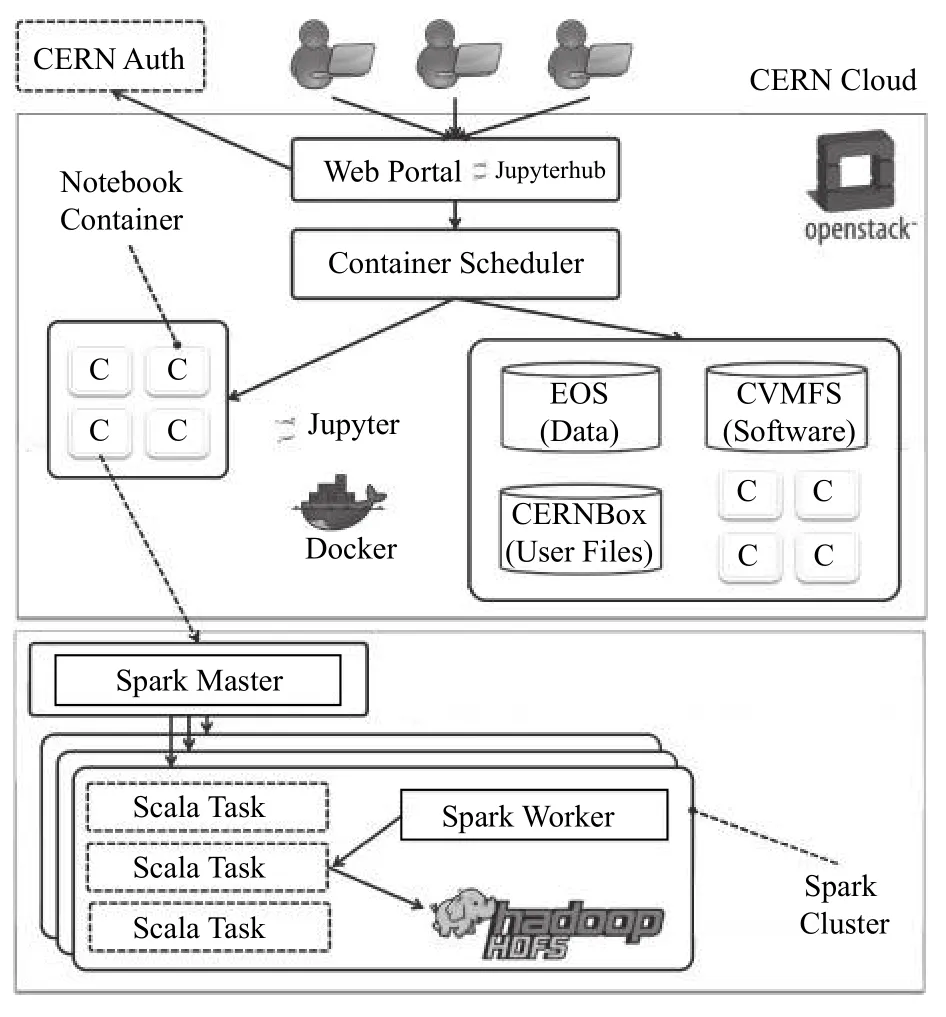
图1 SWAN体系架构示意
本文研究的重心关注Jupyter体系的架构优化与拓展,通过容器和微服务化改造Jupyter体系架构,研究基于Kubernetes集群构建面向多用户的交互式数据分析平台.
2 Jupyter体系架构
2.1 Jupyter Notebook架构特点
Jupyter Notebook是一个典型Web架构的应用,客户端部分负责笔记代码的运行、存储和输出等功能,并通过markdown语法进行标记,以JSON格式发送给服务器端存储,服务器端负责存取笔记代码、调用编译内核等功能.
Jupyter Notebook (如图2)作为最基本的交互式分析程序,缺少平台级的资源调度与管理的能力,不具备面向多用户的服务管理功能,后台运行环境无法做到隔离. 这种状况限制了Jupyter Notebook在计算集群上的部署应用.
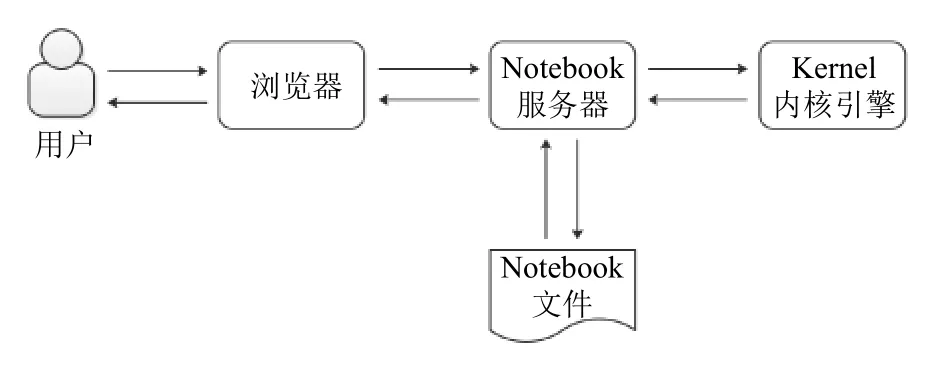
图2 Jupyter Notebook架构示意
2.2 Jupyter Hub的改进与局限
Jupyter Hub在Jupyter Notebook基础上实现了多用户的管理,用于创建、管理、代理多个Jupyter Notebook实例. Jupyter Hub包含3个组件:多用户的Hub管理器、可配置的http代理、多个单用户Jupyter Notebook服务器. Jupyter Hub架构如图3所示.
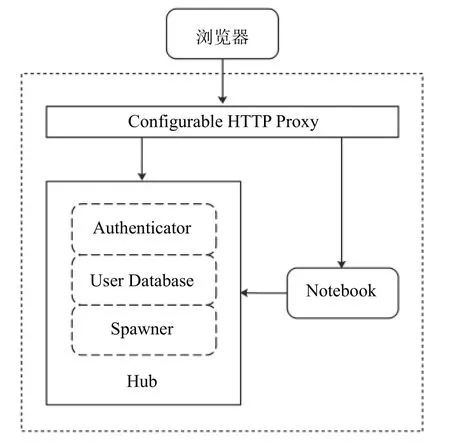
图3 Jupyter Hub架构示意
Jupyter Hub的功能流程[9]包括:首先,Hub服务启动一个代理; 然后,代理默认将所有访问请求转发给Hub; Hub处理用户登录认证并根据需求启动一个单用户的Jupyter Notebook服务器; 最后,Hub配置代理将URL前缀转发给单用户的Jupyter Notebook服务器.Jupyter Hub实现多用户的服务管理、具备访问认证机制,但仍然无法实现集群调度、分布式计算、弹性扩容等功能,特别是无法直接部署在大型计算集群. 对应用系统进行微服务化改造、运用分布式架构是解决问题的根本途径.
2.3 Jupyter微服务化重构
微服务将单体应用(Monolithic)先拆分成多个单元应用,服务间通过HTTP API或消息中间件进行通信,再聚合组成实际应用,这个过程显著改善了系统架构的弹性,同时通过容器技术可以降低系统持续集成与持续部署(CI/CD)的复杂度. 容器作为微服务的一种基础运行方式,具备成熟和强大的工具、平台以及开发生态圈. Jupyter 微服务化重构示意图如图4.
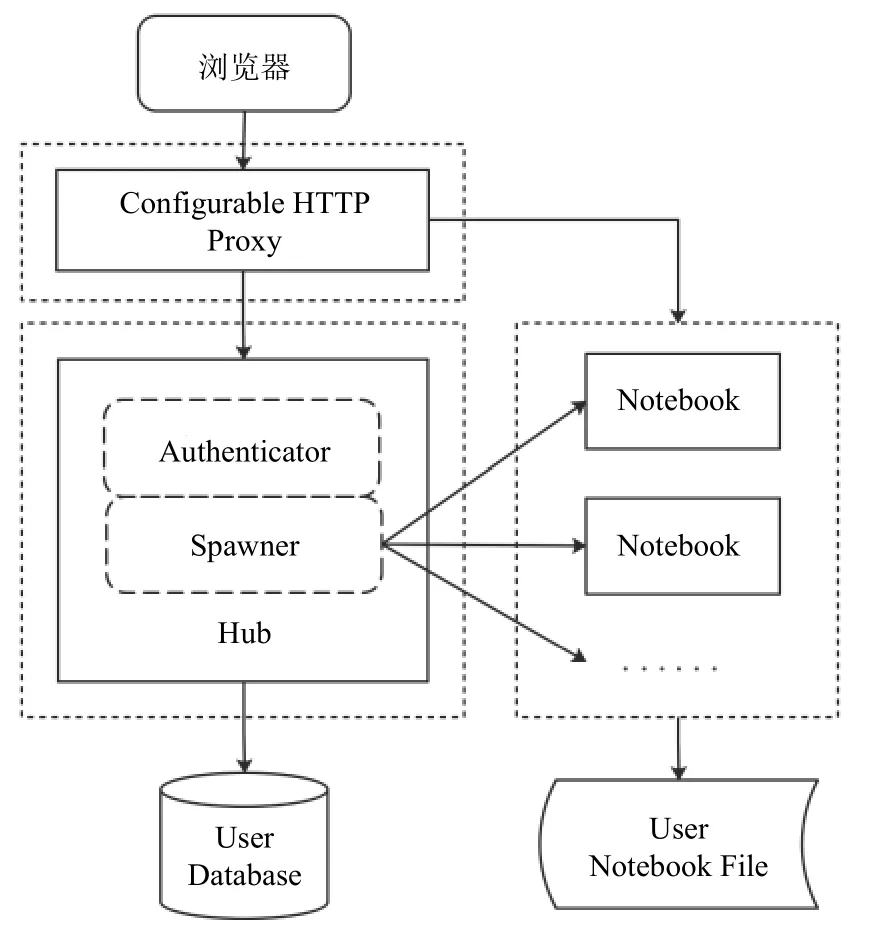
图4 Jupyter微服务化重构示意
2.3.1 微服务架构特点
微服务之父Martin Fowler总结微服务具有3个典型特征[10]:微小化(small),独立化(independently deployable)和自动化(automated deployment). “微小化”是“独立化”的基础,“微小化”代表微服务的设计应当遵循“高内聚、低耦合”的原则,功能边界定义清晰无重叠,“自动化”代表系统组装、部署和运维可以通过工具实现高度的自动化.
康威定律[9](Conway's Law)认为组织结构决定系统结构. 随着组织规模的不断扩大,必然会演化出更多的小型组织. 从这个角度来看,传统单体应用拆分转换为微服务的过程,是系统结构适应平台功能扩展的演变. 微服务降低了系统架构的复杂性,通过将单体应用分解为一组服务,在保持功能不变的条件下,强化了系统模块化的组织水平,使得开发更易于维护.
2.3.2 Jupyter的微服务拆分
单体应用的主要架构特征是系统模块间的“紧耦合”,模块运行在同一进程中. 在系统部分模块更新升级、故障掉线等情况下,需要重新启动整个应用进程,导致系统可靠性和可维护性水平低下. 微服务架构通过对单体应用的不同功能模块进行拆分重构,转换为多个独立的微服务,运行为多个独立的进程,微服务间通过REST、RPC等远程接口通信,实现分布式架构部署[11].
微服务架构包括了无状态化和容器化两个前提准备环节,从架构角度来看,单体架构对状态信息的读写在本地的内存或存储中,从而导致难以进行横向扩展.无状态化的过程是将业务逻辑无状态部分与数据读写存储的有状态部分做分离,业务逻辑经过无状态化处理能够实现横向扩展,状态部分则通过中间件、分布式数据库等进行存储,从而实现单体架构向分布式架构的转化改造. Jupyter Hub的3个主要组成部分:Configurable HTTP Proxy、Hub、Notebook,3个模块间功能界限清晰,完全可以做到微服务化拆分,符合能够独立运行的标准,其中的Hub和Notebook模块需要进行无状态化(stateless)处理. Configurable HTTP Proxy是可配置的访问代理模块,负责代理转发用户的访问请求; Hub中主要包括了认证功能模块(Authenticator)和Notebook生成模块(Spawner),Authenticator提供web安全访问认证的接口,Spawner负责生成和启动各个隔离的Notebook容器.
3 基于Kubernetes微服务架构设计
3.1 相关基本概念
Kubernetes(简称K8S)作为一个分布式集群管理平台,同时也是一个容器编排系统,用于在主机集群之间自动部署、扩展和运行应用程序容器,提供以容器为中心的基础架构. K8S具有如服务命名与发现、负载均衡、运行状况检查、横向弹性伸缩和滚动更新等功能[12],适合在生产环境中部署应用程序. 基于 Kubernetes的Jupyter 微服务架构如图5所示.
Pod:Pod是Kubernetes的基本单元,由一个或多个容器组成,并在同一个物理主机内,共享相同的资源.在pod内部署的所有容器都可以通过localhost看到其他容器. 每个Pod在集群中具有唯一的IP地址.
Service:Service是一组Pod的逻辑区分,是Pod在集群内部被公开访问的策略,同时允许在集群外部IP地址上访问,主要通过ClusterIP、NodePort、Load Balancer和ExternalName等四种方式进行地址暴露.
Replication Controller:Kubernetes的一种控制器,能够在集群中运行指定数目的Pod副本,实现Pod的数量伸缩(scale)操作.
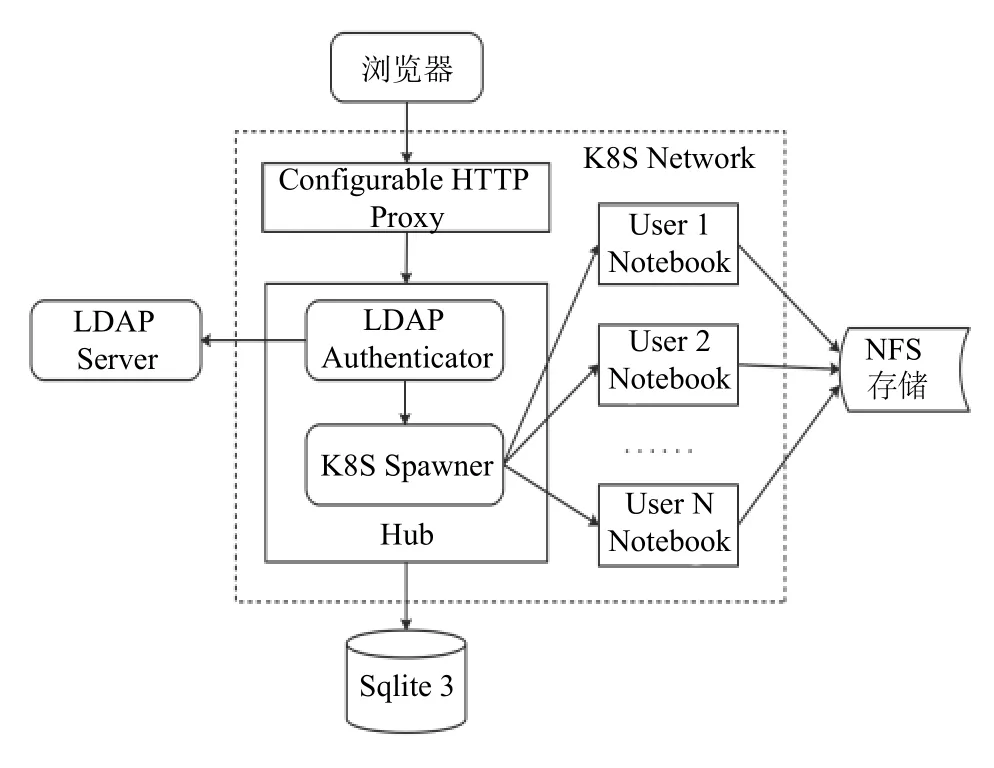
图5 基于Kubernetes的Jupyter微服务架构
3.2 Jupyter微服务架构要素
3.2.1 访问认证
交互式数据分析平台通常部署在计算中心,向组织内部提供计算服务,其访问认证的形式应当能够与组织内部现有账户信息做到无缝对接和集成. LDAP是轻量目录访问协议(Lightweight Directory Access Protocol)的缩写,是从X.500目录访问协议的基础上发展而来,是一种集中账号管理架构的实现协议.LDAP通常应用于组织内部的账户密码管理[13],构建集中的身份验证系统,可以降低管理成本,增强安全性.
Jupyter Hub中访问认证功能可通过插件的方式配置LDAP访问认证功能,与组织内部现有用户访问认证体系完整集成. 这种方式对于大型科研机构、高校等组织,可以显著降低用户管理和安全运维成本.
3.2.2 持久化存储
Kubernetes持久化存储通过API资源管理,包括PersistentVolume和PersistentVolumeClaim. Kubernetes中的存储组件支持NFS、EBS等多种后端存储,存储具有独立于Pod的生命周期. NFS (Network File System)作为FreeBSD支持的网络文件系统,NFS节点之间通过TCP/IP协议访问,NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,跟本地文件访问相同.
Jupyter Hub配置Kubernetes中使用NFS,文件系统将被挂载在Pod中. NFS允许多个Pod同时进行写操作,这些Pod使用相同的PersistentVolumeClaim. 通过使用NFS卷,相同的数据可以在多个Pod之间共享.
3.2.3 用户资源分配
Jupyter Hub用户资源分配内容一般包括了CPU、内存和存储,对于高性能计算还需要重点关注GPU资源的分配. CPU、内存和存储等资源可以直接在Kubernetes中弹性配置,对于GPU资源需要通过驱动挂载的方式,将宿主机上的GPU资源提供给容器使用. Jupyter Hub的资源定制化配置能力,关系到满足不同用户群体的不同层次需求,以及用户体验的改进. 用户资源分配主要有两种方式:资源保证(resource guarantees)和资源限制(resource limits).
资源保证的方式是确保所有用户在任何情况下至少可以使用的资源量,如果有多余的资源仍然可以在加配. 例如,如果一个用户得到了1 GB内存的资源保证,如果系统存在闲置多余的内存资源,此用户可以分配到高于1 GB的内存量.
资源限制的方式设置了用户可用资源的上限,如果一个用户只给了1 GB内存的资源限制,那么此用户在任何时间、任何系统资源富余的情况下,都不能使用超过1 GB内存的资源量.
3.3 集群资源调度
资源调度是Jupyter Hub充分利用计算集群资源和具备面向多用户开放的关键. Kubernetes内置了默认的调度规则为Pod分配运行主机,并且开放自定义编写调度算法. 调度规则区分为预选(predicates)和优选(priorities)两个阶段规则. 系统首先通过预选初步排除不符合Pod运行要求的主机,然后再对预选后的主机进行量化评分,分值高低代表主机状态优劣,最后将分值最高的主机调度为Pod的运行主机.
3.3.1 预选规则与节点筛选
预选规则是在集群节点中排除不满足基本运行条件主机的规则集,Kubernetes集群排除不符合预定条件的节点. Kubernetes 默认预选规则集见表1.
定义Kubernetes集群的工作节点集合为:
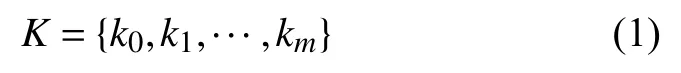
预选算法的规则集合为:
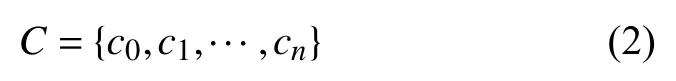
定义规则的运算结果:

当节点不满足预选算法规则集合中的任一规则,则节点被筛选掉,最终通过预选规则过滤得到的集合为:
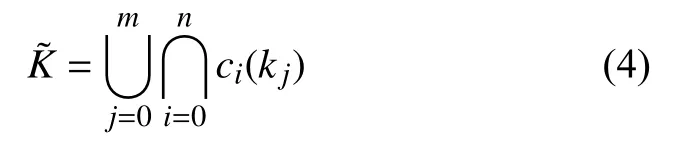

表1 Kubernetes默认预选规则集
3.3.2 优选算法与节点评分
在筛选出符合基本要求的候选节点后,通过优选算法的节点评分决定Pod容器具体调度运行的集群宿主机. 优选算法通过不同的评分函数以及其权重,得出候选节点的综合分值为评分函数加权求和,最后根据得分情况,将容器运行在最佳节点上.其中,s(k)为优选算法的节点综合评分; wi为权重系数,权重系数一般为均匀等比例分配,也可以由用户根据主观情况进行自定义分配调整,pj(k)为评分函数.
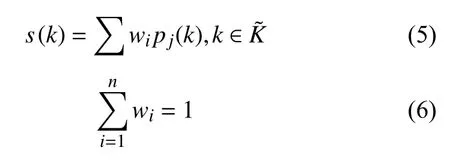
Kubernetes中默认内置了几种典型评分函数:
(1) LeastRequestedPriority,当新的Pod被调度到节点上,节点的优先级取决于节点空闲资源与节点总容量的比值,比值越高的节点得分越高,CPU和内存的权重相同,具有参照资源消耗跨节点调度Pod的作用.
(2) BalancedResourceAllocation,尝试分析部署Pod后集群节点的CPU和内存利用率,以达到集群均衡状态为目标,可以避免出现CPU、内存负载不均衡的情况.
(3) SelectorSpreadPriority,主要针对多实例的场景下使用,将优先级交给运行Pod实例数量少的节点.
4 性能测试
为了对比Jupyter“微服务化”分布式架构改进性能,将Jupyter单体服务架构应用与基于Kubernetes集群架构的两种不同部署方式进行测试,测试内容包括了两个部分:并发访问负载测试、Pod运行数量负载均衡测试. 其中,访问负载测试的是为了对比两种架构方式下后台服务的响应能力; Pod运行数量负载均衡测试是通过观察集群中Pod运行数量变化与节点计算资源使用率间的变化关系,分析验证集群计算资源调度分配的有效性.
4.1 测试条件
本文研究重点关注资源调度和横向扩容测试,为了方便实验,可以控制测试节点规模,本实验中搭建了3个节点(节点配置如表2所示)的Kubernetes集群,其中1个master集群控制节点、2个Node工作节点.

表2 节点配置
4.2 访问负载测试
Apache Bench (AB)是一种简单有效的压力负载测试工具包,通常用于对服务器的HTTP请求性能测试. 本研究通过AB工具分别对基于Kubernetes微服务架构和单体架构的Jupyter负载能力进行测试,测试模拟100个用户共20 000次服务请求的响应情况,测试结果主要关注“平均响应时间(time per request)”[13,14]指标,其计算公式如下:
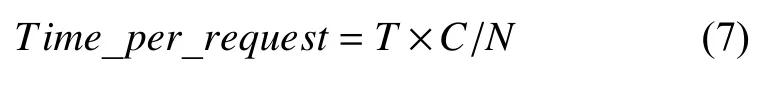
其中,T代表请求测试花费的总时间,N代表总请求数量,C代表并发用户数.
如图6测试结果数据统计分析表明,在相同的访问量和用户数条件下,在访问请求总数的各个百分比分位点上,基于微服务架构的Jupyter在“平均响应时间”指标上优于单体架构.
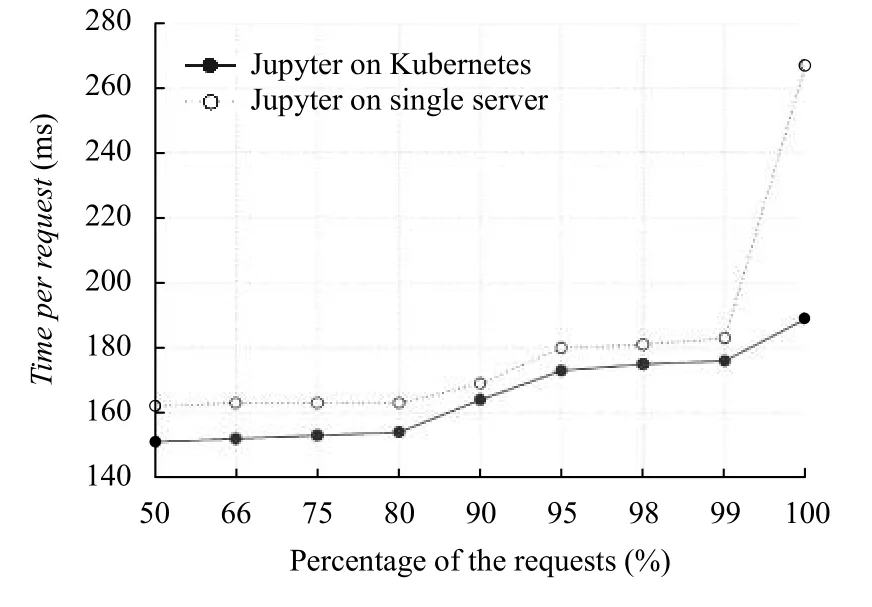
图6 访问负载测试结果数据统计分析
4.3 Pod运行数量负载均衡测试
基于Kubernetes分布式微服务架构的Jupyter,通过为不同的用户启动独立的Pod提供Notebook服务,其Pod运行数量即代表用户运行数量. Pod运行数量负载均衡测试模拟随着用户运行数量增加,集群节点的资源使用率变化情况,主要关注“内存使用率(Memory Usage)”和“CPU使用率(CPU Usage)”两个指标,计算公式见式(8)和式(9):
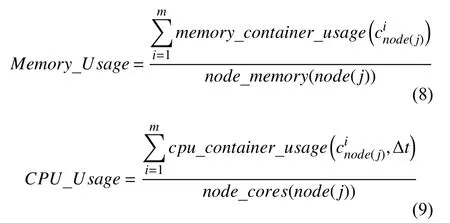
其中,假设集群节点node(j)共计运行m 个容器实例,代表节点node(j)序号为i的容器实例,memory_container_usage[15]为节点某个容器内存使用率,cpu_container_usage[15]为节点某个容器在Δt时间间隔内的CPU使用率,node_memory为某节点总计内存资源量,node_cores为某节点CPU计算资源总量.
如图7所示测试结果数据分析表明,随着用户数量的增加,集群不同节点的资源使用率呈现总体同步提高的变化趋势,证明了计算资源的负载被均衡分配到集群各个宿主节点上. 通过资源分配算法,Kubernetes在集群上启动Pod单元时,优先考虑宿主机的剩余计算资源,将负载优先分配到计算资源、环境条件相对优越的节点上,从而实现了在整个集群上的负载均衡.
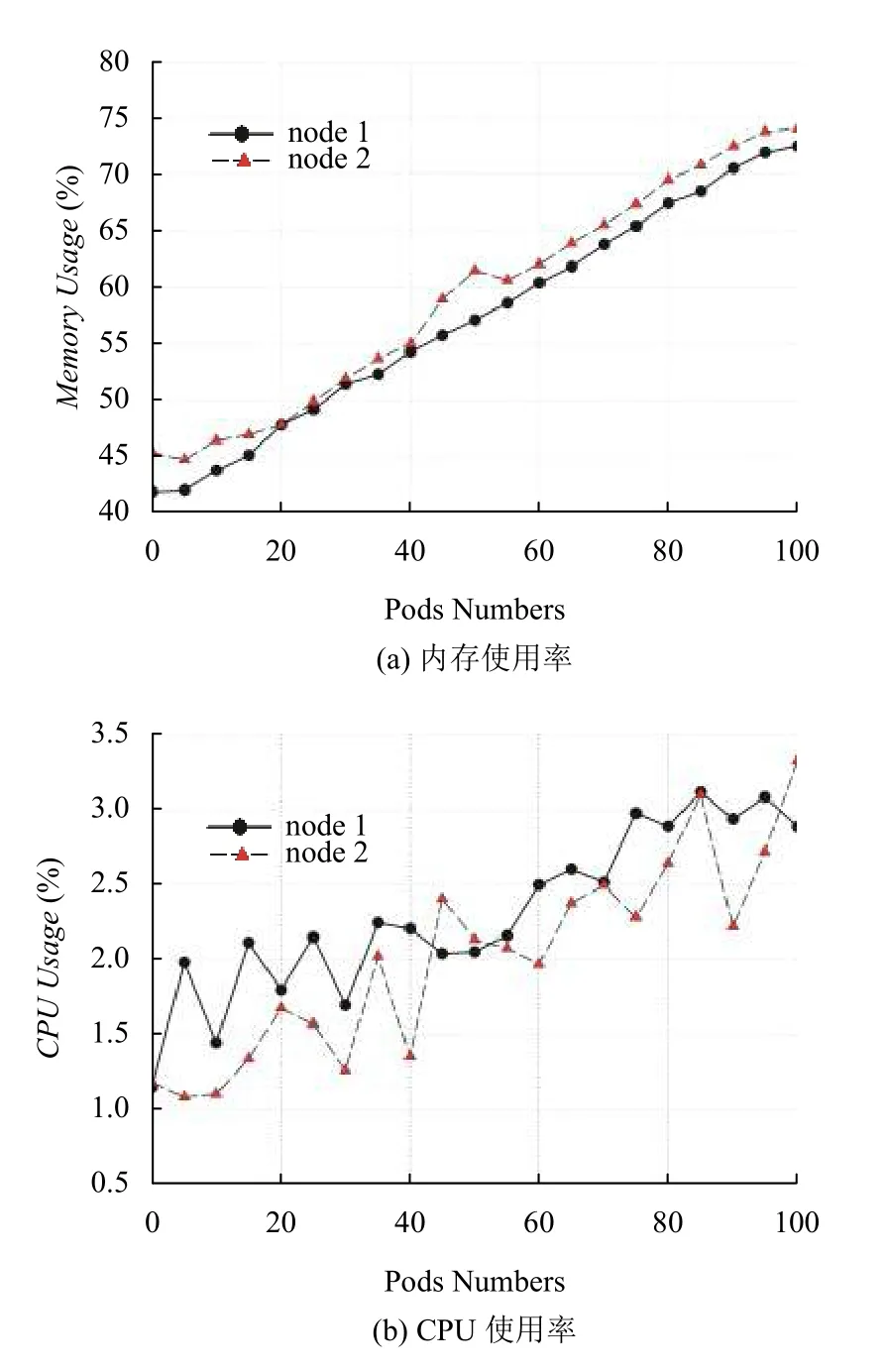
图7 Pod运行负载测试结果数据分析,node1、node2为测试集群中的两个计算节点,为Pod的运行宿主机.
5 结语
Jupyter作为集合了代码运行、数据分析、论文编写等功能为一体的优秀平台工具,逐渐走向大型计算中心的后端,向着基于容器技术的分布式微服务架构方向演进. 本文研究通过对Jupyter的微服务化重构,并结合Kubernetes资源调度分配算法,实现了在计算集群上多用户资源需求的负载均衡,能够充分优化利用计算中心的集群资源[16],具备了横向动态扩容的能力,为用户提供更为便捷、高效的计算资源访问方式.在下一步的研究中,将重点关注面向HPC高性能计算的Jupyter分布式并行架构,以优化计算资源利用率为主要目标[17],并融合主流大数据存储计算框架,为计算中心和用户构建易于管理操作的交互式分析计算平台.
