基于自适应免疫算法的配送中心选址问题研究
2019-08-06李纪鲁张晓朱杰
文/李纪鲁 张晓 朱杰
关键字:自适应;免疫算法;选址;配送中心
引言
物流配送中心的选址理论最初由Alfred Weber于1929年提出[1],他们研究如何设置一个配送中心到达各个需求点的距离最短。这种交通问题一提出便得到了各位学者的广泛关注,从此,配送中心的选址和优化问题越来越重要。近几年的研究成果也越来越多。费腾[2]等人在配送中心的选址中引入基于DNA改进的鱼群算法,丰富了鱼群的多样性,促进鱼群算法跳出最优解,使选址有了更好的寻优能力。唐炜[3]为解决配送中心的选址问题,提出基于层次分析法的优化方法,为实际操作提供了新思路。徐小平[4]在解决配送中心选址问题中,提出一种改进的狼群算法,通过引入扰动操作、不确定的奔袭和攻击步长提高算法的精确度。王辛岩[5]等人通过AHP和人工免疫算法结合来求解物流中心的选址问题,验证了免疫算法的收敛性和鲁棒性。
李爽[6]等人针对物流中心的选址问题提出一种融合DEA和AHP的混合模型,比传统的物流配送中心选址模型有更强的可行性和实用性。胡利利[7]等人把节点需求量和辐射半径纳入约束条件,并以需求量作为距离的权重放入目标函数中,建立配送中心选址模型,并通过实验找出了交叉和变异概率的事宜取值,为后续的研究提供了方向。
淦艳[8]等人将配送时间作为目标函数中的权值进行模型构建,并通过免疫算法进行多次实验,验证了模型的可行性。倪卫红[9]等人在配送中心选址中对免疫算法的交叉和变异概率进行自适应改进,并通过实验验证了改进的可行性。姜婷[10]针对配送中心选址的研究提出改进的萤火虫算法,通过对萤火虫算法的李算话处理来解决选址问题,验证了算法的稳定性和运行效率。殷月[11]建立考虑多方面成本因素影响的配送中心模型,并通过免疫算法对模型求解,验证了免疫算法在配送中心选址中的可行性和实用性。本文主要在上述文献的基础之上,综合考虑物流配送中的位置因素和需求量因素,并通过数学建模的方式对目标函数和约束条件进行定义,构建一个带有需求量权重的配送中心选址模型,并通过自适应的方法改进免疫算法,应用到配送中心模型中进行求解。
1.配送中心选址模型的建立
本文是根据总成本最小为目标的物流配送中心选址问题[12],在建立配送中心选址模型时考虑到满足需求节点约束和配送中心到需求点的最大距离约束等,在已知的多个备选点中设定一定数量的配送中心,并构成以配送中心和需求点为基本单元的网络,实现总成本最小。本文中的距离采用欧氏距离,并采用单位需求运输费率为1,即运输费用等于运输距离。在物流配送中心选址模型中做如下假设:
(1)配送中心的规模容量满足需求点的需求;
(2)一个配送中心可以对多个需求点进行配送,但一个需求点只能由一个配送中心进行配送;
(3)不考虑运输费用之外的其他费用。
基于以上假设,根据成本最小化为目标来建立配送中心的选址模型,在配送中心选址模型中,在不超过距离上限的基础上,需要从n个需求点中找出设定个数的配送中心向各需求点配送货物。目标函数是各配送中心到需求点单位需求量的运输成本和需求量的乘积最小。符合就近分配和容量约束原则。
目标函数为:

约束条件为:

2.自适应免疫算法
免疫算法是一种仿生学的算法,它旨在区分有害抗原和自身组织,从而保持有机体的稳定。免疫系统不仅有交叉变异保证种群的多样性,而且有种群经营保留策略,全局寻优能力较好,同时精英保留策略可以维持免疫系统平衡机制,对于今后侵入相同的抗原,相应的记忆细胞会迅速激发产生大量的抗体。免疫系统在产生抗体时,可以借助克隆选址、免疫记忆、疫苗接种等方式对抗体的产生进行促进和抑制,体现了免疫系统有较好的自我调节能力。参考文献[7]中的免疫系统改进策略对算法的各部分进行定义描述,同时引进根据抗体与抗原之间的亲和力对变异概率进行计算,亲和力越高,变异概率越小。
2.1 产生初始抗体群
采用实数编码的方式对初始抗体群进行编码,如果记忆库非空,则从记忆库中产生初始抗体群,否则,随机产生初始抗体群。每个可行方案均形成一个长度为q的抗体,即设定的物流配送中心个数。
2.2 亲和力计算
在抗体的适应度方面考虑配送中心对需求点的配送最大距离上限约束条件,设置违反距离约束的惩罚函数。抗体亲和力包括抗体与抗原之间的亲和力和抗体与抗体之间的亲和力,抗体与抗原之间的亲和力表示抗体对抗原的识别程度,抗体与抗体之间的亲和力表示抗体与抗体之间的相似程度。本文中抗体与抗原之间的亲和力用Cu表示。
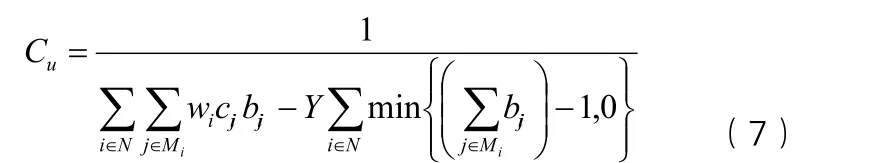
其中,对于配送中心到需求点距离超过规定上限的解给予惩罚,其中Y取一个比较大的正数。
抗体与抗体之间的亲和力计算方法主要根据文献[8]中α位连续方法,即根据两个抗体中相同位数所占总长度的比重来判断量抗体的相似程度。两抗体的亲和度定义如下:

其中,ku,v表示抗体u和抗体v之间的相同位数数量,q为抗体的长度。
2.3 抗体浓度的计算
抗体浓度即抗体群中相似抗体所占的比例,为了保证进化过程中种群的多样性,免疫系统需要对抗体的产生进行促进和抑制,若抗体群中相似抗体所占的比重过大,即抗体间的相似程度较高会影响抗体群的多样性,因此需要设定一个阈值φ来控制抗体浓度。本文中设定抗体浓度的阈值为0.7,其中N为抗体总数,抗体浓度定义如下:

2.4 期望繁殖概率
每个个体的期望繁殖概率由抗体与抗原之间的亲和力Cu和抗体浓度C'u两部分共同决定,是免疫选择操作中的重要依据。在期望繁殖概率中不仅体现了适应度高的促进,而且体现了抗体浓度高时的抑制,从而保证整个抗体群的多样性。与此同时,为了避免出现抗体浓度高时受到抑制而丢失最优解的情况出现,采用了精英保留策略,设置记忆库容量为overbest的容量库,先将抗体育抗原亲和度的抗体存进记忆库中,再按照期望繁殖概率选择优秀的抗体放进记忆库中。本文设置多样性评价参数ε对抗体与抗原之间的亲和度起到促进作用,同时对抗体高浓度情况起到抑制作用。期望繁殖概率定义如下:
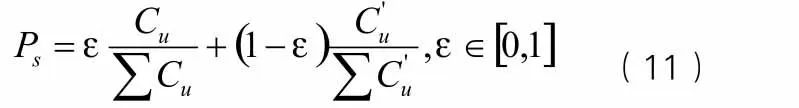
2.5 选择操作
本文采用轮盘赌的方法,基于适应度权重和浓度权重的选择策略。个体被选择的概率与上述期望繁殖的概率一致。
2.6 交叉操作
交叉概率越大,新的抗体产生的速度越快,搜索的范围越大,但是交叉概率过小时,容易导致搜索速度过慢,影响计算的时间长度,因此,采用自适应交叉概率可以保证较优的解进入下一代,减少计算时间复杂度。交叉概率公式如下,其中Pc0为初始的交叉概率,Fm为最大的适应度值,Fa为平均适应度值,F为进行交叉的两个个体中较大的适应度值。

2.7 变异操作
本文变异算子基于适应度的大小,主要思想是当适应度较大时,应该抑制变异行为,当适应度较小时,应促进变异行为。对需要变异的个体采用多变异位自适应的方法进行变异,即根据适应度值选择变异概率及变异位。变异概率定义如下,其中为'F变异个体的适应度值。

2.8 自适应免疫算法求解配送中心选址问题
(1)本初始化抗体种群。随机产生N个个体并从记忆库中提取m个个体构成初始抗体种群,其中m为记忆库中个体的数量。
(2)对上述种群中的抗体进行评价,按照期望繁殖概率对父代进行评价选择,找出适应度值较大且抗体浓度适当的抗体作为父代并根据精英保留策略存入记忆库中。
(3)判断是否满足终止条件,如果是则输出结果,如果不是则进行下一步操作。
(4)采用轮盘赌的方式对抗体种群进行选择操作。
(5)根据自适应公式对抗体群体进行交叉操作、变异操作,并从记忆库中取出记忆的个体,共同构成新一代群体。
(6)转到执行步骤(2)。
改进后的自适应免疫算法流程如下:
3.实验对比设计
该为了验证算法的可行性,数据采用文献[11]城市位置坐标和需求量信息如表所示。表中(x,y)代表城市坐标,Wi表示需求点的需求量。本文采用MATLAB2014a编程,并在HP450,CPU为2.60GHz,内存为4GB的ARM笔记本上测试改进的自适应免疫算法,算法参数设置为:种群规模为50,记忆库容量为10,最大迭代次数为100,交叉改路初始值为0.5,变异改路初始值设置为0.4,求得配送中心的选址方案为[12 28 9 5 20 17] ,距离和为5.49X105 , 运行对比如下:
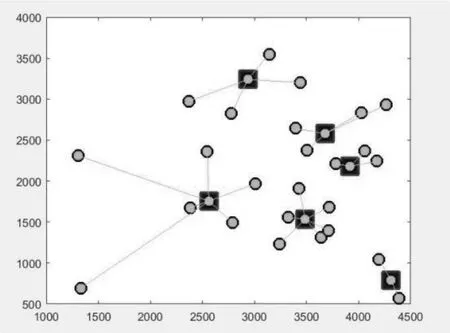
图2 配送中心选址图
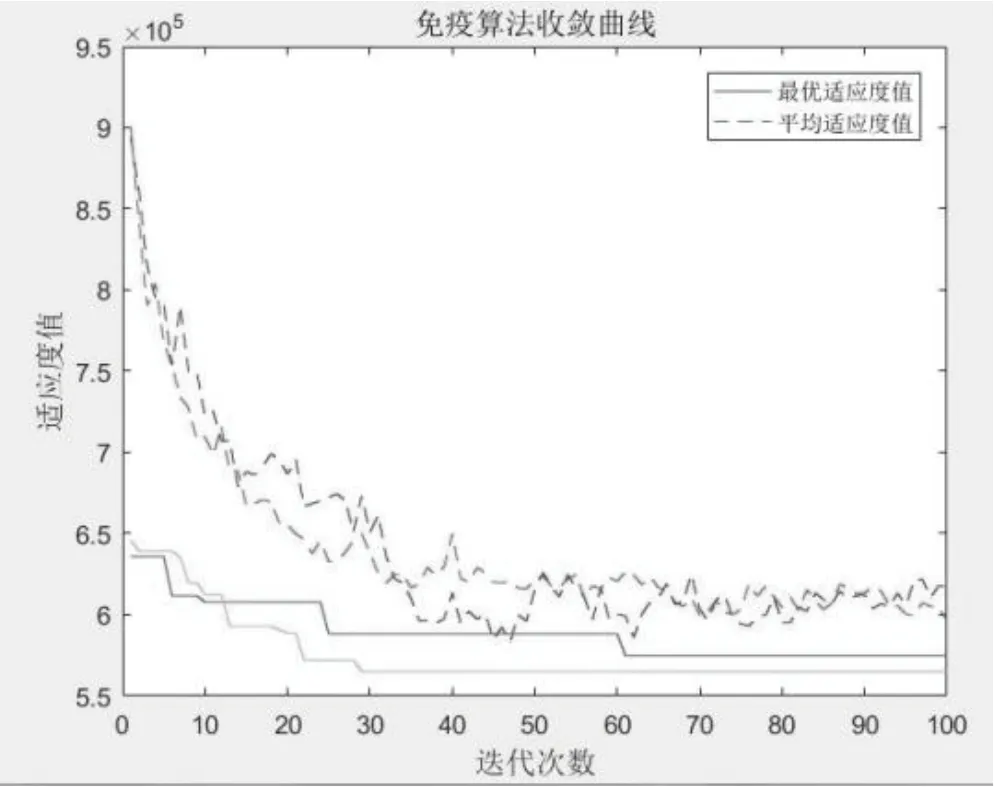
图3 对比分析
与未设定交叉变异算子的免疫算法对比,收敛速度较快,最终收敛到最小值。
4.结语
考虑到免疫算法容易受精英解的影响,设定自适应的交叉和变异算子,构建路径和最小为目标函数,设定相应的约束条件,实例验证得出自适应的免疫算法由较好的全局搜索能力,收敛速度快,可以跳出局部最优解。
