多层次场景感知评分预测研究
2019-08-14胡文心
郭 望 胡文心* 吴 雯 贺 樑 窦 亮,2
1(华东师范大学计算机科学与软件工程学院 上海 200062)
0 引 言
基于评论的推荐,利用用户评论文本作为评分的补充。评论文本解释了用户对物品打分高低的原因,用户的评论集合反映了用户不同方面的兴趣,物品的评论集合反映了物品的性质。
同时在两个层面层次化地构建用户和物品的表示可以更加细粒度地挖掘用户和物品特征,但是现有工作大多只单独在“单词”层面或“评论”层面之一过滤重要特征,例如D-ATT[1](“单词”层面)和NARRE[2](“评论”层面)。此外,D-ATT在“单词”层面建模中先过滤重要单词再使用CNN编码文本的方法容易在过滤中丢失一个单词的上下文,先编码每个单词的上下文表示再过滤可以有效缓解这个问题。
用户兴趣与物品性质是随场景动态变化的。对于给定用户其面对不同物品时表现出的兴趣方面是不同的,对于给定物品其面对不同用户时表现出的主要性质也是与具体用户相关的。例如一个喜欢篮球运动的用户,面对一个球星代言的手机可能会打分较高,此时交互场景中“篮球”的特征被凸显了,而与手机其他特性(屏幕大小、性能等)关系较小。然而现有工作大多在用户和物品编码为固定维度的静态向量,两者再进行交互,例如DeepCoNN[3],不能突出场景中的主要因素。因此,使用户和物品的向量表示根据交互场景的上下文动态变化,可以更好捕捉两者的交互关系。
本文提出了一种基于用户评论的多层次评分预测模型SCRM。每个用户和物品都表示为L个评论的集合,其中每个评论N个单词。用户和物品的表示通过两个平行的网络建模,两者结构相同。以用户为例,在“单词”层面,通过CNN编码每个单词的局部上下文并使用“门机制”提取用户兴趣特征,去除冗余信息,得到每个评论的表示。在“评论”层面,通过注意力机制计算单个用户评论的交互场景上下文。具体地,计算单个用户评论到所有物品评论的相关性权重,将所有物品评论加权求和作为单个用户评论的上下文表示,与单个用户评论的表示进行融合,构成“交互场景感知”的用户评论表示。对于每个用户评论重复同样的过程,并将它们聚合得到用户的最终表示。最后,将用户和物品的最终表示在交互层进行匹配,计算预测评分。
1 相关工作
在推荐系统中,评论文本已经广泛地在许多工作中使用,例如HFT[21]、RMR[22]、EFM[23]、TriRank[24]、RBLT[25]和sCVR[26]。这些工作大多将用户表示为他过去写的所有评论的集合,同样地将物品表示为用户为它写过的所有评论的集合。评论文本不仅缓解了冷启动问题,也为建模用户兴趣和物品性质提供了更丰富的语义信息。
较早的工作大多基于主题模型LDA[20],将从评论中学习到的主题分布作为用户和物品的表示。例如HFT[21]将LDA和MF统一在同一个框架中,将评论文本主题分布的似然函数作为正则项与MF的目标函数相结合,拟合评分数据。
近来的工作明显地转向深度学习模型。神经网络在评论建模中具有明显的优势,例如自动的特征学习和十分有竞争力的性能。最近的工作在网络结构上大多由 “编码层”和“交互层”构成,例如DeepCoNN[3]、D-ATT[1]和NARRE[2]。在编码层,使用卷积神经网络(CNN)抽取文本中的特征,将用户和物品分别编码成两个低维向量。在交互层,对两个向量进行匹配,计算预测评分。
基于深度神经网络的模型,较早的是DeepCoNN。在编码层,它同时将用户和物品用两个平行的网络处理,通过CNN编码为固定长度向量。在交互层,用户和物品向量通过Factorization Machines(FM)进行匹配。
DeepCoNN的结构相对简单,近来提出的D-ATT在CNN编码层之前,加入了注意力机制。其核心思想是,根据局部和全局上下文信息衡量每个单词的重要性。它使用两个平行的网络分别过滤相对于局部和全局重要的单词。
将评论集合中所有评论拼接,作为用户(物品)的表示,存在比较大的噪声。因为用户的每个评论是在不同时期写的,代表用户不同方面的兴趣。NARRE对每个评论单独编码其表示,并衡量每个评论的有用性,使用注意力机制为每个评论分配权重,最后将全部加权求和作为用户(物品)的最终表示。
然而,这些模型都只单独在“单词”层面或“评论”层面之一过滤重要特征,缺少更加细粒度建模。此外,D-ATT由于先过滤重要单词,再用CNN编码单词的上下文表示,导致单词的上下文在编码前已经丢失了。而NARRE从评论有用性的角度计算评论的权重,却没有考虑具体的“用户-物品”交互场景对评论表示的影响。事实上,每个评论中所体现的用户兴趣和物品性质是与交互场景上下文相关的。
2 模 型
图1显示了SCRM整体的网络结构。我们对于用户和物品使用同样的网络结构,因此下文只详细介绍用户网络。
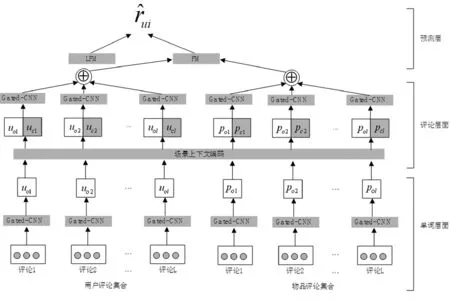
图1 SCRM整体结构图
网络接受一个评论集合,包含多个评论{r1,r2,…,rl},其中l代表评论的最大数量。每个评论经过“词嵌入层”映射为词向量序列,接着在“单词层面”通过“带门机制的卷积层”编码为固定维度的向量。编码后的评论表示在“评论层面”融合交互场景的上下文。最后将所有评论表示聚合为用户(物品)的最终表示,在“交互层”使用FM进行匹配。
2.1 词嵌入层
每个评论都是一个长度为T的单词序列,每个单词是用独热(one-hot)编码表示的向量。每个单词都通过嵌入矩阵Wd×|V|将独热编码映射到一个d维稠密向量,其中V是词汇表的大小。
2.2 单词层面:带门机制的卷积层
近年来,卷积神经网络(CNN)在文本编码方面得到了广泛的应用[12],例如TextCNN[7]、DCNN[8]。如图2所示,模型使用CNN来抽取单个评论的表示,包括一个卷积层和一个池化层。
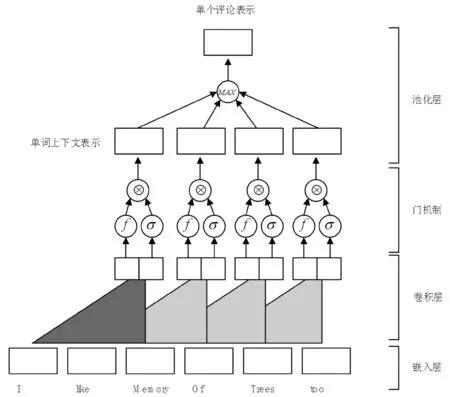
图2 单词层面建模图
2.2.1卷积层
在卷积层,输入是一个长度为T的评论,包含一个单词序列{x1,x2,…,xT}。将评论表示为一个矩阵X∈T×d,矩阵中的每一行为每个单词对应的d维词向量。我们使用卷积操作对句子中每个大小为h的窗口内的单词进行卷积,例如{x1:h,x2:h+1,…,xT-h+1:T}。每个窗口内卷积得到的特征图是窗口内“中心词”的上下文表示,例如窗口xi:h+i编码的是单词的上下文表示。
为了获得每个单词的上下文表示,使用一个大小为h的滑动窗口对整个评论文本进行卷积得到特征图A:
A=f(W*X+b)
式中:*表示卷积运算,参数W∈K×h×d为卷积核权重,参数b∈K为偏置项,K是卷积核的数量。f(·)为激活函数。为了编码单词在局部的上下文,实现中把h设置为3,过大的窗口容易引入太多噪声。
2.2.2门机制
带门机制的卷积神经网络(gated CNN)[10]在语言建模[6]和机器翻译[11]等领域取得了良好的性能。长短期记忆网络(LSTM)[9]中使用门机制决定特征的记忆与遗忘,受其启发,这里为CNN加入门机制。
A∈K×(T-h+1)中每一列对应一个单词的上下文表示。每个单词的重要性不同,每个单词上下文中不同特征的重要性也不同。因此,使用门机制给予A中特征不同权重来过滤相关信息,得到Ag:
Ag=A⊗G=
f(W*X+b)⊗σ(V*X+c)
式中:G=σ(V*X+c)∈K×(T-h+1)为门机制,控制A中特征的通过率。由于引入了非线性的门机制,实现中,激活函数f(·)使用恒等映射,即f(t)=t。参数W,V∈K×h×d为卷积核权重,参数b,c∈K为偏置项。σ为sigmoid函数。⊗为矩阵间的按元素乘法。
门机制G的作用体现在两个层面的:一方面根据单词的上下文过滤重要的单词,另一方面利用按元素乘法,在每个单词的上下文表示中过滤更相关的特征。相比只是给予不同单词权重,门机制G进行了更细粒度的处理。
2.2.3池化层
在池化层,将卷积层输出的单个评论表示Ag每行取最大值,得到向量a∈K。

为了方便起见,实验中设置K=d。
2.3 评论层面:场景上下文感知的评论建模
评论层面的输入是用户评论向量集合{u1,u2,…,ul}和物品评论向量集合{p1,p2,…,pl},分别用Uo,Po∈l×d表示。Uo中的每行代表一个用户评论的向量表示,Po中的每行代表一个物品评论的向量表示。
评论层面为每个评论表示计算场景上下文,然后将“原评论表示”和“场景上下文表示”融合为“评论的动态表示”,动态的含义是评论的表示根据当前场景上下文动态变化。SCRM在评论层面主要分为三个部分:场景上下文编码层、评论动态表示编码层和平均池化层。
2.3.1场景上下文编码层
场景上下文编码层根据用户评论集合Uo和物品评论集合Po计算每一个单个评论的上下文表示,得到用户评论的场景上下文集合Uc和物品评论的场景上下文集合Pc。
(1) 键值对记忆网络:注意力机制广泛的应用于许多任务,例如信息检索[15]、推荐系统[1]、阅读理解[13]和机器翻译[14]。基于注意力机制,SCRM使用“键值对记忆网络”[27]为每个原评论表示计算场景上下文表示。
“键值对记忆网络”的组成包括一个查询向量q∈d和一个“键值对记忆M”,目的是根据查询向量q从M中寻找相关的内容。键值对记忆网络的查询过程如图3所示。
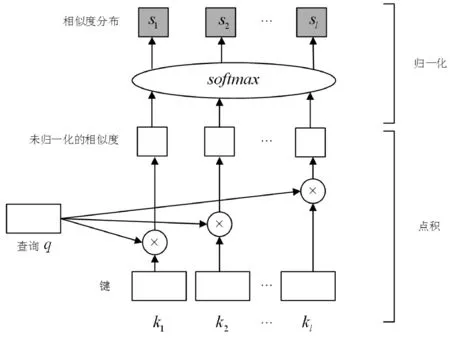
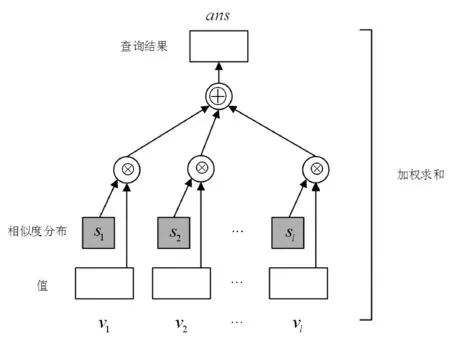
图3 键值对记忆网络查询图
“键值对记忆M”中包含若干键值对(ki,vi),ki,vi∈d。将所有键值对表示为两个矩阵K,V∈l×d,其中K、V中对应的同一行的两个向量代表一个键值对(ki,vi),l表示键值对的数目。给定查询向量q∈d,基于注意力机制可以从M中查询所有与q相关的键ki并得到对应的vi作为查询结果返回。使用“基于点积的注意力机制”可以更好地基于q与ki的内容相似性进行查询。
给定查询向量q和键值对矩阵K×V,使用注意力机制Attentionvector(q,K,V)查询:
s=softmax(Kq)
ans=Attentionvector(q,K,V)=Vs=
Vsoftmax(Kq)
式中:s∈l表示q对所有键K的相似性分布,这里利用softmax函数对相似性分布进行归一化。
ans∈d表示查询结果向量。Vs的含义是:如果q和ki相关度大,那么就返回相应的vi作为查询结果。需要注意的是,q可能与多个ki相关,基于注意力机制的查询方式会将多个vi按相关度加权求和作为查询结果。
键值对记忆网络中,查询可以批量进行。如果有一组查询qi∈d,其中i=1,2,…,nq,nq为查询的数量,可以将所有查询表示为一个矩阵Q∈nq×d,利用对矩阵运算优化良好的处理器进行加速。
给定查询矩阵Q和键值对矩阵(K,V),使用注意力机制Attentionmatrix(Q,K,V)查询:
S=softmax(QKT)
Ans=Attentionmatrix(Q,K,V)=SV=
softmax(QKT)V
式中:S∈nq×l中的第i行si∈l,表示查询向量qi∈d对所有键K的相似性分布。这里利用softmax函数对S中的每一行进行行内归一化。Ans∈nq×d表示查询结果向量,其中的每一行代表Q中对应行的查询结果。
(2) 场景上下文编码:交互场景由用户和物品的关系定义,用户多方面的兴趣和物品多方面的性质之间存在复杂的依赖关系,将这种相关性的语义通过注意力机制编码可以表达“场景上下文”的语义。
以用户为例,“用户的上下文”中需要考虑当前面对的物品各方面的性质,而每个物品评论反映了某一方面的性质,因此根据整个物品评论集合计算用户的上下文。此外,用户兴趣是多方面的,每个用户评论体现了不同方面的用户兴趣,所以逐一为每个用户评论计算上下文。类似地,“物品的上下文”也根据整个用户评论集合计算。
SCRM使用“键值对记忆网络”为每个评论编码其“场景上下文表示”,以用户的上下文来说明计算方法:对于单个用户评论uo∈d,其上下文表示根据所有物品评论集合Po计算。在键值对记忆网络中,令Attentionvector(q,K,V)中q=uo,K=Po,V=Po。那么uo的场景上下文uc∈d计算如下:
uc=Attentionvector(uo,Po,Po)=
Posoftmax(Pouo)
“键值对记忆网络”为整个用户评论集合Uo∈l×d逐一计算其中每个评论d的场景上下文表示d。其中i=1,2,…,l表示用户评论集合中的第i个评论。
使用键值对记忆网络中批量查询方式,可以得到所有用户评论的场景上下文表示,使用一个矩阵Uc∈l×d表示。令Attentionmatrix(Q,K,V)中Q=Uo,K=Po,V=Po,得到:
Uc=Attentionmatrix(Uo,Po,Po)=
softmax(UoPoT)Po
类似地,为整个物品评论集合Po∈l×d计算物品评论的场景上下文集合Pc∈l×d。令Attentionmatrix(Q,K,V)中Q=Po,K=Uo,V=Uo,得到:
Pc=Attentionmatrix(Po,Uo,Uo)=
softmax(PoUoT)Uo
在“场景上下文编码层”,我们最终得到用户评论的场景上下文集合Uc和物品评论的场景上下文集合Pc。
2.3.2评论动态表示编码层
在评论动态表示编码层,将每个评论的“原表示”和“场景上下文表示”进行融合,输出评论的动态表示。
对于用户,“评论的原表示”反映了用户某一个方面的兴趣,对于物品,“评论的原表示”也反映了物品某一个方面的性质。但是这种用户兴趣或物品性质是静态的,即使是很强的信号也不一定与当前交互场景相关,需要借助交互场景的上下文来确定用户兴趣或物品性质中真实有效的信号。
(1) 合并层:在合并层,输入用户(或物品)评论集合的“原表示”矩阵和“场景上下文表示”矩阵,将它们逐评论拼接并输出。
对于用户,合并后的评论集合表示Uoc:
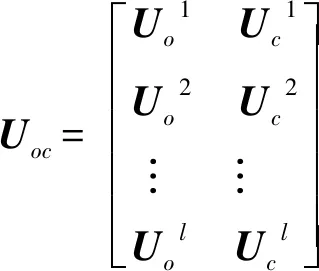
对于物品,合并后的评论集合表示Poc:
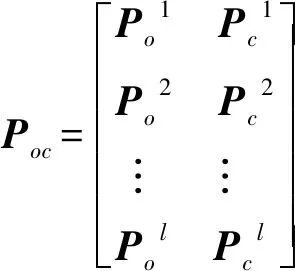
式中:Uo、Po分别为用户和物品评论集合的“原表示”矩阵,Uoi、Poi为其中的一行。Pc、Uc分别为用户和物品评论集合的“场景上下文表示”矩阵,Pci、Uci为其中的一行。经过拼接后的Uoc∈l×2d和Poc∈l×2d每行的维度由扩展到了2d。
(2) 融合层:在融合层,将每个评论的“原表示”和“场景上下文表示”进行融合,得到每个评论的“动态表示”。

Udynamic=Uconv⊗Gconv=
(Woc*Uoc+boc)⊗σ(Voc*Uoc+coc)
式中:*表示卷积运算,参数Woc,Voc∈K×h×2d为卷积核权重,参数boc,coc∈K为偏置项,K是卷积核的数量,实现中设置K=2d。
Udynamic=Woc*Uoc+boc将每个评论拼接后的表示uoci投影到一个新的语义空间,融合了两种表示。Gconv=σ(Voc*Uoc+coc)为门机制,给予评论表示中不同特征以不同权重。Udynamic=Uconv⊗Gconv将两者按元素相乘,达到根据场景上下文动态生成评论表示的目的。 类似地,对于物品,也对拼接后的Poc物品评论表示集合进行卷积,并利用门机制动态生成评论表示Pdynamic。
2.3.3平均池化层
在平均池化层,输入用户评论的动态表示集合Udynamic∈l×2d和物品评论的动态表示集合Pdynamic∈l×2d,输出用户的最终表示upool和物品的最终表示ppool。
以用户为例,对Udynamic中每列取平均值,得到向量upool∈d:
类似地,对于物品,根据Pdynamic得到向量ppool∈d。
平均池化可以反映用户评论集合中的多个方面的特征和总体情况。而最大池化希望观察到的是强特征,可以去除冗余的噪声,在“单词”层面使用最大池化,可以去除很多没有信息量的单词的影响,突出一个评论内部所反映的强信号。但是在“评论”层面,每个评论反映的用户兴趣和物品性质不同,最大池化会丢失较弱的信号。
2.4 预测层

第一部分rrating-based使用隐含因子模型(LFM)[4]来建模评分数据中反映的用户物品关系。LFM将用户和物品表示为从历史评分数据中推断出的向量:
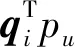
第二部分rreview-based中,将从评论文本中学习得到的用户表示upool和物品表示ppool拼接为z=[upool,ppool]∈2d并输入到分解机(FM)中。FM接受一个特征向量z并建模特征之间的一阶和二阶关系:
式中:w0是全局偏置;wi用于捕捉用户和物品之间的一阶交互强度;viTvj用于捕捉用户和物品之间的二阶交互强度。
3 实 验
实验部分给出了实验设置和经验性的评估。我们设计实验来回答以下几个问题:
问题1: SCRM是否超过了最先进的方法,例如D-ATT和NARRE?相应的提高为多少?
问题2:本文在“单词”层面的建模方法,是否缓解了D-ATT中上下文丢失的问题?
问题3:本文在“评论”层面的建模方法,相比NARRE中不考虑场景上下文的方法,是否带来了性能的提升?
问题4:本文同时在“单词”和“评论”层面抽取评论文本的表示,是否带来了性能的提升?
3.1 数据集
在实验中,使用了来自不同领域的四个公开数据集来评估SCRM,表1给出了相关的统计数据。四个数据集来自Amazon 5-core[17]的Digital Music、Toys and Games、Cell Phones and Accessories、Office Products。后续实验中将它们简称为“Music”、“Toy”、“Phone”和“Office”。

表1 四个数据集的统计数据
3.2 基 线
将SCRM和一系列基线方法相比较。
2) DeepCoNN[3](2017)是一个基于评论的推荐模型。在编码层它将用户(物品)的评论集合中所有评论拼接,通过卷积神经网络(CNN)编码其表示。在交互层它使用分解机(FM)建模用户和物品的交互关系并计算预测评分。
3) D-ATT[1](2017)是一个近来提出的模型,在多个数据集上达到的最先进性能的模型之一。它的主要特点是,使用局部注意力和全局注意力在“单词”层面过滤重要的单词,通过卷积神经网络(CNN)编码其表示,然后将局部表示和全局表示进行拼接作为最终表示。在交互层,它使用点积建模用户和物品的交互关系并计算预测评分。
4) NARRE[2](2018)是一个近来提出的模型,在多个数据集上达到的最先进性能的模型之一。它在“评论”层面对每个评论单独编码其表示,并使用注意力机制为每个评论分配权重,最后将全部加权求和作为用户(物品)的最终表示。在交互层,将隐含因子模型(LFM)中的用户表示和物品表示扩展成“基于评分的表示”和“基于评论文本的表示”并计算预测评分。
3.3 实验设置
我们在Tensorflow中实现了所有的模型并使用了Adam[18]进行优化,初始学习率设定为0.002。将所有模型训练至连续5轮验证集性能都不再提升,使用“早停”(early stopping)选择验证集上表现最佳的模型参数,并汇报最佳参数在测试集上的结果。实验中发现,MF需要35轮左右才能收敛,其他模型都在20轮以内收敛。我们重复实验20次,并汇报平均结果。
3.3.1评价指标
式中:N表示用户对物品评分的总数。
3.3.2参数设置
对于矩阵分解模型(MF),将用户(物品)向量维度设置为50。对于DeepCoNN和NARRE,将卷积核窗口大小设置为3。对于D-ATT,根据原文中的设定将“局部注意力模块”中的卷积核窗口大小设置为3,“全局注意力模块”中的卷积核窗口大小设置为{2,3,4}。所有模型的词向量均维度均设置为50,并使用预训练的Glove[19]词向量初始化。对含有隐含因子模型(LFM)的交互层中bu、bi、qi、pu均使用了系数为0.2的L2正则化。对含有FM的交互层中使用了概率为0.5的dropout,并将FM中的权重因子维度设置为10。
3.3.3数据预处理
本文将单个评论文本的最大长度设置为30个单词,评论集合中最多包含20个评论。在实验中,我们发现这样设置可以比较合理地反映不同模型的性能。对于DeepCoNN和D-ATT,将评论集合中所有评论拼接。
3.4 实验结果
3.4.1模型总体表现
表2中汇报了实验结果。对于“问题1”,我们发现SCRM在四个数据集上都是表现最好的。表3中汇报了SCRM相对于其他模型的提升,其中本文基于提升=(MSEhigh-MSElow)/MSEhigh×100%计算模型之间的相对提升。“提升1”-“提升3”分别表示SCRM相对于DeepCoNN、D-ATT和NARRE的提升百分比,“提升4”表示SCRM相对于表现最好的模型的提升百分比。SCRM稳定而显著地超过了近来有竞争力的基于评论的推荐模型DeepCoNN、D-ATT和NARRE(统计显著性p<0.01),其中提升最多达到13.0%(DeepCoNN)、4.6%(D-ATT)和5.6%(NARRE),相对其中表现最好的模型提升最多达到3.8%。提升平均为8.8%(DeepCoNN)、3.58%(D-ATT)和4.0%(NARRE),相对表现最好的模型提升平均达到3.3%。SCRM通过层次化的细粒度建模和动态适应交互场景的特征表示,全面地超过了现有方法。
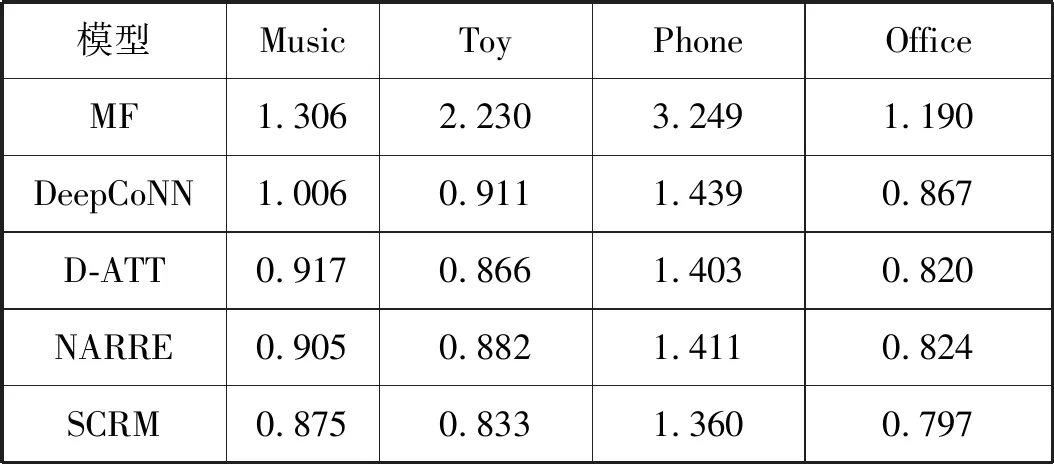
表2 模型总体表现对比(统计显著性p<0.01)
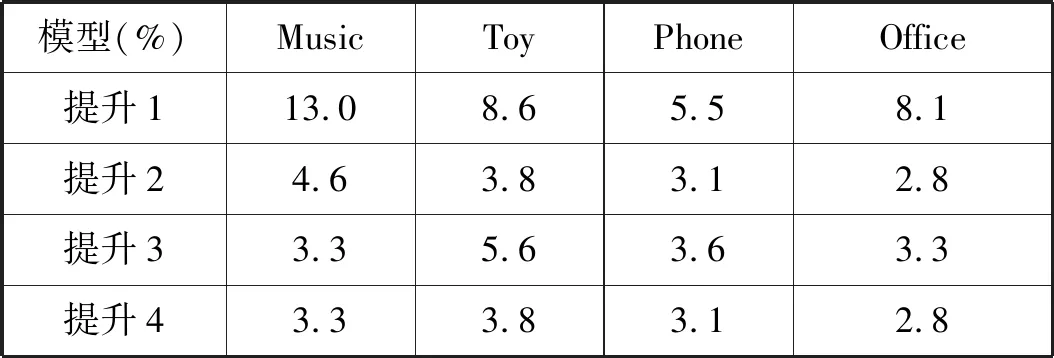
表3 SCRM性能提升百分比
此外我们发现,D-ATT和NARRE的表现稳定地超过DeepCoNN,这来源于它们对在“单词”层面或“评论”层面对评论更细粒度的处理。D-ATT和NARRE的相对排名在不同数据集上的有所不同,我们认为不同领域对于“单词”层面和“评论”层面的关注程度不同。NARRE在Digital Music数据集上超过了D-ATT,因为在音乐领域用户的兴趣相对更加多样性和主观性的,因此在“评论”层面对每个评论独立建模更有助于区分不同方面的兴趣。D-ATT在其他三个数据集上表现更好,例如Toys and Games数据集上,我们观察到大多是父母为孩子买玩具,相对于音乐电影等文化产品而言兴趣相对集中,此时“单词”层面的细粒度建模就会体现出更大的作用,可以更清晰地反映用户的具体兴趣。与两个基线模型不同的是,SCRM在不同领域上都有良好的表现,这来源于兼顾多层面的用户兴趣建模,使得两个层面相辅相成、互相促进。例如在Digital Music数据集上SCRM相对D-ATT和 NARRE的提高分别为4.6%和3.3%,根据领域特点SCRM更多弥补了“评论”层面的缺失。相反地,在Toys and Games数据集上提高分别为3.8%和5.6%,SCRM更多弥补了“单词”层面的缺失。
3.4.2“单词”层建模:缓解了单词上下文丢失
对于“问题2”,本文设计了实验来比较D-ATT与SCRM在只有“单词”层面建模的情况下性能。为了公平起见,我们对两个模型做了两点修改:首先,保证它们都只在“单词层面”上建模,并且将评论集合中所有评论拼接作为输入。其次,保证它们具有相同的交互层,避免交互层不同带来的影响。具体地,本文将修改后的D-ATT命名为“D-ATT-2”,其中只保留了局部注意力模块(SCRM也在“单词”层面只考虑局部上下文),在交互层更换为FM。SCRM修改后命名为“SCRM-2”,只保留“单词”层面的gated CNN,去除了“评论”层面的部分,并在交互层只使用FM。
表4汇报了在四个数据集上“D-ATT-2”和“SCRM-2”的结果,并将原始的D-ATT模型的结果作为参照。“提升”一行表示“SCRM-2”相对“D-ATT-2”的性能提升。
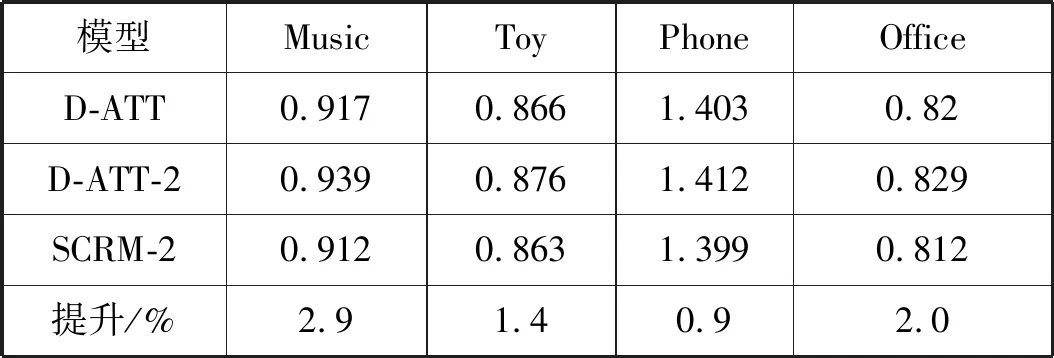
表4 “单词”层面表现对比
我们发现,在四个数据集上,SCRM-2在“单词”层面的表现都超过了D-ATT-2。我们认为这是D-ATT“单词”层面存在单词上下文丢失的问题引起的。D-ATT利用局部注意力机制给予每个单词不同权重来选择重要的单词,然后再将过滤后的评论送入CNN中编码每个单词的上下文表示。例如,评论中的一句话“I like Memory Of Trees too.”,Memory Of Trees是一首歌曲的名字。在D-ATT中,局部注意力根据上下文“Memory Of Trees”会保留中心词“Of”,因为这三个词经常作为词组出现,但是根据上下文“like Memory Of”丢弃中心词“Memory”,根据上下文“Of Trees too”会丢弃中心词“Trees”,因为它的上下文没有特殊意义。过滤后的评论表示变为“xxx like xxx Of xxx xxx”的形式,此时CNN再希望编码“Memory Of Trees”作为一个整体词组的表示时,已经丢失了“Of”的上下文“Memory”和“Trees”。
相反,SCRM先编码滑动窗口内每个单词上下文表示,然后再过滤有意义的单词上下文或词组。例如,先在gated CNN得到所有三元组“I like Memory”、“like Memory Of”、” Memory Of Trees”、“Of Trees too”,再利用“门机制”过滤得到“I like Memory”和” Memory Of Trees”两个有意义的三元组。最后将“I like Memory”中无意义的部分过滤,得到“xxx like xxx”和” Memory Of Trees”,它们表达了用户对歌曲喜爱的情感。此外,gated CNN中的“门机制”与“注意力机制”不同,“注意力机制”为每个单词上下文向量a∈d生成一个标量权重w∈1,而“门机制”生成权重向量w∈d,更加细粒度地过滤相关特征。
3.4.3“评论”层建模:场景上下文的作用
对于“问题3”,本文设计了实验来评估在“评论”层面的引入场景上下文的方法相对于只是从评论有用性的角度计算评论的权重的NARRE是否带来了性能的提升。为了公平起见,本文也对NARRE进行了修改:原本NARRE没有在“单词”层面过滤有效信息,因此为它加入word-level gated CNN保证两个模型在“单词”层面相同,然后比较它们在“评论”层面建模的差异。此外,两个模型在交互层也略有不同,但是都是将LFM扩展成“基于评分”和“基于评论”两部分,这里把交互层都统一改为FM。本文将修改后的NARRE命名为“NARRE-3”和“SCRM-3”。表5汇报了在四个数据集上的结果,并将原始的NARRE模型的结果作为参照。“提升”一行表示“SCRM-3”相对“NARRE-3”的性能提升。

表5 “评论”层面表现对比
我们发现,在四个数据集上SCRM-3在“评论”层面的表现都超过了NARRE-3。NARRE在“评论”层面使用注意力机制给予每个评论表示权重,并进行平均池化为一个固定维度的向量作为用户(物品)表示。在交互层之前,用户表示和物品表示都没有联系,反映的是静态的用户兴趣和物品性质。SCRM考虑到交互场景的不同对用户和物品表示的影响,在平均池化之前编码了每个评论的场景上下文,并与原表示融合,生成动态的用户和物品表示,消除了场景无关的信息,突出了场景中重要的特征。
此外,我们尝试保留NARRE的原始交互层,但是加入“单词”层面模块,表5中的“NARRE-4”一行汇报了相应的结果。将第一行和第二行的“NARRE”和“NARRE-4”比较,我们发现增加“单词”层面的建模对Digital Music数据集提升不大,但是其他三个数据集均有明显提升。这再次验证了在问题1中的推断:不同领域中用户兴趣的多样性程度不同,音乐电影等领域中“评论”层面的建模显得更加重要。
3.4.4层次化建模的作用
对于“问题4”,本文设计了实验比较只有“单词”层面建模和同时在“单词”和“评论”两个层面建模的不同,将这两种的情况命名为“SCRM-4”和“SCRM-5”。表6汇报了在四个数据集上比较的结果。“提升”一栏表示“两个层面”同时建模相对于只有“单词”层面建模的提升。

表6 单层建模与层次化建模表现对比
我们发现,同时在“单词”和“评论”两个层面建模,相比只在“单词”层面有了提高。层次化的特征抽取一方面对“评论内特征”进行了更细粒度的抽取,另一方面通过独立建模每个评论,对不同评论所代表的多方面兴趣的进行区分并融合场景信息,更好地突出了场景中显著的某一方面的兴趣。此外,在表5中我们发现“NARRE-4”超过了原始的NARRE,再次证明了多层次建模的必要性。
4 结 语
在推荐系统中,只根据“用户-物品评分矩阵”推断出用户和物品的表示,在数据稀疏时会出现严重的冷启动问题,从评论文本中挖掘用户兴趣和物品性质作为补充成为主流的方法。
本文主要的贡献是:(1)同时在“单词”和“评论”层面更加细粒度地从评论文本中抽取特征。(2)在“单词”层面,编码每个单词的局部上下文表示、过滤相关的上下文特征,并缓解了D-ATT[1]中单词上下文丢失的情况,保留更丰富的语义。(3)在“评论”层面,编码每个评论在当前交互场景中的上下文,动态生成用户和物品表示,突出在当前交互场景中决定用户打分的主要因素。(4)在多个数据集上进行了实验。SCRM在每个数据集上都显著地超过了基准MF、DeepCoNN、D-ATT和NARRE,并在“单词”层面超过了D-ATT,在“评论”层面超过了NARRE。
但是SCRM仍然存在一些不足之处:第一,对于单个评论仍然将评论内所有句子拼接,丢失了句子级别的语义。第二,对于每个单词而言,只编码了局部的上下文,没有更进一步的复杂语义,例如“我喜欢在周末听Memory Of Trees”中“周末”代表的时间场景和歌曲“Memory Of Trees”不能建立关系。
本研究对“层次化的评论建模”和“场景相关的推荐”提供了一些新思路,我们将来的方向是,加入“句子”层面的细粒度兴趣建模以抽取更丰富的语义关系。
