基于迁移学习的类别级物体识别与检测研究与进展
2019-08-21张雪松庄严闫飞王伟
张雪松 庄严 闫飞 王伟
计算机视觉是一个多学科交叉的领域,主要研究如何从静态图像或者视频流中自动地提取、分析和理解其中的有用信息[1].图像数据可以使用不同类型的传感器采集,其表现形式也是多种多样的,例如不同分辨率的彩色图片、灰度图片、深度图片和三维激光点云等.物体识别与检测属于计算机视觉领域的一个基础性问题,主要任务是在静态图像或视频流中识别及定位出其中感兴趣的物体.物体识别通常要求对于任意给定的图像能够正确地对其中包含物体的语义类别进行类标签预测,而物体检测则还要求将图像中的物体准确地定位出来.而且,物体检测对于定位的精确度要求也不一样,可以用矩形框将图像中的物体框选出来,也可以将物体从图像中分割出来,后者称为像素级物体检测[2].
物体识别可以分为实例级物体识别和类别级物体识别两种主要类型[3].对于实例级物体识别,其主要任务是在图片或视频中找到某个特定的物体,例如在一张含有多个行人的图片中找出航天员杨利伟.实例级物体识别的难度主要在于感兴趣的特定物体通常被其他物体所遮挡,而且其姿态和尺度是变化的.目前,实例级物体识别所采用的方法主要是从图像中提取角点、线、轮廓或者表观特征,然后采用匹配和几何配准等方式和目标物体进行对比,根据匹配程度找出图像中的目标物体[3].到目前为止,实例级物体识别的研究已经趋于成熟,其中比较有代表性的工作是提取SIFT[4−5]、SURF[6]或深度DeCAF[7]特征,然后基于树或哈希算法[8]以及几何验证[9]等方法进行特征匹配.
类别级物体识别的主要任务是判断给定的图像或视频中是否存在属于某一语义类别的物体实例,例如判断一张图片中是否有椅子类别的物体存在.由于在不同拍摄视角、光线条件和嘈杂场景的图像中,属于同一类别的不同物体可能存在较大程度的类内变化,这就给对物体类别进行数学建模带来了很大的挑战.此外,物体类别的定义本身属于语义层面的概念,往往存在一词多义的现象,比如,多个形状和表观特征完全不同的物体都可以被人们叫做椅子.类别级物体检测是比类别级物体识别更加严格的任务,它不仅要求计算机能够判断出给定的图像数据中是否含有某些类别的物体,而且还要能够准确定位出属于同一类别的物体的位置.由于类别级物体识别与检测任务是紧密相关的,因此其采用的方法也是相辅相成的.
为了能够对物体类别进行数学建模,研究人员通常需要采集大量的图像数据,然后对这些图像数据按照语义类别进行分类和手工标注.虽然近年来不断地有各种研究机构推出自己采集和手工标注的数据集[10−11],但是研究人员发现大量数据集都存在有偏向性[12−13]的问题.举例来说,将SUN2012数据集[11]训练出来的分类器在Caltech256数据集[14]上进行测试,其分类准确率将会有大幅度的下降.在移动机器人应用中,机器人使用异构传感器采集到的图像数据在表现形式和特征分布上差异更大,例如用摄像头采集的彩色图像和用三维激光测距仪采集的三维点云在表现形式上就完全不同.因此,使用不同传感器采集的同一物体类别的图像数据的特征分布差异十分显著,这就使得利用单一传感器采集的数据训练出来的分类器只能够适用于本领域内的物体识别与检测任务.由于三维激光测距仪和雷达等可采集深度信息的传感器的造价比较昂贵且采集过程比较复杂,因此三维点云数据集的规模及其所包含的物体类别数目相对于大规模Web图片数据集而言小很多.当采用有监督或者半监督学习方式进行物体检测时,分类器训练过程中使用的少量正样本通常来自训练图片中标注的矩形框或者多边形,而大量的负样本往往直接从背景区域提取,正负训练样本数量的绝对不平衡导致训练出的分类器模型带有偏向性且易于过拟合.
在基于小规模数据集的类别级物体识别与检测应用中,过拟合、类不平衡和跨领域特征分布差异等关键问题与挑战交织在一起.近年来,随着迁移学习理论的发展与成熟,为解决物体识别与检测中的问题与挑战提供了新的思路和解决方案.本文围绕迁移学习理论如何应用于类别级物体识别与检测展开论述,以问题驱动的方式对迁移学习理论在物体识别与检测中的应用研究工作进行综述.章节安排如下:第1节对迁移学习理论和类别级物体识别与检测的研究现状进行了归纳和梳理;第2节对迁移学习如何解决类不平衡问题进行论述;第3节对迁移学习如何解决跨领域特征分布差异进行介绍;第4节对迁移学习如何解决过拟合问题进行了讨论;第5节对研究重点和技术发展趋势进行说明.最后,对该研究方向进行总结.
1 迁移学习理论和类别级物体识别与检测的研究现状
1.1 迁移学习理论研究现状
在机器学习领域,传统的机器学习方法通常局限于解决单一领域内的问题,即要求训练数据和测试数据都服从相同的分布.当训练数据和测试数据的特征分布不同时,往往需要在新数据集上重新训练模型.但是,在实际应用中,重新采集数据的成本很高甚至有时难以实现,此时将从源领域中学习到的有用知识迁移到目标领域就变得很有必要.自从1995年迁移学习研究兴起以来,不断有研究人员将传统的机器学习方法扩展到了迁移学习中,其中包括基于核学习的迁移学习[15−17]、基于强化学习的迁移学习[18−19]、基于流形学习的迁移学习[20]和基于深度学习的迁移学习[21]等.
首先,我们给出迁移学习中一些术语的定义[22].
定义1(领域).一个领域可以形式化地表示为

其中,χ表示特征空间,p(X)表示X={x1,x2,···,xn}∈χ,xi∈d,i=1,2,···,n的边缘分布.
定义2(任务).给定某一个具体的领域D={χ,p(X)},一个任务可以形式化地表示为

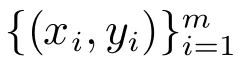
Pan等[22]将迁移学习形式化地定义为:“给定一个源领域Ds和源任务Γs,一个目标领域Dt和目标任务Γt,迁移学习使用Ds和Γs中已有的知识去改进Dt中对目标预测函数f(·)的学习,其中Ds6=Dt或者Γs6=Γt”.因此,迁移学习的过程就是将源领域Ds中解决任务Γs时学习到的“有用”知识迁移到目标领域Γt,结合Γt中已有的训练数据为完成任务构造出泛化能力更好的模型,如图1所示.
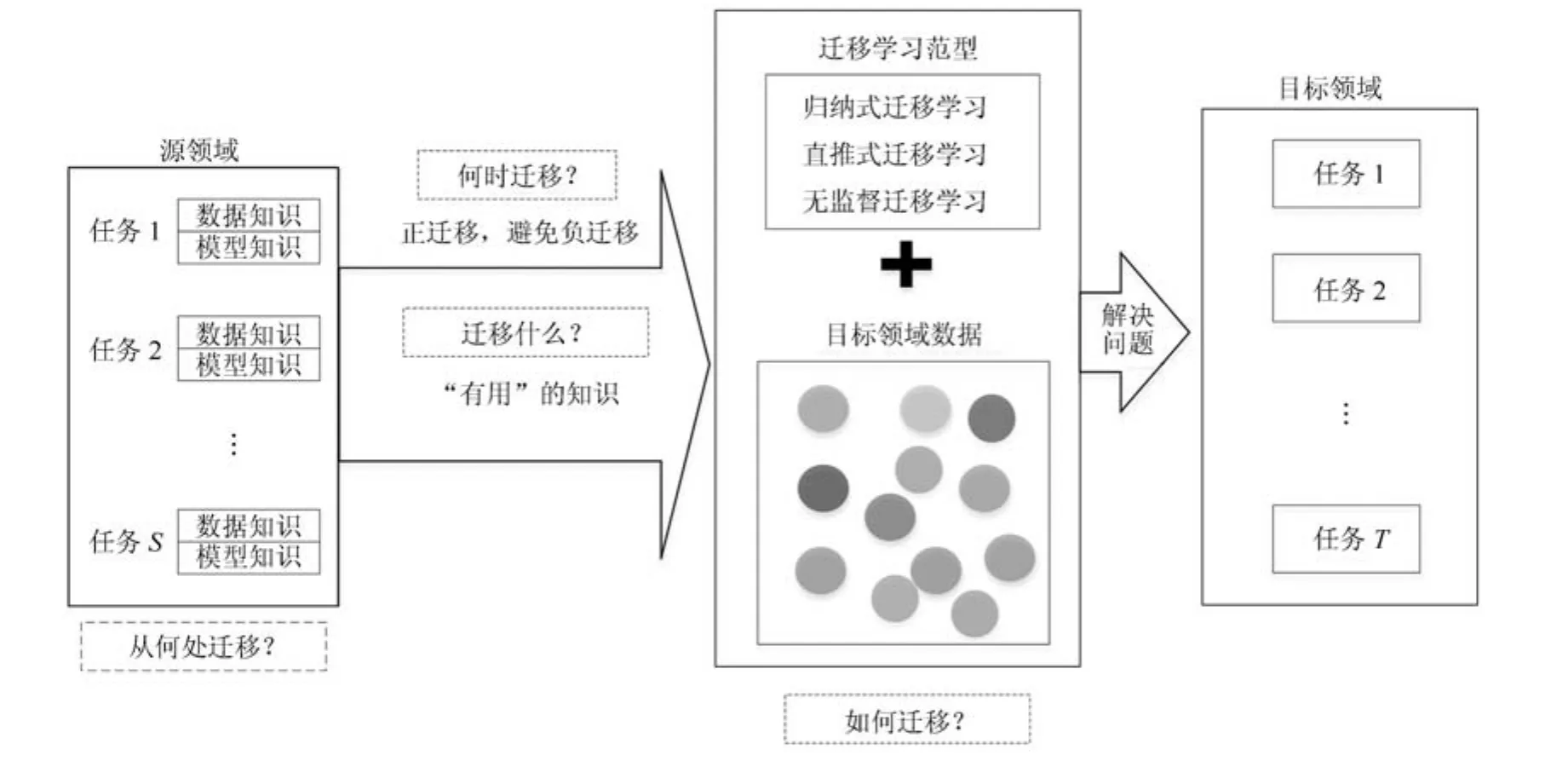
图1 机器学习中迁移学习过程的概念表示Fig.1 Concept illustration of transfer learning process in machine learning
文献[23]中,Aytar将迁移学习过程概括为回答下面的4个主要问题:1)从何处迁移(Where to transfer);2)迁移什么(What to transfer);3)如何迁移(How to transfer);4)何时迁移(When to transfer).
“从何处迁移?”问的是被迁移到目标领域的知识的来源.根据迁移学习的定义,只要在源领域中存在对于完成目标领域任务有用的知识都可以将其迁移到目标领域.值得指出,如果迁移到目标领域的知识来自源领域或目标领域中的多个相关的任务,则属于多任务学习(Multi-task learning)的范畴[24−25].多任务学习和迁移学习是机器学习中两个高度相关的研究领域,多任务学习主要强调多个相关任务的共同学习,即多个模型如何联合地进行训练.除此之外,还可以根据迁移学习中源领域的个数将迁移学习分为单源迁移学习(Single source transfer learning)和多源迁移学习(Multi-source transfer learning)[26−29].
“迁移什么?”问的是源领域的哪些知识可以被迁移到目标领域任务中.由于在源领域的某些知识是局限于某个源任务的,因此只有具有共性的知识才是可能迁移到目标领域的“有用”知识.文献[22]将被迁移的知识类型分为数据级知识和模型级知识两种类型,其中数据级知识主要包括实例、特征表示和关系型知识,模型级知识指的是模型的参数.根据从源领域迁移的知识类型,可以将迁移学习方法分为基于实例的迁移、基于特征表示的迁移、基于参数的迁移和关系型知识的迁移4种主要类型,如表1所示.此外,还可以将多种类型的知识联合迁移到目标领域中,称为混合知识迁移(Hybrid knowledge transfer)[30].例如基于实例和特征的迁移学习、基于特征和参数的迁移学习等.
“如何迁移?” 问的是使用哪种机器学习范型和方法来进行迁移.当给定了源领域中可以迁移的知识类型之后,只要确定了迁移学习的范型就可以根据目标领域任务的特点来设计具体的算法了.由于表1中已经概括了迁移学习的常用方法,这里重点介绍迁移学习的范型.众所周知,传统的机器学习理论中提出过大量的范型.文献[31]根据训练数据的特点和学习目标将其分为有监督学习、无监督学习、半监督学习、归纳式学习、直推式学习和元学习等.因为传统的机器学习范型只涉及单一领域内的学习,所以它们不能被直接运用到迁移学习中来.通过对传统机器学习范型定义的扩展,Pan等[22]最早较为系统地将迁移学习的范型分为归纳式迁移学习(Inductive transfer learning)、直推式迁移学习(Transductive transfer learning)和无监督式迁移学习(Unsupervised transfer learning)三种.概括地讲,归纳式迁移学习和无监督式迁移学习允许源领域任务和目标领域任务不同但是相关,而直推式迁移学习要求源领域任务和目标领域任务相同.值得指出,直推式迁移学习和领域适应(Domain adaptation)的研究内容相似,但是二者存在一定差异.在领域适应研究中,不仅允许部分源领域训练数据有类标签,而且也允许有少量的目标领域训练数据有类标签[32].文献[33]中指出,对于全部目标领域训练数据有类标签的情况,称为有监督领域适应(Supervised domain adaptation),对于仅少量目标领域训练数据有类标签的情况,称为半监督领域适应(Semi-supervised domain adaptation),对于全部目标领域训练数据都没有类标签的情况,称为为无监督领域适应(Unsupervised domain adaptation).综上所述,通过将迁移学习中的三种范型和表1中的迁移学习方法进行交叉组合,就构成了迁移学习的主要研究内容.

表1 迁移学习的不同方法[22]Table 1 Different approaches to transfer learning[22]
“何时迁移?”问的是迁移学习使用的时机.显而易见,迁移学习并不是在任何时候都是有益的,尤其是当源领域和目标领域任务差异显著时,进行迁移学习往往会导致负迁移的发生.例如,将源领域中完成骑自行车任务时学到知识迁移给目标领域中的开汽车任务必然是有害的.虽然如何避免负迁移是一个亟待解决的问题,但是相关的研究仍然较少.文献[34]中提出了一种核方法,可以同时用来评估不同任务的相关性和不同实例的相似性,以此减少负迁移的可能性.Ge等[35]提出了一种两阶段框架,当源领域中存在和目标领域任务完全无关知识的前提下,仍然有效地从多个源领域中迁移“有用”的知识给目标领域任务,避免负迁移的发生.在物体识别与检测等应用中,当源领域/任务和目标领域/任务间的差异十分显著或者目标领域的训练数据充分时,一般不需要迁移学习.
下面以迁移学习方法为主线,对迁移学习理论的研究现状进行概述.
1)基于实例的迁移学习方法
基于实例的迁移方法的主要思想是有选择性地从源领域挑选部分“有用”样本到目标领域,通过扩大目标领域训练样本集的方式提高所训练出模型的泛化能力.由于实例迁移并不进行特征层面的变换,只是直接将源领域的样本“借用”到目标领域,为了防止负迁移的发生,一般要求源领域和目标领域数据的特征分布相似.
表2中归纳和总结了一些典型的基于实例的迁移学习算法,通过对比分析可以看出集成学习、决策树和深度学习等算法已经在基于实例的迁移学习领域进行了一定的扩展性研究,但是针对多实例迁移学习、多源和无监督方式的实例级迁移学习的理论研究仍然较为少见,有待进一步加强.
2)基于特征表示的迁移学习方法
基于特征表示的迁移学习方法的主要思想是学习一种特征变换,利用该特征变换可以将源领域的实例有效地映射到目标领域特征空间,或者将源领域和目标领域的实例映射到一个共同的子空间.“有效映射”的含义是特征变换应该能够减少源领域和目标领域训练数据在特征分布上的差异且不破坏数据的可分性.因此,利用特征变换后的源领域和目标领域样本训练模型实质上相当于通过增加训练数据来提高模型的泛化能力.
表3中归纳和总结了一些基于特征表示的迁移学习方法,通过对比分析可以看出基于无监督或半监督的单源特征迁移学习算法研究较多,多源特征迁移学习的理论研究仍然较少,有待进一步加强.
3)基于参数的迁移学习方法
基于参数的迁移学习方法的主要思想是,如果源领域任务和目标领域任务相似,那么源领域模型中的有些参数有助于学习目标领域模型,将从源领域学到的模型参数作为初始值训练出的目标领域模型要比用随机初始化参数值的方式更有效.
表4中归纳和总结了一些基于参数的迁移学习方法,通过对比分析可以发现早期的参数迁移学习方法主要围绕支持向量机模型进行.近几年,针对深度卷积神经网络、贝叶斯网络和随机森林等模型的参数迁移研究已取得初步的成果.但是,多源的半监督和无监督方式的参数迁移学习理论研究仍然较少,有待进一步加强.
4)关系型知识的迁移学习方法
关系型知识迁移学习的主要思想是将源领域内数据间的关系型知识迁移到目标领域内相似角色的数据间关系中去.只要两个领域中属于同等级数据的角色类似,将源领域中数据间的关系型知识迁移到目标领域同等级数据间关系的学习过程中就是“有益”的.由于迁移的对象是数据间的关系型知识,所以这种迁移方式的源领域和目标领域的数据允许非独立同分布.举例来说,院长在高校中所扮演的角色类似于处长在工厂中扮演的角色,而院长和教师间的关系类似于处长和职员间的关系.因此,只要建立了院长和处长角色的映射以及教师和技术员角色的映射,就可以将高校领域中的院长和教师间的关系知识迁移到工厂领域中处长和技术员间关系的学习过程中.
基于关系型知识的迁移一般适用于使用图建模的网络化数据,例如室内场景环境中物体间的语义关系和社会网络数据间的关系等.文献[36]提出了一个完备的马尔科夫逻辑网络(Markov logic networks,MLN)迁移系统.在MLN中,关系型领域中的实体用谓词表示,而实体间的关系用一阶逻辑表示.该方法首先将源MLN中的谓词映射到目标领域,然后在目标领域中继续修正其映射结构以提高其性能.文献[54]提出了一个方法,可以在目标领域样本极少且存在不连通单元的特殊情况下将源MLN中的谓词映射到目标领域,从而实现关系型知识的迁移.文献[55]中提出了一种基于高阶语义关系型知识迁移的非参数化的语义分割方法,可以将源领域的标注图片中的场景上下文关系型知识迁移给目标领域的未标注图片.
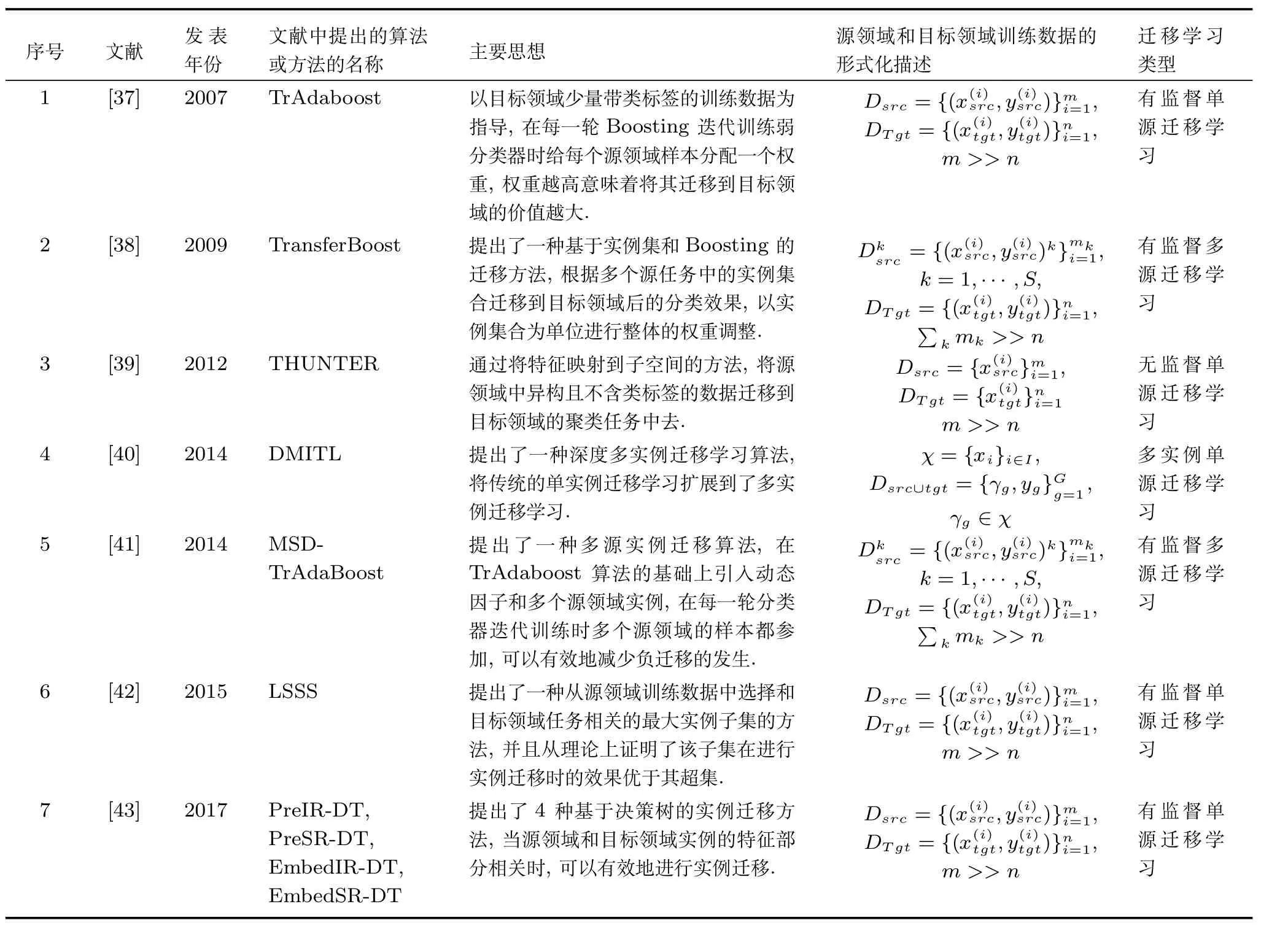
表2 基于实例的迁移学习方法Table 2 Instance based transfer learning methods
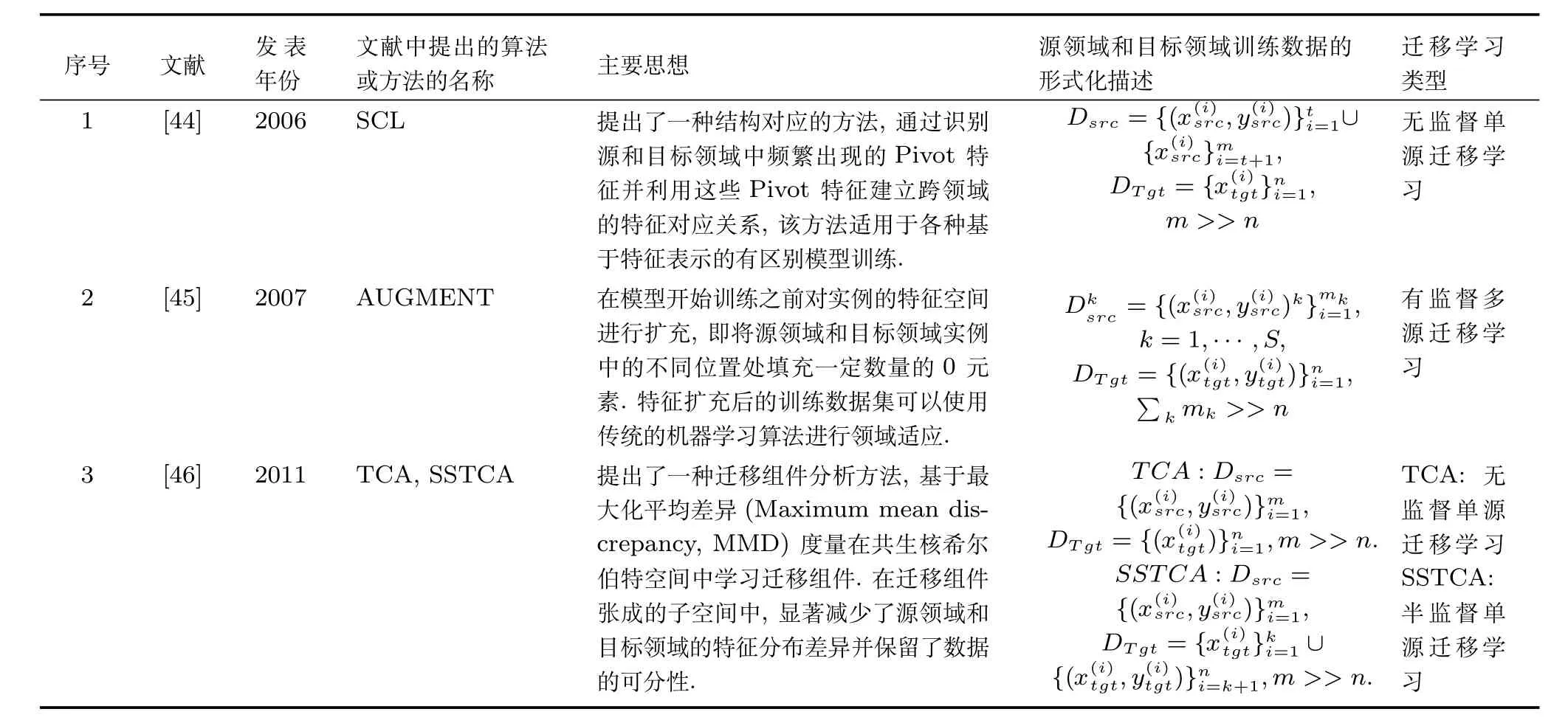
表3 基于特征表示的迁移学习方法Table 3 Feature representation based transfer learning methods

序号 文献 发表年份文献中提出的算法或方法的名称 主要思想 源领域和目标领域训练数据的形式化描述迁移学习类型4 [47] 2015 CoMuT 提出了一种为多个源领域和目标领域寻找共同特征表示的方法,该方法采用半监督的方式将训练数据映射到一个隐空间,利用隐空间建立源领域和目标领域的联系.Dk src={(x(i)src,y(i)src)k}mk i=1,k=1,···,S,DTgt={x(i)tgt}k i=1∪半监督多源迁移学习{(x(i)tgt,y(i)tgt)}n i=k+1,无监督单源迁移学习和多任务学习6 [49] 2017 Autoencoder-Based FTL 5 [48] 2015 TSM 提出了一个异构特征空间映射方法和任务选择方法用于无监督迁移学习.Dk src={x(i)m>>n k}mki=1,k=1,···,S,Dt Tgt={x(i)tgt}nti=1,t=1,···,T基于降噪自动编码、共享隐层自动编码和极限学习机自动编码技术提出了三种特征迁移方法用于语音情感识别任务.Dsrc={(x(i)src,y(i)src)}m i=1,DTgt={(x(i)tgt)}ni=1,m>>n无监督单源迁移学习

表4 基于参数的迁移学习方法Table 4 Parameter based transfer learning methods
5)混合迁移学习方法
混合迁移学习的主要思想是综合地运用上面4种迁移学习方法,进一步提高目标领域模型的学习效果.Xia等[56]提出了一种样本选择(Sample se-lection)和特征集成(Feature ensemble)的方法,联合使用实例迁移和特征迁移来解决源领域和目标领域的边缘概率密度与条件概率密度分布的差异.文献[57]提出了一种混合迁移学习机制,分别使用实例迁移和特征迁移来解决领域特征分布差异的问题.
虽然近年来迁移学习在理论研究上取得了很多的研究成果,但是在物体识别与检测领域应用时仍有很多新的问题需要解决.例如,许多迁移学习理论研究人员提出的算法只是在低维特征空间上进行了验证,而物体类别的特征空间通常都是高维度的.此外,随着深度学习等基于大数据的机器学习算法在计算机视觉领域应用中取得的巨大成功,也给深度迁移学习理论的发展和应用研究带来了新的机遇和挑战.
1.2 类别级物体识别与检测方法研究现状
1)类别级物体识别方法研究现状
在类别级物体识别领域,比较有影响的方法主要包括基于词包(Bag of words,BoW)模型[58]的方法和基于深度卷积神经网络(Convolutional neural network,CNN)模型的方法两大类.文献[59]中对基于词包模型的图像分类方法进行了较为系统的综述,归纳总结了PASCAL VOC竞赛从2005年至2012年的冠军团队使用的方法,指出所有冠军团队的算法都是基于词包模型.2012年被视为类别级物体识别领域的一个重大转折点,主要体现在基于深度CNN模型的方法以较大的优势超越了基于词包模型的方法.近几年,随着深度学习理论在计算机视觉领域的广泛应用,基于大规模数据集和深度CNN模型的方法已成为类别级物体识别与检测研究的主流方向,研究主要集中在CNN体系结构的设计与CNN模型训练过程的优化.
表5对历届ILSVRC(Image Net large scale visual recognition challenge,ILSVRC)竞赛中出现的基于CNN模型的物体识别方法进行归纳总结.通过对比表5中的数据不难看出,2010年和2011年的冠军团队使用的方法是词包模型结合SVM分类器,2012年以后ILSVRC的冠军团队方法都是基于深度CNN模型的,性能的提高主要通过设计新的CNN的体系结构和提出新的模型优化技术.虽然基于大规模数据集和深度CNN模型的物体识别方法取得了很高的分类准确率,但是当训练样本不足时深度CNN模型易于过拟合,而且CNN模型的层次过深时还会出现性能退化问题.另外,在源领域训练得到的深度CNN模型不能直接应用于特征分布不同的目标领域物体识别任务.因此,将迁移学习理论引入类别级物体识别领域,降低深度CNN模型训练对于大规模数据集和高配置硬件资源的依赖,进一步解决跨领域特征分布差异和类分布不平衡等实践中遇到的问题很有现实意义.
2)类别级物体检测方法研究现状
近年来,在类别级物体检测领域,比较有影响的方法可以分为基于滑动窗口的方法和基于深度CNN模型的方法两大类.基于滑动窗口的类别级物体检测方法以可变形部件模型[67]为代表,2013年基于深度CNN模型和选择性搜索(Selective search)技术的R-CNN[68]的框架的出现,使得类别级物体检测进入一个全新的时期.
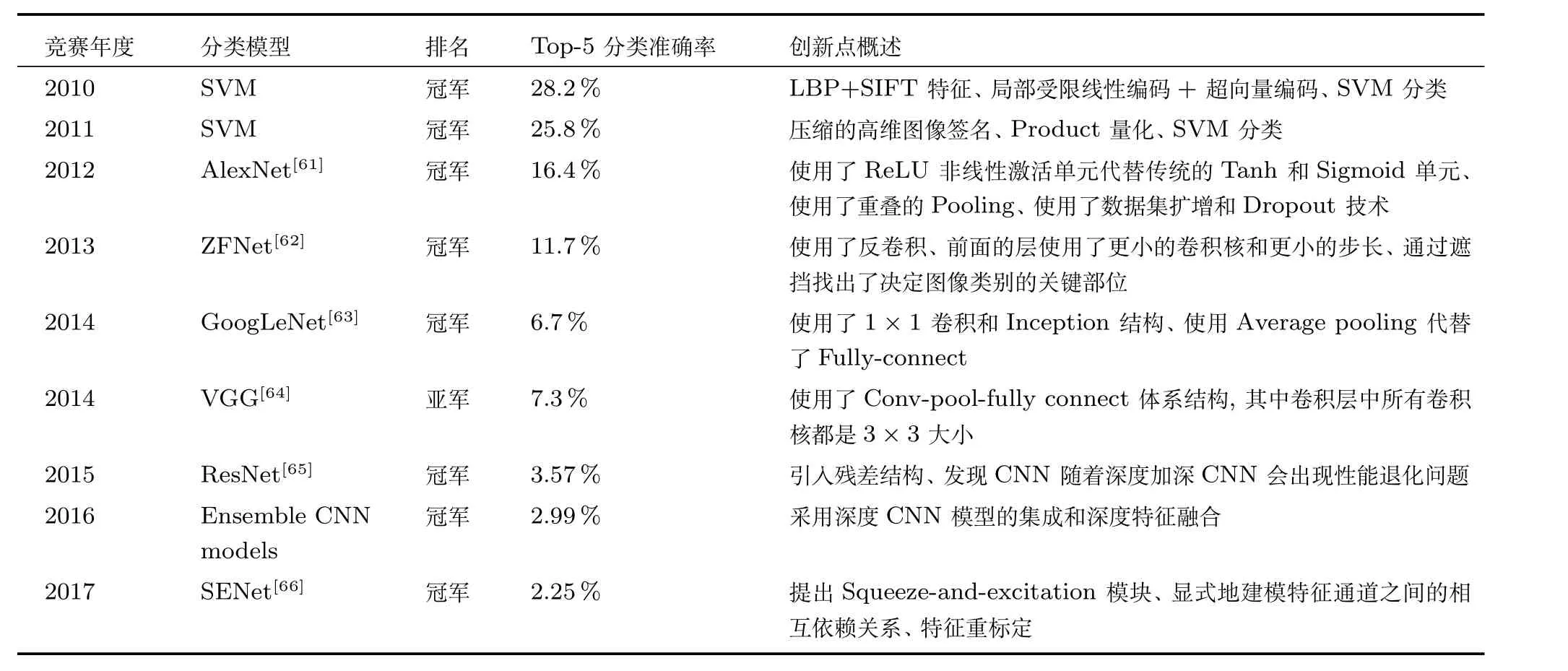
表5 ILSVRC图像分类方法[60]Table 5 Imageclassification methods in ILSVRC[60]
近几年,基于深度CNN模型的类别级物体检测方法可以分为两个主要方向:
1)基于候选区域建议(Region proposal)和深度CNN分类的两阶段(Two stage)物体检测方法,代表性工作有R-CNN[68]、SPP-NET[69]、Fast R-CNN[70]、Faster R-CNN[71]和 Mask R-CNN[72]等.
2)将物体检测转换为回归问题的一阶段(One stage)物体检测方法,代表性工作有YOLO[73−74]、SSD[75]、G-CNN[76]和 RON[77]等.
值得指出,由于这两个方向采用的检测框架存在差异,导致算法的性能也各有优势,两阶段物体检测方法的准确率占优,而一阶段物体检测方法的检测速度占优.
表6中归纳和对比了典型的物体检测方法,对每个方法的创新点进行了简要的描述.近年来,物体检测领域的两阶段方法和一阶段方法普遍基于深度CNN模型、大规模数据集和高配置的硬件设备,并且只是在训练和测试领域不变的前提条件下表现出了十分优异的性能.但是,在训练样本不足、硬件资源受限和跨领域等情况下,基于深度CNN的物体检测方法的性能将出现较大幅度的退化.因此,基于深度CNN和迁移学习的类别级物体检测是一个很有意义的研究方向.
2 类不平衡问题及迁移学习解决方法
分类器训练是类别级物体识别与检测中的关键,在类偏态分布(Skewed class distribution)的数据集的上训练分类器会导致容易训练出有偏向性的分类器,因为只要投机性地将多数类标签作为预测输出就会获得很高的训练正确率.但是,如果少数类样本的分类错误代价远远高于多数类样本,这种带有偏向性的分类器是毫无意义的.Weiss[78]指出,机器学习中的类不平衡包括类相对不平衡和类绝对不平衡两种情况.以二元分类为例,类相对不平衡指的是分类器训练时可以提供足够数量的正训练样本,只是正负训练样本数量的比例失衡.类绝对不平衡指的是正训练样本数量严重稀缺且正负训练样本数量的比例失衡.在物体识别任务中,由于一些物体的数据采集代价很高,导致其训练样本数量严重匮乏.因此,当采用有区别的(Discriminative)方式训练分类器时,分类器将偏向于始终输出训练数据中多数类的标签,这将导致分类器无法有效地识别物体.对于物体检测任务而言,当采用有区别的方式训练物体的检测器时,正训练样本通常在训练图片中标注的矩形框中提取,而负训练样本则在训练图片的背景区域随机地大量提取.由于训练时使用的负样本数量远远多于正样本数量,训练出来的物体检测器则很容易带有偏向性且易于过拟合.
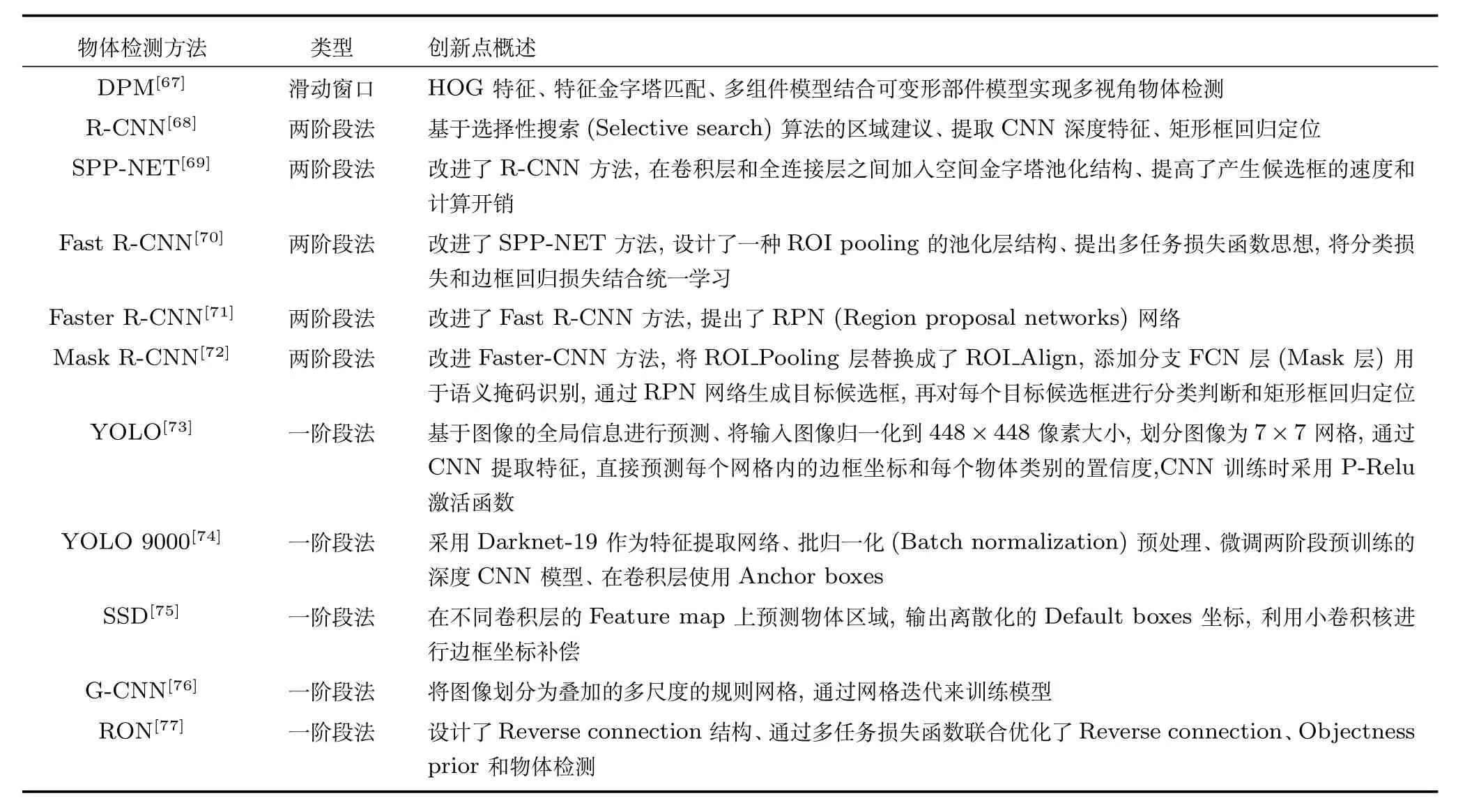
表6 典型的物体检测方法Table 6 Typical object detection methods
近年来,机器学习领域围绕类不平衡学习问题进行了大量的理论研究.He等[79]对类不平衡条件下的模型训练和度量方法给出了一个较为全面的综述.文献[79]将已有的类不平衡学习方法分为三种主要的类型:数据级(Data-level)方法、算法级(Algorithm-level)方法和成本敏感(Cost-sensitive)方法.对于“数据级方法”而言,在模型学习过程中对少数类训练样本的过采样(Over-sampling)和对多数类训练样本的欠采样(Under-sampling)策略被广泛用于再平衡类的偏态分布.Zhou等[80]通过实验比较了随机过采样(Random over-sampling,ROS)和随机欠采样(Random under-sampling,RUS)方法在训练成本敏感(Cost-sensitive)神经网络时的作用.文献[81−83]中提出了人工合成少数类过采样技术(Synthetic minorities over-sampling technique,SMOTE)及一系列扩展方法来解决类不平衡问题.尽管ROS、RUS和SMOTE技术在解决类相对不平衡问题时取得了较好的效果,但是在解决类绝对不平衡问题时的作用仍很有限.对于“算法级方法”来说,采用的主要策略是基于类不平衡的训练数据集将采用类平衡算法训练出来的模型适配(Adapt)为满足类不平衡应用.对于“成本敏感方法”而言,主要策略是在训练模型时为少数类训练数据分配一个较大的权重,而为多数类训练数据分配一个较小的权重.
到目前为止,在机器学习的理论研究层面,利用迁移学习解决类不平衡学习问题的研究仍然较少.Al-Stouhi等[84]提出了一个Rare-transfer算法,通过引入依赖于类标签的校正因子来减缓源领域样本权重的收敛速度.文献[84]中特别指出,Raretransfer算法是第一个在实例迁移框架下解决类不平衡问题的算法,论文中对算法的验证使用的是文本挖掘应用.文献[85]在类不平衡条件下对比了主流迁移学习算法和传统机器学习算法的性能.Wang等[86]提出了一种基于平衡分布适应(Balanced distribution adaptation)的深度迁移网络模型,通过自适应地平衡边缘分布和条件分布差异来解决类不平衡问题带来的挑战.文献[35]提出了一个两阶段学习框架,可用于解决多源迁移学习过程中的负迁移和类分布不平衡问题,并且从理论上证明了所提出方法的错误边界.Su等[87]基于自适应阈值化和二次加权思想提出了4种方法来解决类不平衡数据对自适应正则化迁移学习(Adaptation regularization transfer learning)算法的影响,并且在UCI数据集和脑电图分类应用中验证了所提出方法的有效性.
在物体识别与检测领域,虽然文献[67−68]中通过难负例挖掘(Hard negative mining)结合支持向量机(Support vector machine,SVM)的方法在类不平衡条件下训练出了准确率较高的物体检测器,但是难负例挖掘技术通常只适用于类相对不平衡条件下的物体识别与检测任务,即少数类训练样本的数量不是真正的稀缺(Scarity),只是相对于多数类训练样本而言数量上有些比例失衡.针对物体检测中出现的类绝对不平衡问题,文献[88]中提出了一个RUS-SMOTEBoost算法来训练分类器并将其用于物体检测的再分类阶段,该算法在每一轮boosting迭代时都对目标领域的多数类训练样本进行RUS采样,对少数类训练样本进行SMOTE采样,以保证在类绝对不平衡时减少SMOTE运算的开销.
在基于迁移学习的类不平衡物体识别与检测方面,文献[89]针对类不平衡的无监督领域适应问题,提出了一种最邻近共同空间学习(Closest common space learning,CCSL)算法,通过引入隐领域变量(Latent domain variable)来表征领域内和领域间的类标签和结构信息,该算法的求解过程可以视为同时进行实例加权和子空间学习.Tsai等[90]提出了一个领域受限迁移编码(Domain constraint transfer coding,DcTC)算法,该算法通过挖掘单领域或跨领域隐子空间的方式学习一个共同的特征空间,并将其用于领域适应和分类.Wang等[91]从统计学的角度提出了一个平衡分布适应(Balanced distribution adaptation,BDA)算法,可以自适应地权衡源领域和目标领域间边缘分布和条件分布的差异,然后基于BDA算法提出了加权平衡分布适应(Weighted balanced distribution adaptation,W-BDA)算法,用于解决迁移学习中的类分布不平衡问题.在文献[92]中针对物体识别中的类绝对不平衡问题,提出了一种人工合成实例迁移学习的方法,其基本思想是利用源领域和目标领域的训练样本人工合成出一些样本,然后通过实例迁移的方式有选择性地从源领域实例和人工合成实例中迁移一部分“有用”的实例到目标领域中.通过为每个人工合成实例分配一个合理的权重,将其动态加入TrAdaboost算法的每一轮弱分类器训练过程中.文献[89−92]中的每个方法均通过实验验证了其在类不平衡物体识别应用中的有效性.
综上所述,类不平衡条件下的迁移学习理论研究积累比较薄弱,尤其缺少各种类不平衡迁移学习算法的理论损失边界的定量化证明,这从某种程度上阻碍了算法的应用研究.另外,基于迁移学习理论的类不平衡物体识别与检测研究主要集中在基于实例和特征迁移的类别级物体识别范畴,对于类绝对不平衡条件下的物体检测方面的研究比较少见.
3 跨领域特征分布差异及迁移学习解决方法
跨领域物体识别与检测的主要挑战来自于跨领域带来的特征空间差异.近年来,迁移学习和领域适应中的一些理论开始被广泛应用于解决跨领域物体识别和检测任务中.值得指出,领域适应属于迁移学习的一个分支,侧重于研究两个领域间的特征分布不同但任务相同的迁移学习.
3.1 同构特征迁移(Homogeneous feature transfer)
在物体识别与检测应用中,同构特征的含义是指源领域和目标领域的特征提取和编码方法相同.此时,表示源领域和目标领域物体的特征向量维度相同,物体特征分布的差异主要由图像内在差异性导致,例如拍摄视角变换、图像分辨率或者图像纹理特性等.
文献[93]中提出了一个有监督的对称特征变换学习算法用于跨领域的多类物体识别,该算法基于Davis等提出的信息论度量学习(Informationtheoretic metric learning)方法[94]学习特征变换函数.文献[95]中提出了适用于目标领域分布随时间进化的连续流形适应方法(Continuous manifold adaptation),该方法将每一个目标领域的样本均视为隐含采样于目标领域流形的一个不同的子空间上.文献[96]提出了一种自适应结构化SVM(Adaptive structural SVM,A-SSVM)算法用于有监督的行人检测,同时基于高斯过程回归等方法提出一种无监督的行人检测方法.文献[97]中提出了一种深度迁移网络(Deep transfer network)框架,将深度神经网络用于跨领域的特征分布匹配,并且在跨领域多类物体识别应用中对算法的有效性进行了验证.Yang等[98]提出了一个Boosting框架下的多特征学习方法,通过迭代地学习多特征表示来解决无监督领域适应的问题.文献[99]中提出了一种深度适应网络DAN,将深度CNN应用到了领域适应中.在DAN中,每个任务的隐特征表示被嵌入共生核Hilbert空间中进行匹配.Yan等[100]提出了一个最大化独立领域适应(Maximum independence domain adaptation)算法,用于从领域特征中学习出最大化独立特征,并且在跨领域多类物体识别应用中对算法的有效性进行了验证.Long等[101]提出了一种无监督的领域适应方法,利用深度神经网络从有类标签的源领域训练数据和无类标签的目标领域训练数据中同时学习分类器和可以迁移的特征.文献[102]基于前向神经网络和对抗式训练方法提出了一种无监督的领域对抗神经网络DANN,可以使用标准后向传播和梯度下降算法进行模型训练.Long等[103]基于希尔伯特空间嵌入(Hilbert space embedding,HSE)和联合最大化平均差异准则(Joint maximum mean discrepancy,JMMD)提出了一种联合适应网络(Joint adaptation networks,JAN),通过使用对抗式训练的方法最大化源领域和目标领域间的JMMD度量.文献[104]在Faster R-CNN框架下提出了领域不变候选区域生成(Domain-invariant region proposal,DRP)网络,基于实例和迁移学习实现了跨领域的物体检测.文献[105]提出了一种弱监督的渐进式领域适应方法,通过领域变换(Domain transfer,DT)和伪标注(Pseudo-labeling,PL)两种方法人工生成的样本对源领域检测器进行微调实现跨领域物体检测.
表7对文献[93−105]中提出的方法进行了归纳和总结,通过对比分析可以看出当前研究主要是基于单源无监督领域适应的物体识别应用研究,其中深度神经网络和特征迁移学习的结合性研究较多.不难发现,基于同构特征迁移的物体检测研究在近三年才逐渐活跃起来,这可能与类绝对不平衡条件下的特征迁移学习理论研究仍比较薄弱有关系.
3.2 异构特征迁移(Heterogeneous feature transfer)
在物体识别与检测应用中,异构特征的含义是指源领域和目标领域的特征提取和编码方法完全不同.一般来说,异构特征迁移算法更为通用,它们也适用于同构特征空间的物体识别与检测任务.Kulis等[106]扩展了文献[93]中的方法并且提出了一个非对称特征变换学习算法,该算法允许源领域和目标领域的特征维数不一样.文献[107]针对异构领域适应问题,提出了一种异构特征扩增(Heterogeneous feature augmentation)方法,该方法将源领域和目标领域中维度不同的特征映射到一个共同的子空间,以此来减少跨领域特征分布的差异性.Xiao等[108]基于Hilbert-Schmidt独立性准则将目标核矩阵(Target kernel matrix)和源核矩阵(Source kernel matrix)的子矩阵进行匹配,以此将目标领域数据映射为源领域的相似数据,同时利用源领域数据学习一个源领域分类器.文献[109]提出了一个跨领域标志选择(Cross-domain landmark selection)算法用于异构领域适应,该算法可以识别跨领域的标志性数据并将其用于生成领域不变的特征子空间.
表8对文献[106−109]中提出的方法进行了归纳和总结,通过对比分析可以看出异构特征迁移学习理论在物体识别与检测领域的应用难度很大,目前的研究主要集中在物体识别应用领域,且主要采用有监督和半监督学习方式.另外,由于嘈杂背景的干扰和类分布不平衡等因素的影响,异构特征迁移学习理论在物体检测中的相关研究很少见到.
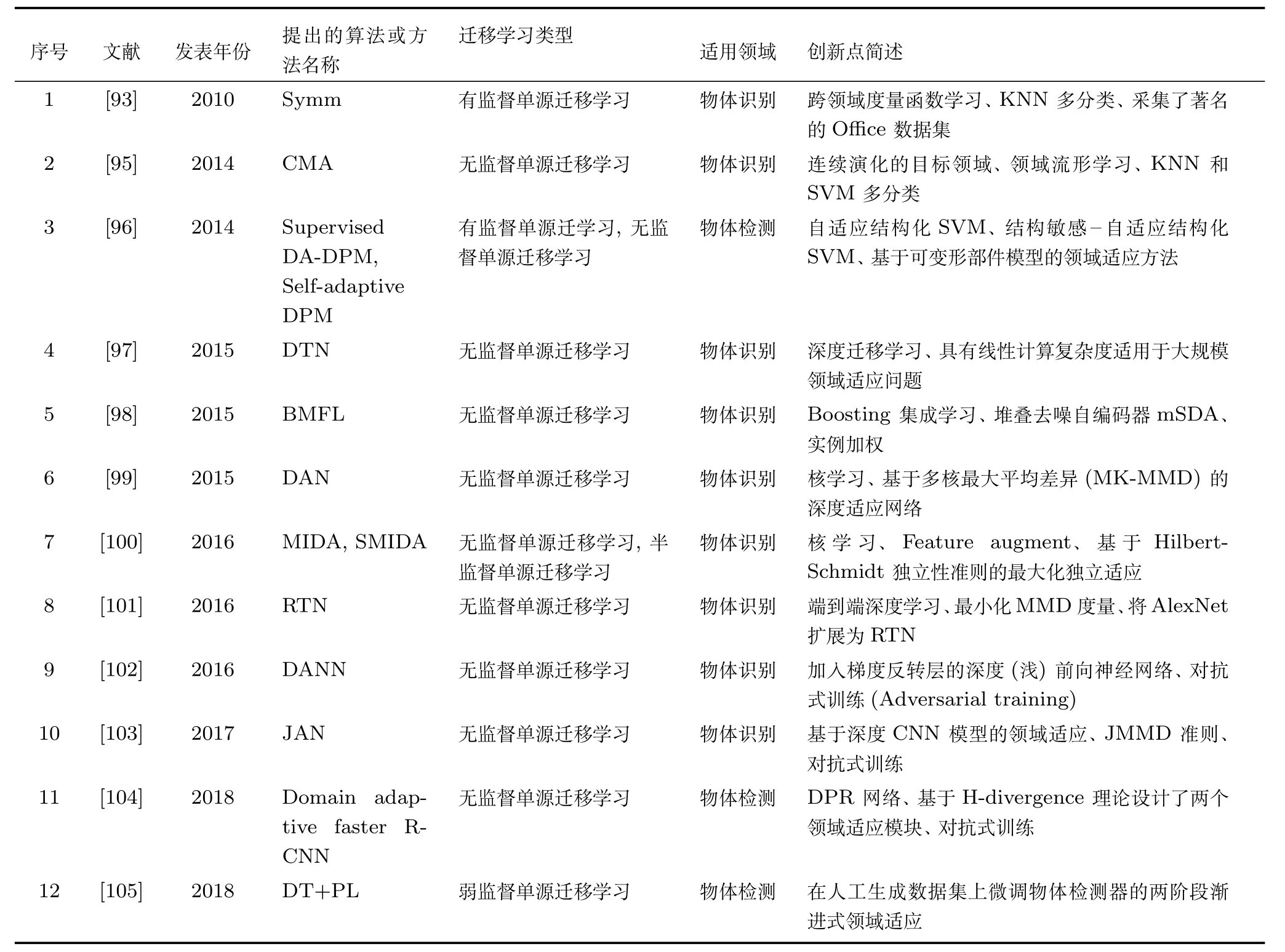
表7 基于同构特征迁移的物体识别与检测方法Table 7 Homogeneous feature transfer based object recognition and detection methods

表8 基于异构特征迁移的物体识别与检测方法Table 8 Heterogeneous feature transfer based object recognition and detection methods
虽然已经有大量的迁移学习算法通过学习特征变换函数来解决跨领域物体识别遇到的特征分布差异问题,但是这些方法绝大多数采用的都是离线学习的方式,即目标领域的训练数据是以离线方式获取的.当源领域训练数据集的规模很大或者目标领域训练数据通过在线方式获取时,采用离线方式学习特征变换通常由于内存开销过大导致无法满足实际应用的需求.目前,关于在线特征变换学习的研究较为少见,Zhao等[110]提出了一个在线迁移学习框架用于解决同构和异构领域适应问题,但是他们的工作主要集中于二分类在线迁移学习和文本挖掘应用.文献[111]中提出了一个在线迁移学习框架用于捕获代理(Agent)间的交互,指出强化学习中的迁移学习属于在线迁移学习的一种特殊情况.文献[112]针对离线方式学习特征变换时内存开销过大的缺点,提出了一系列在线线性和非线性特征变换学习算法,通过在线学习的方式来学习特征变换函数,有效地减少了计算机的内存开销.
4 过拟合问题及迁移学习解决方法
近年来,基于深度学习的物体识别与检测方法取得了极大的成功,但是这些方法适用的前提条件是有高质量的大数据和高配置的硬件设备支持.但是,在移动机器人环境感知领域,当移动机器人使用三维激光测距仪等传感器获取三维点云数据时,由于采集成本较高,三维点云数据集的规模和含有的物体种类相对于Web图片数据集而言小很多.当目标领域训练数据不足时,训练的模型易于过拟合,即在训练数据上表现很好,但在测试数据上的泛化能力很差.因此,解决过拟合问题对于某些特殊应用需求的物体识别与检测任务而言十分重要,迁移学习中的多任务学习、实例迁移和参数迁移可以用来解决这个问题.
4.1 多任务学习
多任务学习通过联合利用包含在多个相关任务中的有用信息,同时改善模型完成多个任务时的泛化能力,如图2所示.由于多任务学习涉及目标领域内多个任务间知识的共享和迁移,本文将其视为迁移学习的范畴.对于多类物识别与体检测任务而言,每个类别的物体识别与检测可以视为一个任务,多任务学习的动机是联合训练多个物体分类器要比单独地训练每一个物体分类器的效果更好.
Ghifary等[113]提出了一种多任务自动编码器(Multi-task autoencoder),可以在跨领域物体识别时具有更好的泛化能力.文献[114]提出了一种层次化深度多任务学习算法,用于大规模物体识别(例如:自动识别成千上万个原子物体类别)应用,该方法中使用视觉树(Visual tree)的方法将视觉上相似的原子物体(Atom object)类别分类为一组,以此自动标识多个任务的内部相关性.Torralba等[115]基于GentleBoost集成学习和决策树桩弱分类器提出了一种多任务特征选择类型的算法JointBoost,基于共享碎片特征实现复杂场景中的多类多视角物体检测任务,该方法通过在多物体类别间寻找共享特征的方式降低了小样本带来的模型过拟合风险并且提高了模型的健壮性.文献[88]在Torralba等[115]工作的基础上,利用BA图表示模型和再分类等技术实现了基于三维点云的多类多视角物体检测.Li等[116]基于带有全局输入和输出的全连通神经网络提出了一种多任务深度显著模型.该模型使用了多任务学习框架来发现语义图像分割和显著性检测之间的内在相关性.文献[117]提出了一种端到端的多任务学习方法,可以联合学习出物体及其行为.Chu等[118]提出了一种基于多任务深度卷积神经网络和感兴趣区域投票(Region-of-interest voting)的车辆检测框架,该设计使得卷积神经网络模型可以共享不同的车辆属性中的视觉知识.Lu等[119]提出了一种多模态树结构嵌入多任务学习方法,该方法既可以选择有区别能力的特征,也可以选择多个相似的分类任务共享的特征.文献[120]提出了一种联合稀疏表示和多任务学习的方法用于光谱物体检测,利用多任务学习技术将稀疏表示模型集成到多个相关的子光谱图像中.Zhang等[121]提出了一种多任务相关粒子滤波(Multi-task correlation particle filter)方法用于物体跟踪应用中,其中多任务相关滤波利用多个不同特征的内部相关性来联合学习相关滤波.
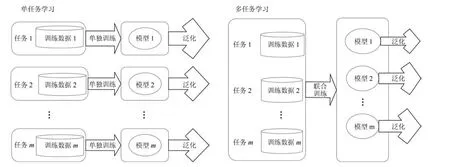
图2 单任务学习vs.多任务学习过程Fig.2 Single task learning vs.multi-task learning process
4.2 实例迁移
训练数据匮乏导致的分类器过拟合问题还可以通过从源领域迁移一些实例来扩大目标领域的训练数据规模的方法来解决.由于真实场景中嘈杂背景和类分布不平衡等因素的影响,基于实例迁移的物体检测研究较少,主要困难在于如何有效地选择“有用”的实例来扩增目标领域数据集,同时有效地避免负迁移的发生.文献[122]针对多类物体数据集中部分物体类别缺少训练数据的问题,通过从其他相关物体类别中直接迁移实例或者简单变换后再迁移实例的方式,扩大了部分物体类别的训练数据集规模.Zhang等[92]提出了一种基于人工合成实例迁移学习的物体识别方法,其基本思想是利用源领域和目标领域的训练样本人工合成出一些样本,然后通过实例迁移的方式有选择性地从源领域实例和人工合成实例中迁移一部分“有用”的实例到目标领域中.
4.3 参数迁移(也称为模型迁移)
在跨领域多类物体识别中,有时候源领域只有若干训练好的模型却没有训练数据可以提供.这时,如何利用这些已有的源领域模型和少量的目标领域样本训练出泛化能力更好的目标领域模型是一个很有意义的工作.目前,一些基于支持向量机[23,67]或卷积神经网络(Convolve neural network,CNN)的参数迁移算法[68]已经被用于解决这个问题.这些算法的主要思想是以源领域模型中的部分或全部参数值作为目标领域模型训练时的参数初始值,然后利用少量的目标领域训练数据来继续学习目标领域模型.基于参数的迁移学习通常要求源领域和目标领域的模型使用相同的算法进行训练.
Xu等[96]在可变形部件模型[67]基础上提出了两种半监督领域适应方法和一种无监督领域适应方法,将从虚拟世界行人图片集上训练的模型知识迁移到对真实世界行人图片的物体检测任务中.Malisiewicz等[123]利用一个正训练标本(Examplar)和大量的负训练样本去训练一个标本支持向量机(Examplar-SVM,E-SVM)模型,并将E-SVM 模型集成后用于物体检测任务中.正训练标本中包含的元数据(Meta-data)知识(例如,分割信息、几何结构和3D模型等)可以直接迁移到目标领域的检测任务中.文献[124−125]基于E-SVM 的思想提出了一种基于部件的迁移正则化方法EE-SVM,通过从标本支持向量机模型中迁移部件级参数到新模型中构造出泛化能力更强的模型.文献[126]中使用参数迁移的方法从源领域CNN模型中迁移参数用于训练目标领域CNN模型,其中源领域模型使用的是AlexNet体系结构[61],目标领域CNN模型的体系结构则是在AlexNet体系结构上针对目标领域的任务特点进行了调整修改.Hoffman等[127]提出了一个方法用于将CNN在源领域RGB图片集上训练的模型迁移到目标领域中基于深度图的应用中.
4.4 不同方法的对比
通过第4.1节∼第4.3节的文献综述,可以看出多任务学习、实例迁移和参数迁移在解决训练数据匮乏所导致的模型过拟合问题上各具特点.多任务学习适用于目标领域内有多个相关任务且每个任务的训练数据不足的情况,此时知识的共享和迁移仅在目标领域内部进行,不涉及到源领域中知识的迁移.因此,目标领域内多个任务的相关性和任务的数量对于模型的学习效果影响很大.实例迁移在用于解决模型过拟合问题时,主要是通过迁移单个或多个源领域的实例或者人工合成一些实例来扩增目标领域的数据集规模,进而提高训练出的模型的泛化能力.此时,如何快速地挑选或人工合成出“有用”的辅助实例且避免负迁移很重要.由于迁移学习中的“负迁移”问题尚未得到有效解决,目前在实际应用中主要是利用图像抖动(Image jittering)方法(即图像的旋转、缩放和平移等)来扩增目标领域的数据集规模.参数迁移在解决模型过拟合问题时,前提条件是目标领域需要训练的模型和源领域中已有的模型体系结构一致且训练算法相同,利用目标领域小规模的训练样本对已有的源领域模型进行参数微调.总的来讲,上述三种方法的适用场合各不相同,在应用时需要根据实际情况选用.
5 研究重点和技术发展趋势
5.1 研究重点
从当前的研究现状来看,迁移学习理论正在物体识别与检测领域进行着大量的实践应用.所发表的研究成果主要集中在特征迁移和参数迁移的范畴内,在利用迁移学习理论来解决类不平衡、异构特征和运动物体检测等方向的应用仍然较少.因此,未来的研究重点可以概括为以下4个方面:
1)深度学习和迁移学习相结合
近年来,深度学习在计算机视觉领域的应用很成功,通过依赖大数据和GPU硬件设备等的支持,将多类物体识别与检测的准确率大幅度地进行了提升.但是,深度学习对于数据质量和规模的要求在某些移动机器人的应用领域是无法满足的.因此,如何利用迁移学习降低深度学习对大数据的依赖是个十分重要的研究工作.
2)在线学习与迁移学习相结合
在移动机器人应用中,在视频流中进行运动物体追踪是一个更加有挑战性的研究课题.移动机器人通常采用多类传感器在不同环境中对感兴趣的物体进行追踪定位,当机器人所处的外部环境不断发生变化时,如何让机器人在进行物体检测时能够实时地适应环境的变化是个很有挑战性的研究工作.
3)跨传感器和异构特征空间的迁移学习
由于使用不同的数据采集传感器或者特征提取和编码方法生成的物体特征分布差异显著.例如,将从基于RGB彩色图片的物体检测任务中学习到的知识迁移到基于三维点云、BA图或者深度图的物体检测任务中是个更有挑战性的研究工作.因此,在跨传感器和异构特征空间下进行知识的迁移将面临来自特征分布异构、嘈杂背景干扰和小数据量等众多因素的干扰.
4)多源知识迁移和避免负迁移问题
目前,迁移学习领域对于多源迁移学习在物体识别与检测中的应用研究较少.迁移学习算法在海量的多源知识中穷举搜索“有用”的知识会导致知识的迁移时间过长,无法满足物体检测对实时性的需求.另外,源领域中“有用”的知识和“有害”的知识是并存的,如何避免负迁移是减少迁移学习过程中嘈杂背景对于物体检测准确率影响的关键.
5.2 技术发展趋势
近年来,随着移动机器人主动环境感知等领域对于物体识别与检测技术的需求不断变化,对于迁移学习理论的发展和应用也提出了更高的要求,新的基于迁移学习的物体检测方法和思路也不断涌现.以下是对该研究领域的技术发展趋势的展望:
1)基于深度迁移学习的物体识别与检测
基于深度学习的物体检测方法的模型训练中普遍使用了大规模数据集和深度卷积神经网络.因此,引入迁移学习的目的主要在于通过改进CNN的训练过程提高物体检测的准确率.Yosinski等[128]通过大量物体识别实验定量分析了卷积神经网络编码特征过程中,哪一个卷积层编码的特征更适合进行迁移学习使用.文献[129]提出了一种半监督迁移学习方法,将多核最大平均差异(Multikernel maximum mean discrepancy)损失引入微调卷积神经网络迁移学习框架中并用于中文字符识别.Christodoulidis等[130]提出了一种基于多源迁移学习的方法,使用多个源领域数据集预训练模型并将其迁移到目标领域的模式识别任务中.
2)基于在线迁移学习的运动物体检测
近几年,运动物体检测(或物体跟踪)的方法可以分为三个主要方向:
a)基于检测的物体跟踪(Tracking by detection),比较有代表性的工作有TLD[131]、Struck[132]和DCEM[133]等.该类方法与基于静态图片的物体检测方法类似,区别在于对特征和机器学习的速度要求更高,检测范围和尺度更小.
b)基于相关滤波(Correlation filter)的物体跟踪[134],比较代表性工作有CSK[135]、KCF[136]和CN[137]等.该类方法的主要思想是学习一个滤波器,然后和图像进行卷积操作得到相关信息图,图中相关值最大的点就是物体的位置.
c)基于深度学习的物体跟踪,比较有代表性的工作是 DLT[138]、SO-DLT[139]、FCNT[140]、MDNet[141]和RTT[142]等.上述基于深度学习的物体跟踪方法中大量地使用了CNN模型的预训练和微调(参数迁移)的策略,其他的迁移学习方法使用较少.
3)基于异构特征迁移学习的物体识别与检测
近几年,基于异构特征领域适应的跨领域多类物体识别研究的较为深入,比较有代表性的工作有ARC-t[106]、HFA[107]、MIDA[100]和 CDLS[109]等.目前的研究主要集中在多类物体识别的应用范畴,在跨领域物体检测方面的研究很少见,主要原因是嘈杂背景对异构特征迁移学习的干扰较大,影响了迁移学习的效果.在未来,异构特征迁移在物体检测领域的应用将是一个很有应用价值的研究工作.
6 结束语
基于迁移学习的类别级物体识别与检测的应用研究工作,将为基于小规模数据集的物体识别与检测应用提供一系列有效的解决方案,同时也会推动迁移学习理论的深入发展.要在该领域取得创新性的研究成果,必须把迁移学习理论和物体识别与检测技术有机地结合起来,兼顾理论创新与技术创新.此外,迁移学习可以弥补基于大数据和深度学习的物体识别与检测方法的不足,迁移学习的引入将为该领域的深入发展提供一个新的研究方向,为其注入新的活力.
