基于字符树结构的高性能中文词库技术①
2019-08-22杨光豹杨丰赫郑慧锦
杨光豹, 杨丰赫, 郑慧锦
1(浙江广播电视大学 青田学院,青田 323900)
2(东南大学 网络空间安全学院,南京 211189)
3(浙江青田县职业技术学校,青田 323900)
引言
利用大数据技术处理海量中文信息是当今很成熟的技术,而中文分词作为中文信息处理的基础,它是大数据处理中文信息的基础. 而中文分词的性能与准确度一直是相互制约的. 业内对该技术的研究一直在性能与精确度两个方向在推进. 中文分词方法的研究从大的方向来讲,大体分为两大类:(1) 基于词库的字典的机械分词法. (2) 采用统计学理论的统计分词法. 比如文献[1]是使用人工制作的分词语料进行特征信息学习的机器学习分词法. 文献[2,3]是通过双向LSTM神经网络模型进行分词. 文献[4]利用上下文词长特征作为分词特征,从上下文信息中获取信息进行分词,这些都属于统计分词法. 这类分词法在对未登录词与歧义词的处理上占优势,但性能上不及机械法. 一种好的分词技术往往都是采用综合方法,以机械分词为基础,再融入统计法以提高分词精确度. 例如文献[5]利用统计学上的概率,引入层次分析法将多种切分法优劣排序,帮助选择最优排序法,它在一定程序上提高了准确率.在机械分词中,为了提高性能,文献[6]提出了前四字hash索引树技术. 文献[7]提出了首字hash查询的方法,文献[8,9]提出了双字hash法; 文献[10]提出了对四字hash索引的trie树进行改进,文献[11]提出了利用首字hash法进行正向与逆向的多方案分词的选择以减少分词的歧义. 而文献[12]却提出了首字拼音首字母表. 目前为止,基于词库的中文分词都有一个共同特点就是词库结构都是:索引+余词表. 在索引上采用各自认为速度快,占用内存小的方式来进行查询. 目前业内普遍认为采用前4字trie索引树法的分词技术性能最好. 而本文在实际编程中发现,利用字符树结构的分词技术能更好地进行中文分词,无论从时间复杂度还是空间复杂度,字符树分词技术都更胜于其它各种词库技术,它能进一步改善大数据处理中文信息的性能.
1 字符树分词原理
1.1 单字符树原理
单字符树是在各个节点上都保存单个字符的树.将词库文件加载到内存时,所有的词都将先被分割成一个个的单字,然后逐个“挂接”在一棵树上. 一个词的所有字加载完后在最后一个字节点上作词串标记,然后加载第二个词的各个字,如果这棵字符树上该位置已经存在要加载的字,则视为已加载(不覆盖),但如果是词的最后一个字符,则要对它的词串标记进行修改.整棵树的构造如图1所示.
单字符树的各个节点都采用同样的数据结构,每个节点中都有一个词串标记isword,如果其值为true则表示从根到该节点为止的路径构成一个词,否则仅仅是词的中间节点. 其数据结构如图2所示.

图1 单字符树词库构造举例

图2 单字符树词库节点数据结构
查询一个词只需要从根节点开始,例如查询“中国”这个词,只需要从根节点开始先找“中”,找到后再在“中”的子节点中找“国”找到后再看这个“国”的节点中的词串标记是否是true,如果是true,则说明词库中存在“中国”. 否则就不存在. 这样构造起来的字符树最大的好处是不会出现无效查询,当查询词库中存在的词,比如想查询“千方百计”,它从树根逐级查询会有一条路径存在,最后依据路径末端节点的词串标记来判断.查询词库中不存在的字符串时,要么路径不存在,要么路径末端节点的标记是false.
1.2 多字符树原理
多字符树是从单字符树演变过来的一种变异树.它的设计思路与单字符树类同. 只是为了减少节点数,把字符树中出度为1,词串标记为false 的节点字符连在一起放在一个节点上,直到节点出度大于1或标记位为true为止,但它的查询思路与单字符树是一样的,都是从树根开始向各个分支逐级查询,加载时相同的前缀也只加载一份.
多字符树的构造过程是这样的:例如“ABCDEF”是一个词,开始加载这个词时,将它作为整体挂在根节点的一级子节点上,此时如果加载第二个词“ABCMN”,由于有共同的前缀“ABC”,于是将原来的节点“ABCDEF”进行“裂变”,产生共同前缀的节点为父节点“ABC”,子节点为“DEF”,然后再把要插入的“ABCMN”这个词的共同前缀去掉,剩下的字符构成一个节点“MN”,并把它挂在“ABC”节点下的子节点数组中. 此时如果要加载ABC这个词,则只需要将“ABC”节点的标记位设为true即可. 而没有共同前缀的词都挂在根节点的一级子节点上,依此类推将所有词库文件中的词加载到这棵树上. 整棵树的构造如图3所示,节点数据结构如图4所示.
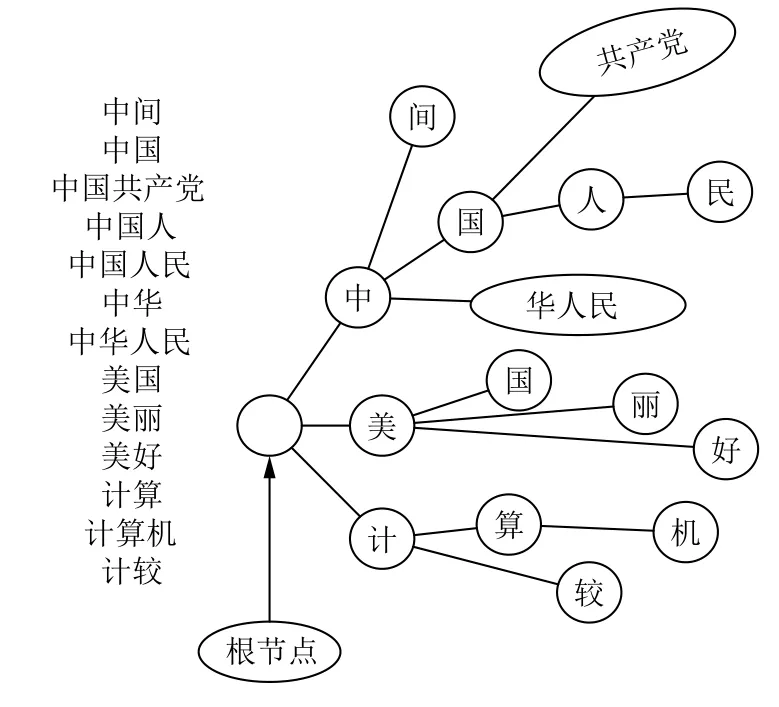
图3 多字符树词库构造举例

图4 多字符树词库节点数据结构
多字符树结构的词库节点总数比单字符树少,但它的查询过程与单字符树相同,需要逐个比较字符,所以它的查询性能与单字符树是相同的. 它总节点数少是否意味着内存占用少呢? 事实并非如此. 本实验词库加载成多字符树时,节点总数是291 893个,约是单字符树的节点数目的3/4; 它平均每个节点大约拥有1个词,但因为多字符树中的每个节点保存的字符数目是不确定的,所以它不能全部直接存储在节点上,只能将节点字符串中第一个字符保存在节点上,而多出的字符只能以数组的形式用指针“挂”在节点上,这样以来,每个节点必须要多出一个指针字段进行挂接字符串,而且多出的字符需另外申请空间来存放,这将在内存占用上比单字符树要大得多,后文实验数据会证明这一点.
2 各词库查询性能分析
无论是单字符树还是多字符树,它们都不是索引树. 因为它们没有所谓的“余词正文”,所有的词都已经在这棵树上,它只是把词库的存储方式从“表”变成“树”,它不需要索引.
为了比较整词法,trie索引树法以及单字符树与多字符树等在词库成功查询上的性能区别,我们采用顺序访问的平均访问长度作为衡量各种词库性能的指标,以此比较它们在查询性能上的优劣.
2.1 字符树词库查询长度统计分析
由于单字符树与多字符树在查询原理上相同,所以查询性能相同,在性能比较时以单字符树为代表参与. 之所以引用两种结构的字符树是为了研究它们占用的内存区别.
单字符树词库构造完成后各节点的统计数据如表1所示. 本实验词库中最长的词是16个字,所以单字符树的最大层次是16,每一层的节点中如果有孩子,它会派生出下一层的子节点,它将作为下一层节点的父节点统计,而没有孩子的节点不作为下一层节点的父节点统计,节点平均访问长度是指从父节点到本节点需要的平均访问次数,词串的访问长度是指一个词各节点的访问长度之和,而词串平均访问长度是指同一长度的词串的访问长度的平均值. 由表1可知,字符树中各词串的平均访问长度是3371,其主要由一级节点数量 (常用汉字数量) 决定. 它的词库查询时间复杂度为O(1)
2.2 trie索引树词库查询长度统计分析
trie索引树结构以索引字数分为四类:前1字trie索引树trie1,前2字trie索引树trie2,前3字trie索引树trie3,前4字trie索引树trie4. 它们前n字(n为1,2,3,4)与字符树结构相同,但字数长度超过n的词,其剩余部分全部存在同一张“余词表”中,所以将余词表视为同一层次的节点,以trie4为例,其平均访问长度统计如表2所示. 各类trie索引树的平均访问长度统计方法与表2相同,限于篇幅,在此不再一一举出.
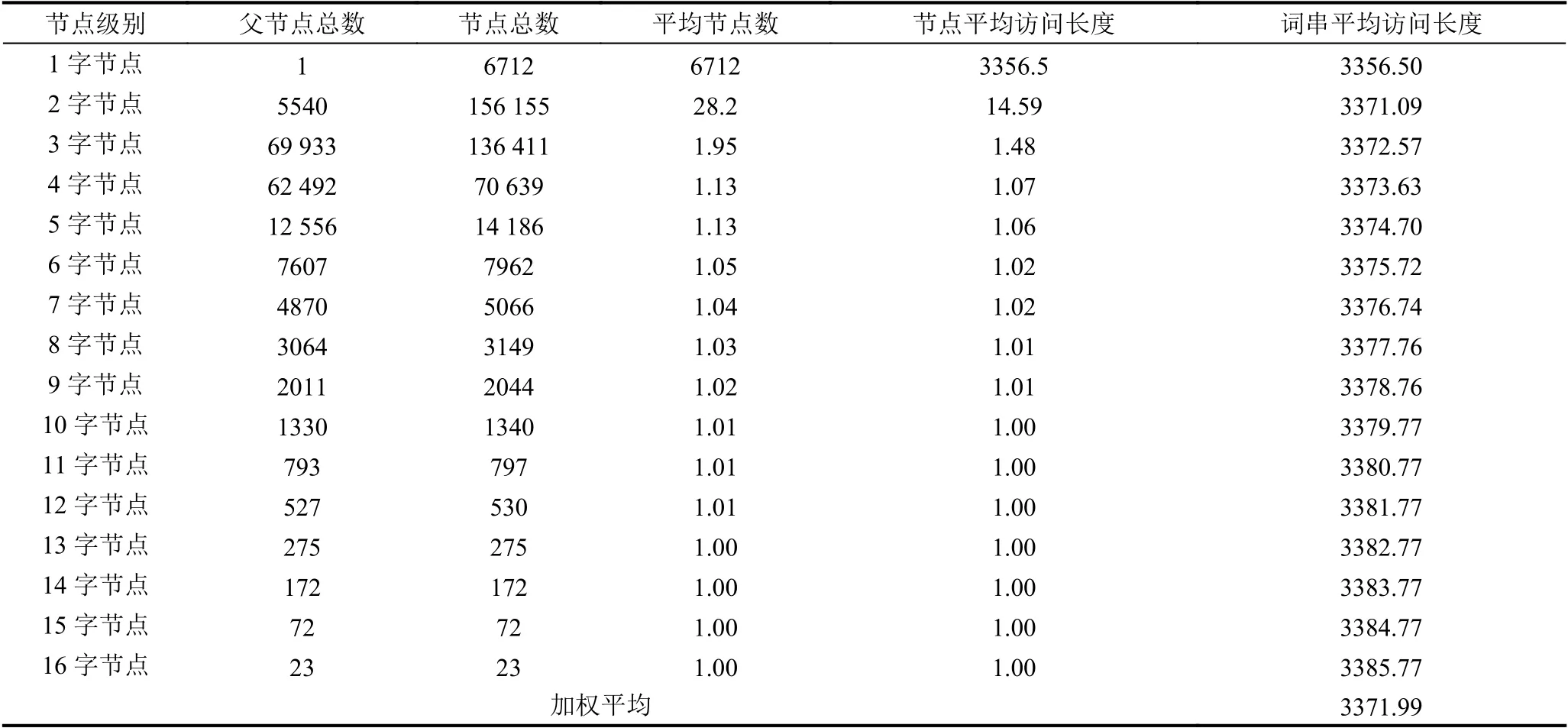
表1 单字符树词库平均访问长度统计表

表2 前四字trie树词库平均访问长度统计表
2.3 整词词库查询长度分析
整词词库的平均访问长度直接受词库总词条数量影响,假设词库总词条数量为n,则它在顺序查询时,成功查询的平均访问长度为n/2,失败查询长度为n. 所以它的词库查询的时间复杂度为O(n). 它的性能会随着词库的增大而变慢. 本实验词库中它的平均访问次数是139 548次,是字符树平均访问次数的41倍. 随着词库条目的增大,两者性能差距将越来越大.
2.4 各类词库查询性能对比
现将本实验词条集构成的字符树词库、各类trie索引树词库以及整词词库的平均访问长度与余词数量统计在表3中.
由表3可知,平均访问长度是字符树最短,它的平均访问长度接近于一个常数(常用汉字数6712的一半),整词词库最长,它接近于词库总数的一半,而trie索引树则介于两者之间,对前n字的trie索引树来说,n越大,级数分的越多,余词数越少,它的平均访问长度就越短,trie索引树就会向单字符树演变; 当n越小,它的级数越少,余词表越大,它的平均访问长度就越长,于是它将向整词词库演变. 所以字符树词库与整词词库是trie索引树词库的两个极端,前者词库内查询时间复杂度为O(1),它不随词库规模增大而增大; 而后者词库内查询时间复杂度为O(m),它随词库的规模(词条总数为m)增大而增大; 而trie索引树性能在这两者之间,当词库增大时,随着余词数量增大,其性能就会降低,尤其在大规模词库中,trie索引树词库的余词大量存在,余词表对性能影响将上升为主要矛盾. 而字符树词库的查询词条的时间复杂度为O(1),它不受词库总条数影响,且不存在余词表,所以在大规模词库中将会突显它的优势.
3 字符树在扫瞄算法上的优势
基于词库的中文分词是建立在“最大匹配算法”的思想上,要从待分词的字符串中找出尽可能字数多的词,分词时提取的词长度越长越好,分词结果中词的个数越少越好.
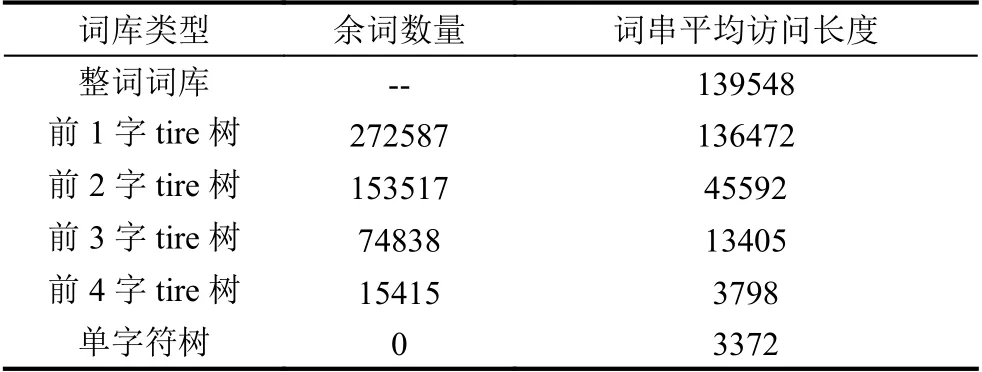
表3 各类词库平均访问长度统计表
3.1 整词词库分词扫瞄的缺陷
传统整词法存在大量的无效查询,效率低下. 比如要找出字符串“ABCDEFGHIJKLM”中最长的词. 如果词库中最长词的长度是10个,则它必须先取长度是10的字符串A-J与词库中词比较,查找是否有相同的,如果有则提取该字符串,如果没有,则第二次取长度为9的字符串A-I来比较,依此类推,逐一缩短字符串长度进行查询. 在最坏的情况下,10次查询有9次无效的,它的分词时间复杂度为O(n×m),(n为待分词总字符数,m为词库最长字符数).
3.2 Trie索引树分词扫瞄的缺陷
Trie索引树能够将词长度小于树深度的词快速找到并确定,消除了它们的无效查询问题. 所以对于词长度小于树深度的词,它的时间复杂度与字符树相同. 然而,对于词长度大于或等于树的深度时,依然与传统方法一样,存在无效查询的问题,比如上例字符串中如果ABCD是一个词,它从首字,次字,三字,四字都找到了,此时它却无法确定ABCD就是最长的词,因为最长的词有可能是ABCDE,也有可能是,ABCDEF…甚至是更长的字符串. 它既然无法确定ABCD是最长的词,就只能逐个去查询对比才能确定最长的词. 所以它的性能只是介于两者之间.
3.3 基于字符树的分词扫瞄算法时间复杂度
基于字符树的分词扫瞄能够完全消除无效查询问题. 无论要处理的字符串是多少长,它从字符串首字开始逐字与字符树对比,一旦发现字符树的路径已经是“尽头”了,则查询结束,然后提取现有的最长的词. 它的时间复杂度取决于待分词字符的总长度,与词库中最长词的长度无关. 所以,它的分词算法的时间复杂度为O(n),(n为待分词总字符数). 采用字符树词库进行分词不仅消除了无效查询问题,而且它对于利用回溯法[13]进行多种分词方案的选择时具有得天独厚的优势.
4 实验结果比较
实验环境:操作系统是Win10,CPU 为Intel®CoreTMi5-6500 CPU @3.20 GHz;内存大小为4 GB. 为了区别各类词库的查询性能与内存占用情况,本文编写了6个词库类,如表4所示,它们分别依次对同一个词库文件进行加载,对同一个文本文件进行分词,查看加载词库所用时间,占用内存,以及分词所花费时间等数据. 内存占用量用加载词库前程序占用总内存与加载词库后程序占用总内存的差作为取值,内存占用信息通过操作系统提供的GetProcessMemoryInfo函数获取. 加载词库所需时间与对文件进行分词所需时间分别是在开始前用clock()函数获取时间,结束后再次用该函数获取时间,用它们的差值作为花费时间,各trie索引树法的散列表的装载因子统一设为0.5. 实验取得数据分析表见表5所示.

表4 各词库类的数据结构及实现技术
4.1 内存占用情况
本文提出的单字符树词库内存占用最小,整词二分法词库最大; 而对trie索引树词库的内存占用情况是级数越多,内存占用却越小. 原因是trie索引树分的级数越多,就会有更多的共同的前缀字符被省略,而“余词”数量也会大幅度减少,所以占用内存会越少. 传统的整词词库占用内存最大,最主要的原因是字符串对象的创建与排序会造成大量的“内存碎片”,从而浪费内存. 而多字符树与单字符树相比,性能接近相同,但内存占用却是多字符树更大,原因是多字符树的每个节点多了一个指向字符数组的指针,而且各节点中除第一个字符保存在节点内,其余的字符都是组合成数组“挂接”在节点上,需要另外的存储空间. 所以它的内存占用会比单字符树大得多.
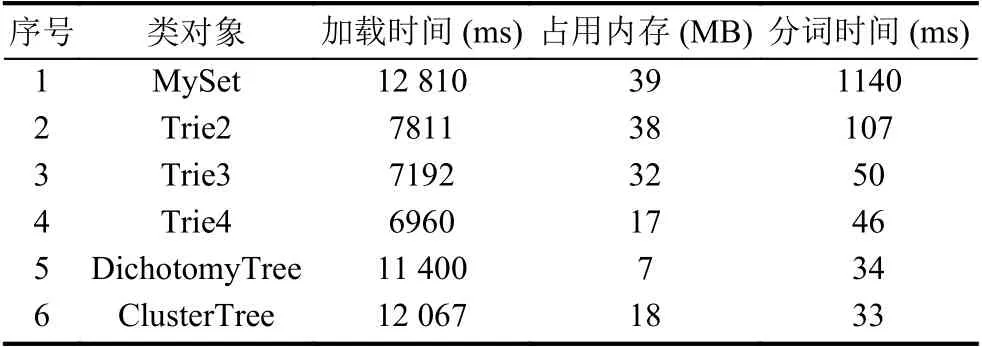
表5 实验数据统计表
通过软件采集实验所用的词库文件获得词库总条数为279 095,总字符数为:821 105. 平均每个词含字符数为2.94个. 而加载成单字符树后产生的节点数为405 534,相当于词库中的一半字符可以省略,平均一个词仅占1.45个节点数. 单字符树一方面省略了共同前缀的字符; 另一方面,也是更重要的是由于它的节点数据结构单一,大小一致,在构造字符树完成后可以将所有字符节点从“分散”状态“收集”到一张线性表中,释放掉原来的所有节点. 这一过程会释放大量的“内存空闲碎片”,从而减少内存占用. 它的内存占用只有整词词库MySet的占用内存的1/5.5.
4.2 分词性能比较
分词速度最快的是本文提出的字符树分词法,其次是trie索引树分词法,最差是整词二分法. 字符树的分词速度大约是整词折半法的35倍. 而对于trie索引树词库的性能情况是级数越多,分词速度越快.
原因分析:字符树消除了分词过程中的无效查询的问题,它同时在扫瞄算法与词库查询两个方面都具有最突出的优越性,所以总体分词速度是最快的. 整词分词法由于在扫瞄算法上存在大量的无效查询,而它的词库查询时间复杂度又是最高的,所以它的分词速度最慢. 而trie索引树可以部分消除无效查询,同时它的词库查询访问性能是介于字符树与整词法之间,所以它的分词性能也处于两者之间. 另一方面,不同级数的trie树性能也不同,trie索引树级数越多,也就是深度越深,它的分词性能越好,越接近字符树,而级数越少,则其性能越差,越接近整词分词法.
总之trie索引树的分词性能是介于单字符树与整词法两者之间,当它的级数增大则向字符树方向演变,当它级数减少则向整词词库方法演变,整词法与字符树法是trie树的两个极端情况.
5 结束语
本文从基于词库的中文分词思想出发,对现有分词技术进行分析对比,提出字符树的分词技术,解决了中文分词中的无效查询问题. 首先它改进了词库查询方式与分词扫瞄方式,大大减少了运算的复杂度,减少运算量,尤其在大规模词库中显示出具有的巨大优势;其次,单字符树词库占用内存小,大大降低了程序的空间复杂度. 无论在时间复杂度还是空间复杂度,单字符树都是一种占据绝对优势的,在大数据处理中文信息时值得推广的中文分词技术.
