基于NIRS技术和PCA-SVM算法快速鉴别国产和进口啤酒花
2019-08-08郭云香李晓瑾王果平蒋益萍辛海量贾晓光
郭云香,陈 龙, 李晓瑾,王果平, 蒋益萍 ,辛海量, 贾晓光
(1 新疆医科大学 中医学院,新疆 乌鲁木齐 830011;2 新疆维吾尔自治区中药民族药研究所,国家中医药管理局新疆中药民族药资源重点实验室,新疆 乌鲁木齐 830002;3 海军军医大学药学院生药学教研室,上海 200433;4 襄阳市中心医院 湖北文理学院附属医院,湖北 襄阳 441021;5 湖北中医药大学 中药资源和中药复方教育部重点实验室,湖北 武汉 430065)
啤酒花HumuluslupulusL.为桑科葎草属啤酒花的干燥雌性球穗状花序,不仅是酿造啤酒的重要添加原料[1]。在我国还作为民族药使用。被收录于《新疆药用植物志》《内蒙古植物药志》《宁夏中药志》《哈萨克药物志》《四川中药志》等,具有止咳化痰、健胃、消食、镇静、利尿的功效,为药食两用的新疆特色资源植物[2]。在欧洲,啤酒花提取物用于缓解更年期的潮热不适以及绝经后骨质疏松症[3]。传统啤酒花生药的鉴别方法有显微鉴定、理化鉴定[4]及非线性化学指纹图谱[5-6]等,但这些方法都存在实验复杂、检测时间过长等缺点。近红外漫反射光谱技术(NIR)其无损、快速、准确的优点能够反映样品的综合信息,在植物药[7]、动物药[8]和矿物药[9]中均有涉及,能反映分子中C-H、N-H、O-H基团基频振动的倍频吸收与合频吸收。本研究将运用近红外漫反射光谱(NIRS)技术,将主成分分析(PCA)和支持向量机(SVM)等化学计量学算法相结合,建立快速无损的PCA-SVM识别模型,用于国产和进口啤酒花的快速鉴别。
1 仪器与材料
1.1 仪器
MPA傅里叶变换近红外光谱仪(德国布鲁克光学仪器公司,配备固体积分球漫反射附件),OPUS 7.5 采集和处理软件(德国布鲁克光学仪器公司),MATLAB R2014b软件(美国Math Works公司)。
1.2 样品
2017年采集的国内外不同地方的啤酒花样品均经第二军医大学药学院生药教研室辛海量副教授鉴定,并密封存放于干燥阴凉处,详细采集信息见表1。

表1 啤酒花样品产地来源及采集时间

(续表1)
2 方法与结果
2.1 近红外光谱采集
共计56批样品,分别取2g置于样品瓶中,采用积分球漫反射测试模式扫描NIR光谱。光谱扫描范围4 000~12 500 cm-1,扫描次数32次,仪器分辨率为8 cm-1。每个样品重复扫描3次,取平均值作为该样品的分析光谱。所有样品NIR光谱见图1。

2.2 样本集划分及类别标签值设定
将56批样品按2:1比例随机分为校正集和测试集2个子集,校正集训练模型,并以内部交叉验证法验证模型性能,测试集对所建模型进行预测能力评价。采用矢量归一化法(VN)、一阶导数(FD)、二阶导数(SD)对样品进行光谱预处理,运用PCA-SVM算法,以 RBF(高斯径向基核函数)为核函数,分别采用网格搜索优化法、遗传算法(GA)、粒子群算法(PSO)并结合五折交叉验证法进行建模,并以五折交叉验证准确率为指标,对SVM模型参数组合(c,g)进行寻优,用寻优所确定的最佳参数建立PCA-SVM模型,并用所建模型对校正集和测试集样品进行预测,计算预测准确率。具体分集信息见表1。

图1 56份啤酒花样品的近红外原始光谱叠加图
2.3 PCA降维及光谱预处理
2.3.1PCA降维
PCA是一种将原来多个具有一定相关性的众多指标,重新组合成一组新的互相无关的综合指标的统计分析方法[11]。运用PCA方法对近红外光谱数据特征提取和压缩,对多维数据进行降维,去除输入随机向量之间的相关性,突出原始数据中的隐含特性,可消除众多信息共存中相互重叠的信息部分。选择特征值较大的几个主成分作为特征变量进行模式识别[12]。
在OPUS软件中,将校正集样本初始建模谱段的原始光谱数据,进行PCA降维处理,提取前两个主成分,利用各样品的第一主成分(PC1)和第二主成分(PC2)得分值绘制平面散点图(图2)。
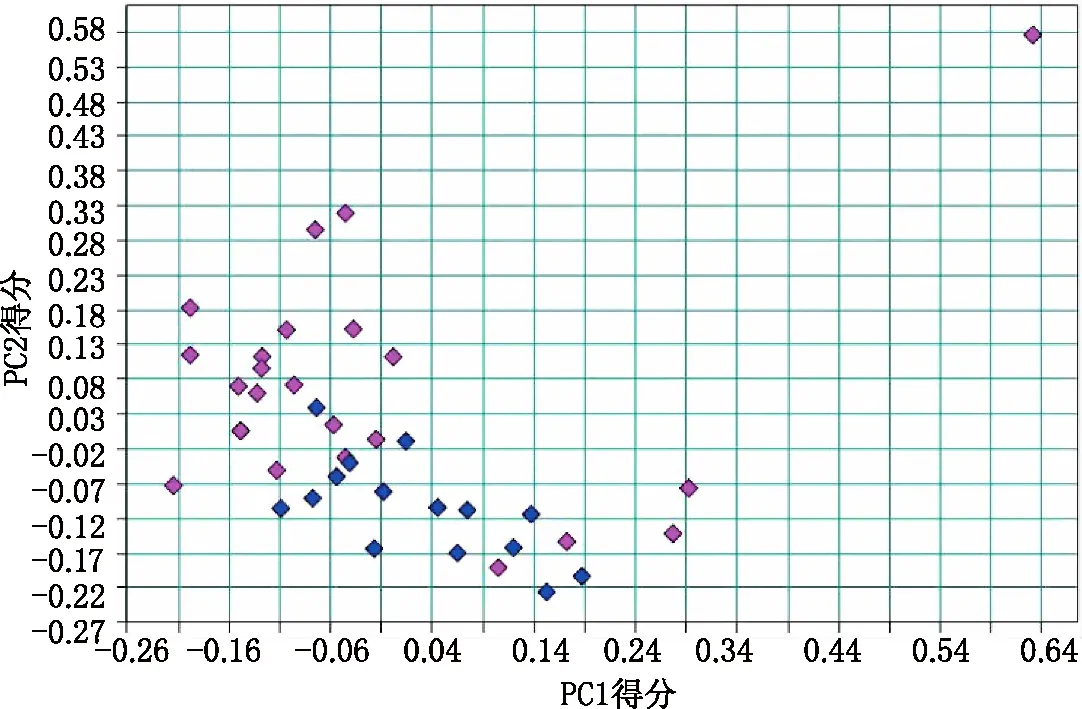
图2 第一主成分(PC1)和第二主成分(PC2)得分平面散点图 进口:蓝色;国产:红色
2.3.2光谱预处理
在用近红外漫反射仪进行光谱信息采集时,得到的样品信息包括除自身信息外的无关信息,例如由于仪器、样品粒径大小、装样量、重复测量次数等引起的基线不平、噪音干扰,为了得到可靠的信息,需要对光谱进行预处理以消除干扰,建立更可靠的模型。采用光谱预处理方法有矢量归一化法(VN)、一阶导数法(FD)、二阶导数法(SD)建立定性模型,并以模型效果确定最佳预处理方法。
为确定最佳的光谱预处理方法,提取有效的主成分。利用Matlab R2014b软件,在训练集样品的9 000~4 100 cm-1谱段,分别对VN,FD或SD预处理后的光谱进行PCA降维,并提取不同预处理条件下的前两个主成分,利用各样品的第一主成分(PC1)和第二主成分(PC2)得分值绘制平面散点图(图3)。
由图3可知,校正样品经VN、FD、SD预处理后可见鉴别趋势,但VN、SD预处理后部分同类别样品分布较近,易混淆。而校正集样品的光谱经FD预处理后,其主成分得分的散点图上,同类样品彼此靠近,异类样品彼此分离,相比于其他预处理方法,其分类效果最佳,故确定FD为最佳光谱预处理方法。光谱在9 000~4 100cm-1谱段的光谱经FD预处理后,消除了基线漂移,同时光谱峰差异得到显著放大,更有利于进行品种鉴别。
2.4 特征谱段筛选
在9 000~4 100 cm-1谱段中还包括水的特征吸收7 500~6 500 cm-1,5 400~5 000 cm-1。此外还有尚不明确的干扰信息,因此,为简化模型,消除干扰,提高模型稳定性,对建模谱段进行筛选。在不降低模型鉴别能力的情况下,尽可能缩小建模谱段的范围。
由图4,在排除水分的干扰后,初始建模谱段可被分为3部分:9 000~7 500 cm-1,6 500~5 400 cm-1,5 000~4 100 cm-1,故将上述SD预处理后的三个谱段,分别进行PCA降维,提取前两个主成分,绘制主成分得分散点图(图5)。由图5可见6 500~5 400 cm-1谱段效果最佳,该谱段条件佳,PCA得分散点图上,同类样品点相对集中,异类样品点能较好分离。但3批样品出现类别混乱。尚需进一步的优化。
因此,选取6 500~5 400 cm-1谱段,以FD为最佳预处理方法进行光谱预处理,以PCA提取主成分,获得各样品光谱的主成分得分,作为SVM模型的输入变量,建立国产和进口啤酒花的近红外光谱PCA-SVM定性分析模型。
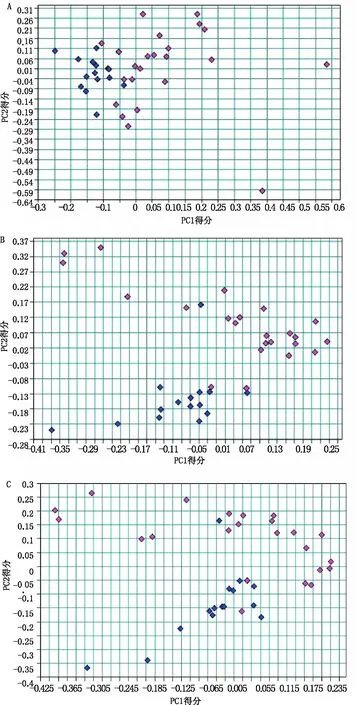
图3 光谱预处理VN、FD、SD散点图 A.矢量归一化法散点图;B.一阶导数法散点图;C.二阶导数法散点图

图4 啤酒花样品的一阶导数NIRS
2.5 SVM建模
2.5.1SVM算法
SVM算法[13]是一种基于统计学理论的新的机器学习方法,SVM通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,达到在统计样本量较少的情况下,获得良好统计规律的目的。在解决小样本、非线性、高维数据时具有很大优势,在很大程度上能够克服“过学习”和“维数灾难”等问题。SVM常用核函数有多项式、Sigmoid感知核和高斯径向基核(RBF)。其中,RBF核函数[14]是应用最广泛的核函数,适用于低纬、高维、小样本或大样本等情况,是较为理想的分类依据函数。
2.5.2内部参数优化
在RBF为核函数的SVM算法中有2个重要的参数:惩罚因子c和核函数参数g,不同参数所建立的模型的预测能力不同,故参数优化的方法在建模过程中有着很大的影响。网格搜索法(GS)是SVM问题上应用最为普遍的参数寻优算法,它是将参数(c,g)在一定的空间范围中划分成网格,从网格中全部的点中找到最优参数[15]。此外,遗传算法(GA)和粒子群算法(PSO)是近年来迅猛发展起来的智能算法,GA算法是借鉴生物界自然选择和遗传机制,利用选择、交换和突变等算法的操作,随着不断的遗传迭代,保留目标数据较优的变量,最终达到最优结果的一种方法[16]。PSO算法模拟鸟群飞行觅食的行为,通过鸟之间的集体协作使群体达到最优目的。在PSO算法系统中,每个备选解被称为一个粒子,多个粒子共存、合作寻优,每个粒子根据其自身的经验和相邻粒子群的最佳经验在问题空间中向更好的位置飞行,搜索最优解[17]。
基于上述原理,本文使用了RBF核函数建立国产和进口啤酒花的SVM模式分类模型。模型以FD预处理的样品光谱(6500-5400cm-1)经PCA提取的前两个主成分得分为SVM输入变量,以各类样品的类别标签值为输出,分别采用网格搜索优化法、GA、PSO并结合五折交叉验证法,以五折交叉验证准确率为指标,对SVM模型参数组合(c,g)进行寻优,用寻优所确定的最佳参数建立PCA-SVM模型,并用所建模型对校正集和测试集样品进行预测,计算预测准确率。综合考虑五折交叉验证准确率、校正集预测准确率和测试集预测准确率,对PCA-SVM模型进行评价。不同寻优方法的寻优过程见图6所示,所得参数建立的SVM模型效果见表2。
综合对比上述预测准确率,准确率越高,模型越好,据此判断最佳SVM模型。由表2,不同寻优方法下,两个主成分所建PCA-SVM模型的效果一致。但PSO寻优所确定的c值偏大而g值偏小,该选优方法不合适。对比网格搜索法和GA寻优过程,发现GA寻优操作更为复杂,且具有一定随机性,故确定网格搜索法为最佳。依据网格寻优结果,确定最佳c和g值均为1,利用前2个主成分得分值建立的PCA-SVM模型对校正集和测试集预测准确率均较高(>85%)。但考察主成分累计贡献率变化(图7),前两个主成分累计贡献率为91.70%(<95%),2个主成分包含原光谱数据的信息量有限,是否为最佳建模主成分数尚不明确,故对主成分数进行优选,进一步提高PCA-SVM模型性能。

图5 不同建模波段的一阶导数PCA得分散点图 A.9 000~7 500 cm-1;B.6 500~5 400 cm-1;C.5 000~4 100 cm-1

图6 SVM内部参数寻优过程图 A.网格搜索优化法;B.遗传算法;C.粒子群优化算法

寻优算法主成分数cg准确率/%五折交叉验证校正集测试集网格21192.1192.11(35/38)88.89(16/18)GA22.55660.344792.1192.11(35/38)88.89(16/18)PSO2778.68770.00192.1192.11(35/38)88.89(16/18)
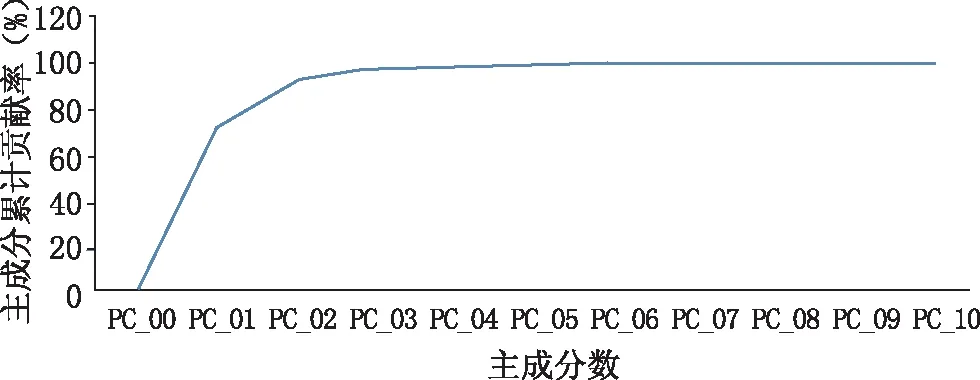
图7 主成分累计贡献变化图
2.5.3主成分数进一步优选
经原始光谱(9 000~4 100 cm-1)FD预处理、PCA降维得到前2个主成分,并提取特征谱段数据(6 500~5 400 cm-1)进行SVM建模,前2个是否为必要或最佳主成分尚不明确,且对原始光谱数据信息的代表性不强,故需对主成分数进行优选。在前2个主成分的基础上,增加建模的主成分个数,将PCA提取前3、4、5、6、7、8、9、10个主成分,以防数据丢失。但主成分数增加会使模型稳定性减低,故需对建模的主成分数进行筛选。根据上述SVM算法建模及寻优过程依次建立8个PCA-SVM分类模型,由图7可得,前10个主成分累计贡献率达99.74%,前10个主成分的贡献率相对较大,对原数据的代表性较强,故本研究在这前10个主成分中进行筛选,依次建立不同主成分数的PCA-SVM模型,并对比建模效果见表3。

表3 不同主成分数的PCA-SVM模型的建模参数及验证、评价效果
由表2和表3可知:随主成分数的增加,校正集和测试集预测准确率均增加,其中当主成分数为8时,校正集预测准确率达到最大,其后保持稳定;当主成分数为7时,测试集预测准确率达到最大,并保持稳定。此外,五折交叉验证准确率先增大,后减小,当主成分数为8时,五折交叉验证准确率最大。故确定啤酒花样品最佳主成分数为8。即以PCA提取的前8个主成分得分为PCA-SVM的输入变量。
2.6 SVM评价
综上所述,在6 500~54 00 cm-1建模谱段,确定最佳光谱预处理方法为一阶导数法(FD),FD预处理光谱PCA降维后,确定最佳主成分前8个主成分(PC1,PC2,...,PC8)。经网格搜索法确定最佳SVM建模参数组为:c=2,g=1,所建PCA-SVM模型对校正集和测试集样品预测正确率均分别为97.37%和97.44%,预测准确率高。模型五折交叉验证准确率亦达97.37%,模型性能最佳。该模型对校正集和测试集预测结果见图8。
通过图8可以看出,在寻优过程中发现,网格搜索算法寻优原理简单,具有可重复性,而PSO算法和GA寻优的智能算法,其运算过程具有一定的随机性,对复杂问题的解决能力更强。建立光谱数据经FD预处理后进行降维,使得建模复杂度相对简化,且不同样品的趋向度不一致,故确定最优内部寻优方法为网格搜索算法。以网格搜索算法确定的模型8对训练集和测试集样品的预测可知,校正集的第9个样品PJH-14预测错误,测试集的第17个样品PJH-51预测错误,可能样品的基数过小,可达标原始光谱的绝大多数信息。
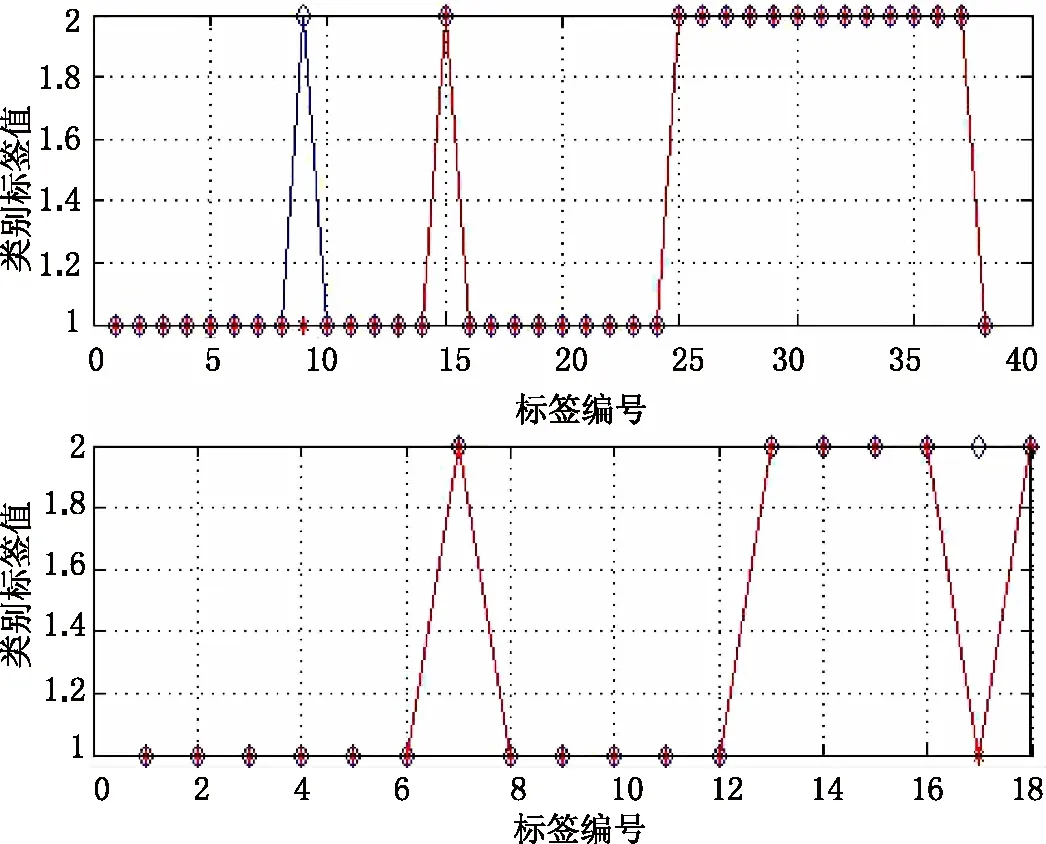
图8 模型8对样品的预测效果 A.预测集;B.校正集
3 讨论
本实验通过收集国产和进口啤酒花样品,在收集的56个样品中,有21个进口啤酒花,35个国产啤酒花,利用NIRS光谱,建立了啤酒花中药材的PCA-SVM模式识别模型,该模型对预测集和校正集样品的预测准确率高。模型五折交叉验证准确率亦达97.37%,模型性能最佳。可用于啤酒花样品的快速鉴别。建模过程中,本文采用光谱PCA降维所得的主成分得分平面散点图,对光谱预处理主成分进行优选,根据样品的趋势,确定样品的最佳预处理方法。然后对SVM的内部参数进行GA算法、PSO算法寻优,建立PCA-SVM算法,快速鉴别啤酒花样品。
本文首次将NIRS技术应用于啤酒花中药材的鉴别,证明了其具有可能性,为啤酒花的鉴别提供了新的方法。但由于样本量及产地的限制,本文在对啤酒花样品进行模型五折交叉验证中校正集第9个样品PJH-14预测错误,测试集第17个样品PJH-51预测错误。后期需对样品量和产地、品种进行扩增,对模型进行完善。使该方法可以快速鉴别啤酒花,提高测试正确率和准确率。该方法也可用于其他中药材的鉴别,例如矿物类和树脂类中药材[18-19]。本研究方法较新,收集样品量大,建立方法具有一定的应用和推广价值。
