模型参数自适应迁移的多源域适应
2019-08-13余欢欢魏文戈
余欢欢 魏文戈


摘 要:在新领域中,常常存在样本不充分或标记不足的問题。针对此问题,人们提出了域适应,该方法利用相关领域(源域)的知识来提高当前领域(目标域)学习性能。单个源域的知识往往不充分且类别完全相同的多个源域难以满足,同时域之间存在漂移问题。而现有的多源域适应模型难以解决类别不完全一致的问题,因此给多源域适应带来了较大的挑战。为此提出了一种基于模型参数自适应迁移的方法(Adaptive Transfer for ModelParameter,ATMP),通过对每个源域的模型参数进行私有和公有模型参数字典学习,同时将多个源域中所学的模型参数字典作为目标域的模型参数字典,然后通过对字典系数的行稀疏约束实现源域和目标域模型参数的自适应选择。除此之外,该方法迁移的是模型参数而不是数据本身,因此有效实现了对源域数据的隐私保护。经过一系列实验表明,在相关数据集上的实验显示了本文所提方法在聚类性能上的显著有效性。
关键词:多源域适应;模型参数自适应迁移;隐私保护;聚类
中图分类号:TP391 文献标识码:A
Model Parameter Transfer Adaptively for Multi-source Domain Adaptation
YU Huan-huan WEI Wen-ge
(College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing,Jiangsu 211106,China)
Abstract:In new fields,there is often the problem of insufficient samples or labels. For this problem,domain adaptation(DA) has been proposed,which uses the knowledge of the related domain (source domain) to improve the learning performance of the current domain (target domain). The knowledge of a single source domain is often insufficient and multiple source domains with identical categories are difficult to satisfy,and there is a shift problem between domains. However,the existing multi-source TL model is hard to solve the problem of sharing inconsistent categories,which brings a great challenge for multi-source TL. Aiming at this problem,an adaptive transfer for model parameter method has been proposed,which can learn the private and public model parameter dictionary in each source domain. The model parameter dictionary learned in the source domains are used as the target ones,and then the model parameter of source domains and target domain are selected adaptively by the row sparse constraint of the dictionary coefficients. In addition,the method can also be directly used for TL of privacy protection due to the fact that the knowledge is transferred just via the model parameters rather than data itself. After a series of experiments,the experiments on the relevant datasets show the significant effectiveness of the proposed method in clustering performance.
Key words:multi-source domain adaptation;model parameter transfer adaptively;privacy protection;clustering
在传统的机器学习中,通常假设训练数据(称为源域)和测试数据(称为目标域)独立同分布,但在现实场景中,由于不同的因素,比如视角,展现模式的区别等,这些因素都可能导致该假设难以满足。因此,学者们提出了域适应,通过迁移源域的知识到目标域来避免源域和目标域数据分布不一致的问题。目前域适应主要包括单源域到单目标域知识的迁移,多源域到单目标域知识的迁移。在多源域的场景中,与目标域相关的多个源域的类别不完全一致的问题给多源域适应带来了较大的挑战。针对这一问题,提出了一种基于模型参数自适应迁移的方法(Adaptive Transfer for Model Parameter),在传统的聚类方法上,创新性地实现了源域和目标域模型参数的自适应选择,从而避免了源域知识到目标域知识的直接迁移。
主要貢献如下:
1)借助源域的知识,从模型参数字典的角度,对每个源域的模型参数进行私有和公有模型参数字典学习,同时将多个源域中所学的模型参数字典作为目标域的模型参数字典,并通过稀疏约束进行各域权重的适应性选择,从而实现域适应并提高目标域的聚类性能;
2)为现有参数迁移方法提供一个更大的灵活
框架,克服了现有参数迁移方法无法适应性选择参数的缺陷,同时实现了对源域数据的隐私保护;
3)通过在真实数据集上与相关算法的比较,验证了本方法在聚类性能上的显著有效性。
1 相关工作
域适应[1]是机器学习领域的重要研究之一,近几年广泛应用于计算机视觉[2],自然语言[3]和生物信息[4]等领域。
根据源域个数,可将域适应划分为单源域适应和多源域适应。其中,对于单源域适应的研究最多,主要包括参数迁移和非参数迁移的方法。参数迁移是通过参数传递实现知识迁移。文献[5]利用共享模型参数w0实现域间“连接”,侧重于共享模型参数的直接迁移;文献[6][7]分别在神经网络的模型上通过参数微调和变换实现知识参数迁移。而非参数迁移可分为基于实例和基于特征的方法,前者受重要性加权的启发,将源域有标记样本重加权后用于目标域;后者试图寻找一个“好的”转换矩阵来减小域间的差异。文献[8]采用核均值匹配(KernelMeanMatching,KMM)直接学习权重 ,实现了知识迁移;文献[9][10]分别提出了子空间对齐(SubspaceAlignment,SA)和相关性对齐(CorrelationAlignment,CORAL)的方法,通过对齐的方式学习一个源域到目标域的转换矩阵,从而减小域间的差异。
由于单源迁移存在信息不足的问题,因此,多源域适应逐渐备受关注。文献[11][12]针对一般的多源迁移场景,即每个源域和目标域的类别完全相同,然后分别采用实例迁移和特征迁移的方法解决域漂移的问题;文献[13]针对源域类别不完全相同的场景采用了特征迁移的方式实现了迁移。
综上所述,目前大部分域适应仅面向单域之间和类别完全相同的多域到单域问题,而对于源域类别不完全共享的域适应研究相对较少。为了弥补现有方法的不足并扩展域适应的应用范围。本文提出了一种参数自适应迁移的多源域适应方法(ATMP)。
2 模型参数自适应迁移的方法(ATMP)
在本节中,针对多个源域类别不完全共享的场景,我们提出了一种基于模型参数自适应迁移的方法。
2.1 ATMP算法设计
对于式(1),第一项和第二项为原始的 SLMC 算法;第三项和第五项为模型参数字典的学习,实现了源域到目标域知识的迁移;其他两项为字典系数的约束,并通过行稀疏约束实现了选择性域适应。
2.2 ATMP算法优化
3 实验分析
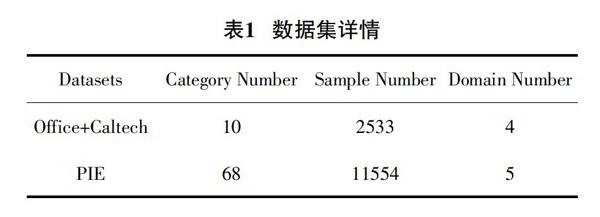
实验中,以Office+Caltech和PIE数据集为主,分别为目标识别和人脸识别数据集。
由于多个源域共享不完全相同的类别,因此,我们以共享类别数3为例,分别对2、3、4个源域进行实验类比。
对于TSC[16]、STC[17]和TFCM[18],针对的是单源之间的的迁移。因此,为了实现多源的迁移,我们将多个源域的数据融合后作为单个源域。同时,本文针对的是无标记小样本问题,且原始样本数过多,故我们从对应类中随机删除部分数据。此外,对于源域的类别做不完全共享的处理,即删除部分类别的数据,使得源域类别不完全相同,并且保证这些源域类别的并集与目标域相同。
通过以上处理,分别在2个真实数据集上进行算法比较,得到表2、表3和表4,并据此得出以下结论:
(1)在2个源域、3个源域和4个源域的数据集上,ATMP基本优于其他算法,主要得益于源域和目标域间模型参数字典的连接及其自适应选择。
(2)通过对比发现,随着源域个数的增加,目标域的聚类性能越好,基本上每增加一个域,目标域的性能可以提高2%左右,主要是因为域的增加使得源域所提高的知识也增加。
4 结 论
目前针对多源域适应的研究较少。由于现实场景中难以发现类别完全相同的多个源域,且源域之间存在着漂移问题,而现有算法关注的都是源域类别完全相同的场景,难以适用于现实场景。针对这一问题,提出了模型参数自适应迁移的方法(ATMP),通过模型参数字典的迁移和模型参数的自适应选择,实现了源域到目标域知识的迁移。除此以外,该方法迁移的模型参数而非数据本身,因此有效实现了对源域数据的隐私保护,并通过一系列实验表明了ATMP算法的显著有效性。
参考文献
[1] PAN S J,YANG Q. A survey on transfer learning[J]. IEEE Transactions on knowledge and data engineering,2010,22(10):1345—1359.
[2] SOHN K,LIU S,ZHONG G,et al. Unsupervised domain adaptation for face recognition in unlabeled videos[J]. arXivpreprintarXiv:1708.02191,2017.
[3] BLITZER J,MCDONALD R,PEREIRA F. Domain adaptation with structural correspondence learning[C]. Proceedings of the 2006 conference on empirical methods in natural language processing. Association for Computational Linguistics,2006:120—128.
[4] KAMNITSAS K,BAUMGARTNER C,LEDIG C,et al. Unsupervised domain adaptation in brain lesion segmentation with adversarial networks[C]// International Conference on Information Processing in Medical Imaging. Springer,Cham,2017:597—609
[5] SCHWAIGHOFER A,TRESP V,YU K. Learning Gaussian process kernels via hierarchical Bayes[C]// Advances in Neural Information Processing Systems. 2005:1209—1216.
[6] YOSINSKI J,CLUNE J,BENGIO Y,et al. How transferable are features in deep neural networks[C].Advances in Neural Information Processing Systems. 2014:3320—3328.
[7] 許夙晖,慕晓冬,柴栋,等. 基于极限学习机参数迁移的域适应算法[J]. 自动化学报,2018,44(2):311—317.
[8] HUANG J,GRETTON A,BORGWARDT,et al. Correcting sample selection bias by unlabeled data[C]. Advances in Neural Information Processing Systems. 2007:601—608.
[9] FERNANDO B,HABRARD A,SEBBAN M,et al. Unsupervised visual domain adaptation using subspace alignment[C].Proceedings of the IEEE International Conference on Computer Vision. 2013:2960—2967.
[10] SUN B,FENG J,SAENKO K. Return of frustratingly easy domain adaptation[C]. AAAI. 2016,6(7):8.
[11] SUN Q,CHATTOPADHYAY R,PANCHANATHAN S,et al. A two-stage weighting framework for multisource domain adaptation[C].Advances in Neural Information Processing Systems. 2011:505—513.
[12] LIU H,SHAO M,and FU Y. Structure-preserved multisource domain adaptation[C]. 2016 IEEE 16th International Conference on. Data Mining(ICDM).IEEE,2016:1059—1064.
[13] XU R,CHEN Z,ZUO W,et al. Deep cocktail network: multi-source unsupervised domain adaptation with category shift[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3964—3973.
[14] TSENGP. Convergence of a block coordinate descent method for nondifferentiable minimization[J]. Journal of Optimization Theory and Applications,2001,109(3):475-494.
[15] WANG Y,CHEN S. Soft large margin clustering[J]. Information Sciences,2013,232:116—129.
[16] JIANG W,CHUNG F. Transfer spectral clustering[C].Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer,Berlin,Heidelberg,2012:789—803.
[17] DAI W,YANG Q,XUE G R,et al. Self-taught clustering[C]. Proceedings of the 25th international conference on Machine learning. ACM,2008:200207.
[18] DENG Z,JIANG Y,CHUNG F L,et al. Transfer prototype-based fuzzy clustering[J]. IEEE Transactions on Fuzzy Systems,2016,24(5):12101232.
