大数据流式计算框架Heron环境下的流分类任务调度策略
2019-08-01张译天于炯鲁亮李梓杨
张译天 于炯 鲁亮 李梓杨


摘 要:新型大数据流式计算框架Apache Heron默认使用轮询调度算法进行任务调度,忽略了拓扑运行时状态以及任务实例间不同通信方式对系统性能的影响。针对这个问题,提出Heron环境下流分类任务调度策略(DSC-Heron),包括流分类算法、流簇分配算法和流分类调度算法。首先通过建立Heron作业模型明确任务实例间不同通信方式的通信开销差异;其次基于流分类模型,根据任务实例间实时数据流大小对数据流进行分类;最后将相互关联的高频数据流整体作为基本调度单元构建任务分配计划,在满足资源约束条件的同时尽可能多地将节点间通信转化为节点内通信以最小化系统通信开销。在包含9个节点的Heron集群环境下分别运行SentenceWordCount、WordCount和FileWordCount拓扑,结果表明DSC-Heron相对于Heron默认调度策略,在系统完成时延、节点间通信开销和系统吞吐量上分别平均优化了8.35%、7.07%和6.83%;在负载均衡性方面,工作节点的CPU占用率和内存占用率标准差分别平均下降了41.44%和41.23%。实验结果表明,DSC-Heron对测试拓扑的运行性能有一定的优化作用,其中对接近真实应用场景的FileWordCount拓扑优化效果最为显著。
关键词:大数据;流式计算;Apache Heron;任务调度;数据流分类;通信开销
中图分类号:TP311
文献标志码:A
文章编号:1001-9081(2019)04-1106-011
0 引言
随着云计算、物联网、移动互联、社交媒体和人工智能等新型信息技术和应用模式的不断发展,数据正以前所未有的方式推动人类社会进入大数据时代[1]。国际数据公司(International Data Corporation, IDC)发布的白皮书《数据时代2025》中显示,预计到2025年全球互联网数据总量达162ZB,其中超过1/4的数据为实时数据,而物联网实时数据将占这部分数據的95%以上[2]。面对实时大数据具有的实时性、易失性、突发性、无序性和无限性的新特征[3],传统的MapReduce等批处理方式不再适用,分布式大数据流式计算应运而生。流数据处理摒弃了传统批处理中对数据先存储后计算的方式,将数据以数据流的形式在数据产生初期进行计算,使用可靠传输模式而不对计算中间结果进行存储,在对数据分析实时性要求较高的场景中得到了广泛的应用,并不断融入实时图像识别、智慧城市等人工智能的发展中。
目前,在典型的流数据处理系统(例如,Storm[4]、Flink[5])中,默认调度算法常采用静态轮询调度算法。该算法实现简单,在拓扑提交时对拓扑进行任务分配,拓扑运行期间任务分配状态不再发生改变;但静态轮询调度算法在进行任务分配时,仅考虑资源的可满足性将任务均匀分配到各个工作节点,未考虑拓扑中任务间的关联关系和节点间的通信开销,会对集群性能产生一定影响。针对这一问题,国内外研究人员针对不同流式计算平台提出在线调度算法,在拓扑运行过程中通过实时监测集群运行状态,对已分配的任务进行重调度或调整,以使集群具有更高效的性能。针对Storm环境,文献[6]提出自适应调度策略,分为离线调度和在线调度。其中在线调度通过实时监测拓扑运行过程中CPU负载和工作节点间数据流流量等数据,依次将通信开销较大的一对任务调度到CPU负载较小的工作节点中。该策略可以较好地降低Storm的通信开销,但实验中使用的是自定义链式拓扑,缺乏一定的代表性。文献[7]提出流量感知在线调度策略T-Storm,旨在最小化进程间和工作节点间通信开销,同时实现了细粒度的任务分配控制,可以通过调整预设参数控制工作节点数量。但该策略忽略了直接通信的一对任务之间的数据流情况且调度执行开销较大。文献[8]提出资源感知调度策略R-Storm,通过将CPU、内存和网络带宽资源映射为三维空间向量,使用最小化向量距离的方法寻找任务和工作节点的分配关系,从而最大化资源利用并提高系统吞吐量。该策略充分考虑了集群资源的有效利用,但拓扑中各任务的资源需求由编程人员设定而非实时监测获得,很难应用于资源需求变化较大的在线调度。文献[9]提出一种异构环境下的任务迁移策略TMSH-Storm,将超出阈值节点中的阻尼线程细粒度地迁移至满足条件的目标节点,避免了资源溢出后的任务重部署,可以较好地降低调度时延和节点间通信开销。针对Flink环境,文献[10]提出流网络的流式计算动态任务调度策略。该策略通过建立流网络模型,基于最大流算法使模型在满足延迟约束前提下提高集群的实际吞吐量,能在一定程度上解决输入速率增加阶段出现的计算延迟升高问题。
但该策略仅关注集群输入速率急剧上升阶段的性能优化,且没有考虑流网络容量动态变化的问题。针对其他流式计算系统,文献[11]从资源分配的角度出发,对多代分布式流处理系统的弹性资源调度机制进行对比并提出未来研究方向。文献[12]基于拓扑任务与集群资源的分配与映射关系提出模型驱动的调度策略,为流处理系统提供高效的资源利用率和吞吐量。文献[13-14]侧重于流处理系统的稳定性,分别提出一种基于队列的稳定性预测模型和一种稳定的在线调度策略以优化系统性能。
Heron[15-17]是Twitter为解决其上一代分布式流处理平台Storm在可扩展性、可调试性、可管理性以及集群资源共享等方面问题,而构建的新一代分布式流处理平台[15]。Heron在2015年已经取代Storm,成为Twitter实际使用的实时数据处理系统[17],现已进入Apache开源项目孵化器。Heron在设计层面对Storm进行多方面优化的同时,其默认调度策略仍使用轮询(Round Robin,RR)算法进行任务实例分配。该算法根据拓扑中任务实例资源需求和容器资源需求,创建用于调度的任务分配计划,然后交由Heron调度器(Aurora[18]、Mesos[19]、YARN[20]等)分配至工作节点。对于Twitter目前使用的Aurora调度器,Heron将一个拓扑对应于Aurora中一个工作(Job),一个容器与其中分配的任务实例作为Aurora的一个资源分配单元,由Aurora负责将这些单元分配至集群中满足资源需求的工作节点中运行。在配置了Aurora调度器的Heron集群中,工作节点资源分配由Mesos负责进行,其采用DRF(Dominant Resource Fairness)资源分配策略为Aurora框架中提交的任务寻找集群中注册的合适工作节点进行任务分配。
在Heron调度策略和任务分配过程中仍存在如下问题:1)任务分配没有考虑任务实例间通信开销,忽略了节点间通信和节点内通信的差异;2)任务分配仅考虑了任务实例和工作节点资源的约束关系,且算法采用资源最大化对齐的方式容易造成资源浪费;3)仅提供了静态调度策略,无法针对运行状态下的拓扑进行实时调度。
针对Heron默认调度策略中存在的上述问题,本文提出流分类调度策略(task scheduling strategy based on Data Stream Classification in Heron, DSC-Heron),主要工作如下:1)提出Heron作业模型,将拓扑中任务实例通信方式划分为节点间、容器间和实例间通信,明确不同通信方式间的通信开销差异。
2)以Heron作业模型为基础,提出资源约束模型、最优通信开销模型和流分类模型,作为提出DSC-Heron任务调度策略的理论依据。
3)提出流分类调度策略,包括流分类算法、流簇分配算法和流分类调度算法。该策略首先根据数据流实时大小对数据流进行分类,然后以高频数据流关联的高频流簇为单位进行任务调度,使得拓扑的任务分配在满足资源约束条件的同时最小化节点间通信开销。
4)使用Heron示例拓扑和自定义拓扑对流分类调度策略进行性能评估。实验结果表明,相较于Heron默认调度策略,DSC-Heron在系统完成时延、节点间数据流大小和吞吐量方面均有一定的优化效果。
1 Heron作业模型
在Heron中,拓扑是用户定义流式作业的抽象,使用有向无环图(Directed Acyclic Graph, DAG)表示,由组件和数据流构成。组件分为Spout和Bolt两类:Spout为数据源编程单元,可以从Kafka[21]、DistributedLog[22]或HDFS(Hadoop Distributed File System)中不间断地读取数据,以数据流的形式传递给下游组件;Bolt为数据流处理单元,用于实现数据处理逻辑。数据流是对组件间以元组形式进行数据传递的抽象,可以通过不同的流组模式定义元组的传递和分组方式。由此定义拓扑逻辑模型如下。
Heron中为提高系统并行度和数据处理速度可以为拓扑中每个组件定义运行并行度,并在拓扑提交时为每个组件创建相应数量的任务实例。每个任务实例运行一个Java进程且运行在一个JVM中。由此定义拓扑实例模型如下。
根据实例分配模型可知,Heron任务实例之间的通信需要经过所在容器中的SM进行路由。集群中各个SM彼此连接形成一个全连接网络,将复杂度为O(N(N-1)/2)的N个任务实例间通信,通过M个SM简化为O(M(M-1)/2),其中NM。因此,在Heron集群中存在三种不同的通信方式:1)工作节点间通信,即集群不同物理工作节点间任务实例的通信方式。这种通信方式中,数据流需要经过源任务实例、源任务所属SM、目的任務所属SM和目的任务实例进行传输,会占用大量的网络带宽资源,是集群中通信开销最大的一种通信方式。如图3中,任务实例Ia和Id1间的通信即属于工作节点间通信。
2)容器间通信,即同一工作节点、不同容器中任务实例之间的通信方式。这种通信方式不占用网络带宽,数据流在同一节点的不同任务间进行传递,但仍需要经过源任务实例、目的任务实例以及各自所属的SM,属于进程间通信且通信开销较小。如图3中,任务实例Id2和Ic间的通信即为容器间通信方式。
3)实例间通信,即同一工作节点且同一容器中任务实例间的直接通信。这种通信方式在一个容器中进行,数据流只经过一个SM进行传输,是三种通信方式中通信开销最小的一种。由于在Heron中每个任务实例都是一个Java进程,因此这种通信方式也属于进程间通信,但由于减少了数据流经过的SM数量,因此通信开销较容器间通信开销小。如图3中,任务实例Ib和Ig间即属于实例间通信方式。
2 问题建模与分析
本章在Heron作业模型的基础之上提出资源约束模型、最优通信开销模型和流分类模型。其中资源约束模型为任务分配的基础条件;最优通信开销模型论证了节点间和节点内通信开销的相互关系,为最小化通信开销的任务调度过程提供依据;流分类模型定义了拓扑中数据流分类的理论基础。
2.1 资源约束模型
在Heron应用环境中,为使各个工作节点不会出现满负荷运行状态以影响集群运行性能,需要为每个工作节点预留少量的计算资源。因此,在上述资源约束中,α、 β、γ分别为集群管理人员为CPU、内存和网络带宽资源设定的资源阈值参数,该参数可根据集群资源情况进行设置。
2.2 最优通信开销模型
2.3 流分类模型
3 流分类调度策略
本章基于上述模型提出流分类调度策略(DSC-Heron),包括流分类算法、流簇分配算法和流分类调度算法。其中流分类算法以流分类模型为基础,以数据流实时大小为依据对数据流进行分类;流簇分配算法以高频流簇为基本单元进行任务分配;流分类调度算法对不同类别的数据流依次进行调度,最终完成目标任务分配计划的构建。
3.1 流分类算法
通过使用3.4节提出的负载监测模块对集群中任务实例以及实例间数据流大小进行监测,实时获取拓扑中任务实例间数据流大小,得到拓扑的数据流集合S={s1,2,s1,3,…,sI-1,I}作为输入;然后根据流分类模型将集合S划分为高频数据流集Hf、中频数据流集Mf和低频数据流集Nf。具体算法如算法1所示。
算法1 流分类算法。
输出 高频数据流集Hf;中频数据流集Mf;低频数据流集Nf。
步骤1 根据S中各个数据流大小vij,kl,使用式(8)计算数据流总量V;使用式(9)计算数据流平均值;使用式(10)计算sij,kl的绝对偏差值;使用式(11)计算数据流总绝对偏差ΔV;使用式(12)平均偏差Δ。
步骤2 根据vij,kl大小降序排序S并进行遍历,进行如下判断:若数据流sij,kl满足式(13),将其加入高频数据流集Hf;若满足式(14)或式(15),将其加入中频数据流集合Mf;若满足式(16),将其加入低频数据流集合Nf。
步骤3 返回Hf、Mf和Nf。
流分类算法步骤1中包括两次对数据流集合S的遍历。第一次遍历数据流集合S,计算出拓扑数据流总量V,进而可以计算数据流平均值。第二次遍历数据流集合S,由数据流平均值计算各个数据流的绝对偏差值,同时累加计算所有数据流的总绝对偏差值ΔV和平均偏差值Δ。算法步骤2~3根据流分类模型中的式(13)~(16),使用步骤1计算所得值,对数据流集合遍历的同时进行数据流的分类并返回分类所得不同数据流集合。由此可知,该算法的时间复杂度为数据流集合S的大小,即O(S)。
3.2 流簇分配算法
由定义4可知,DSC-Heron将高频数据流关联的高频流簇作为调度的基本单元,尽可能得将同一高频流簇相关的任务实例调度到同一工作节点。在调度的过程中,需要根据当前高频数据流关联的任务实例在高频流集合Hf中递归搜索与之关联的流簇,然后对该流簇中的任务实例进行分配,由此得到流簇分配算法。具体算法如算法2所示。
算法2 流簇分配算法。
输入 数据流sij,kl关联的任务实例Iij和Ikl;高频数据流集合Hf;目标节点nk;原始任务分配计划PPold;当前目标任务分配计划PPnew。
输出 更新后的目标任务分配计划PPnew。
步骤1 根据Iij和Ikl在Hf中搜索关联的高频数据流sgh,ij和skl,mn,若不存在相关联高频数据流或存在任务实例Igh、Imn且均已分配则递归结束。若存在且未分配,根据PPold判断Igh和Imn是否分别位于目标节点nk中:如果是,判断将该任务实例仍分配至nk中是否满足资源约束条件:若满足则进行分配,更新PPnew并进行步骤2;若不满足则查找当前PPnew中负载最小的工作节点进行调度。
如果否,判断将未分配任务实例调度到nk节点之后是否满足资源约束条件:若满足进行调度,更新PPnew并进行步骤2;若不满足则查找当前PPnew中负载最小的节点进行调度。
步骤2 在Hf中递归查找Igh和Imn关联的高频数据流sef,gh和smn,op,若存在任务实例Ief,Iop未分配,重复步骤1直至递归结束。
流簇分配算法是一个递归的集合搜索过程,它将一个高频数据流关联的源任务实例、目的任务实例和高频数据流集合作为输入,分别对源任务实例和目的任务实例在高频数据流集合中搜索相关联的高频数据流,并依次对搜索结果中包含的未分配任务实例进行调度,以更新目标任务分配计划。同时,该搜索过程也是构建该数据流高频流簇SC的过程。若一条高频数据流在高频数据流集合中不存在关联的高频流或存在且均已经分配完成则递归结束,返回对该条数据流构建完成的目标任务分配计划。流簇分配算法将每个高频数据流的关联的流簇集合整体作为任务调度对象,旨在最大化节点内任务间数据流,根据最优通信开销模型即等价于最小化节点间数据流,以减少拓扑整体通信开销。根据该递归算法可知,其时间复杂度为:O(Hf·SC)。其中,由于SC的最大值等于拓扑关键路径长度,因此该算法的运行时间与拓扑的层数以及高频数据流集合规模有关。
3.3 流分类任务调度算法
流分类调度算法整合了流分类算法和流簇分配算法,将流分类算法中得到的高频流集合作为输入,通过遍历数据流集合S,首先对其中高频数据流进行分配并对该数据流调用流簇分配算法进行任务调度,直至所有的高频数据流分配完成,然后对未分配的中频数据流和低频数据流分別调度,完成构建目标任务分配计划。具体算法如算法3所示。
算法3 流分類调度算法。
输出 目标任务分配计划PPnew。
初始化 由负载监测模块获取当前各数据流大小vij,kl和各任务实例CPU负载wIij以初始化数据流集合S与任务实例负载集合W;使用流分类算法得到各数据流分类集合Hf、Mf、Nf;初始化PPnew为空。
步骤1 根据数据流vij,kl的大小对集合S进行降序排序,遍历集合S中各数据流sij,kl。
步骤2 如果sij,kl属于高频数据流集合Hf,进行如下步骤:①判断数据流sij,kl关联的两个任务实例Iij和Ikl是否在PPnew中已经重新分配,若都已经重新分配则对该数据流的调度结束。
②若仅其中一个任务已分配,这里以Iij已分配至工作节点nk且Ikl未分配为例,进行如下步骤:(a)根据PPold判断Iij和Ikl是否位于同一节点。若在同一节点nk,更新PPnew并调用流簇分配算法,分配sij,kl关联的其他高频数据流,调度结束。
(b)若Iij和Ikl位于不同节点,根据资源约束模型判断Ikl调度到工作nk后是否满足资源约束,若满足则将Ikl调度到工作节点nk,更新PPnew并调用流簇分配算法,分配sij,kl关联的高频数据流,调度结束。若不满足,则根据W查找当前PPnew中负载最小节点分配任务Ikl。
③若任务实例Iij和Ikl均未分配,进行如下步骤:(a)根据PPold判断Iij和Ikl是否位于同一节点,若在同一节点nk,更新PPnew并调用流簇分配算法,分配sij,kl关联的高频数据流,调度结束。
(b)若Iij和Ikl位于不同节点ni和nk中,计算当前分配计划PPnew中ni和nk已分配任务的负载,将Iij和Ikl分配到负载较小的节点中,并根据资源约束模型判断调度过程中是否满足资源约束,若满足则逐个调度任务,更新PPnew并调用流簇分配算法,分配sij,kl关联的高频数据流,调度结束。若在调度任务实例Ikl时已不满足资源约束條件,则将其调度至当前负载最小的节点。
步骤3 如果sij,kl属于中频数据流集合Mf,则重复步骤2中的①~③,但不再调用流簇分配算法,此时高频数据流已经调度完成。
步骤4 结束数据流集合S的遍历,对剩下低频数据流集合Nf中sij,kl计算当前PPnew中各个节点的任务负载情况,优先将任务Iij、Ikl调度到负载较轻的节点中并保证满足资源约束条件,直到全部任务调度完成。
算法步骤1中根据集合中数据流的大小对数据流集合S进行降序排序,这样可以保证在对集合S进行遍历时,对高频数据流进行优先处理。
步骤2对集合S进行遍历,对属于高频数据流集合的当前数据流进行调度。该步骤中包含的①~③分别是对当前高频数据流关联的两个任务实例是否在目标任务分配计划中分配完成进行判断,目的是为了避免对可能出现在不同高频数据流中的同一任务实例进行重复调度。步骤①中,如果当前的两个任务实例均已经在目标任务分配计划中分配完成,则不再进行重复调度。步骤②中,当前两个任务实例中仅有一个任务实例已经分配,则优先将未分配的任务实例调度到已分配任务实例当前所在的工作节点中,此举是为了最大化节点内任务实例间的直接通信以最小化节点间的通信开销。但在这种调度的过程中,需要判断调度发生后目标节点是否满足资源约束条件:若满足则可以进行调度,完成最大化节点内通信开销;若不满足,则需要使用当前目标任务分配计划PPnew和任务负载集合W寻找当前集群中负载最小的工作节点分配该任务,目的是为了在未能满足最小化通信开销的情况下,尽量平衡集群各工作节点负载从而在负载均衡的角度优化集群性能。步骤③中为当前两个任务实例均未重新分配,需要依次对两个未分配任务实例进行调度。首先根据原始任务分配计划PPold判断两个任务实例是否位于同一节点,并优先将两个任务调度到其中当前负载较轻的工作节点中,以最小化通信开销的同时均衡集群负载。但在对两个任务进行依次调度时,均需要对目标工作节点计算调度完成后的资源约束情况,若不满足资源约束,则同步骤②中的方法相同,将该任务实例分配至当前集群中负载最小的工作节点。
通过步骤1~2,算法将数据流集合S中包含的高频数据流及其关联高频流簇调度完成,因此步骤3对中频数据流集合中的数据流进行调度时,不需要考虑高频流簇的分配,仅对中频数据流本身继续调度。
算法步骤4进行之前,前序算法步骤已经对数据流集合S中高频数据流和中频数据流调度结束,此时只剩下低频数据流,而低频数据流在拓扑中对整体通信开销的影响最小,因此仅对其进行负载均衡处理,依次将低频数据流调度至集群当前负载较小的工作节点中,最终完成全部数据流的调度。根据该算法步骤可知,该算法在对数据流集合S遍历的同时分别将属于各个类别的数据流调度至符合条件的工作节点中,因此算法时间复杂度为O(S·N)(其中N为工作节点数量)。
3.4 算法部署与实现
Heron为编程人员提供了可扩展的Custom Scheduler[23]实现。为实现自定义调度器,需要实现与Heron调度器相关的IPacking、ILauncher、IScheduler和IUploader四个Java接口。在本文实验中,DSC-Heron基于Heron中默认AuroraScheduler进行部署和实现,Uploader仍使用HDFS不作修改,但分别实现了以下三个接口:1)DSCPacking。实现IPacking接口,用于部署DSC-Heron以构建目标任务分配计划,为调度控制模块对拓扑任务的重调度提供依据。
2)DSCLauncher。实现ILauncher接口,替换原有的AuroraLauncher。用于在拓扑提交后创建DSCScheduler对象实例并调用其onSchedule方法启动自定义调度器。
3)DSCScheduler。实现IScheduler接口,替换默认AuroraScheduler,拓扑提交后将由该调度器完成拓扑的初次调度。其中部署调度触发模块和调度控制模块,用于重调度的触发以及使用DSCPacking创建的目标任务分配计划更新拓扑,完成重调度过程。
在拓扑重调度的过程中,需要实时获取各工作节点以及工作节点内各任务实例的CPU负载。对于各任务进程的CPU资源占用信息,可以通过Java API中ThreadMXBean类的getThreadCpuTime(long id)方法获取,其中id为各Java进程中运行任务实例的线程ID。对于各工作节点的CPU负载,可以通过对运行在该工作节点中的任务实例CPU负载进行累加求得。此外,工作节点中相关硬件参数可通过/proc目录下的相关文件获得。在代码编写完成后,使用Maven创建自定义调度器的jar文件,将其放置到${HERON_HOME}/lib/scheduler目录下,并在${HERON_HOME}/conf/aurora目录下的scheduler.yaml文件中进行配置DSCScheduler和DSCLauncher类名后即可使用。
改进后的Heron系统结构如图4所示。其中,在Heron系统结构中新增的四个自定义模块分别是:
1)负载监测模块。部署在各个工作节点中,负责在一定时间窗口内监测工作节点中运行的任务实例CPU负载、任务间数据流大小和内存资源占用等信息,并将监测信息实时写入数据存储模块。使用该模块,需要在拓扑中各Spout的open()和nextTuple()方法以及各Bolt的prepare()和execute()方法中调用该模块。
2)调度触发模块。部署在DSCScheduler中并在该调度器对象实例化时启动。负责在满足重调度触发条件时调用调度控制模块中重调度方法完成DSC-Heron的重调度过程。
3)数据存储模块。存储并实时更新负载监测模块获取的任务实例监测信息,这里使用MySQL数据库实现。
4)调度控制模块。完成流分类调度策略的核心模块,通过调度触发模块调用。根据原始任务分配计划获取由DSC-Heron构建的目标任务分配计划,更新拓扑任务分配以完成任务调度过程。该模块采用与DSCScheduler松耦合的设计范式,便于未来部署其他在线重调度算法。
4 实验
4.1 实验环境
实验环境采用硬件配置相同的PC搭建一个9节点的Heron集群。其中一个主控节点运行Heron、Heron Tracker、Heron UI、Mesos Master和Aurora Scheduler;一个协调节点运行ZooKeeper和MySQL等服务;一个节点运行Heron自动创建的拓扑管理进程(Topology Master)用于管理拓扑整个生命周期;其余节点为工作节点分别运行Mesos Agent、Aurora Observer和Aurora Executor,负责实际运行拓扑的任务实例。此外,集群中各节点共同运行HDFS作为Heron的Uploader系统组件并负责共享Heron Binaries文件。实验集群的软硬件配置如表1所示。
实验采用Heron Github开源项目[24]提供的Sentence WordCount和WordCount示例拓扑以及自定义FileWordCount拓扑,三种拓扑中采用不同的结构和数据源以评估DSC-Heron在不同场景中的表现。其中SentenceWordCount拓扑包含三层结构:
第一层Spout组件随机创建一个长度为128×1024的句子数组并随机发射;
第二层Bolt组件(名为Split)通过空格字符分割句子产生单词;
第三层Bolt组件(名为Count)接受Split中发送的单词并进行计数。
WordCount为两层结构,Spout组件(名为word)随机生成单词并发射,由Bolt(名为consumer)组件进行统计。FileWordCount拓扑结构与SentenceWordCount相同,但数据源来自原版英文历史小说《双城记》,格式为txt。SentenceWordCount拓扑相对于WordCount的两层结构,包含的数据流数量和流簇规模较大,两者对比有利于評估系统性能的优化效果。
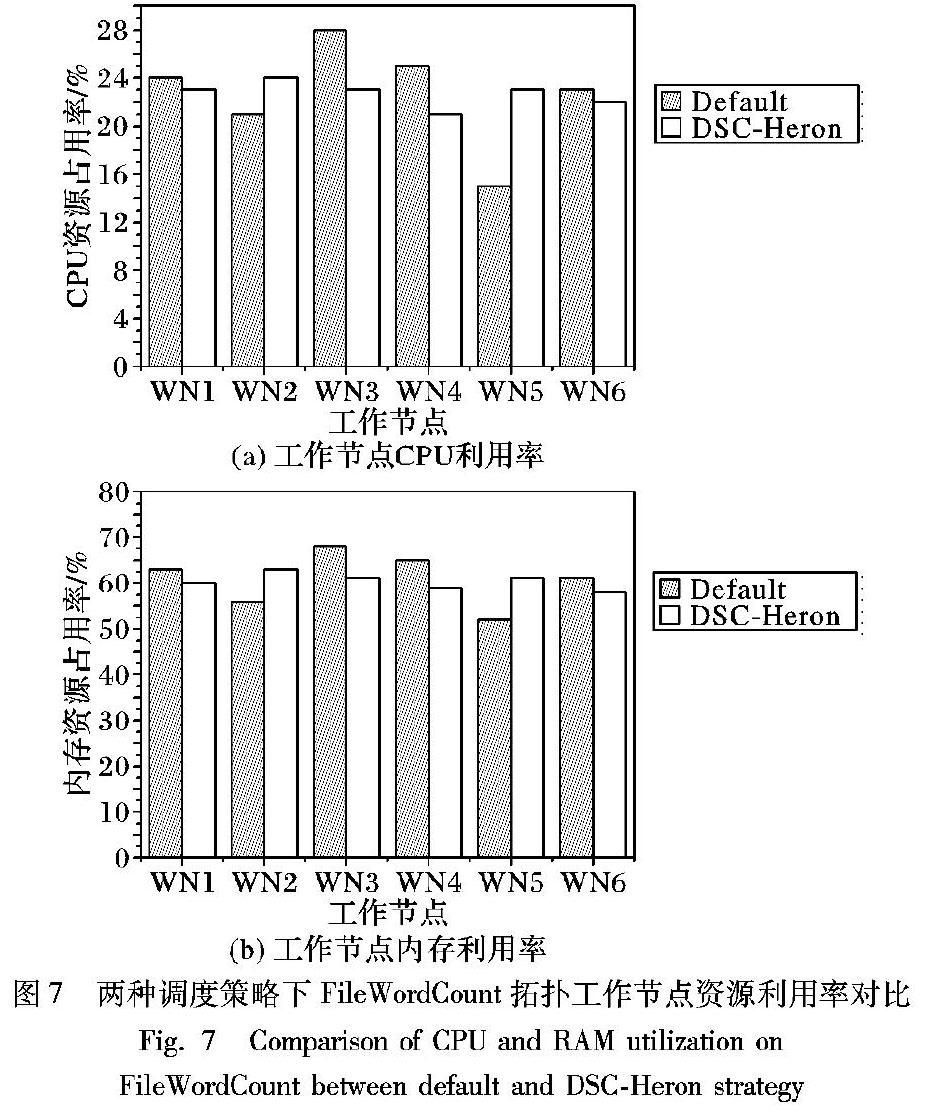
FileWordCount拓扑数据源采用真实文本文档,其中各单词出现的频率不尽相同,在实际的应用场景中有一定代表性。
实验拓扑中设置了各组件的并行度和资源需求,数据流在各组件间的传递模式,可用的容器数量以及资源需求,详细的测试拓扑运行参数配置如表2所示。
表2中:topology.max.spout.pending(简称为pending)的值为Spout缓存队列的最大容量,当队列长度达到设置的容量时Spout停止发送数据,当队列长度小于设定值时Spout持续发送数据,从而实现对拓扑数据传输速率的控制。topology.message.timeout.secs(简称为timeout)的值配合ATLEAST_ONCE可靠性语义模式和Acknowledgement[25]机制使用。实验拓扑在Bolt组件中设置ack机制,唯一标识标记的元组从Spout中发射,在timeout设定的时间内经过各个组件处理完成后由Spout中ack方法进行确认,若没有在该参数规定的时间内接受到指定元组,Heron则会重新发送以保证ATLESAT_ONCE的有效进行。
对于参数pending和timeout的取值,在默认调度策略下使用SentenceWordCount拓扑经过多次实验得到表3所示参数取值对拓扑元组失败率的影响,在表2所示参数下其他测试拓扑实验结果与此类似。其中, pending的值设置为100且timeout值设置为60s时,虽然拓扑运行前5min的失败率较低,但由于pending的值较小无法正常发挥集群运行性能且无法体现真实应用场景;当pending的值设置为1000且timeout的值设置为60s时,拓扑提交后前5min内的元组失败率为6.6%,相对于相同pending值但timeout值为30s时拓扑运行的20%失败率,元组失败率明显降低并且有少量拓扑出现重新发送的情况,该场景较符合真实应用场景且集群能够快速地趋于稳定。而当pending的值设置为10000且timeout的值为60s时,元组失败率较高,此时虽然提高timeout参数值可以降低元组失败率,但会导致CPU负载过高从而使集群运行情况不可预测。因此, pending的值设置为1000,timeout的值设置为60s,在当前集群的配置下能够较好地满足实验的需要。
此外,由于集群中主控节点独立运行,拓扑管理器单独运行于一个工作节点的容器中,ZooKeeper和MySQL等服务进程占用一个节点资源,因此集群中可分配任务实例的工作节点数量为6。在表2中将topology.stmgrs的数量设置为6,即容器数量与集群中工作节点的数量相同,意味着每个工作节点中仅运行一个容器,从而消除容器间通信带来的开销,重点关注节点间通信和节点内实例间通信的转换对集群性能的影响。
为验证DSC-Heron的有效性,本文与Heron默认的轮询调度策略进行了对比,表4中列出了DSC-Heron的参数设置,其中主控节点根据reschedule.timeout参数触发重调度。工作节点中α、 β和γ为资源约束模型中设置的资源阈值参数,为避免节点满负荷运行影响集群性能,α值设置为0.7,由于Heron容器中已为系统级进程留有内存资源,因此β和γ的值设置为1。time.window.length和time.window.count为负载监测模块中设置的数据统计窗口大小和数量,即使用长度为5s的时间窗口对数据采样3次统计平均值。此外Heron集群的其他配置参数与默认轮询调度算法的参数均取默认值。
