融合词性与位置信息改进的Lucene排序算法
2019-08-10苏琴谢卫华
苏琴 谢卫华


摘要:文档检索的相关性是依据用户的搜索需求对搜索结果的一种符合用户期望的排名。为了提高用户对检索系统的满意度,考虑到查询与文档大多由名词和动词组成,而且在不同上下文中词性可以起到语义消岐的作用;另外,考虑到文档的不同字段具有不同的重要程度,因此词位置加权将有效改进检索系统的性能。由于默认的Lucene排序算法未考虑文档不同字段、查询词词性和词性分布对检索相关性排名的影响,因此在Lucene排序算法的基础上,提出一种融合词性与位置信息的改进算法。通过对比实验分析,该改进算法能够有效提升检索系统的性能,相比默认的Lucene排名算法,准确率、召回率与F值都有不同程度的提升。
关键词:BM25算法;信息检索;相关性排序;Lucene;排序算法;垂直搜索
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2019)17-0082-04
开放科学(资源服务)标识码(OSID):
Abstract: The relevance of document retrieval is a ranking of the search results that meets the user's expectations based on the user's search needs. In order to improve the user's satisfaction with the retrieval system, it is considered that the query and the document are mostly composed of nouns and verbs, and parts of speech in different contexts can play the role of semantic disambiguation; in addition, considering that different fields of the document have different importance levels, the word position weighting will effectively improve the performance of the retrieval system. Because the default Lucene ranking algorithm does not consider the influence of different fields of the document, query term part of speech and its distribution on the ranking of search relevance, an improved algorithm combining part of speech and location information is proposed on the basis of Lucene ranking algorithm. Through comparative experiment analysis, the improved algorithm can effectively improve the performance of the retrieval system. Compared with the default Lucene ranking algorithm, the accuracy, recall rate and F value have different degrees of improvement.
Key words: BM25; Information retrieval; Relevance sorting; Lucene; Sorting algorithm; Vertical search
1 引言
在信息检索领域,前人做了大量研究提出了许多算法与框架,例如布尔检索模型[1]、向量空间模型TF-IDF[2]与概率检索框架BM25[3]算法等。Okapi BM25算法目前已经是很多开源框架(Elasticsearch、Solr等)的默认排序算法;该算法在自然语言处理文本加权[4] 、搜索排序等领域有广泛的应用;目前很多商业搜索引擎使用的也是在BM25基础上改进的排序算法。
Lucene是一个高性能、可伸縮的信息检索库[5],具有添加索引和搜索的功能。Lucene自6.0版本起默认相关性排名算法采用基于概率检索框架的BM25算法。在Lucene中,BM25算法通过IDF、文档长度、文档频次、查询词频信息计算查询和文档的相关性,按照文档得分高低对文档排序。相较于基于向量空间模型的TF-IDF算法,BM25算法抑制了高术语频率对整体评分的影响。早期学者对Lucene评分算法做了大量研究,文献[6]将BM25算法应用到个性化排名算法中,讨论了用户的查询术语中名词占据很大比例,因此赋予名词较高的权重以改进检索排名。但是该算法并没有对查询与文档中词性进行统计说明,并且仅仅对名词赋予较高权重可能导致返回结果的相关性有误。文献[7]通过对词位置加权并结合PageRank算法提高搜索精度。文献[8]提出一种改进的向量空间模型,基于文档中术语之间的邻接关系为关键字赋予更多权重,该算法考虑文档中查询术语间的关系进而提升查询结果的相关性。但是该算法只是考虑了局部信息,未将查询术语在文档不同位置的出现信息考虑在内。文献[9-10]基于Lucene的默认排序算法提出一种融合位置和概率排序的改进算法,但是该算法是基于向量空间模型TF-IDF算法的改进,并且该改进算法是一种基于TF-IDF排序算法的基础上的二次排序算法。
词性是根据词的特点划分词类,很多学者对词性进行了研究,提出大量词性标注方法,例如基于决策树的方法[11],基于规则的方法[12]以及基于统计的方法[13]等。考虑到词在不同的上下文中对应不同的词性,每种词性又对应着不同的词义,因此将词性标注引入到信息检索中将实现词义消歧的功能,提高信息检索系统的召回率。一些早期的文献针对词性标注对信息检索系统的影响做了研究,文献[14]认为用户查询术语通常很短因此会产生歧义,因此提出使用词性标注减少查询歧义。文献[15]研究不同词性特征在文本聚类中的贡献度,通过实验发现名词是表征文本内容的重要词性。文献[16]将词性标注加入信息检索,实验发现在信息检索中加入词性标注可能对某些特定Topic和Document的检索结果有所改进。
本文基于上述文献,对Lucene默认的相关性排序算法进行研究,并且针对目前相关性排序算法存在的不足进行改进,提出一种结合词性、词性分布、词位置加权与Lucene默认评分算法的改进的相关性排序算法。文献[17]中提到词性有两种用法:1)对某些词性的词进行索引;2)不同词性的词分开,只让查询文档中词性相同的词能够匹配上。本文所做工作如下:1)对给定垂直检索系统中的数据进行词性标注,并统计各种词性占比,按照词性占比排名添加负载;2)分析垂直搜索系统中数据的词性分布(包括特定字段的词性分布与整体的词性分布);分析查询项的词性分布;根据这些词性分布信息计算每个字段的权重;3)分析给定的垂直检索系统文档的不同字段,按照字段的重要性添加权重,实现词位置加权。
从Lucene的默认评分公式BM25中可以看到,默认相关性计算公式的基本思想是:通过查询词在文档中的频率、逆文档频率、文档长度与两个调优参数对文档的相关性进行打分,得分越高的文档排名越靠前。该算法将文档作为整体考虑,未考虑文档不同字段的重要程度;另外该算法也没有考虑查询词的词性和查询词的词性分布对检索系统的影响。然而在实际的信息检索系统中,例如在电影检索系统中,电影标题往往是主要的检索对象,赋予电影标题字段的权重显然应高于其他字段;名词和动词等词性明显比其他词性出现在文档中的频率更高,也应分别赋予较高的权重。
因此本文对Lucene默认评分算法做一些改进,融合词性与位置信息,提升检索系统的性能。
3 基于Lucene默认排序算法的改进
3.1文档不同字段的权重计算
其中,f(qj)表示查询词qj在wi字段出现的频率,|F|表示字段wi的长度,avgdlf表示平均字段长度。
3.2 与词性分布有关的改
在本文提出的改进中,用户查询时,系统首先引用外部的词性标注工具(Thulac[18],结巴等)对查询项进行词性分析,统计查询字段的词性分布。按照查询时的词性分布、结合系统中文档整体的词性分布与特定字段的词性分布计算每个字段的权重。本文基于词性分布的改进:1)分析查询时的词性分布;2)分析系统中文档的整体词性分布;3)分析不同字段的词性分布;4)计算每个字段的权重。基于词性分布的改进公式如式(6)所示:
其中,qd表示查询时词性分布的占比;d表示系统中文档的整体词性分布的占比;pd表示特定字段的词性分布的占比;field表示文档的不同字段;m表示涉及的词性分类;1.0表示默认权重为1.0。
3.3 词性信息成为评分算法的一部分
Lucene默认计算公式中提供了负载[5](默认负载字段值为1.0),本文将词性信息以负载的形式添加到Lucene默认评分公式中,主要通过对系统中存储文档进行词性分析,为词性占比较高的几种词性添加权重。考虑到如果对所有的词都按照词性添加权重将导致在搜索引擎中占据大量存储空间,因此只对名词和动词添加词性信息。此时默认的Lucene排序算法修改为公式(7)所示:
其中,payloads表示按照词性添加的负载信息;old_score表示式(1)给出的默认的Lucene评分算法的得分。此负载信息是在索引阶段建立,搜索引擎添加数据时分析词性,如果是动词或者名词就按照上面给出的负载添加方式添加负载信息。
3.4 改进的Lucene排序算法
本文在默认排序算法的基础上,对查询词进行词性分析,将词性和位置信息融合到默认Lucene排序算法中。改进的Lucene相关性排序算法如公式(8)所示:
其中,score表示式(7)中结合payloads和默认Lucene排序算法的相关性得分,weight为式(6)给出的相关字段与词性分布有关的权重。WPosition为式(4)中给出的位置信息的权重。关于改进的Lucene排序算法的描述如下:
输入:用户查询;
输出:按照用户查询计算文档排序并返回。
索引阶段:对文档进行词性分析,将名词和动词的权重作为负载添加到倒排索引中;
查询阶段:1)对查询词进行词性分析,按照式(6)计算特定字段的权重;2)利用Lucene的检索功能,在返回结果的基础上按照式(4)计算查询词分布在不同字段的权重;3)根据式(8)获取最终的相关性评分;4)将搜索结果按照相关性评分排序返回。
4 实验结果与分析
本文采用基于Lucene开发的全文检索搜索引擎Elasticsearch进行算法的改进实验,Elasticsearch版本为6.3.2。数据采用从时光网上爬取的四万条电影数据(标题,演员列表,导演,类型,剧情简介等),对这些数据分析、处理后得到实验数据集。首先,从演员、导演和编剧这三个字段中随机选取50条数据作为单人名字段查询项;然后将这50条数据随机组合,产生另外50条数据组成组合人名字段查詢项;接下来,从标题和剧情简介字段中随机选择关键词组合产生100条关键词查询项;最后将人名字段查询项和关键字查询项随机组合产生100条组合人名与关键字查询项。Lucene默认评分算法与改进算法的对比实验将依据这300条查询项展开,并且针对每次查询返回的前200条数据分析,计算评价指标。
4.1 评价指标
本文采用信息检索系统中常用的评价指标对算法进行评估,这些评价指标包括召回率(Recall),准确率(Precision)和F值度量(F measure)。准确率是指与查询相关的检索文档得分;召回率指的是搜索返回结果中相关文档的百分比;F值度量是一种测试准确性的度量,F值度量将准确率和召回率都包含在内。使用R表示召回率,P表示准确率,F表示F值度量,公式表示如下:
4.2 实验结果分析
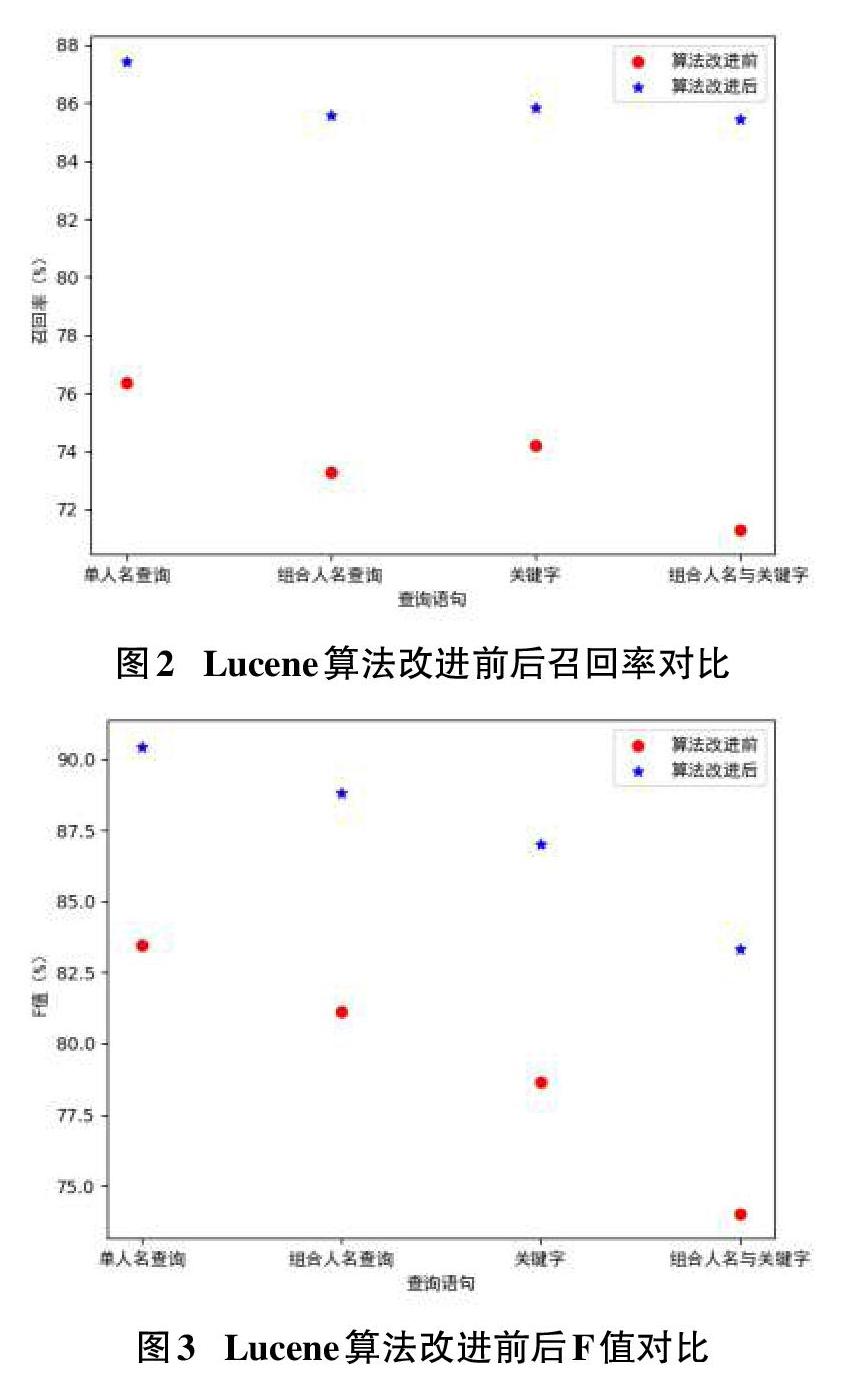
如上文所述,本次实验的查询项主要分为四类:单人名查询项;组合人名查询项;关键字查询项;组合人名与关键字查询项。实验针对每一类进行多次实验,并记录每次实验的准确率、召回率与F值,最后将这些实验的准确率、召回率和F值求均值。表1-3记录了算法改进前后准确率、召回率与F值的对比:
实验结果分析:
如图1-3所示,Lucene算法在改进后,相比改进前准确率、召回率与F值都有不同程度的提高。改进后算法的性能在基于关键字和组合人名与关键字查询上面表现很好,准确率、召回率、F值的提升空间都很大。但是对于基于人名的查询上三种评价指标的上升幅度较小,这里考虑是分词的影响。
4 总结与展望
本文通过对Lucene默认评分算法进行分析,针对默认评分算法存在的不足进行改进。改进策略主要分为两个方面,将词性信息作为负载添加到Lucene默认算法的公式中;另外分析查询字段的词性分布,基于此为不同字段添加权重改进默认Lucene排序算法;考虑查询词出现在文档的不同位置重要性的差别,改进Lucene默认评分算法。实验结果表明,与Lucene默认排序算法相比改进后的排序算法的准确率、召回率和F值均有不同程度的提升。当然还存在一些缺点,例如负载信息的添加可能导致搜索引擎中存储数据增加;另外每次查询时需要先进行词性分析,可能导致搜索实时性下降。下一步的工作就是优化上述问题,以及研究不同的词性分析方法,进一步提升检索的相关性,以及研究如何减少检索系统对分词的依赖性。
参考文献:
[1] Cooper W S. Getting beyond Boole.[J]. Information Processing & Management, 1988, 24(3):243-248.
[2] Wu H C , Luk R W P , Wong K F , et al. Interpreting TF-IDF term weights as making relevance decisions[J]. ACM Transactions on Information Systems, 2008, 26(3).
[3] Robertson S, Zaragoza H. The probabilistic relevance framework: BM25 and beyond[J]. Foundations and Trends? in Information Retrieval, 2009, 3(4): 333-389.
[4] Bestgen Y. Improving the character ngram model for the DSL task with BM25 weighting and less frequently used feature sets[C]//Proceedings of the Fourth Workshop on NLP for Similar Languages,Varieties and Dialects (VarDial). 2017: 115-123.
[5] McCandless M, Hatcher E, Gospodnetic O. Lucene in action: covers Apache Lucene 3.0[M]. Manning Publications Co., 2010.
[6] Cong L U O, LI Z. Personalized Ranking Algorithm Based on User Interest Modeling[J]. DEStech Transactions on Computer Science and Engineering, 2017 (cst).
[7] 聞峥. 基于Lucene的搜索引擎优化[D]. 北京: 北京交通大学, 2011.
[8] Wang L S. Relevance weighting of multi-term queries for Vector Space Model: 2009 IEEE Symposium on Computational Intelligence and Data Mining, 2009 [C]. Nashville, TN, USA: IEEE, 2009: 396-402.
[9] 胡博, 蒋宗礼. 融合位置相关和概率排序的Lucene排序算法改进[J]. 计算机科学, 2016, 43(9):247-249.
[10] 胡博. 基于Lucene的垂直搜索引擎研究与实现[D]. 北京: 北京工业大学, 2016.
[11] Màrquez L, Rodríguez H. Part-of-speech tagging using decision trees: European Conference on Machine Learning, 1998[C].Springer, Berlin, Heidelberg: Lecture Notes in Computer Science (Lecture Notes in Artificial Intelligence) , 1998: 25-36.
[12] Brill E. A simple rule-based part of speech tagger[C]//Proceedings of the third conference on Applied natural language processing. Association for Computational Linguistics, 1992: 152-155.
[13] Brants T. TnT: a statistical part-of-speech tagger[C]//Proceedings of the sixth conference on Applied natural language processing. Association for Computational Linguistics, 2000: 224-231.
[14] Allan J, Raghavan H. Using part-of-speech patterns to reduce query ambiguity[C]//Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2002: 307-314.
[15] 韓普, 王东波, 刘艳云, 等. 词性对中英文文本聚类的影响研究[J]. 中文信息学报, 2013, 27(2):65-74.
[16] 苏祺, 昝红英, 胡景贺, 等. 词性标注对信息检索系统性能的影响[J]. 中文信息学报, 2005(2).
[17] 程彬彬. 词性在汉语科技文献检索中的作用与影响[D]. 南京: 南京农业大学, 2008.
[18] Li Z , Sun M . Punctuation as Implicit Annotations for Chinese Word Segmentation[J]. Computational Linguistics, 2009, 35(4):505-512.
【通联编辑:梁书】
