一种有效的通信网络告警分析方法
2019-08-20齐小刚胡秋秋姚旭清刘立芳
齐小刚,胡秋秋,姚旭清,刘立芳
(1.西安电子科技大学 数学与统计学院,陕西 西安 710071;2.中国移动集团公司 山西有限公司,山西 太原 030002;3.西安电子科技大学 计算机科学与技术学院,陕西 西安 710071)
通信网络管理主要是对网络的日常运行进行实时监控,以保证通信网络的高效可靠运行。随着信息技术的不断发展,通信网络规模持续扩大,网络结构也日益复杂,使得网络中任何设备发生故障或异常都会触发其它互连设备,引发越来越多的告警数据,从而增加了故障诊断和定位的难度[1]。因此,从网络告警数据中挖掘出有助于故障诊断和定位的知识信息是通信网络管理的基础。
告警相关性分析可将多个告警合并为一个具有更多信息的告警规则,从而找出引发故障的根源告警。典型的告警相关性分析方法有:基于场景的方法[2]、基于相似性的方法[3]和基于因果的方法[4]。基于场景的方法主要依据已有故障行为所抽象成的知识库,需要专家知识或推理知识不断更新知识库,从而难以发现并解决新的故障行为;基于相似性的方法主要取决于所选择的度量函数,对事先选取相似性度量函数要求很高;基于因果的方法需要建立比较精准的模型,且只适合每个步骤之间有明显因果关系的故障分析中。虽然以上方法在相应的情景中可以进行告警分析,但随着告警数据类型和数据量的增多,上述方法一定程度上需要依靠专家经验已逐渐不能满足实际需求。因此,基于数据挖掘的告警相关分析研究倍受研究人员的关注,其中关联规则挖掘算法和序列模式挖掘算法被广泛应用于通信网络的告警相关性分析中。文献[5]将关联规则挖掘算法和群体智能算法应用于通信领域,提出了基于粒子群优化的告警关联规则挖掘算法;同样,文献[6]将告警规则挖掘问题转化为蚁群旅行商问题,提出基于小生境跳蚁群的告警关联规则挖掘算法。文献[7]提出了一种基于前缀树和局部增长树数据结构相结合的并行频繁模式增长算法,提高了告警关联规则挖掘的效率。另外,考虑到告警发生具有时间上的先后顺序,序列模式挖掘算法常常被用来识别网络发生故障时告警之间存在的潜在时序关系[8],并广泛应用于其他领域[9-10]。文献[11]设计了一种基于扇形扑动和父子规则的告警模式挖掘系统,该系统利用序列模式挖掘算法搜索序列模式,并利用父子规则找到与故障相关的告警规则;文献[12]利用序列模式挖掘算法发现了网络节点与问题之间的关系。以上基于数据挖掘的告警分析方法都把告警看作是平等的,没有考虑告警对网络的影响等其他信息,因此,仅会挖掘出大部分出现频繁的告警,却很难发现那些发生次数少却对网络影响比较大的告警,从而难以挖掘到包含重要意义的告警知识。文献[13]将告警看作是不平等的,并表示支持向量机适合于告警的权值分配,但支持向量机是需要大量训练数据集的有监督算法,然而实际应用中往往无法事先获取大量有代表性的训练样本;其次,该文献提出的告警挖掘方法没有考虑告警发生的时间顺序,因此,无法挖掘到告警之间的时序关系。
在实际的通信网络中,各个告警对网络的影响程度不同,且由同一故障引发的告警之间都存在时序关系,使得告警的发生、发生的顺序以及告警发生对网络设备和业务的影响程度对告警规则的挖掘都具有非常重要的作用。因此,如何根据告警的重要性分配相应的权值,并建立相应的加权告警数据挖掘模型来发现告警之间的时序关系是该文研究的关键问题。
该文根据通信网络告警数据的特点,利用熵值法为各告警分配权值以说明其对网络的影响程度,并系统地探索了一种基于投影和模式增长的加权告警序列模式挖掘算法,来搜索告警数据中的加权告警序列模式以表示告警之间的时序关系。同时,将一种新颖的剪枝策略应用于这种算法中,以减少挖掘过程中需要搜索的数据集大小。实验结果表明,该算法能快速有效地挖掘不同级别告警之间隐藏的时序关系,并包含更多的重要告警。
1 网络故障与告警
网络故障指网络运行过程中出现的导致网络及设备无法提供正常服务的异常现象。网络告警是在系统中发生网络故障时自动触发的消息记录,用于传输所定义的信息。通常,这类消息都有其特定的含义并包括有关告警的告警名称、设备信息、网元名称以及告警发生的时间等,以通知网络管理员系统中可能出现的故障[14]。但告警通常不包括关于网络中故障的确切位置和问题根源的明确信息。因此,需要通过分析告警数据从而发现和故障有关的告警信息来确定故障根源。
表1告警实例

属性内容属性内容属性内容告警设备类型PTN网元名称53-147-XX-HW-PTN1对设备的影响无影响告警标题ETL_LOS告警发生时间2018-10-30 01:45:49对业务的影响可能全阻告警级别三级告警告警清除时间2018-10-30 01:46:16
在移动通信网络中,一个告警实例通常包含告警标题、网元名称、告警级别等属性,标题为“ETH_LOS”的告警实例如表1所示,其中告警级别、对设备的影响和对业务的影响可以反映一个告警的重要程度。另外,通信网络中的重要告警发生次数要远远小于一般告警的发生次数,但一个重要告警对网络服务的影响却比无数一般告警的影响大很多。因此,可为不同类型的告警分配不同的权值以反映其对网络的影响程度。由于通信网络的异构性和复杂性使得告警类型有成千上万种,仅依靠专家经验或主观判断无法快速且有效地为告警分配权值。熵值法[15]是一种根据评价指标的信息熵,来计算评价对象权值的客观赋值方法,因此可利用熵值法来计算告警属性的信息熵,从而达到客观计算告警权值的目的。该方法相对于主观赋值法,计算更加科学化,且精度较高。
2 基于熵值法的告警权值设计
2.1 熵值法的相关概念


2.2 告警权值的设计方法
每个告警都包含许多不同的属性,为了表明不同告警的重要程度,主要用对设备的影响、对业务的影响以及告警级别这三个属性信息来表示各个告警对网络的影响程度,并用熵值法来计算各个告警的权值。表2显示了一些告警实例的相应告警属性,包括5个评价对象和3个评价指标。
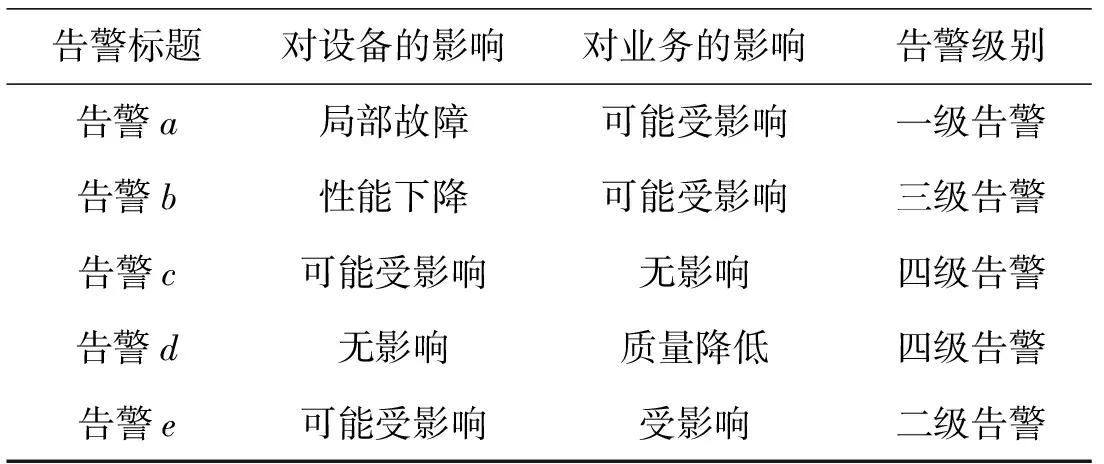
表2 一些告警信息实例
利用熵值法计算表2告警实例中的告警权值的步骤如下:

步骤2 根据式(1)标准化矩阵X=(xij)m×n,从而得矩阵Xnorm=(xij′)m×n,其结果为
xij′=xij-xmin/xmax-xmin。
(1)

步骤4 根据各个属性的熵权,由式(2)可计算各个告警的权值分别为Wa=0.82,Wb=0.42,Wc=0.09,Wd=0.26,We=0.58。
(2)
结果显示,告警越重要,其权值越大。因此,熵值法可以有效地确定通信网络中告警的权值。
3 加权告警序列模式挖掘算法设计
3.1 算法相关概念定义
为了清晰描述加权告警序列模式挖掘问题,下面定义该算法的一些相关概念。
前缀和后缀:假设每个告警序列中的项集都是按时间顺序排列。已知告警序列α=〈e1e2...en〉和β=〈e′1e′2...e′m〉,(m≤n),序列β为α的前缀,当且仅当:(a)e′i=ei(i≤m-1);(b)e′m⊆em;(c)(em-e′m)中的所有频繁项都在e′m后。若序列χ=〈e1e2...e′m〉,(m≤n)是序列α的前缀,则序列γ=〈e″mem+1...en〉是序列α以χ为前缀的后缀,其中e″m=em-e′m。
项集权重:对于给定项集e=(i1i2...im),其中每个告警项ij∈e对应的权重为wj,那么项集e的权重定义为该项集内所有项的权重的平均值:
(3)
序列权重:对于给定项集α=〈e1e2...ek〉,其中每个项集ej∈α对应的权重为w(ej),那么序列α的权重定义为该序列内所有项集的权重的平均值:
(4)
加权支持度:数据集D是元组〈sid,S〉的集合。那么告警序列T的加权支持度等于数据集D中含有T的序列个数和序列T的权值之积与D中所有序列的权值之和的比值:

(5)
加权告警序列模式:假设最小加权支持度阈值ξ(ξ∈(0,1]),若告警序列T的加权支持度满足Wsup(T)≥ξ,则T为加权告警序列模式,有l个项的加权告警序列模式称为l-加权告警序列模式。
加权频繁告警项:对于一个告警项i,若该项的加权支持度Wsup(i)不小于最小支持度阈值ξ,则该项i为加权频繁告警项;否则,为非加权频繁告警项。其中项i的加权支持度Wsup(i)等于当前搜索的数据集中包含项i的序列数和项i的权值之积与原数据集D中所有序列的权值之和的比值。
3.2 算法的模型和剪枝策略
为了避免在加权告警序列模式挖掘过程中产生候选子序列影响算法效率,该算法采用了投影和模式增长模型递归地挖掘加权告警序列模式。首先从加权告警序列数据集中搜索1-加权告警序列模式,从l=1开始分别递归构造以l-加权告警序列模式为前缀的投影数据集;然后从投影数据集中搜索加权频繁告警项,并将其分别附加到l-加权序列模式后从而形成l+1-加权告警序列模式。
传统的序列模式挖掘算法均遵循序列模式的全部子序列都是序列模式和非序列模式的任何超序列都肯定不是序列模式的向下闭合原则[9]。这里将该原则应用于新提出的算法的剪枝策略中,以减少递归挖掘过程的计算负荷。下面介绍新提出的算法的剪枝策略。
对于l-加权告警序列模式sl,假设已经搜索到〈sl〉-投影数据集中的所有加权频繁告警项,并将每个加权频繁告警项分别附加到l-加权告警序列模式sl后形成l+1-加权告警序列模式sl+1;然后分别从以包含〈sl〉的l+1-加权告警序列模式为前缀的后缀序列中删除所有非加权频繁项,形成〈sl+1〉-投影数据集。显然,在这个递归过程中,许多非频繁的加权告警子序列被修剪,极大地减少了对投影数据集的挖掘过程,且新提出的算法仍保持传统序列模式挖掘中的向下闭合原则。
3.3 算法流程和算法分析
为了简洁,将“告警a”用“a”表示,以此类推。表3为网络故障时的告警序列数据集实例。
对于表3的告警序列集,且给定ξ=0.5;各告警项的权值分别为wa=0.3,wb=0.2,wc=0.2,wd=0.4,we=0.3,wf=0.4,wg=0.9。该算法挖掘加权告警序列模式的详细步骤如下:

表3 告警序列数据集实例
步骤1 根据式(4)可计算表3中4个告警序列的权重分别为0.26,0.28,0.31和0.39。
步骤2 扫描表3中的告警序列数据集。以告警项a为例,可以发现所有的告警序列里均发生了a,因此,根据概念可计算Wsup(a)=(0.3×4)/(0.26+0.28+0.31+0.39) =0.97。类似地,可计算所有告警项的支持度分别为a:0.97,b:0.65,c:0.48,d:0.97,e:0.73,f:0.97,g:0.73。
步骤3 将告警项看作1-序列,可得〈a〉,〈b〉,〈d〉,〈e〉,〈f〉,〈g〉为1-加权告警序列模式。分别挖掘以〈a〉,〈b〉,〈d〉,〈e〉,〈f〉,〈g〉为前缀的加权告警序列模式。
(i) 由于告警项c不是告警数据集的频繁告警项,由向下闭合原则可知,后续挖掘过程中不会形成任何包含告警项c的加权告警序列模式,因此,根据剪枝策略,删除所有以1-加权告警序列模式为前缀的后缀序列中的所有告警项c。
(ii) 以前缀〈a〉为例,其后缀包括〈(bd)bcb(ade)〉,〈(_b)(df)cb〉,〈(_d)(bf)abf〉 和〈(_f)bc〉。然后,删除所有后缀序列中的告警项c,从而得到〈a〉-投影数据集,包含〈(bd)bb(ade)〉,〈(_b)(df)b〉,〈(_d)(bf)abf〉和〈(_f)b〉。
(iii) 扫描〈a〉-投影数据集,可知仅有项a,b,(_b),d,(_d),e,f,(_f)发生在〈a〉后可形成2-序列。计算a,b,(_b),d,(_d),e,f,(_f)的加权支持度,知b,d,(_d),f为〈a〉-投影数据集的频繁告警项(注:(_d)和d是不一样的,d表示和前缀a在不同项集内,(_d)表示和前缀a在相同项集内。故(_d)和(ad)为相同含义,即(_d)出现在〈a〉-投影数据集的第一个和第三个序列中。),将其分别添加到1-加权告警序列模式〈a〉后形成以〈a〉为前缀的2-加权告警序列模式:〈ab〉:0.65,〈ad〉:0.65,〈(ad)〉:0.65和〈af〉:0.65。
(iv) 由于a,(_b),e,(_f)是〈a〉-投影数据集中的非加权频繁告警项,因此,根据剪枝策略删除所有以包含〈a〉的2-加权告警序列模式为前缀的后缀中的告警项a,(_b),e,(_f)。以前缀〈ab〉为例,其包含〈(_d)bb(ade)〉和〈(_f)abf〉两个后缀,删除非频繁告警项后,〈ab〉-投影数据集中包含〈(_d)bbd〉和〈bf〉。扫描〈ab〉-投影数据集,可知仅有告警项b,d,(_d),f发生在2-序列〈ab〉后可形成3-序列。计算告警项b,d,(_d),f的支持度,可知没有加权频繁项,从而不会有3-加权告警序列模式产生,因此以〈ab〉为前缀的递归挖掘过程结束。同样地,〈ad〉,〈(ad)〉和〈af〉-投影数据集可以以同样的方式递归地建立和挖掘。最后,就可以导出以〈a〉为前缀的所有加权告警序列模式。
类似地,通过递归地构造并挖掘以〈b〉,〈d〉,〈e〉,〈f〉和〈g〉为前缀的投影数据集,从而可导出所有加权告警序列模式。综上所述,该算法用于加权告警序列挖掘的算法流程如下:
算法加权告警序列模式挖掘算法。
输入:D表示告警数据集;W表示各个告警权值数据;ξ表示最小加权支持度阈值。
输出: 所有加权告警序列模式。
步骤1 对于数据集D中的每个告警序列S,根据式(4)计算各个序列的权重W(S)。
步骤2 查找所有告警项,将各告警项看作1-序列,并计算其加权支持度,把加权支持度不小于ξ的1-序列加入1-加权告警序列模式数据集Seq1,令l=1(l代表序列中告警项个数)。
步骤3 分别将Seql中的每个l-加权告警序列模式〈sl〉看作前缀,递归执行以下步骤:
(i) 对于Seql中有相同前缀〈sl-1〉的序列模式〈sl〉,已得到〈sl-1〉-投影数据集中所有的非加权频繁告警项z,根据剪枝策略,删除所有以〈sl〉为前缀的后缀序列中的非加权频繁告警项z,从而得到〈sl〉-投影数据集。
(ii) 搜索〈sl〉-投影数据集中所有的加权频繁告警项;然后将每一个加权频繁告警项附加到l-加权告警序列模式〈sl〉后,形成以〈sl〉为前缀的l+1-加权告警序列模式集Seql+1。
ⓐ 若〈sl〉-投影数据集为空,则递归结束; ⓑ 若〈sl〉-投影数据集中所有告警项的加权支持度都小于ξ,则递归结束; ⓒl=l+1,并执行步骤3。
由于该算法在挖掘加权告警序列模式过程中不会产生任何告警候选子序列,且基于剪枝的方法可以在挖掘过程中剔除权值较低告警,从而极大地缩减了投影数据集,减少了对非频繁告警项的计算数量,因此,相对于传统的序列模式挖掘算法,该算法可以显著地提高挖掘过程中的执行效率。虽然该算法需要花费一定的时间和空间来计算和存储告警序列的权值,但对于大量告警数据的挖掘和存储来说,这些都是可以忽略不计的量。另外,采用该算法挖掘告警数据集中的加权告警序列模式,不仅可以挖掘出更多的重要告警,而且可以过滤掉大量不重要告警,使所挖掘的告警时序关系更加有效和实用,对故障诊断和定位有很大的帮助。
4 实验结果与性能分析
为了验证将不同告警看作是不平等的更适用于移动通信网络的告警相关性分析,本部分采用大量实验,对新提出的加权告警分析方法和传统将告警看作是平等的告警分析方法进行告警时序关系挖掘性能比较。在传统的基于数据挖掘的告警时序挖掘方法中,这里主要使用前缀投影序列模式挖掘(Prefix-Projected Sequential Pattern Mining, PrefixSpan)算法挖掘告警序列模式来表示告警之间的时序关系,因为该算法是所有传统序列模式挖掘算法中性能最好的[16],且文献[11-12]均用该算法挖掘告警数据中的时序关系模式。
4.1 实验数据集
实验主要使用中国移动提供的真实数据集和IBM数据生成器生成的T40I10D100k数据集[17]来验证加权告警分析方法挖掘告警之间时序关系的有效性和高效性。

表4 移动告警数据信息
由于通信网络具有规模大、异构、互连等特点,使得告警数据具有信息量大但不完全、冗余和相关等特点。因此,对于2018年7月内一周的中国移动真实告警数据,首先对其进行数据清洗,数据信息如表4所示;并选择告警标题、网元名称、告警发生时间、告警级别、对设备的影响、对业务的影响和告警清除时间7个属性来描述一个告警实例。然后利用熵值法对不同的告警分配不同的权值。同时,由于大部分告警的时序关系在10 min内发生,因此利用窗口宽度为600 s和滑动步长为480 s的滑动窗口得到告警序列数据集;其次由于不同设备的告警延迟在2 min内,则每个序列中的项集由窗口宽度为60 s和滑动步长为50 s的滑动窗口得到。T40I10D100k数据集包含100 k条序列和942个项,每个序列的平均长度为40,最大潜在序列模式长度为10。由于该数据集中每个项都没有权值,故将数据集中的每个项视为告警项,并为每个项随机生成(0.0, 1.0]的权值。
4.2 实验评估
第一个实验主要在中国移动数据集上评估新提出的加权告警序列模式挖掘算法挖掘加权告警序列模式和传统序列模式挖掘算法挖掘告警序列模式在不同支持度阈值(加权支持度阈值或支持度阈值)下的性能,主要以告警模式数量(加权告警序列模式或告警序列模式,即时序关系)和重要告警覆盖率为评判指标。其中,告警模式数量不包含1-告警模式的数量;重要告警覆盖率指包含重要告警的告警模式数除以总告警模式数的百分比。由于一级告警和二级告警共占总告警量不足1%,因此,统一将一级告警、二级告警和三级告警看作重要告警,四级告警看作不重要告警。
从图1(a)中可以看出,新提出的算法和所对比的传统算法挖掘的告警模式数量都会随着支持阈值的增加而减少,但新提出的算法挖掘的告警模式数比传统算法挖掘的告警模式数少。图1(b)显示,新提出的算法所得的重要告警覆盖率总是大于传统算法所得的重要告警覆盖率。其原因是所对比的传统算法将所有告警都看作平等的,因此,会挖掘出包含大量高频却不重要告警的告警模式;而利用新提出的算法挖掘加权告警序列模式能够过滤掉许多包含不重要告警的告警模式,并挖掘出包含重要告警的告警模式。因此,新提出的算法挖掘的告警模式数比所对比的传统算法挖掘的告警模式数少,且新提出的算法所得的告警模式的重要告警覆盖率有显著的优势。也就是说,传统的基于简单支持计数的序列模式挖掘所发现的告警序列模式中,那些权值较小的不重要的告警不会包含在加权告警序列模式中。由此可知,加权告警分析方法在通信网络的告警时序关系分析中具有很大的优越性。图2为移动数据集在不同支持阈值下加权告警序列模式的分布情况。

图1 中国移动告警数据集的分析结果

图2 移动数据集的k-加权告警序列模式分布

图3 移动数据集下支持度阈值与运行时间关系

图4 IBM生成数据集的分析结果
为了验证所提加权告警分析方法的适用性和有效性,在数据集T40I10D100k上进行第二个实验。在本实验中,将支持阈值设置在0.02到0.08之间以找到足够多的序列模式来验证算法性能,且将权值大于0.5的项视为是重要的告警项。如图4所示,总体结果与第一个实验结果相似,与传统告警分析方法相比,都呈现了较大的优势。通过上述分析,新提出的算法在搜索通信网络中告警的时序关系时,比以往的基于数据挖掘的告警分析方法具有更好的性能。
为了验证新提出的算法挖掘告警之间时序关系的高效性,在移动数据集上对新提出的算法和传统算法挖掘告警模式的效率进行了测试。图3显示了在移动数据集的各支持度阈值下两个方法挖掘告警模式的运行时间。显然,在不同支持度阈值的情况下,新提出的算法在效率上有很大的优势。其主要原因是新提出的算法运用了文中所设计的剪枝策略,在挖掘过程中剔除了后缀序列数据集中的非频繁告警项,大大缩减了投影数据集的规模,从而减少大量的非频繁告警子序列的计算,提高了搜索告警时序关系的执行效率。
综上性能研究表明,加权告警序列模式挖掘算法在挖掘通信网络中的告警时序关系时,具有很好的性能和效率。因此,文中提出的加权告警分析方法更适合于通信网络告警。
5 总 结
根据移动通信网络告警数据的特征,考虑到网络中不同告警对网络的影响程度不同且告警的发生有一定的序列关系,提出了一种高效的加权告警分析方法。首先,采用熵值法为不同的告警分配不同的权值;然后提出了一种加权告警序列模式挖掘算法来搜索告警数据中的时序关系,并采用了一种新颖的剪枝策略来缩减需要搜索的数据集大小,以减少非频繁告警子序列的计算数目。实验结果表明,该加权告警分析方法可以有效地减少告警模式的数量,并包含更多的重要告警,有利于网络管理人员及时地进行故障诊断和定位。此外,该加权告警分析方法在执行效率方面有很大的优势。因此,文中提出的加权告警分析方法为告警相关分析提供了一种有效的方法。
