基于Hadoop 平台的招聘数据分析
2019-08-12武晓军陈怡丹赵青杉
武晓军,陈怡丹,赵青杉
(1.忻州师范学院计算机系,忻州034000;2.河南广播电视大学信息工程学院,郑州450008)
0 引言
随着互联网的快速发展,大量的人才招聘信息发布到互联网上,形成了大量的具有异构性的非结构化数据。对这些数据做有效的分析对行业的发展具有一定的引导作用。非结构化数据在数据处理阶段具有一定的困难,大量数据在分析阶段具有分析能力的不足,性能不足等缺点。文献[1]就3 个招聘平台数据近8 万条计算机行业招聘数据进行聚类分析,并统计每一种岗位的市场需求,并计算出与岗位相关的其他维度信息的相关系数。文献[2]就4 个招聘网站数据进行分析,对招聘信息采用二维隐马尔科夫模型进行分割,得到招聘信息中岗位、企业名称、企业类型等关键词。文献[3]对爬取的50 万条数据进行分析,通过数据预处理、特征词选取、词袋构造,利用奇异值分解法(SVD)对文本矩阵降维,利用聚类算法挖掘行业信息。文献[4]利用Hadoop 平台进行网络舆情数据分析。文献[5]利用Hadoop 平台对葡萄酒数据信息进行分析,文献[6]基于Hadoop 平台对商业银行数据进行分析。Hadoop技术逐步成为比较完整的分析技术,针对传统数据分析的计算能力弱,并行性低等问题,提出了基于Hadoop平台的招聘数据分析与研究,对近2000 万条计算机行业招聘数据进行分析。
1 相关技术
1.1 HDFS分布式文件系统
HDFS 文件系统采用了主从架构,由一个主节点和部分数据节点组成。主节点主要负责文件系统中数据元的存储管理工作,具体包括存储地址的选择、命名空间及各节点的访问权限和各数据块间的关系等。数据节点负责具体数据块的存储于管理工作。具体包括数据块的创建,数据的读写以及向主节点反馈信息。当需要存储的数据文件较大时,HDFS 会将文件数据分割为独立的数据块,由主节点主导,将数据块发送到数据节点中并存储,各数据节点种数据块的储信息存储则保存在主节点中。主节点负责调用执行数据节点,数据节点不定期将更新的数据反馈给主节点。
1.2 MapReduce编程模型
MapReduce 执行过程包含两个阶段,Map 阶段与Reduce 阶段[7],Map 为映射阶段,Reduce 为归约阶段。首先由主节点输入文件,执行Split 操作,再执行Map操作将文件解析为<key,value>格式,并将中间数据存入节点的缓存空间,定期存写入本地磁盘且被划分为R 个区,每个区对应于一个Reduce 作业,执行Reduce操作前可对分区数据进行排序以及合并。所有数据均来自底层文件系统,执行过程产生的临时数据存储于当前节点的文件系统中,执行结果最终存储于底层分布式文件系统中。
2 分析系统的设计与实现
2.1 分析平台系统架构
将大数据技术与数据挖掘技术应用到招聘数据的分析中,实现了基于Hadoop 平台的招聘数据分析平台,如图1 所示,分析平台包括数据采集、文本处理、分析与展示四大模块。
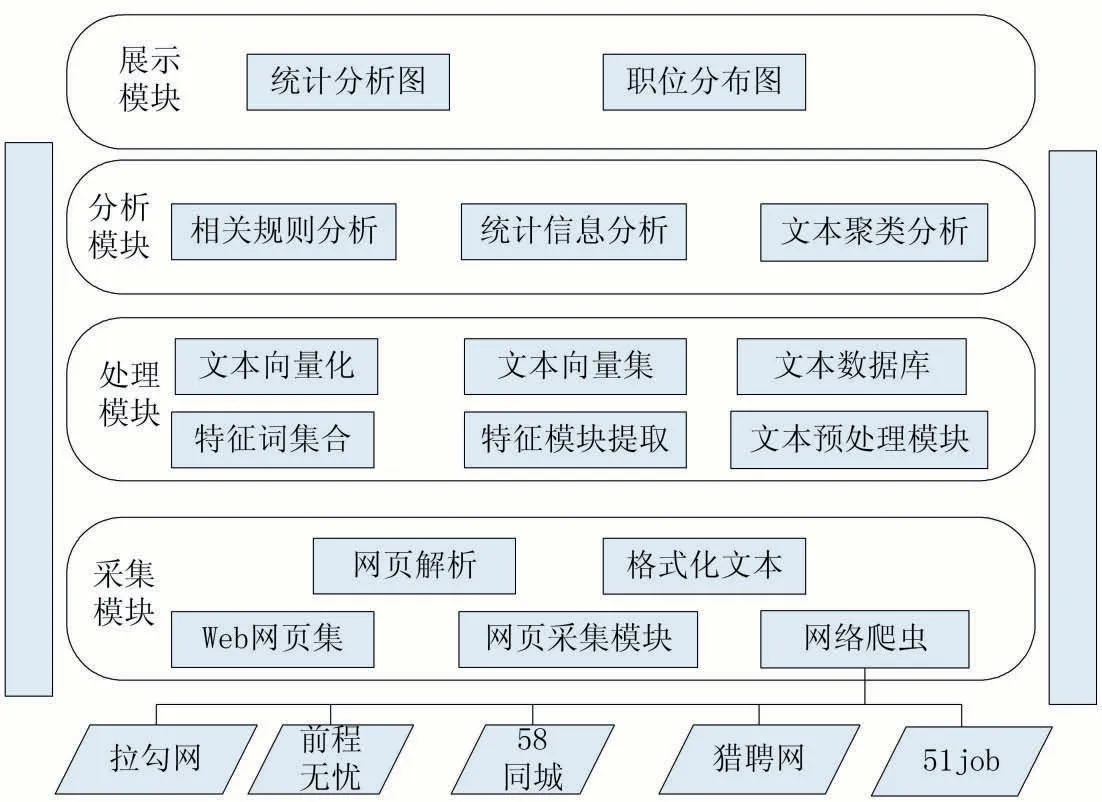
图1 平台架构图
信息采集模块主要是利用网络爬虫从各大在线招聘平台等Web 页面采集相关招聘信息,需要保证数据的全面性与准确性。数据采集成功以后需要对数据进行基本去噪与基本格式化处理,并使用统一接口将格式化数据存储于数据库中。
爬取的数据多数为文本格式数据,部分数据存在关键字段数据为空以及重复行的问题,采集的数据组存在部分噪声特征,对词频统计、文本聚类与相关性分析有一定的影响。对部分缺失的文本数据进行补充,对不同网站相同数据进行去重,保证数据的完整性与唯一性。在数据处理模块主要进行特征模块的提取、特征词集合的生成、文本向量化、文本向量集的生成、最后生成文本数据库。
经过数据特征提取与文本向量化处理之后得到数据的文本数据库,将数据发送至其他节点进行存储,数据分析模块主要利用数据挖掘技术进行分析,分别从数据统计角度与不同维度相关性规则挖掘进行分析。
2.2 数据处理
(1)分词
采集到的招聘数据中部分属性需要进行数值化,例如工作经验字符类型:1 年、3 年、不需要,可根据正则表达式进行转化,转化为1、3、0;薪水字符类型:5K、8K、10K 等,可转化为数值型5、8、10。
对文本中包含中文与英文进行分词操作。英文数据采用正则表达式进行分词,中文数据采用jieba 分词模块进行分词,基于前缀词典实现高效的词图扫描,并生成可能生词情况所构成的有向无环图(DAG),再采用动态规划算法查找最大概率的路径,得到词频较最大的分词组合。对于未被录入词典的词,采用基于汉字成语能力的HMM 模型,中文分词结果如图2 所示。

图2 中文分词
(2)分词过滤
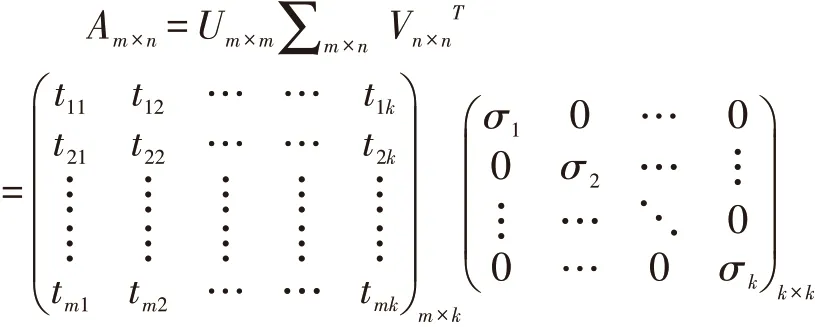
理想条件下,中文分词之后即可对分词进行特征提取,但是由于中文的多音、多义等特点,对特征的提取有一定的困难,主要表现在未被录入词典的词以及部分没有实意的介词,连词,符号等字符。对于词频过高或者过低的停用词来说,没有实际的意义,对文本主题没有影响或者影响较小的词予以过滤,减小信息的存储量,提高信息处理效率,例如“你”、“我”“我们”、“如果”、“因此”等。一般的高频词语噪声词具有一定的相关性,只有在少数情境下,高频词才会被重视。假设TFi表示分词i 的词频,nij表示分词i 在文本j 中出现的次数,则有
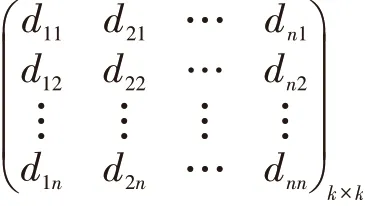
2.3 文本向量化
(1)特征提取
通过文本的特征提取可以使文本向量化,其中特征值的权重与聚类的结果有很大的关系,深度影响着分析结果。逆向文档频率(Inverse Documentation Frequency,IDF)根据分词在文本中的重要程度与文本集中出现的频率有效提取特征的方法。文本分词出现的频率较低,则其区分能力强,分词的权重值越大,其信息熵越大,权重为TF∙IDF(ti,dj)=TFi,j×IDFi,其中ti为文本d 中的某一特征项,wi为该特征项的权值。。逆向文档频率如式(1)所示,N 表示文本总数,ni表示分词在文本中出现的次数。每一个文本用向量表示,每一个特征项可表示向量的一个维度,特征项在文本中的权重值用向量取值表示例如文本的空间向量为V(d)=(wi)n×1。

(2)语义空间降维
将文本分词抽取特征词之后可形成多个特征项,可构建一个特征词词典。招聘文本根据特征词典对应的坐标可转化为一个同维度文本向量,可构建词汇-文本矩阵。文本矩阵元素个数较大,计算量大,所得特征也无法准确诠释自然语言的表达。为了解决文本特征向量的高维问题,需要对高维向量进行降维处理。对任意矩阵均可采用奇异值分解[8],假设文本矩阵为Am×n, 按 照 奇 异 值 分 解 定 理 可 得Am×n=Um×m∑m×n,其中U 为m×m 的酉矩阵,每一个非零元素表示词的重要程度,∑为m×n 的对角矩阵,表示特征词与文本的相关性,VT为n×n 的酉矩阵,可视为文本矩阵。在对角矩阵中通过删除奇异值小的元素,保留奇异值大的元素,得到A 文本矩阵的近似矩阵 Ak×k矩 阵,从 而 达 到 对 矩 阵 的 降 维,其中
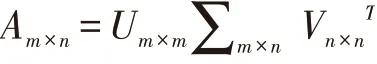
3 实验与结果分析
实验平台采用4 台普通PC 集成搭建,Master 节点为4 核8 线程,8G 内存,IP 为172.16.0.15,安装zookeeper 与yarn 软件,主机名为Hadoop1;3 台Slave 节点均为2 核4 线城,4G 内存,IP 分别为172.16.0.18-172.16.0.20,主机名分别为Hadoop2-Hadoop4,安装zookeeper 与yarn 软件。配置所有节点免密通信,且保持所有节点时钟同步。
3.1 关联规则挖掘
关联规则挖掘时,需要对招聘信息中城市级别进行划分,分为一线城市、二线城市、三线城市;需求将公司规模分为50 人以下、50 人-100 人、100-300 人、300人-500 人、500 人以上;将工资待遇转化为月薪分为5K 以下、5K-8K、8K-12K、12K-20K、20K 以上;学历分为博士研究生、硕士研究生及以上、本科及以上、专科;将工作年限分为1 年、2 年、3 年-4 年、5 年-7 年及10年以上。关联规则挖掘采用FP-Growth[9]算法直接从频繁模式树中获取频繁项集,将最小可信度值作为阈值,得出各维度之间的关联规则,整个过程不需要产生候选集,避免了频繁的I/O 操作。
关联规则挖掘部分结果如表1 所示,可知在一线城市,如果拥有两年工作经验,近92%的企业开出的薪资在8K-12K 之间。如硕士毕业生且有工作经验,在一线城市,有88.75%的企业愿意开出12K-20K 之间的薪资。大数据专业的硕士毕业生主要需求地为一线城市。在二线城市,公司规模大部分维持在50-100 人的中小型企业,如果为本科学历,82.72%可能会拿到5K-8K 之间的薪资。
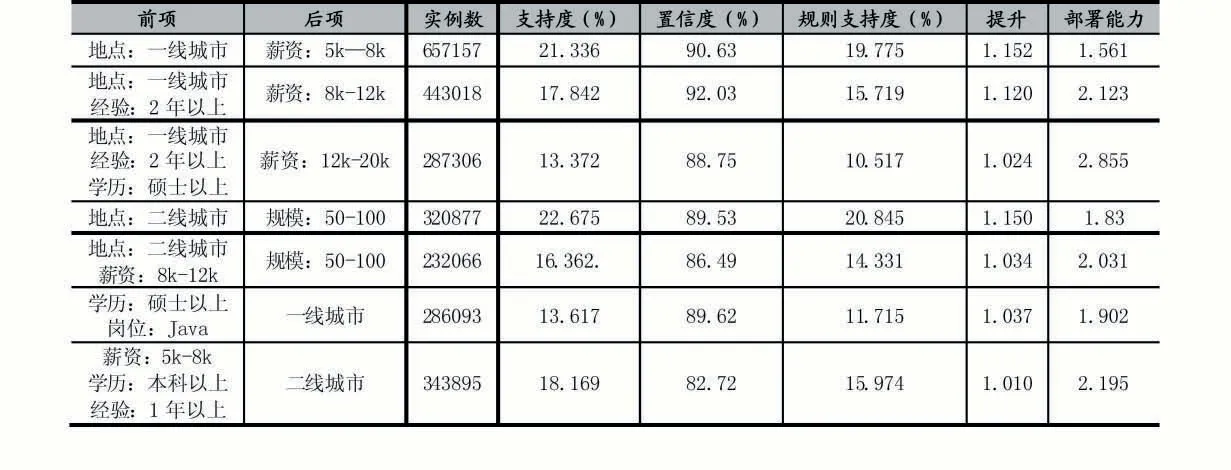
表1 部分关联规则分析结果
3.2 统计分析
平台部分统计数据如图3-图5 所示。有图3 可知,目前近一半的Java 类岗位的学历要求为本科及以上,34.4%的Java 类岗位的学历要求为专科,硕士学历从事Java 类编程岗位的相对较少。由图4 可知,Java类岗位需要10 年以上工作经验的比例较小仅为0.5%,大部分岗位需求的工作经验保持在1 年-4 年之内,占比为69.6%,针对于应届毕业生的岗位不需要工作经验。图5 展示了不同语言编程岗位的中人数与工资数量的统计,由图5 可知,市场需求较大的为Java 语言开发岗位,且Java 与前端的高薪资岗位较多。图6展示了不同岗位需求与薪资的关系,由图可知,目前Java 与前端的岗位需求较大。
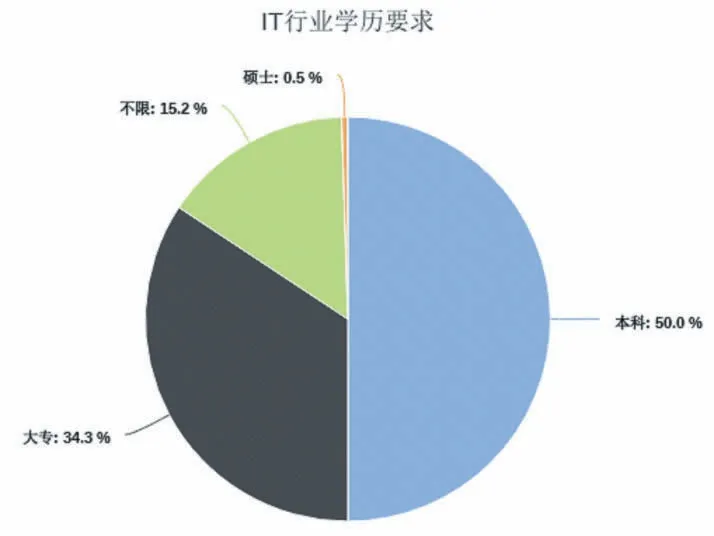
图3 Java类岗位学历要求统计
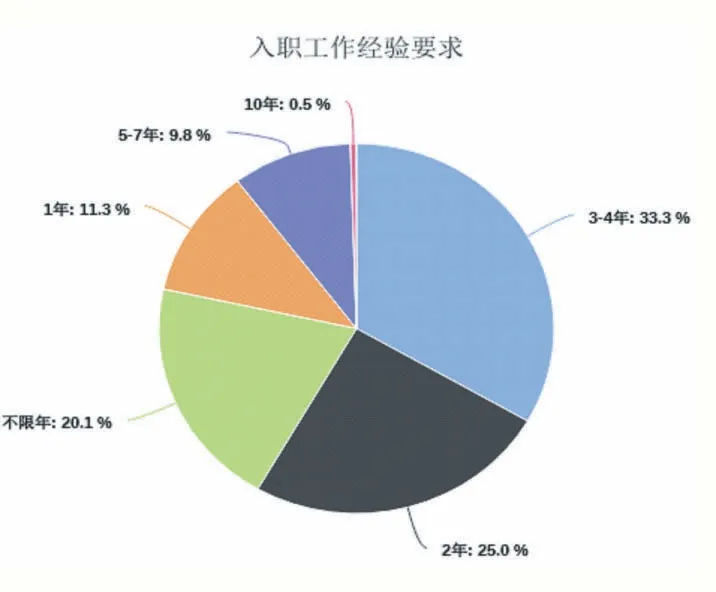
图4 Java类岗位入职经验统计
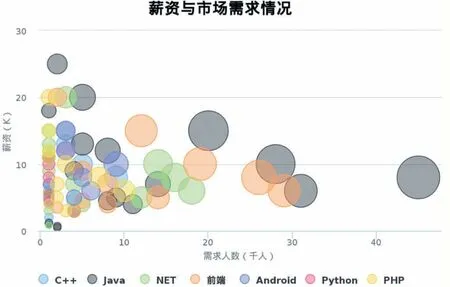
图5 薪资与市场需求统计图
4 结语
本文将离线招聘数据的分析搬迁到Hadoop 平台上,设计与实现了数据分析平台,平台包括数据采集模块、处理模块、分析模块、展示模块。利用FP-Growth关联规则算法对岗位、所需技能、薪资、工作经验等特征维度进行关联规则挖掘,同时利用统计分析法对就业分布、薪资、市场比例等进行分析,形成可视化统计数据。
