松鼠AI智适应学习系统
2019-08-16崔炜薛镇
崔炜 薛镇


人工智能技术的进步促进了各行各业的发展。教育作为关乎国民生计的重要领域,其发展具有举足轻重的地位。面对当今教育领域存在的问题,人工智能的介入,可以促进教育资源的均衡化,通过提高学习效率来减轻学生的学习负担。基于人工智能的自适应学习系统通过个性化的教学方法,为学生提供更适合自身的学习方式,重新定义了教学与学习。
人工智能自从1956年提出以来,经过一个甲子的发展,已经不能停留在科学和技术输出的阶段。它迫切需要产、学、研的结合,找到合适的应用场景,才能产生社会效益和生命力,避免泡沫化。
教育属于第三产业,我国在由发展中国家向发达国家迈进的过程中,第三产业的比重逐年稳步增加。跟普通的第三产业不一样,教育属于基本的必须消费产业。住房、医疗、教育,被称为我国居民的三座大山。人工智能的介入,可以促进教育资源的均衡化,通过提高学习效率,来减轻学生的学习负担。
松鼠AI试图将人工智能学术成果与教育结合起来,改造传统教育方式。
自适应学习系统的构建
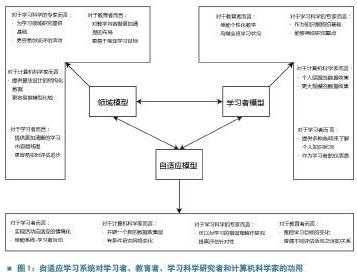
松鼠AI智适应学习系统,是人工智能与自适应学习的结合,“智”表示“智能”。松鼠AI将人工智能技术有机地融入到自适应学习系统当中。自适应学习系统是学习者、教育者、学习科学研究者和计算机科学家合作的产物。根据学习者反馈的数据来规划个体学习体验的方法,是基于自适应模型(Adaptation Model)进行的。如图1所示,它分为两方面:领域模型(Domain Model),比如数学、英语语法等不同领域的知识和陈述性、程序性等不同类型的知识;用户模型或用户画像( User Model或User Profile),比如和用户行为有关的特点和个性。在自适应教育系统中,因为被建模的领域是一个知识领域,该模型通常被称为知识模型,或者教师模型,用来模拟教师的知识和能力。由于用户是学习者,用户模型通常被称为学习者模型(参考Petr Johanes和Larry Lagerstrom于2017年提出的观点)。
自适应系统的开发者需要重点考虑的是:建模的对象是什么、如何建模以及如何维护这些模型。尽管建模的方式多样,现在最常用的是叠加建模(overlay modeling)。叠加建模的核心原则只有一条:一个领域存在某种基础模型,某个用户的模型属于该基础模型的子模型。按照这个范式运行自适应系统有双重目的:一是改变用户的体验,使用的叠加子模型最终与系统的基础模型相匹配;二是改变系统的基础模型,使它更精确地表征某个领域(参考Peter Brusilovsky和Eva Millán于2007年提出的观点)。
松鼠AI的教师模型
由知识图谱建立知识点关系网络
松鼠AI的教师模型是基于知识图谱创建的,构建知识图谱经历了人工驱动和数据驱动两个阶段。首先,学科教育专家将目标教学内容进行重新解构。以初中数学为例,500个知识点被化解为3万个细颗粒度的知识点,每个知识点上配套了学习内容,包括文字题目、动画、PPT、教学短视频等。例如,图2是有理数这个母知识点的细分知识点。这些知识点被分成多个层次,如图3所示,这些知识点分成L1、L2、L3、L4等多个层次,一个母知识点可以化解为更有针对性的子知识点。知识点之间的相互关系联结成一个图谱结构。知识图谱的初始结构由教育专家根据经验构建。
根据学生在松鼠AI系统中的实际学习数据,对知识图谱中的知识点相互关系进行更新。首先,利用贝叶斯网络发现知识点之间更加贴合学生实际学习的关联关系,对原始的知识图谱做迭代。其次,把这个知识图谱应用到AI学习系统中,再次让学生学习。然后,再根据学生的学习数据做迭代。如此循环往复,直到知识图谱趋于稳定。
以整数乘法这个专题为例:我们把它分割成如表1所示的知识点,每个知识点都配有专门考察该知识点的一定量的题目。首先教育专家需要建立知识点之间关系的知识图谱,然后利用贝叶斯网络方法,通过学生的做题记录来迭代知识图谱。得到的知识图谱如图4所示,图中的结点是知识点,箭头起始结点表示前置知识点,箭头终止结点表示后置知识点。
建立贝叶斯网络结构的算法有很多种,比如动态规划算法、A*算法、Chow-Liu算法等。我们这里采用的是Chow-Liu算法(C.K.Chow和C.N.Liu于1968年提出)。这种算法也被称做Chow-Liu树,通过计算信息量来发现描述数据的最优树结构。Chow和Liu在论文中证明,最优树结构的问题等价于求解的最大值,其中和表示結点,表示树,表示互信息。,其中是随机变量的联合概率分布,和是边缘概率。互信息是联合分布与乘积分布的相对熵。
由遗传算法确定难度标签
知识图谱上所有的知识点都配有题目,这些题目由松鼠AI的教育专家生产,并且打上了难度、预估做题时间、题型等标签。每个知识点上都有20个以上不同标签的学习内容,这些学习内容可能是文字题目、短视频、学习动画、PPT等。松鼠AI根据学生在学习系统中的表现,不仅给各个学生推送的知识点不同,而且推送学习内容的难度值等标签也不相同。这里以难度标签为例,来说明学习内容标签的确定方法。
难度的初始值由教育专家给出,分为简单(easy)、中等(moderate)、较难(hard)。系统通过遗传算法识别各个难度水平问题的特性。难度的测量分为两步:遗传算法模型在图5中的学习分析引擎(Learning Analytics Engine)模块中工作,在这里根据学生(Learner)跟学习内容(Content)的作用产生的数据,对难度标签进行迭代。Learning Analytics Engine从学生的响应模式中学习,识别各个难度水平题目的学生响应特性,动态创建分类规则。然后根据分类规则确定每道题目的难度。对学生的响应模式,系统考虑三个参数:学生从拿到题目到提交答案的时间跨度、答题获得的分数、提交答案之前进入题目的次数。所有这些因素取决于学生答题的行为,并且跟每道题目的难度水平相关。
对于每个难度水平,遗传算法根据属于该难度水平(初值由教学专家给出)所有题目的响应模式,来获得它们响应的特性,作为相应的数据集(参考Elena Pérez、Luisa Santos、María Pérez、Juan Fernández和Ricardo Martín于2012年提出的观点)。然后,每道题目的难度水平,通过它的响应模式的难度等级的中位数来计算得到。这样,就可以通过学生的学习数据对教学专家一开始确定的难度水平做迭代。
如此,系统将学生的行为和教育专家的经验结合起来,以便更加客观地计算每道题目的真实难度水平。
图6中,用梯形表示了各个参数的划分方法,相邻两个梯形的交点是分割点。图中“ VH(Very High) ”、“H(High)”、“VL(Very Low)”、“L(Low)”等,代表参数的数值范围,表示遗传算法借助学生对每个问题响应的数据建立规则,如图7所示。从图7可以看出以下规则:
IF GRADE IS VH AND TIME IS VL AND ACCESS IS L THEN DIFFICULTY IS EASY
IF GRADE IS VL AND TIME IS L AND ACCESS IS H THEN DIFFICULTY IS HARD
松鼠AI的学习者模型
学生在松鼠AI系统中学习,所生成的数据可以帮助研究人员和开发人员了解学生是如何学习以响应系统操作的。学生聚类是一种有效的方法,用于研究不同类型的学生如何与基于技术的学习系统进行交互。例如,研究人员使用聚类分析来探索学生的特征和偏好、求助活动、自我调节方法、产生错误的行为、不同学习时刻的数据、各种学习环境(个人还是协作)的数据。松鼠AI系统使用的聚类算法包括K-means和期望最大化(Vellido等于2010年提出)。
这项研究中作为样本的学生是从中国的三个省会招募的,使用松鼠AI学习对他们进行教学。该研究持续4天,每天学习5小时。所有参与的学生年龄均为13—15岁,共206名,包括完整的测试信息和系统数据在内共有72440条数据记录。样本平均年龄为13.8岁,56%为女性。
学生在使用松鼠AI之前和之后都进行了纸笔测试,分别称为前测和后测,以此来评测学生的知识掌握情况。测试由经验丰富的数学教師开发和审查。前测和后测都以100分制进行评分。结果显示,前测的平均值为55.72分,后测的平均值为63.92分。前测和后测结果具有0.86的高相关性,这使得我们能够使用增益分数来衡量学生的成绩。
松鼠AI系统记录了学生与系统的互动。我们根据学生行为和系统响应的日志数据创建了学生特征(参见表2),并为每个学生计算了相应的值。就我们的目的而言,这些特征构成了学生在持续时间方面的表现和学习的总体或平均情况。
对于每个学生,我们计算了表2所示的变量。这些特征的集合组成了每个学生的画像。我们进行了一系列的分析来确定8个画像特征(这里不使用“后测”特征)中的哪一个把学生归为相似的集合。我们使用K-means聚类,在线学习中最常用的聚类算法(Dutt等人于2016年提出)。
由于不同原型的学习者行为的数量是未知的,我们使用K=1-10来初始化K means聚类。考虑到聚类分析的目的之一是数据简约化,而且很多的簇可能没有意义,所以我们没有测试K大于10的情况。对于1-10中K值的每一种情况,我们对上述的变量做了K means分析,并生成了簇。为了确定数据集的最优K值,我们使用伪F统计和立方聚类准则CCC(Cubic Clustering Criterion,Calinski和Harabasz于1974年提出)来评估簇的数量。K=3聚类产生了伪F统计值和CCC(如图8和图9所示),图10中的典型相关分析,表明有清晰的可解释性和简约性。
图10中的簇2包括表现较好的学生,表现为前测分数高、正答率高、完成题目的难度水平高。这些学生也有较高的完成题目平均所需时间、较高的正确回答题目的平均所需时间差、较高的错误回答题目的平均所需时间差。有趣的是,在这3个簇中,这个簇中的学生完成了中等数量的题目和覆盖了中等数量的知识点。
簇1包括表现中等的学生,表现为前测分数中等、正答率中等、完成题目的难度水平中等。这些学生有较低的完成题目平均所需时间、较低的正确回答题目的平均所需时间差、较低的错误回答题目的平均所需时间差。他们完成了较高数量的题目和覆盖了较高数量的知识点。
簇3包括表现较差的学生,表现为前测分数低、正答率低、完成题目的难度水平低。这些学生有中等的完成题目平均所需时间、中等的正确回答题目的平均所需时间差、中等的错误回答题目的平均所需时间差。他们完成了较低数量的题目和覆盖了较低数量的知识点。
我们通过测量以上所述3个簇里面学生的前测到后测的分数提高,来检查分属3个簇的学生学习效果是否有区别。数据显示,这3个簇的分数提高没有显著差异,F(2,203)= 0.44,p=.64,r2= .004。
通过以上的研究可以看出,我们通过K means聚类方法将学生分成三个群体。这三个群体与学生的分数提高没有显著关联,这意味着学习系统能够帮助不同层次的学生取得进步(Shuai Wang、Mingyu Feng、Marie Bienkowski、Claire Christensen和Wei Cui于2019年提出)。
人机大战
松鼠AI在北京、郑州、成都、东营等地进行了多场人机大战,通过对比松鼠AI与真人老师的教学,来评估松鼠AI对改善学生学习的影响,并确定这些影响的可能程度。第三方独立研究机构对研究设计、实验现场执行、实验数据收集、数据分析与研究报告的全过程进行审核,以确保研究结果的科学性、客观性和可靠性。Haoyang Li等人在CSEDU2018、Mingyu Feng等人在AIED2018会议上发表的文章中分析显示,松鼠AI在这些实验中有更好的教学效果。这里以成都为例,说明人机大战的实施方案与数据分析。
样本
实验样本是来自成都的13至15岁的普通初中生,使用分层随机化方法将学生随机分配到对照组和实验组(参考Trochim、Donnelly和Arora于2016年所研究的成果)。共有203名学生参加了实验,其中101名学生被分配到实验组,102名学生被分配到对照组。
实验组的90名学生完成了实验,他们使用松鼠AI进行学习。对照组的73名学生完成了实验,他们是由真人老师进行指导的。其他的学生没有完成实验,不计入数据。在先行测试后,对照组的学生分成三个小组,接受三位老师的指导。老师们在当地的初中或高中具有8到18年的数学教授经验。
实验过程
这项研究在全国性假期期间持续了3天。本研究的时间表如表3所示,除了实验组接受松鼠AI和对照组接受教师指导外,每个学生的时间表相同。在第一天的宣讲中,向学生们说明实验的程序。表3中列出的活动之间的间隔是休息时间。两组涵盖的学习内容包括勾股定理及其应用、实数、三角形、整数表达式、三角形的性质和轴对称。在我们的研究之前,学生已经学过了这些内容。实验组的学生使用了松鼠AI系统,并在没有老师帮助的情况下完成了上述主题。在对照组中,教师根据当地学习标准教授该专题。对照组的学生不使用在线学习。研究开始和结束时的问卷包括人口统计学问题和学生在学习期间的学习经历评分。
前测和后测数据
测试前和测试后的题目,由当地学校(不是本实验研究团队的一部分)经验丰富的教师构建。这些老师在开发测试题目时,只被告知测试的专题和相关的学习标准。两名独立的经验丰富的教学专家审查了测试前和测试后的情况,以确保他们的覆盖范围、总体难度、题目类型与学习标准保持一致。专家们还检查确保测试题目与松鼠AI学习内容不重叠。每项测试由30個多项选择、填空、计算和应用题组成,总分为100分。测试由教师评分,然后扫描并发送给第三方机构进行审核。
分析与结果
图11显示了实验组和对照组从测试前到测试后的平均分数变化。虽然实验组和对照组都显示出从测试前到测试后的改善,但使用松鼠AI的学生成长是接受传统课堂教学的学生成长的4.19倍(实验组分数增长M = 9.38,SD = 11.08,而控制组增长M = 1.81,SD = 10.91,Hedges' g = .68)。以前测成绩作为协变量的单因素协方差分析(ANCOVA)确认了该结果的有效性,F(1,160)= 16.80,p <.001,偏η2= .10。
实验组和对照组在前测的表现,显示他们之前的知识没有显著的统计学差异,t(155.13,假设方差不等)= 1.49,p = .14,Hedges' g = .25。然而,前测也是学习收益的强预测因子,F(1,160)= 6.14,p = .014,部分η2= .10,那些在测试前知识显示较低的学生往往表现出更高的收益。
总结
表4基于实证证据和相关理论归纳了目前AI自适应学习的主要发展前景和存在的问题。AI自适应学习系统促进各类研究和教育资源整合协作,凝结了各方的智慧。如果我们合理地利用AI自适应学习系统,就能够为每个孩子提供适合他的学习模式,提高学习效率。
