一种基于Bilinear-HashNet网络的车型识别方法
2019-08-13费东炜
费东炜,孙 涵
(南京航空航天大学计算机科学与技术学院,南京210016)
E-mail:in4ight@nuaa.edu.cn
1 引言
车型识别技术[1]是以计算机视觉、模式识别技术为基础,通过监控摄像头、车载摄像头等方式对目标车辆进行拍照采样,完成对车辆的品牌、型号进行识别的一种技术.目前绝大多数车型识别是基于分类的方法,本文则提出一种基于检索的方法,得到与目标图像相似的一批图像,然后根据其标签进行识别.
基于分类的车型识别方法主要分为两类.一类是基于浅层学习的方法,通过局部特征提取、特征描述、特征编码、分类这四个步骤进行车辆识别[2].局部特征提取这一步需要将图像中富含信息的部分抽取出来,主要有两种方式:一种是基于关键点检测,有 Harris角点检测[3]、FAST 算子[4]、LoG[5]、DoG[6]等方法;另一种是密集提取,直接按照一定的步长和尺度指定关键点.特征描述则将关键点附近的图像特征转换为特征描述子,特征描述子一般的形式为特征向量或二进制串,常用的特征描述子有 SIFT[6]、SURF[7]、BRISK[8]、ORB[9]等.特征编码则是通过特征变换方法对特征描述子进行编码,从而获得更高可分性和鲁棒性的特征表达,主要的特征编码方法有向量量化、稀疏编码、Fisher向量编码等.从图像中提取特征表达之后,特定目标可以用一个固定维度的特征向量表示,最后训练一个分类器对这些特征向量进行分类.常用的分类器有支持向量机(SVM)[10]、K 近邻、随机森林[11]、神经网络等方法.
另一类方法是基于深度学习的方法.相对于浅层学习使用手工特征进行图像特征描述,深度学习则将特征提取也纳入学习范围.由于深度学习能够通过大量数据学习到从底层到高层的抽象特征,因此其准确率相比浅层学习的方法有大幅提高.目前主流的深度学习方法有自动编码器、受限玻尔兹曼机、卷积神经网络等.其中应用最广泛的是卷积神经网络.常见的卷积神经网络有 AlexNet[12]、VGG、GoogleNet[13]、ResNet[14]等.
本文提出的车型识别方法则是基于检索的方法.检索指的是最近邻搜索,即查询与输入数据最接近的一条或一组数据.哈希是一种被广泛研究的解决最近邻搜索问题的方法,它将数据转换为低维表示,这种低维表示指的是一串二进制数,称为哈希码(hash code).用于图像特征表示的哈希方法有两类[15],一类是局部敏感哈希(locality sensitive hashing,LSH),另一类是哈希学习(learning to hashing).目前主流的方法是哈希学习方法,哈希学习是通过机器学习机制将数据映射成二进制串的形式.
本文提出一种基于哈希检索的车型识别方法,改进了HashNet深度哈希网络,引入了双线性模块,提出了Bilinear-HashNet网络.经过实验对比,检索图像的平均准确度提高了20.2%.另外,基于分类的方法无法分类未训练和标记的数据类型,而本文提出的方法能够分类未训练和标记的数据,对未训练的数据Top1准确率为81.6%.
2 相关研究
2.1 HashNet深度哈希网络
2.1.1 HashNet网络结构
HashNet[16]是一种 深 度 哈 希(deep hashing) 网 络,由Zhangjie Cao等人于2017年提出,如图1所示.HashNet网络主要由三部分组成:
1)卷积神经网络(CNN)层,用于学习图像的深度特征;
2)全连接的哈希层,首先将深度特征转换为k维的特征表示,再将k维的特征表示转换为k位二进制哈希码;
3)配对(pairwise)损失层,使用带权重的交叉熵损失函数进行相似性保持学习.
与一般的卷积神经网络不同的是,HashNet训练时具有两个并列的输入层,输入两幅图像及其标签.这两幅图像经过图像拼接层在channel维度上合并为一层作为第一个卷积层的输入.HashNet的卷积神经网络层使用AlexNet的前7层(分别是Conv1-5、fc6、fc7)来学习车辆图像的深度特征.这些特征在全连接的哈希层被转换为k位的二进制哈希码.由于输入的是两幅图像,需要将输出的哈希码结果经过slice_output层分离成各个图像各自的哈希码,再输入到配对损失层,同时两幅图像各自的标签也被送入配对损失层进行训练.

图1 HashNet网络结构图Fig.1 HashNet structure diagram
2.1.2 损失函数
HashNet网络训练时将问题转换成两幅图像是否相似的二分类问题.作为二分类问题,最常用的方法是逻辑回归(Logistic Regression)分类器.应用到HashNet中,分类器的输入为两幅图像的哈希码.对于二进制哈希码,一般采用汉明距离(Hamming distance)来衡量哈希码之间的相似程度,距离越大表示哈希码越不相似.由于汉明距离与内积之间存在这样的转换公式:

其中σ(x)=1/(1+e-αx)是自适应sigmoid函数,α是控制其带宽的超参数.α一般设置为10/k,k是哈希码的位数.这样设置使得反向传播效率比α=1的sigmoid函数高很多.

2.1.3 连续性训练方法
HashNet将k维的特征表示通过sgn函数转换为k位的哈希码,sgn函数定义如式(5):,其中 K 为哈希码的位数.分类器的输入可以采用哈希码之间的内积,内积越大表示相似度越高.

在HashNet中,由于数据集中不相似的数据远远多于相似的数据,逻辑回归分类器遇到了严重的数据不平衡问题.在这里HashNet采用带权重的最大似然函数来解决这一问题.给定相似标签S={Sij},N个训练数据的哈希码H=[hi,…,hN]的带权重的最大似然估计为其中P(S|H)是带权重的似然函数,sij表示一对数据的相似性,有两个可能值,0表示不相似,1表示相似,wij是一对数据的权重.为了解决相似数据与不相似数据之间的数据不平衡问题,wij设置为:
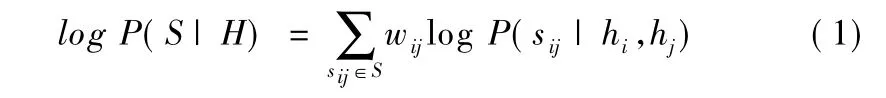

这里β>0是超参数,通过增加β,可以使目标函数越来越逼近sgn函数.训练过程中,一般设置β的初始值为1,每经过一定步长以指数形式增加β,使用tanh(βtz)激活函数训练HashNet,再将训练好的权值用于初始化以tanh(βt+1z)为激活函数的HashNet.一般循环这一过程10次即可得到收敛.
2.2 双线性卷积神经网络(B-CNN)
双线性卷积神经网络[17]是2015年由Tsung-Yu Lin等人提出的,主要用于精细粒度分类.它的主要思想是将图像经过两个卷积神经网络后提取到的不同特征经过池化、矩阵外积的操作结合成双线性特征向量.
由于sgn函数是不连续的而且非凸,普通的反向传播方法不可行.HashNet训练时采用连续的tanh函数,通过调整参数在训练中逐渐逼近sgn函数,具体的原理如式(6):
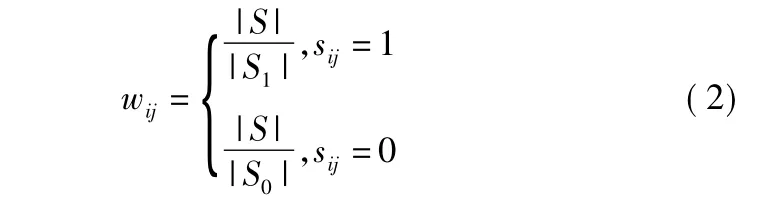
其中S1是相似数据对的集合,S0是不相似数据对的集合.
对于每一对数据,P(sij|hi,hj)指的是给定哈希码hi和hj情况下相似性标签sij的条件概率,定义如式(3):
双线性分类模型分为4个部分fA、fB、P、C,前两个部分是fA、fB是特征函数.特征函数是一个映射 f:L×I→Rc×D,I是图像数据,L是图像中的位置,输出为c×D的特征向量.fA、fB两个特征函数的在位置L的输出通过矩阵外积结合成双线性特征(bilinear feature),双线性特征定义为 bilinear(L,I,fA,fB)=fA(I,L)TfB(I,L).P是池化函数,它将图像各个位置的双线性特征编码成一个特征,一般采用和池化(sum-pooling).C是分类函数,在卷积神经网络中一般采用softmax函数进行分类.
总而言之,管理会计和财务会计是目前企业发展过程当中不可或缺的重要组成部分,只有很好地了解企业的运行情况、收集企业发展的重要信息以及降低经营风险才能够更好地应对以后的风险。所以,在新经济的发展过程当中,财务会计以及管理会计的融合就成为企业管理体系当中的重要问题。企业相关的管理人员不仅要在思想上进行改变,而且更要从企业发展过程当中的细节上考虑,只有这样才能够增强企业的经济效益和市场的竞争力。
在B-CNN中,特征函数fA、fB均为卷积神经网络.在双线性池化之后,还要进行归一化操作.首先将双线性特征进行符号平方根(signed square root)运算,即再进行l2归一化,即z=y/‖y‖2.
B-CNN的反向传播也比较容易理解.假设两个网络的输出分别为矩阵A和B,大小分别为L×M和L×N,则池化后的双线性特征为x=ATB,大小为M×N.令dL/dx为损失函数L关于x的梯度,应用链式法则可得:

再结合卷积神经网络的反向传播,即可学习B-CNN网络.
双线性卷积神经网络有两类,一类是不对称的,即fA、fB采用不同的卷积神经网络结构,另一类是对称的,即fA、fB为相同的卷积神经网络结构.对称的网络具有一个性质,一旦初始化为对称的网络之后,在训练之后依然保持对称.因此,对称的B-CNN可以简化为仅实现一个CNN网络,可以带来极大的效率提高,同时分类准确率的降低很小.文献[18]对不对称的B-CNN进行可视化,发现两个不同模型学习到的部分是类似的,说明两个模型的角色并没有显著分开,因此使用对称的B-CNN模型时性能下降在可接受范围内.
双线性分类模型之所以具有精细粒度分类的能力,是因为用双线性池化来进行特征编码,可以得到比卷积神经网络的全连接层更具可分性的特征向量.经过实验对比,使用同样的深度网络提取特征的情况下,双线性池化比神经网络全连接层和Fisher向量编码性能更高.
3 Bilinear-HashNet网络模型
3.1 HashNet网络的改进
3.1.1 改进卷积层
HashNet使用AlexNet的卷积层作为特征提取层.Bilinear-HashNet网络用VGG-16的卷积层替换了AlexNet部分.VGG-16网络相比AlexNet具有更深的层,能够更好地表达图像特征,在分类任务上错误率更低,用于深度哈希网络中能够生成更具有可分性的哈希码.
3.1.2 用双线性模块替换了全连接层
分类用的卷积神经网络,如AlexNet、VGG,以及HashNet均使用全连接层对卷积层提取的特征进行编码.全连接层对于普通的分类和检索任务表现很好,但是对于车型识别这种类之间差异较小的应用上,全连接层的特征编码性能不足,不能够生成足够可分性的特征向量,成为了这类任务的瓶颈.
Bilinear-HashNet网络借鉴了双线性卷积神经网络的思想,将HashNet网络哈希层前的全连接层替换为双线性模块.双线性模块包括双线性池化层、归一化层.双线性池化层的输入为两个矩阵.当两个输入不同时,需要神经网络具有两组不同的卷积层,这是非对称的双线性卷积神经网络.当两个输入相同时,仅需要一组卷积层,这是对称的双线性卷积神经网络.使用对称的双线性模块,只需要替换HashNet中的全连接层,相当于替换了HashNet中的特征编码方法.使用双线性模块可以将卷积层提取的特征编码为具有高可分性的特征向量,根据优化后的特征向量可以生成更具可分性的哈希码.
3.2 Bilinear-HashNet网络结构
本文提出的Bilinear-HashNet网络在HashNet网络基础上,引入了双线性模块,实现了对于车辆等精细粒度目标的高性能检索.其网络结构如图2所示.
基于HashNet的改进主要是将HashNet中的卷积神经网络替换成VGG-16,并将全连接层替换为双线性模块.双线性模块的输入为对称的VGG-16网络的卷积层,仅需一组卷积层.Bilinear-HashNet没有采用两个不同深度的网络,是因为不对称的双线性模型速度更慢,相比使用单个较深的网络性能提升较小.
该网络输入图像的大小为448×448,图像经过所有卷积层之后输出的特征图为512通道的,大小为27×27.再将该特征图输入到双线性模块,分别进行双线性池化和归一化,得到8192维实数特征.最后将实数特征输入到哈希层,转换为k 位哈希码,k 为用户设定值,一般为 48、64、80、96.5.2 节中实验展示了不同位数哈希码对于检索和分类性能的影响.
3.3 网络的优化和调参
Bilinear-HashNet的训练分3步.第1步是根据ImageNet预训练模型训练双线性模块的最后一层,第2步则是根据第一步的结果训练整个双线性模块.前两步的训练方法是,构建双线性模块的分类网络,以softmax损失函数为目标进行优化.第3步是以第2步训练出来的模型为基础,单独训练哈希表示层.
Bilinear-HashNet的训练每一步骤均采用带momentum的随机梯度下降方法.根据文献[19]所述,momentum参数均设置为0.9.批处理数量(batch size)在GPU内存允许范围内应尽量调大,但不宜超过256.批处理数量太大会导致Bilinear-HashNet网络的收敛更慢.
第1步只训练双线性池化层,学习率一般调的较大,初始学习率一般设为1.0.由于要训练的权值数量较小,权值衰减参数要调低,一般设为0.000005.
第2步训练整个双线性模块,学习率要设置的小一些,根据不同数据集,初始学习率应设置在10e-4到10e-5之间.权值衰减设为标准值0.0005即可.
第3步训练哈希表示层,学习率也应设置的小一些.由于只训练哈希相关的层,权值衰减参数要设置的小一些,一般设为 0.000005.
4 基于Bilinear-HashNet网络的车型识别方法
Bilinear-HashNet网络相当于一个哈希函数,将车辆图片转换为二进制哈希码.通过计算两幅图像哈希码之间的汉明距离可以得到两幅图像之间的相似度.根据这一性质,可以实现相似车辆图片检索.首先,将一部分有标签的车辆图像作为查询库,先计算这些图像的哈希码,存储在文件或数据库中.然后,输入要检索的车辆图像,计算该图像的哈希码,与查询库中保存的哈希码进行匹配,得到与检索图像最相似的一批车辆图像.
在相似车辆图片检索基础上,分析返回的一批车辆图像,当返回图像中某一类的车辆图像占比最多,就将查询图像分类到这一类中,从而实现车型识别.
相比直接训练分类用的卷积神经网络,基于Bilinear-HashNet网络的车型识别方法的主要创新点在于能够识别在训练过程中未见过的数据类型.只需要计算这些未训练数据的哈希码,存储到查询库中,就能对这些类的车辆图片进行分类、识别.应用中,未训练数据类型数一般小于已训练数据类型数,主要用途是在新增最近车型数据时不用重新训练模型.如果未训练数据类型数多于已训练数据类型数,建议重新训练模型以获得更好的效果.
5 实验结果与分析
5.1 实验过程
实验选取了CompCars数据集进行训练和测试,该数据集包含各种视角下的车辆图片.数据集图片示例如图3所示.
CompCars数据集有163个车系,每个车系下分为不同车型,每个车型又分为不同年代.本文按照车型对原始数据集进行处理,将年代不同且车型相同的车辆看做同一个类.并且,忽略小于100张图片的车型类.处理后的数据集具有841个类.
然后,将这841个类分为700类和141类,700类用于训练和测试,141类用于测试车型识别方法对于未训练的数据类型的性能.其中,700类又被分为训练集和验证集,验证集的图片从每类中随机抽取30张,共计21000张图片,训练集则包含65179张图片.
Bilinear-HashNet网络的训练方法按3.2节所述分为三步.第一步训练双线性池化层,学习率设为1.0,直到损失不再下降.第二步训练整个双线性模块,初始学习率设为0.00005,每当损失不再下降时,将学习率减小为初始学习率的1/10.第三层训练哈希层,学习率的设定与第二步相同.
实验采取MAP、avg_p@8、Top1准确率三个指标来评价网络的性能.MAP(mean average precision)是常用的评价检索系统性能的指标,其中,AP(average precision)反映的是一次检索中不同召回率下准确率的平均值,MAP则是每次检索的AP值的平均.在本文设计的检索系统中,输入目标车辆图片,会返回8张相似图片.然后分析这些图片的类型,哪一类的数量大,就将目标车辆图片分类到这一类中.评价指标avg_p@8是每次检索返回的前8张图片的平均准确率.Top1准确率是上述方法进行分类后得到的第一个类别的准确率.
Bilinear-HashNet网络生成的哈希码的位数可以在训练网络时指定.本文选取了 48bits、64bits、80bits、96bits四种不同哈希码位数进行实验.
5.2 实验结果
对于已训练数据类型,Bilinear-HashNet(BHN)网络和HashNet网络在车型识别系统中的性能如表1所示.
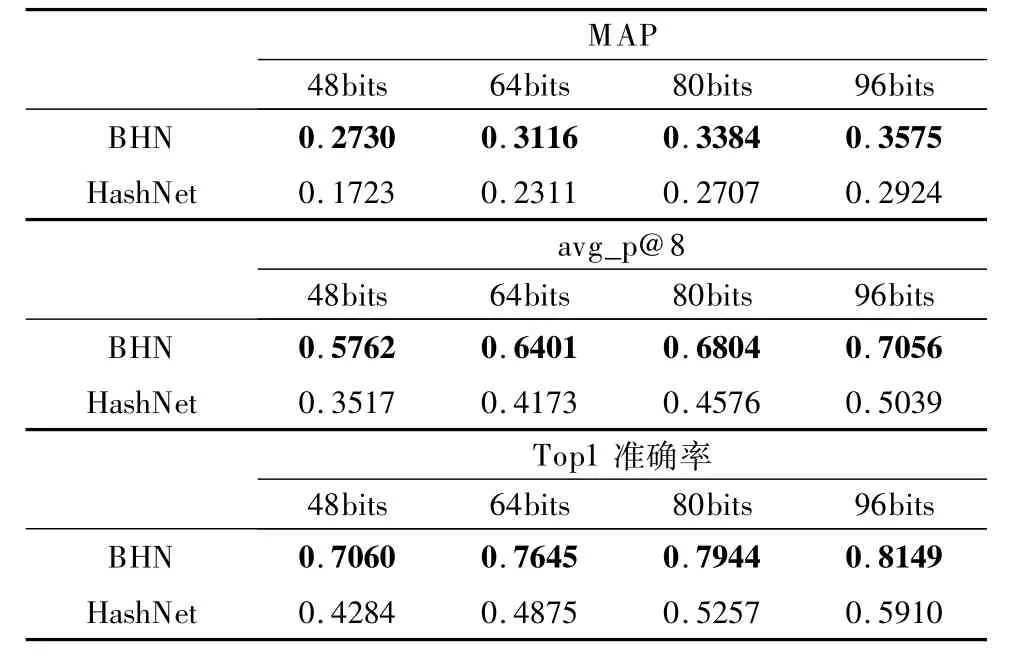
表1 已训练数据类型实验结果Table 1 Experiment results of trained data

表2 未训练数据类型实验结果Table 2 Experiment results of untrained data
对于未训练的数据,两种方法的性能如表2所示.
5.3 结果分析
从实验结果可以得出,在相同的哈希码位数下,Bilinear-HashNet的性能均比HashNet好.其中96bits的实验中,Bilinear HashNet对于已训练数据和未训练数据分别获得了81.5%和81.6%的 Top1准确率,相比HashNet分别提升了22.4%和24.4%.其他评价指标上,Bilinear-HashNet的 avg_p@8和MAP也远远好于HashNet.
Bilinear-HashNet网络在已训练和未训练的数据的Top1准确率相近,在80bits和96bits的实验中,未训练的数据比已训练数据的Top1准确率有微小的提升,在avg_p@8和MAP上未训练的数据比已训练的数据略低.说明本文提出的方法能够用于未训练数据类型的分类、检索,且Bilinear-HashNet网络未出现过拟合现象.未训练数据的Top1准确率和已训练数据相近,甚至准确率更高,这反映了Bilinear-HashNet深度哈希网络从原理上可以理解为特征函数,对于未训练的数据类型仍能够有效的提取特征,因为车型识别任务所需要的图像特征提取方式已经被网络学习到了.而且,先检索一组相似图像,再通过投票的方法进行分类,使得错误的检索结果一般不会重复出现,而正确的相似图片会多次出现,因此未训练数据在avg_p@8和MAP这两个指标略微降低的情况下,Top1准确率仍然会很高.
对于不同的哈希码位数,Bilinear-HashNet的性能随着位数增加而提高,位数越大,再增加哈希码位数所获得的精度提升就越小.实验证明,输出96位哈希码可以取得速度与精度的平衡.
使用深度哈希网络生成图片的哈希码,可以获得对未训练数据进行分类的能力,不过相比分类用的深度神经网络,对于已训练的数据必然有特征信息的损失,需要一定的哈希码位数才能获得近似的性能.未来将对于深度哈希网络的哈希层和损失函数进行进一步研究,使得网络可以用更少的哈希码提取相同信息的特征.
6 结论
本文提出了Bilinear-HashNet深度哈希网络,该网络可以提取目标图像的特征并转换为哈希码.基于这一网络,本文还提出了一种车型识别方法,其主要优点是可以通过将新的车型数据添加到数据库中的方法来实现对未训练图像的分类.实验显示,本文提出的方法在CompCars数据集上对于已训练和未训练数据的Top1分类准确率分别能够达到81.5%和81.6%,相比 HashNet分别提高了22.4%和24.4%.
