探究复述策略对获取实体属性槽“源信息”的意义
2019-08-05宋睿,陈鑫,洪宇
宋 睿,陈 鑫, 洪 宇
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
文本分析会议(text analysis conference,TAC)于2009年提出了知识库群组(knowledge base population,KBP)评测任务,旨在引领信息抽取与组织的深入研究。槽填充(slot filling,SF)是KBP任务体系中的重要研究任务。截至目前,现有槽填充前沿技术的精度尚未超越60%(F值)。具有较高的探索价值。
槽填充的核心问题是如何为特定命名实体的某一属性查找确切的实例(槽值)。面向槽填充的主流系统架构包括三个组成部分:
① 相关文档获取(粗糙的数据源检索);
② 源信息发现(也称源信息分类);
③ 槽值抽取(从源信息中提取具体实例)。
其中,相关文档获取环节主要面向特定实体获取相关的文本信息,这一环节要求系统根据极为有限的先验知识(命名实体和一篇参考文档),从大规模文本数据中精确召回大量与命名实体相关的文档。源信息发现环节则在上述检索到的相关文档中,定位具体的文本片段,所定位的片段需要包含特定类型的实体属性(槽)的实例,并提供可信的上下文以佐证这一实例的可靠性。最终,抽取环节将根据信息源,利用自然语言理解和处理技术自动地从源信息中抽取实例。
槽填充是一种从无结构的自由文本中获取预定义属性的实例信息,并形成结构化报表的任务。维基百科每个词条对应的页面中,信息盒子(InfoBox)即为槽填充技术的一种应用模式,其有助于用户快速理解和概览特定目标实体的主要特性。图1显示了维基百科中关于实体“微软”的InfoBox。

图1 维基百科中关于“微软”的InfoBox
本文针对源信息分类展开研究。源信息分类的核心目标是: 给定特定文本片段,对其是否描述了特定类型实体的某一种属性进行判别。例如,给定句子“微软总部设立于华盛顿州雷德蒙德市”,正确的判定结果为“org: city_of_headquarters”,即描述了“组织”类命名实体的“总部所在城市”这一属性;作为对比,如果目标语句是“微软员工总数已达11万人”,则源信息分类正确判定结果是“org: number_ of_employees_members”,即描述了“组织”类命名实体的“成员人数”这一属性。正确源信息分类有助于属性实例的有效抽取,比如上例中分别抽取“华盛顿雷德蒙德市”和“11万”。
现有槽填充研究在源信息分类方面的专门工作尚不多见,往往采用较为粗糙的处理手段形成槽填充系统的一个弱环节。常见的方式是: 根据实体类型和属性类型的一致性,选取包含恰当类型的实体的句子作为源信息。例如,“雷德蒙德”的命名实体类型标记“GPE-CITY(地理-城市)”可以对应于实体槽“org: city_of_headquarters(总部所在城市)”,从而,句子“微软总部设立于华盛顿州雷德蒙德市”可作为“org: city_of_headquarters”类属性的候选实例的源信息。这类方法往往不顾及候选实例所在文本片段的语义,从而使获得的信息源中蕴含大量冗余样本和错误样本。尤其是这类方法最终将源信息分类连同属性实例抽取一并纳入后续的机器学习和分类模型,使得在性能分析过程中,无法清晰探测属性实例抽取错误的真正根源(源错误或抽取失当)。并且,在优化抽取系统时,也难以辅助研究者实施有针对性的改进。
本文将源信息分类设置为一个关键的研究点,独立于属性实例抽取之外予以研究。根据前期工作中的观测经验,我们发现文本复述有助于探测待测文本片段是否属于特定实体属性槽的源信息。本文针对这一发现展开系统调查,利用一种树编辑模型(tree edit model[1])实现高效的复述检验,并对现有KBP-SF任务体系下的每一种实体属性槽进行分析,重点评价复述对于基于特定规模知识库的源信息发现和分类的支撑能力。
本文组织如下: 第1节概述相关工作,第2节介绍源信息分类的任务定义和资源,第3节介绍源信息中复述可靠性检验的方法,第4节介绍一种基于树编辑模型的复述方法,第5节给出实验设置、结果和分析,第6节对未来工作进行展望。
1 相关工作
实体属性槽填充是信息抽取领域的一个重要研究方向,近年来一直保持一定的热度。复述是一种经典的自然语言处理研究任务,目前已经取得了多项重要突破。本节首先介绍槽填充任务的相关工作,然后对近期主流复述研究给予概述。
1.1 实体槽填充
自动槽填充方法目前形成了两种主要的方法框架,下面分别予以介绍。
(1) 远程监督(supervised classification)
远程监督做出如下假设: 如果两个实体间存在特定的语义关系,那么同时包含这对实体的句子在一定程度上就能表征两者的语义关系。该方法最早是由Mintz等[2]在关系抽取中引入的,通过使用Freebase作为监督数据库,将维基百科正文的句子对齐到Freebase上,获得大量的训练数据。该方法的引入虽然能一定程度上解决槽填充任务训练语料不足的问题,但是却引入了大量噪声,致使模型不能准确探测关系类型。
针对远程监督存在的问题,Reidel等[3]和Angeli等[4-5]在模型上进行了改进,修改了远程监督的假设,而Roller等[6]和Bing等[7]另一批人则通过提高数据质量来解决远程监督的问题。虽然进行了这么多年的探索,但槽填充的性能仍然没有突破性的进展。
(2) 模式匹配(pattern matching)
模式匹配指从源中学习到一种通用的属性表达模板,如果待测句子和模板相符,则按照对应的模板抽取其相应的属性值。这类方法大都通过自动、半自动的方式抽取,并生成生词路径(word sequence)和依存路径(dependency path),其中生词路径是查询实体和槽值之间的单词序列;依存路径则是依存树上实体到槽的路径,该路径由单词和依存关系节点构成。近年来,NYU[8]和PRIS[9]两支队伍一直不断改进模式匹配的方法,他们的系统是目前通过模式识别进行槽填充任务的主要系统。
除了上述两种主流方法外,也有人尝试用问答的方法(Byrne和Dunnion[10])和无监督的图挖掘方法(Yu等[11])来解决这一问题。
1.2 复述的相关工作
复述(paraphrase)是对相同语义句子的不同表达,在自然语言中,复述是一种极为普遍的现象,也因此被广泛应用于各种自然语言处理任务中[12]。其中自动问答(question answering,QA)和信息抽取(information extraction,IE)是与本文相关的两个应用领域。
复述在QA中核心的两个部分——问句理解和答案抽取中都有相应的应用。问句理解中,可以通过将复杂问句复述为简单的子句集合,其中每个子句包含原句的部分信息,以简代繁来理解问句的信息;答案抽取部分,由于问句和答案之间在表述相同信息时往往采用不同的表达方式,因此可以通过复述来匹配相同意思、不同表达的问句。
复述在信息抽取中同样也发挥着重要作用。类似QA中的答案抽取,基于IE模板的方法往往受限于模板不充分而导致召回率低的问题。Romano等[13]在IE系统中引入复述技术,大量丰富IE的模板,从而提升IE系统的性能。
2 任务定义
本节首先介绍面向实体槽填充的源信息分类(下文简称源分类)任务定义及样例,然后给出现有支持这一研究工作的知识体系与资源。
2.1 源信息分类任务(源分类)
源分类的核心任务是对任意文本片段自动标记实体属性槽类型,从而指明这一文本片段潜在包含特定属性类型的实例。具体任务定义如下:
①Input: 一个文本片段,可为子句(clause)、句子(sentence)、语块(chunk)和段落(passage);
②Output: 属性槽类型标记,这一标记并不唯一,如果一个文本片段包含多种属性槽类型的实例,则该文本片段的类型标记也应为多个,而非一个。
根据这一定义,源信息分类实际上执行了一种对任意预定义的槽类型进行二元判别的工作(从而保证一对多的“源—类型”标记)。下面给出一个实际例子,用以直观显示源分类任务的输入输出模式:
• #Input
微软总部设立于华盛顿州雷德蒙德市,目前员工总数已超过11万(句子级)
• #Output
T1-org: city_of_headquarters
(组织-总部所在城市)
T2-org: number_of_employees_members
(组织-成员人数)
其中,T1和T2分别指示两个不同的槽类型。可以发现,该例中具有两种限定域槽类型,需要分类系统全部输出。该例也暗示,在特定处理环境中,如果缩小文本片段的颗粒度,理论上可减少一对多的“源—槽类型”标记情况,这一点对减少属性实例抽取具有积极的作用。
2.2 知识体系与资源
槽填充任务针对给定的实体类查询进行属性槽值(实例)的抽取。本文基于KBP-SF的评测任务展开研究,并遵循其限定的处理对象和知识体系。目前,KBP-SF将实体类型限定于人(person)和组织(organization),实体类查询主要由人名或组织机构的全名构成。KBP-SF设置了34种属性槽类型,表1显示了所有槽类型名称及中文翻译。其中,21种为人的属性,其他为组织机构类实体的属性。历年KBP-SF评测提供三种数据资源。其一是针对每个实体类查询一对一提供可供参考的文档,这类文档往往蕴含了特定实体的背景信息,但值得注意的是,这类文档中背景的信息量并不统一。其二是大规模文本资源(Gigaword),包含新闻、通用网页和论坛中的文本信息,这一资源用于面向实体查询的检索系统粗略收集相关文档。其三是针对实体查询的测试样本提供的标准答案,针对一个实体查询,其答案包括不同属性槽的槽值(实例)、每个实例所在的源信息及所在文档,本文将该数据资源称为KBP知识库。

表1 KBP—SF命名实体属性槽类型总表
KBP知识库存在如下缺陷: 全面性较低且源信息质量不高。KBP采用Pooling池的方式将所有评测队伍对每一个实体查询提交的系统输出取并集,这一并集即为Pooling池,KBP雇用标注人员对Pooling池内的样本进行人工校对,形成正例和负例清晰可分的标准答案。然而在实际使用中,却难以估测召回率。尤其是标注过程对源信息的质量并未给出明确要求,使得源信息中的冗余信息很多,句法和语篇边界并不规范。
相比而言,由斯坦福大学提供的同类知识库较为规范,在面向主动学习的槽填充研究过程中,斯坦福人工标记了大量句子级的源信息,并标记了其中特定实体与属性槽值的关系。本文将其称为STANF知识库,其包含33 814条源信息,其中有11 184条源信息未标注具体属性实例。该知识库也用于评价实体关系抽取研究。
3 源信息分类的复述可靠性检验
本文尝试检验复述是否有助于源信息分类及其可靠性。这一检验包括三个环节: 复述性能评价(ParaphrasingEvaluation,PE)、同类源信息复述占比评测(Occupation in type-HOMgeneous Source Information,OHOM)和异类源信息复述占比评测(Occupation in type-HETerogenous Source Information,OHET),下面分别给予介绍。
•PE: 对特定复述识别方法的性能检验,复述识别方法需为点到点的复述甄别,即两个文本片段是复述或不是复述。评价方法为精度。本文采用一种基于编辑树模型的复述识别方法(详见第4节),该方法计算速度快,性能与目前基于深度学习的复述识别方法具有可比性。
•OHOM: 给定一种实体属性槽Ψ的源信息知识库,假定已包含了特定规模的先验源信息。约定Ψ的测试样本为蕴含Ψ实例的源信息,利用复述技术探寻每个测试样本是否在中存在复述,如存在则为正例,反之为负例。计算正例样本在全部测试样本中的比例,这一比例称为单项测试样本的OHOM比,将所有测试样本的OHOM比求和取平均,生成调和OHOM值,这一指标称为属性槽Ψ的OHOM比。
•OHET: 与OHOM不同,OHET侧重检验某属性槽的测试样本在其他属性槽的知识库中是否存在复述,以及这种可能性的大小。具体而言,给定一种待测属性槽Ψ1的测试样本集,以及另一种属性槽Ψ2的源信息知识库2。对任意测试样本e(e),利用复述技术检验是否在2中存在复述,如存在,则记录这类复述的个数,并计算在所有测试样本中的占比。这一占比称为e相对其他属性槽Ψ2的OHET比,计算中所有测试样本相对Ψ2的OHET比,并求和取平均,获得调和OHET值,这一指标称为属性槽Ψ1的测试样本相对于其他属性槽Ψ2的OHET比。
本文实验部分对基于树编辑模型的复述识别性能进行评测(PE),并对所有KBP-SF的属性槽进行OHOM评价。此外,针对每一种属性槽,本文也提供了其对应所有其他属性槽的OHET评价。
4 基于树编辑模型的复述识别
本文在规整的复述语料上,利用现有的树编辑模型进行特征提取,训练一个可信的复述分类器,从而利用这个复述分类器来挖掘槽填充任务中同类型和不同类型间的复述现象。树编辑模型能够有效匹配语义相同但结构不同(表达方式不同)的文本片段,在自动问答、机器翻译和信息抽取领域有着广泛的应用。就目前而言,尚未有前人工作专门将复述技术引入实体属性槽填充的相关研究。
本节首先介绍树编辑模型,然后给出利用树编辑模型的识别方法。
4.1 树编辑模型
树编辑模型(tree edit model,TEM)是一种依照句子依存特征实施的语义对齐技术。给定一对句子(本文中特指一对可能互为复述的候选语句),TEM首先将两者分别解析为两棵依存树T1和T2。其中,每个节点用三个域进行表示,分别是词目(lemma)、词性(POS)以及该节点的依存关系。比如,某节点上的标记“Goldstein/nnp/sub”表示名词“Goldstein”作主语,关系则体现在“Goldstein”的对外依存弧上。
TEM遵循Bille[14]提出的树结构编辑距离理论。具体而言,TEM尝试利用编辑操作将两棵依存树T1和T2相互转化,而在转化过程中,通过特定代价函数对每一次编辑操作都赋予一个转化代价,从而形成序列编辑操作的脚本δ和代价表单。在此基础上,TEM 对δ计算总体代价。这一代价泛称树编辑距离。
Yao等[1]定义了9种编辑操作,前6种操作(INS LEAF、INS SUBTREE、 INS、DEL LEAF、DEL SUBTREE和DEL)是对叶节点、其他节点或是整个子树的插入和删除操作;后3种操作(REN POS、REN DEP和REN POS DEP)则是对词性标记、依存关系或两者皆有的重命名操作。编辑操作代价设置如下:
① 对单一节点特定域的编辑操作代价值为1.0;
② 如果是对树节点整体的增、删操作,那么代价值为3.0(因为需对节点的每个域都进行修改);
③ 对于不同树的两个相同节点(不存在编辑操作)或是具有相同的词而进行的编辑操作,都称之为对齐操作。
图2给出了一套TEM编辑操作样例,操作目的是将右边的句子通过编辑操作转化为左边的句子。其中,每个节点由词目和词性组成,边代表其依存关系。为了简化描述,图中省略了句号和根节点。
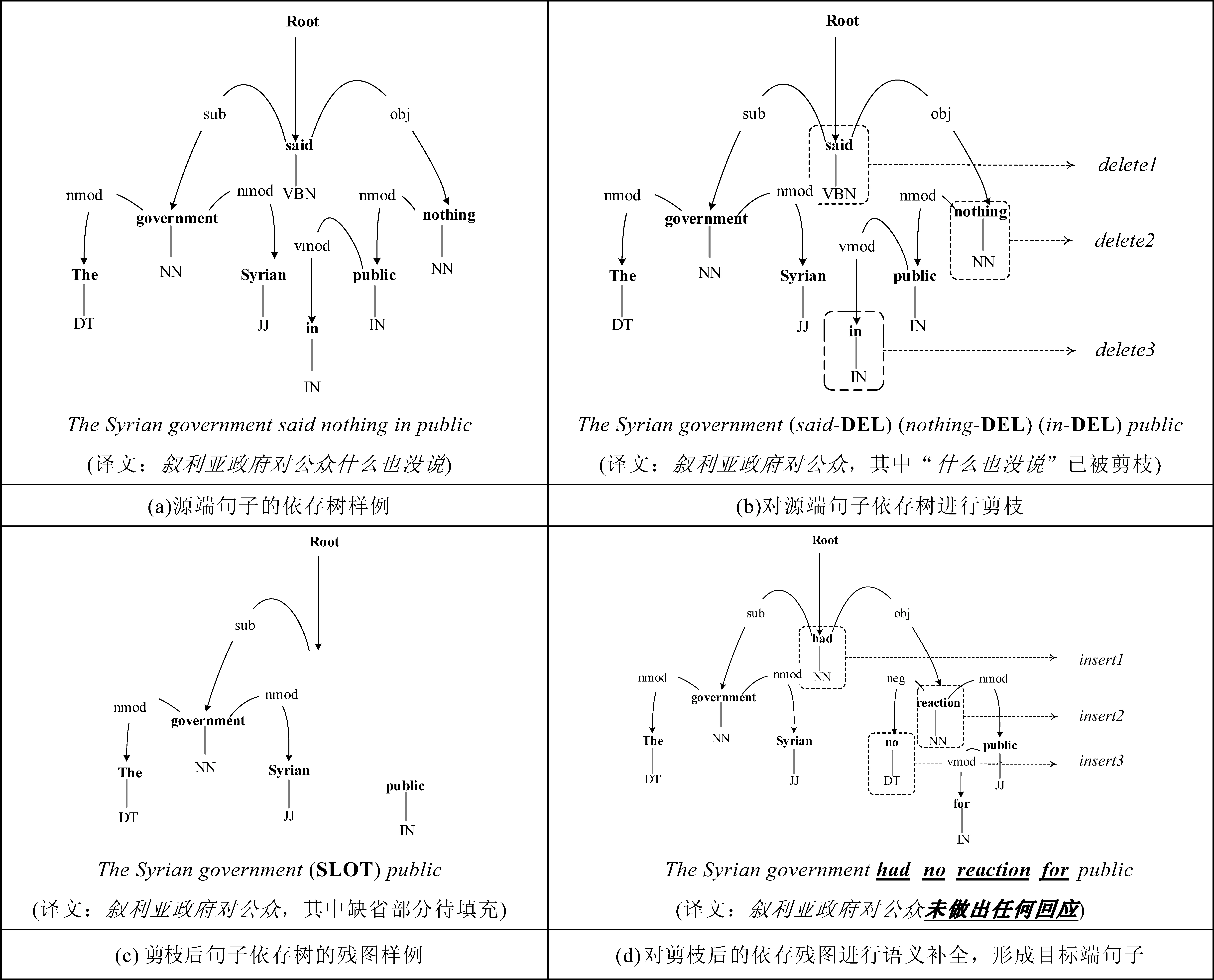
图2 TEM编辑操作样例
对于编辑脚本的选择,模型采用了Zhang等[15]的动态规划算法,自底向上地探索两棵树的编辑操作,从而生成具有最小树编辑距离的编辑脚本。算法的时间复杂度如式(1)所示。
O(|T1||T2|min(D1,L1)min(D2,L2) )
(1)
其中,|Ti|(i=1或2)代表节点的数目,|Di|代表树的深度,|Li|则为叶节点的数目。
4.2 复述识别
本文采用基于树编辑模型的复述识别方法参与实验,该方法使用依存树的编辑操作作为特征,使用支持向量机学习复述样本,最终形成对句对进行“依存或否”的二元分类器,方法框架如图3所示。

图3 复述识别方法框架
(1) 构建语料库树形集合
首先,利用现有的依存分析工具,将复述语料中的所有句子转化为特定的树形结构集合。在这一环节,传统的依存分析工具往往采用最小生成树分析方法[16](MSTParser),但这类工具使用的依存类型并不丰富。为此,本文在这一环节略作修改,采用最新的斯坦福依存分析工具[注]https://stanfordnlp.github.io/CoreNLP/进行依存关系解析。
(2) 数据泛化
命名实体在语义表达中具有统一的含义,从词形角度考虑,同类但不同形命名实体难以一一对应。例如,“微软”“谷歌”和“腾讯”等的概念基本一致(特定的组织机构),但以词形学为基础的处理方法难以对应。从而,TEM的编辑操作难以将同类实体视作含义一致的对齐样本,引发不完整的编辑脚本,编辑代价也将失真。
为此,本文将命名实体实例进行泛化,统一使用实体类型标签作为代替。换言之,将实体的人名抽象为一个统一的名称PER,组织名则抽象为ORG。此外,对符合槽填充中的属性槽类型的实例也进行改写,统一泛化为槽类型标签。
(3) 基于SVM的复述识别器
本文根据不同句子之间的树形结构,利用TEM模型进行特征提取,并从中抽取相应的复述特征。复述特征如表2所示。
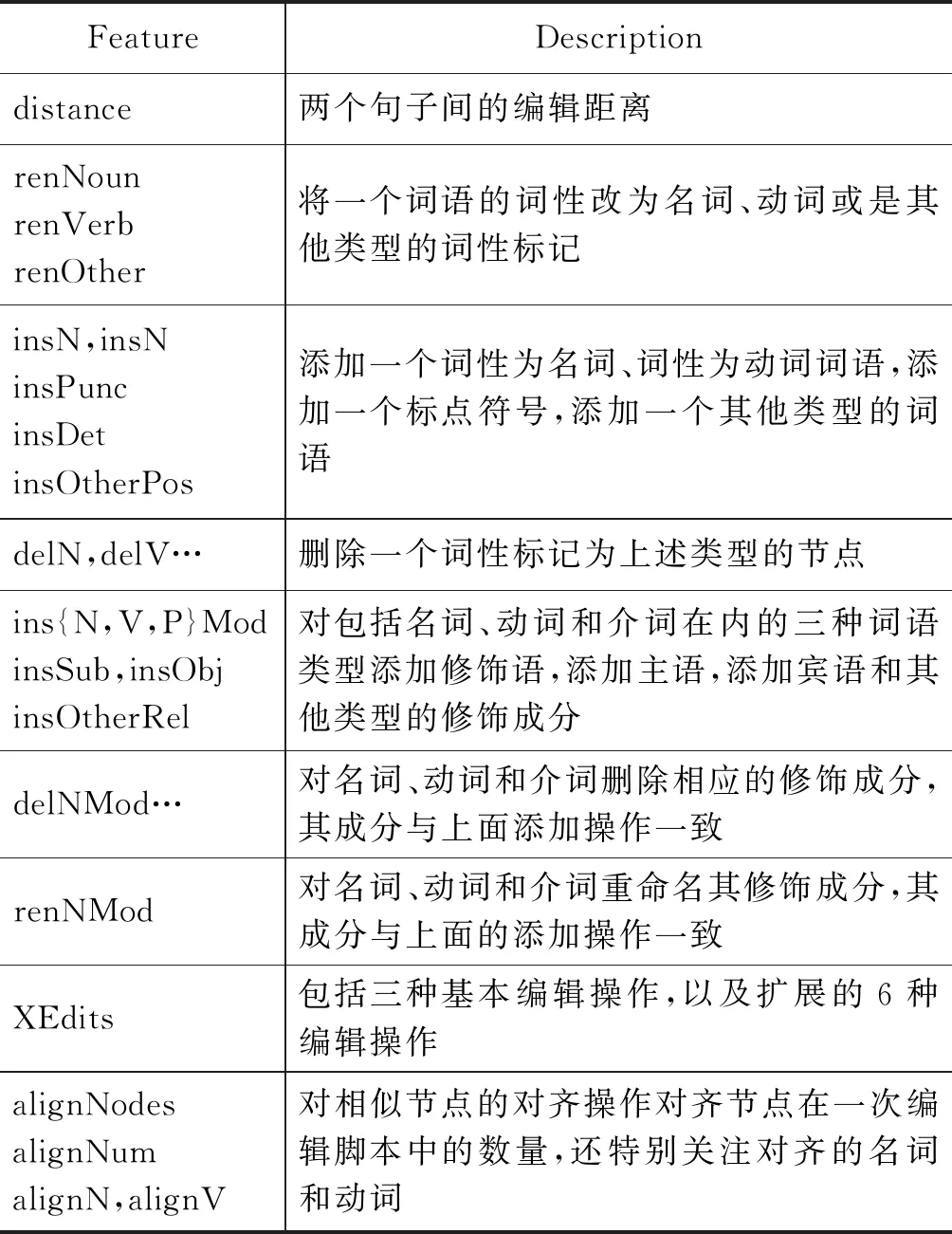
表2 复述特征列表
该表阐述的48维句法特征在传统的树编辑模型中已经取得了较好的效果,但考虑到复述句对中存在大量的近义词或包含关系,因而考虑引入WordNet网络词典,通过词义的特征改善复述的判别效果。例如,下述两个句子中的“战胜癌症”分别使用了“beat”和“defeated”,使用WordNet中的同义词和上下位词关系,可有效地在两者之间形成对齐,提高TEM中对齐编辑操作的召回率。
例1Armstrongbeatcancerthatspreadtohisbrain
例2Armstronghasdefeatedcancerthatspreadhismind
本文利用Dolan等的复述语料训练基于支持向量机(SVM)的二元分类器,正例样本为互为复述的句子,负例为非复述的句对。分类器的具体配置如5.2节所示。
5 实验和结果分析
本文对采用的复述方法(PE)和复述对源信息识别的可用性和可靠性验证(即OHOM和OHET系数)分别进行实验。本节分为三个部分进行陈述,首先介绍评测语料与评测标准,其次给出实验设置,最后对实验结果进行分析。
5.1 评测语料与标准
(1) 评测语料
本文使用微软复述研究计划(Microsoft research paraphrase,MRP)的复述语料对基于树编辑模型的复述二元分类器进行训练与测试。语料包含4 664个句子级复述对。本实验采用其中3 001个复述对构建训练集,其他样本作为测试集。
此外,本文采用Angeli等[4]给出的斯坦福标注语料,总计22 630个有实际标记的句子级源信息。其中,16 972个源信息用作已有知识库,并按照45种实体属性槽类型,划分成45个对应的源信息知识库。其他作为测试样本,共计5 658个。
(2) 评测标准
本文使用精度(accuracy,ACC)对复述二元分类器进行评测。此外,实验使用OHOM和OHET系数作为复述对源信息分类可用性和可靠性的评价标准。
5.2 实验设置
实验采用基于SVM的二元分类器进行复述识别,复述特征如表2所示。分类器采用LibSVM模型,核函数为树核,具体参数配置如表3所示。

表3 复述分类器参数配置
注: 符号注释- iter: 迭代次数;nu: libsvm中树核函数的参数类型;obj: svm文件转化为二次规划求解得到的最小值;rho: 判决函数的偏执项;nsv: 标准支持向量个数。
针对源信息分类检验的实验,使用了5倍交叉验证,每次验证从22 630个句子级源信息中随机选择75%的样本(16 972个源信息)作为知识库,其他作为测试样本。
5.3 实验结果与分析
实验首先验证了复述本身的性能(SF)。评测显示,本文所采用的基于树编辑模型的复述识别方法在开放测试情况下获得72.28%的精度,具有这一性能的复述识别可在一定程度上辅助信息源复述占比(OHOM和OHET)的检验,并使得检验结果具有一定的可参考性。
5.3.1 OHOM检验及分析
在此基础上,实验首先对同类源信息复述占比进行计算,人物类实体所有槽类型的OHOM平均值超过30%,组织机构类实体的OHOM平均值超过20%,如表4所示。这在一定程度上反映出,利用复述对待测语句进行源信息分类有潜在的可用性。当给定一个待测语句,直接通过复述技术寻找语义相似的先验源信息,并依据这一源信息所属的已知槽类型对待测语句进行槽类型标记,能够获得20%~30%以上的召回率。从而可以推测,将这一方法与现有方法进行结合,存在优化源信息分类和槽值填充性能的潜在可能。
实验额外采用人工方式对大量OHOM指标较低的槽类型的源信息进行校对,发现其指标不高的原因主要表现在如下三个方面。
(1) 源信息知识匮乏
观察发现,某些槽类型的源信息知识库样本匮乏,导致利用复述找出同类源信息的概率极大降低。比如,斯坦福源信息数据资源中,per:schools_attended(人物的就读学校类)仅有少量样本,即可供参考的知识很少,而本文所采用的复述方式对语义一致性要求较高,当知识库中样本匮乏、先验源信息多样性较低的时候,复述方法很难将待测源信息投影到对应知识库中的任何一个样本,因此无法借助复述样本直接判定其所属的槽类型。

表4 同类源信息复述占比检验
相反,源信息知识库规模较大的槽类型则可在多样性和信息量上给予源信息分类更大支持。例如,per: date_of_birth(人物的出生日期类)源信息知识库的规模是上述per: schools_attended(人物的就读学校类)的接近4倍(表5),两者的OHOM指标的差异则达到了14倍。

表5 源信息知识库规模对比样例
注: Num: 源信息知识库样本数量
Pcg: 特定实体槽类型知识库的样本数占总体知识库的比重
就这一点而言,探索一种知识库的扩充方法,并了解知识库内样本语义一级的多样性,将有助于基于复述的源信息分类性能。例如,利用主动学习策略实现知识库扩展技术。
(2) 复述对子规格不一
另一发现是复述对子规格不一。比如,待测源信息是一个较短的句子,而其在对应槽类型知识库中的复述是一个较长的句子,这类复述对子的识别错误影响了待测源信息的分类。这一现象说明,本文采用的复述识别方法存在缺陷。
(3) 难以识别隐喻复述
人工观察发现,文本隐喻是复述识别难以处理的主要问题。隐喻特指表达含义的方式并非直接,而是在蕴含较高知识背景下的间接表述。例如,“乔治84岁时去世”为直白表述,而“84年后,乔治的名字永远镌刻在佐治亚平原的石碑之上”则是一种隐喻。假设前者出现于槽类型per:date_of_death(人物死亡日期)的源信息知识库中,并假设后者为测试样本,则本文使用的树编辑模型很难将两者判定为互为复述的样本,从而也无法利用复述实现源信息分类。
就这一点而言,对于隐喻复述这一语言现象,深度复述检测方法具有潜在的应用价值。
5.3.2 OHET检验及分析
实验对异类源信息复述占比(OHET)进行了检验。其侧重检验待测源信息在非同类的槽类型源信息知识库中具有复述的可能性。理想情况下,如果复述方法的性能较高,且对各种复述现象的处理能力很强,则OHET的值越低,越能说明基于复述的源信息分类方法的可靠性较高。原因在于,OHET具有较低水平时,待测源信息在其他槽类型知识库内复述较少,甚至并不存在,从而被误判隶属其他类型属性槽的概率很低。图4和图5分别显示了面向人物和组织机构类实体的不同槽类型的OHET指标。图5中,深色条纹柱状图表示的是一类待测源信息在同类槽知识库中的OHOM指标,其他浅色条纹柱状图表示的是该类待测源信息在其他类实体槽的知识库中的OHET指标。比如,图4中的第一个子图表示的是属性槽per:age(人物年龄类)的所有的待测源信息样本在所有属性槽的源信息知识库中的占比(深色柱状图为平均OHOM,所有浅色柱状图表示平均OHET)。值得说明的是,图中所有属性槽的名称都用较短的编号代替,从而有助于图示的清晰展示,每个编号对应的具体属性槽名称可在图注释中查询。除此之外,某些空图代表斯坦福源信息数据中不具备对应的属性槽。
根据图4和图5的检验结果可以发现,对于大部分槽类型的待测信息源而言,其复述的OHOM指标都大于OHET指标。换言之,这类待测信息都会在同类性属性槽的知识库中找到大量复述(深色柱状图),而在不同类型的其他属性槽的知识库中找到较少复述(浅色柱状图)。这一发现说明,利用复述的OHOM和OHET系数,借助分布概率计算,可以在较多槽类型上获得较好的源信息分类性能。
针对不符合预期的OHET指标对应的槽类型样本,加入了人工校对环节,并发现了下属语言现象。
(1) 多重类型复述
多重类型复述指的是某一待测源信息包含了多种槽类型的实例,例如,“他出生于1991年,现年刚满18周岁”,这一源信息既可以作为per:date_of_birth(人物出生日期类)槽类型的源信息,也可作为per:age(人物年龄类)槽类型的源信息,致使这一样本在两种槽类型的源信息知识库中都可能存在复述。同理,知识库中的源信息也存在相同现象。在这一情况下,如果某一类型的源信息知识库样本量远多于另一个类型的源信息知识库样本,则多重类型复述待测样本在存在前者中的OHET始终高于在后者的风险。换言之,复述可能倾向于将样本量大的槽类型始终判定为待测源信息的类型。
(2) 复述识别错误
如前文所述,本文采用的基于树编辑模型的复述识别方法存在一定误差。实验观察发现,这类误差并不随机,而是在特定的语义表述上频繁出现。然而,这种较为集中的判断失误往往会集中在特定槽类型的源信息上,从而使得这类复述识别频繁出错,不断误导源信息的分类。

图4 针对人物类槽类型的源信息OHET检验注: Per_T(i){i=1-17}为序号,代替原有属性槽类型的类型名在上图中予以显示。Per_T1: per: age; Per_T2: per: alternate_names; Per_T3: per: cause_of_death; Per_T4: per_cities_of_residence;Per_T5: per: city_of_birth; Per_T6: per: city_of_death; Per_T7: per: date_of_birth; Per_T8: per: date_of_death;Per_T9: per: employee_or_member_of; Per_T10: per: origin; Per_T11: per: other_family;Per_T12: per: parents; Per_T13: per: religion; Per_T14: per: schools_attended;Per_T15: per: siblings; Per_T16: per: spouse;Per_T17: per: title;
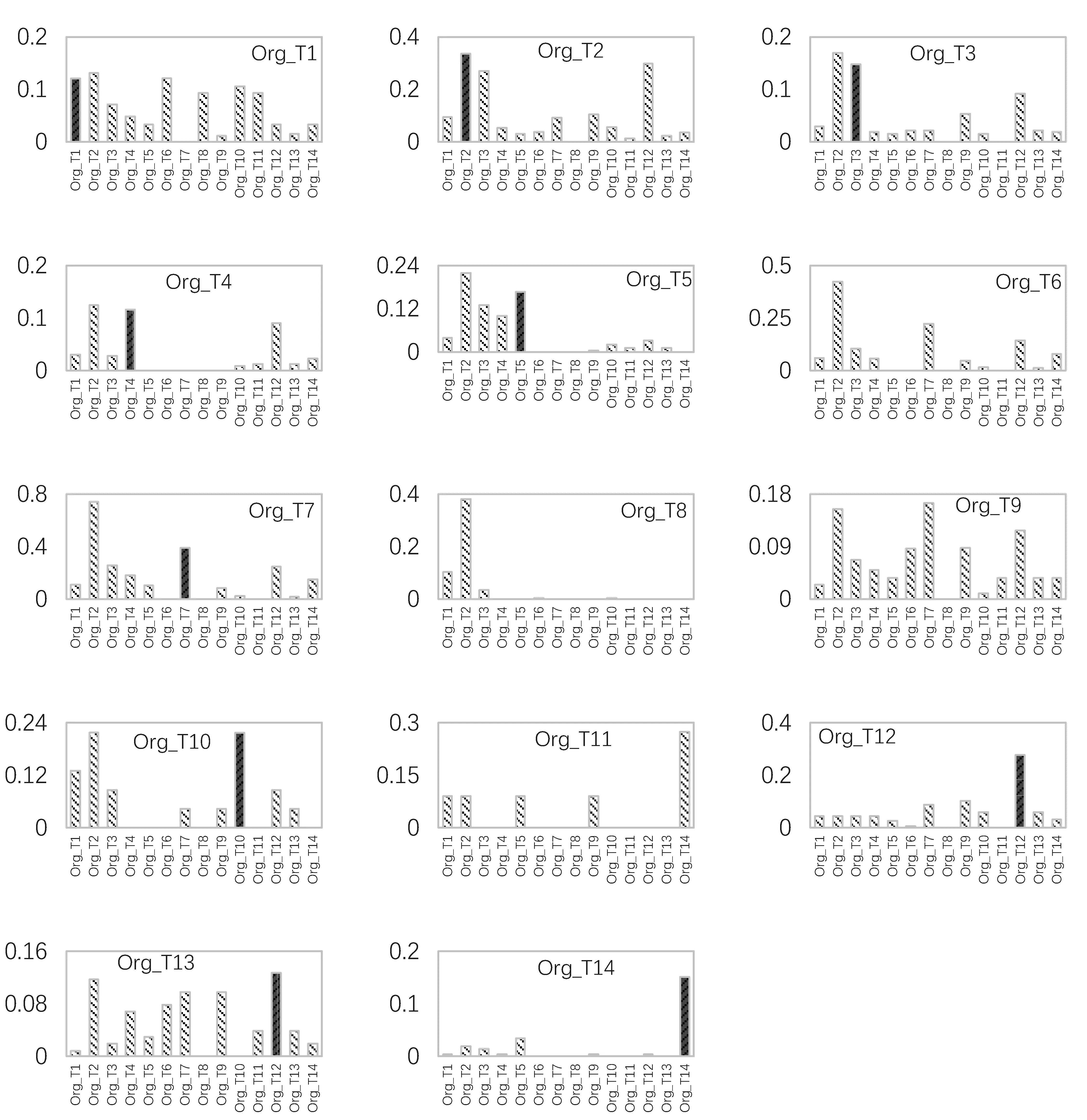
图5 针对组织机构槽类型的源信息OHET检验注: Org_T(i){i=1-14}为序号,代替原有组织机构属性槽的类型名在上图5中予以显示。Org_T1: org: alternate_name; Org_T2: org: city_of_headOuarters; Org_T3: org: country_of_headOuarters; Org_T4: org: date_founded;Org_T5: org: founded_by; Org_T6: org: members; Org_T7: org: member_of;Org_T8: org: number_of_employe_members; Org_T9: org: parents;Org_T10: org: political_religious_affiliation; Org_T11: org: shareholdersOrg_T12: org: stateorprovince_of_headOuarters; Org_T13: org: subsidiariesOrg_T14: org: top_members_employee;
就这一点而言,采用多种复述技术进行互补,将可能有效改善这一现状。比如,引入基于深度学习的复述识别技术,以及利用半监督的复述模板技术等,并结合基于排序学习的多特征融合技术,实现更为有效的复述识别。
6 总结与展望
本文剖析了槽填充任务性能不好的原因,指出了其任务环节中的薄弱部分——源处理,并基于此将源处理与属性实例抽取剥离,设置了一个独立的关键研究点,针对复述在源信息分类上的可用性和可靠性进行了详细的分析。
此外,本文通过一种基于树编辑模型的识别方法,实现了复述的判别,并在槽填充源信息数据集上检验了同类源信息复述占比(OHOM)和异类源信息复述占比(OHET)系数。在此基础上,结合人工观测与校对,发现多种源信息分类错误的语言现象,并提出了相应的解决方法和思路。
总体而言,本文验证了复述对实体槽类型源信息分类的可用性。对于可靠性的进一步提升,本文建议在利用主动学习的多样性源信息知识库构建的基础上,借鉴目前基于深度学习的复述识别方法,融合语义蕴含和隐喻的特征分析与表示,借助多特征融合和排序学习技术,实现更为深入的信息源分类方法,以有效支持属性槽填充技术的发展。
