变量变换回归分析(Ⅲ)寻找理想试验点的方法
——
2019-08-13胡良平
胡良平
(1.军事科学院研究生院,北京 100850;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029
1 基本概念
1.1 多因素试验设计类型
在一项试验研究中,通常都会涉及多个试验因素,从每个因素中各取一个水平组合起来,就形成了一个特定的“试验条件”。在有多个试验因素的研究场合中,以不同的方式选取因素的水平组合,就对应着不同的“试验设计类型”。例如,将所有试验因素的水平全面组合且在各种组合条件下进行两次或两次以上独立重复试验,此安排就被称为“析因设计”;又例如,依据正交原理从全部水平组合中选取部分水平组合来安排试验,就被称为“正交设计”[1]。以此类推,还有“均匀设计”“最优设计”和“正交组合设计”等[2-3]。
1.2 理想试验点
前面所说的每个试验条件常被称为“试验点”,也就是说,每个“试验点”实际上就是由拟考察的试验因素各取一个水平的一种组合。若试验结果是定量的,在各试验点上实施试验后,就可以观测到一个或多个具体的数值。在实际问题中,当定量观测结果的取值越大越好时,就称此类定量指标为“高优指标”;反之,就称为“低优指标”。若定量指标取中等值为优,这种情况并不多见,不属于本文讨论的范畴。
所谓“理想试验点”,也被称为“最优试验条件”,是指“高优指标”或“低优指标”获得最优取值时所对应的“试验点”或“试验条件”。
1.3 三种分析方法的异同点
本文涉及到三种统计分析方法:方差分析、回归分析、结合分析。一般来说,方差分析的主要目的是考察各因素对定量指标的影响,一方面希望能将全部因素及其交互作用对定量结果的影响分出主次关系,另一方面希望能揭示出每个因素各水平对定量结果影响之间的差异。回归分析的主要目的是构建因变量依赖自变量变化而变化的回归模型,同时筛选出对因变量具有统计学意义的自变量,有时,还需要在给定自变量取不同值的条件下,预测因变量的数值;而结合分析的主要目的是希望给出各因素对“偏好评分”影响大小的“重要性”的度量,同时希望给出每个属性(或因素)的每个水平作用大小的“效用值”的度量。
从上面的介绍似乎可以认为上述三种分析方法是完全不同的,事实上,它们都属于回归模型分析法。因为方差分析模型本质上就是一种简单的回归模型,而结合分析模型实际上是将属性(或因素)的每个水平当作一个“二值自变量”,并基于“效用值”可叠加的假定构建出来的回归模型[4]。
2 一个取自TRANSREG过程的样例
2.1 样例的名称与内容
在SAS/STAT的TRANSREG过程中有一个名为“BOX-COX变换”的样例:在纺织研究中,纱线的寿命主要受三个试验因素的影响[5]。见表1。

表1 影响纱线寿命的三个主要试验因素及其水平
注:表中圆括号之前的数字为因素的“真实水平”,圆括号内为因素的“代码水平”
由表1可知,这是一个涉及三个3水平试验因素的试验研究,若将3个试验因素的水平全面组合,就有27种不同的试验条件,每个试验条件下的试验结果为纱线的寿命长短(单位不详),是一个计量变量。研究者在27种不同试验条件下都只进行了一次试验,即没有进行重复试验,其试验结果(用Fail表示)和27种水平组合见表2。

表2 三个3水平因素水平全面组合条件下纱线寿命数据
2.2 结果变量Fail的频数分布
表2中结果变量Fail的频数分布见图1。由图1可知,结果变量Fail呈极严重的正偏态分布。
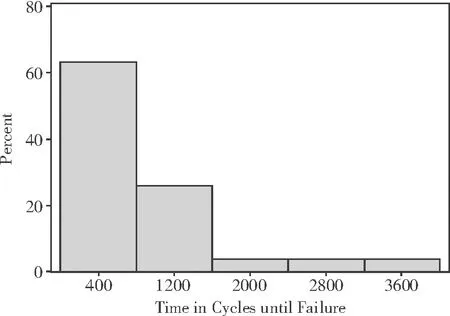
图1 结果变量Fail的频数分布直方图
2.3 需解决的问题及困难
上述样例的专业问题实际上就是一个具有三因素析因设计结构的一元计量资料的统计处理问题。由于在因素各水平组合条件下未进行重复试验,所以,表2中的“安排”不能被称为一个“标准的析因设计”,而只能叫做具有“析因结构”。统计处理的困难在于:其一,结果变量偏离正态分布很远;其二,未进行重复试验,样本含量严重不足,无法分析因素之间可能存在的交互作用效应的大小。
2.4 统计分析的任务
一般来说,在多因素试验研究场合,当结果变量为计量变量时,统计分析的任务是研究哪些因素对结果的影响是主要的、哪些是次要的;因素之间各级交互作用的效应大小;有时,研究者还希望求出“理想试验点”,即在多个试验因素分别取什么样的水平组合条件下,所得到的试验结果在专业上是最满意的。就本例而言,在什么样的试验条件下,纱线的寿命最长(它属于“高优指标”)。
2.5 解决上述困难的策略
第一,可以对计量因变量采取BOX-COX变换,使其服从或近似服从正态分布[5-6]。第二,可以对定性自变量(即试验因素)采取变量扩展变换,例如“CLASS变换”或“POINT变换”或“EPOINT变换”或“QPOINT变换”[5]。实际上,前述提及的那些“变量扩展变换”类似于将定性变量数量化,也就是给定性变量的水平重新编码,并引入交互作用项。第三,将原本属于“方差分析的任务”改换为“回归分析任务”,即构建变换后的因变量关于变量扩展变换产生的自变量的回归模型。第四,借助“结合分析”[7-8]的思路和方法,获得各试验因素对结果变量的“重要性”评价及试验因素各水平的“分值效用”大小,得出“理想试验点(即全部因素最佳的水平组合对应的试验条件)”。
3 数据集的形成与上述策略的实现
3.1 数据集的形成
利用以下SAS程序,可以形成待分析的SAS数据集:
proc format;
value a -1=80 =9 1=10;
value l -1=250 0=300 1=350;
value o -1=40 0=45 1=50;
run;
data yarn;
input Fail Amplitude Length Load @@;
format amplitude a. length l. load o.;
label fail = 'Time in Cycles until Failure';
datalines;

674-1-1-1370-1-10292-1-113380-1-12660-102100-111701-1-11181-10901-111414-10-11198-100634-101102200-162000043800144210-13321002201013636-11-13184-1102000-111156801-11070010566011114011-1884110360111
;
run;
3.2 显示结果变量Fail的频数分布
利用以下SAS程序,可以直方图形式呈现结果变量Fail的频数分布情况:
proc univariate data=yarn normal;
var fail;
histogram fail;
run;
以上程序运行的结果如图1所示。
3.3 对因变量和自变量进行变量变换
对结果变量Fail进行BOX-COX变换,同时,对定性自变量进行QPOINT变量扩展变换。所需要的SAS程序如下:
ods graphics on;
proc transreg details data=yarn ss2 utilities
plots=(transformation(dependent) obp);
model BoxCox(fail / convenientlambda=-2 to 2 by 0.05) =
qpoint(length amplitude load);
output out=aaa approximations;
run;
【SAS程序说明】“proc transreg”调用TRANSREG过程;“model语句”等号左边为对因变量Fail进行“BOX-COX变换”,此变换的一个关键参数叫做“lambda”,经过尝试,需在(-2,2)范围内按步长为0.05去选择具体的lambda值并代入计算,选择使对数似然函数取最大值时的lambda值。当此值带有很多位小数时,尽可能取一个简约的数值(即“convenient”的含义)。“qpoint变量扩展变换”是对三个定性变量进行二次反应面变换,即在三个定性变量的基础上,增加它们的平方项和二次交叉乘积项。
3.4 显示对因变量Fail进行BOX-COX变换的结果
利用以下SAS程序,可以直方图形式显示对因变量Fail进行BOX-COX变换的结果(注:tfail是对变量fail采用BOX-COX变量变换后的变量)。
proc univariate data=aaa normal;
var tfail;
histogram tfail/normal;
run;
以上SAS程序的输出结果见图2:

图2 经过BOX-COX变换后的结果变量tfail的频数分布直方图
对变换后的因变量tfail进行假设检验,所得结果如下:

Goodness-of-FitTestsforNormalDistribution检验统计量PKolmogorov-SmirnovD0.08312402Pr>D>0.150Cramer-vonMisesW-Sq0.02172925Pr>W-Sq>0.250Anderson-DarlingA-Sq0.13498929Pr>A-Sq>0.250
由图2和以上关于正态性检验结果可知,经过BOX-COX变换后的结果变量tfail服从正态分布。
3.5 上述“model语句”输出的结果
上述“model语句”实际上创建了一个经BOX-COX变换后的因变量tfail关于经QPOINT变量扩展变换后的三个定性自变量及其所有二次项的“二次反应曲面回归模型”。见图3。
由图3中倒数第2列可知,三个试验因素的主效应项(即一次项)都具有统计学意义;而由它们产生的所有二次项都没有统计学意义。

图3 二次反应曲面回归模型的参数估计与假设检验结果
反映回归模型对资料拟合效果的输出结果如下:

RootMSE0.19383R-Square0.9725DependentMean6.33466AdjR-Sq0.9579CoeffVar3.05987Lambda0.0000
以上结果表明:模型对资料的拟合效果较好,R2=0.9725,校正的R2=0.9579。
3.6 寻求更简约的回归模型及结果
利用以下SAS程序,可以获得更简约的回归模型。
proc transreg details data=yarn ss2 utilities
plots=(transformation(dependent) obp);
model BoxCox(fail / convenientlambda=-2 to 2 by 0.05) =
class(length amplitude load/zero=sum);output out=aaa approximations;
run;
简约回归模型的输出结果见图4。

图4 仅含主效应回归模型的参数估计与假设检验结果
由图4可知,三个试验因素都有3个水平,都以中间水平为“基准”,除中间水平无统计学意义外,其他均有统计学意义。
反映回归模型对资料拟合效果的输出结果如下:

RootMSE0.18942R-Square0.9691DependentMean6.33466AdjR-Sq0.9598CoeffVar2.99029Lambda0.0000
以上结果表明:模型对资料的拟合效果较好,R2=0.9691,校正的R2=0.9598。
与前面的结果相比,简约回归模型比复杂回归模型的R2略低,但校正的R2反而略高。
关于各试验因素的“重要性”和“效用值”的输出结果见图5。由图5第4列可知,三个试验因素的重要性分别为:纱线测试样品的长度(A)占44.851%、负载循环时的振幅大小(B)占34.000%,负载量(C)占21.149%。由图5第2列可知,“Utility”为各试验因素的各水平的“效用值”,当结果变量属于“高优指标”时,将各试验因素正的最大效用值对应的“水平”组合在一起,就构成了“理想试验点”。就本例而言,在理想试验点为“length 350”“Amplitude 8”和“Load 40”所构成的试验条件下,即当纱线长度取350 mm、振幅取8 mmd和负载量取40 g时,纱线寿命最长。

图5 各试验因素的“重要性”及其各水平的“效用值”的输出结果
4 讨论与小结
在多因素试验研究中,要了解各因素对试验结果的影响情况,特别是因素之间各级交互作用的效应,最合适的试验设计类型为多因素析因设计。然而,多因素析因设计至少应满足两个特点:第一,全部试验点应该由所有试验因素水平的全面组合而成;第二,在各试验点条件下,至少要做两次独立重复试验。本文中的样例满足了前面提及的第一点,但不满足第二点,严格来说,此样例在试验设计上是存在瑕疵的。
通常的方差分析或多重回归分析对资料都有很高的要求,例如正态性和方差齐性等。样例中的因变量呈严重的正偏态分布,通过采用BOX-COX变换,使其偏斜情况得到了很好的校正。将结合分析与回归分析有机地结合在一起,不仅可以获得各试验因素对试验结果影响情况的分析结果,还能获得关于各试验因素重要性的评价以及确定出理想的试验点。
SAS中的TRANSREG过程具有很强且多样性的变量变换能力,它集方差分析、回归分析和结合分析于一体,能够很好地处理不符合传统统计学要求的复杂资料,获得满意的统计分析结果。
