基于AUC及Q统计值的集成学习训练方法
2019-08-01章宁陈钦
章宁 陈钦

摘 要:针对借贷过程中的信息不对称问题,为更有效地整合不同的数据源和贷款违约预测模型,提出一种集成学习的训练方法,使用AUC(Area Under Curve)值和Q统计值对学习器的准确性和多样性进行度量,并实现了基于AUC和Q统计值的集成学习训练算法(TABAQ)。基于个人对个(P2P)贷款数据进行实证分析,发现集成学习的效果与基学习器的准确性和多样性关系密切,而与所集成的基学习器数量相关性较低,并且各种集成学习方法中统计集成表现最好。实验还发现,通过融合借款人端和投资人端的信息,可以有效地降低贷款违约预测中的信息不对称性。TABAQ能有效发挥数据源融合和学习器集成两方面的优势,在保持预测准确性稳步提升的同时,预测的一类错误数量更是进一步下降了4.85%。
关键词:集成学习;曲线下面积;Q统计值;贷款违约预测;信息不对称性;个人对个人借贷
中图分类号:TP181;TP391.77
文献标志码:A
文章编号:1001-9081(2019)04-0935-05
Abstract: Focusing on the information asymmetry problem in the process of lending, in order to integrate different data sources and loan default prediction models more effectively, an ensemble learning training method was proposed, which measured the accuracy and the diversity of learners by Area Under Curve (AUC) value and Q statistics, and an ensemble learning training method named TABAQ (Training Algorithm Based on AUC and Q statistics) was implemented. By empirical analyses based on Peer-to-Peer (P2P) loan data, it was found that the performance of ensemble learning was closely related to the accuracy and diversity of the base learners and had low correlation with the number of base learners, and statistical ensemble performed best in all ensemble learning methods. It was also found in the experiments that by integrating the information sources of borrower side and investor side, the information asymmetry in loan default prediction was effectively reduced. TABAQ can combine the advantages of both information sources fusion and ensemble learning. With the accuracy of prediction steadily improved, the number of forecast errors further reduced by 4.85%.
Key words: ensemble learning; Area Under Curve (AUC); Q statistics; loan default prediction; information asymmetry; Peer-to-Peer loan (P2P loan)
銀行信贷风险一般是指借款人违约不偿还贷款的风险,相关研究包括借款人信用评级、贷款违约预测、金融欺诈分析等,其中贷款违约预测与保障信贷资金安全、防范投资损失直接相关,是银行信贷风险研究中非常重要的子领域。数据统计和机器学习等方法和技术在该领域研究中得到了广泛使用,但由于相关研究主要还是基于借款人提供的信息开展,实际效果受借贷双方间信息不对称性的限制较大。
个人对个人借贷(Peer-to-Peer Lending或Peer-to-Peer Loan)即个人对个人贷款,整个借贷交易过程都在电子平台线上完成。除了借款人方提供的个人基本情况、经济信用、借款用途等信息以外,交易平台也会将投资人投标、贷款还款与违约、投资人收益等信息予以公开,以这些数据为基础,逐步形成了基于投资人端信息的预测模型,这为研究如何降低借贷交易的信息不对称性提供了基础。
机器学习(Machine Learning, ML)主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,或者重新组织已有知识结构使之不断改善自身性能。集成学习(Ensemble Learning, EL)属于机器学习的一个重要分支,是指通过把多个学习器进行整合,获得比单个学习器更好学习效果的方法,集成学习越来越广泛地被运用在计算机视觉识别、信息安全、辅助医疗诊断、金融欺诈预防、银行贷款违约预测等领域[1]。但在贷款违约预测的研究中,目前缺乏具体方法对集成学习构建、优化和检验的全过程进行有效指导。
以P2P借贷为切入点,提出一种集成学习的训练方法,将不同预测模型以及不同来源的数据信息进行集成融合,对于降低信息不对称性、提升贷款违约预测准确性、减少可能的投资失误和资金损失具有较大研究意义。
1 研究背景
1.1 传统银行贷款违约预测
传统的贷款违约预测是指对银行贷款是否会出现违约进行预判,是对银行信贷业务中各类风险进行有效管理的基础。20世纪90年代以前,该领域研究主要使用线性判别分析(Linear Discriminant Analysis,LDA)、逻辑回归(Logistic Regression, LR)等数据统计方法和技术[2-3],进入20世纪90年代以后,各类机器学习算法,包括支持向量机(Support Vector Machine,SVM)、决策树(Decision Tree,DT)、人工神经网络(Artificial Neural Network, ANN)等[4-6],逐渐得到了较广泛的应用。决策树是目前使用最多的方法,文献[7]认为基于C4.5算法的决策树方法较之基于ID3算法表现更优,而如果将决策树与ANN方法进行集成,贷款违约预测的准确度将获得进一步提升[8]。
但从总体上来说,目前还没有发现某一种单一的方法,可以在所有数据集上都保持最好的预测表现。从2010年以后,集成学习由于具有综合多种方法优势的特点,逐步成为了信用风险评估领域研究的热点方向[9-10]。
1.2 P2P贷款违约预测
目前对P2P贷款的违约预测方法主要分为基于借款人端信息和基于投资人端信息两类。前一类方法与传统银行贷款违约预测方法类似,基于借款人提供的各类信息对贷款违约概率进行预测,主要算法包括线性判别分析[11]、决策树[12]、逻辑回归[13-14]、支持向量机[15]、贝叶斯网络(Bayesian Network)[15]等,这些研究发现借款总期数、借款金额、借款人收入、借款人负债收入比、借款人信用级别都与贷款是否违约有较强关联性。
针对P2P贷款的借贷双方信息不对称性问题[16-17],文献[18-19]提出利用贷款投资人端信息,构建基于投资人投资稳定性的P2P贷款违约预测(Lender Stability,LS)模型;文献[20]则基于投资效用理论,利用投资人历史收益率、贷款利率出价等信息,使用TF-IDF算法构造逆向比例权重因子,建立了优化的基于投资人效用的贷款违约预测模型(Lender Utility2, LU2),并取得了更为准确和稳定的预测效果。
1.3 集成学习
集成学习也被称为多分类器系统(Multiple Classifier System, MCS),一般来说机器学习中的学习器(Learner)通常是由一个现有的学习算法从训练数据中产生,比如决策树、支持向量机、神经网络等,而集成学习则通过某种规则,将多个学习器进行组合,集成产生新的学习器。
集成学习中被集成的学习器称为基学习器(Base Learner),将单一算法训练而成的基学习器进行集成的方法被称为同质集成(Homogeneous Ensemble);与之对应,若集成包含了多种不同类型算法生成的基学习器,则被称为异质集成(Heterogeneous Ensemble)。异质集成中基学习器也被称为个体学习器(Individual Learner)或组件学习器(Component Leaner)。为使最终得到的学习器表现更好,除了提高基学习器的准确性以外,提高基学习器之间的差异性(Diversity)也是关键因素之一[21]。
集成学习的过程主要由两步组成:一是训练生成基学习器,二是将这些基学习器进行集成组合。按照基学习器的不同生成方法,可将集成学习分为四类[22]:一是通过重采样或复制等方法改变训练数据,如Bagging、Boosting;二是通过选取特征值(Feature)对训练数据进行变化,如随机子空间(Random Subspace,RS)、随机森林(Random Forest,RF);三是对基学习器的配置参数进行变化,如K近邻(K Nearest Neighbors,KNN)算法分类器中的核函数、神经网络调的扑结构;四是对基学习器的算法类型进行多样化,即对不同类型的基学习器进行集成。
按照基学习器组合的不同方式,集成学习又可以被分为线性集成、非线性集成,以及统计集成(或智能集成)三类。其中线性集成指通过加和或者取平均的方式得到最终结果,非线性集成则指通过多数投票、加权计算等方式获得最终结果,而统计集成(或智能集成)方式则是采取回归预测、贝叶斯算法、神经网絡等方法计算最终结果[23]。
2 贷款违约预测的集成学习训练方法
2.1 总体研究框架
本文的总体研究框架主要包括四部分:1)训练基学习器。2)选择基学习器进入集成过程。3)对基学习器进行集成,根据集成方法不同可分为两类操作:一类是针对线性集成、非线性集成方法,对基学习器结果的组合参数进行调整和优化;另一类则对应统计集成方法,在基学习器之上进行多层模型学习。4)对生成的集成学习器进行测试检验,并根据结果决定是否继续进行集成。
2.2 基学习器筛选
集成学习通过找到准确且互补的基分类器,并对其进行集成来提高学习器的泛化能力,从而获得更优的学习效果。故需要找到合适的指标,对基学习器的准确性和多样性进行度量,从而筛选出预测准确性高,且有较强的多样性和互补性的基学习器。
2.2.1 基学习器的预测准确性度量
ROC(Receiver Operating Characteristic)曲线和AUC(Area Under Curve)值常被用来评价一个二值分类器(Binary Classifier)的优劣。ROC曲线最早运用在军事上,后来逐渐运用到医学领域,再被运用到统计分析研究中,可准确反映某分析方法特异性和敏感性的关系[24]。
ROC曲线以下部分的面积即为AUC,AUC值越高表示模型预测效果越好,它可以被解释为任取一对(正、负)样本,正样本的预测值大于负样本预测值的概率[25]。AUC值具有一致性和稳定性的特点,不受判断阈值选择的影响,而且即使测试数据集正负样本分布不平衡也能保持稳定,故本文使用预测AUC值作为各学习器准确性的度量指标。
2.2.2 基学习器之间的多样性度量
基学习器之间的多样性(Diversity)与其相互之间的互补性紧密相关,多样性越强的基学习器,集成以后模型的泛化能力越强,目前越来越多的研究已经把注意力放到了如何更准确地对分类器之间的多样性进行度量[21]。
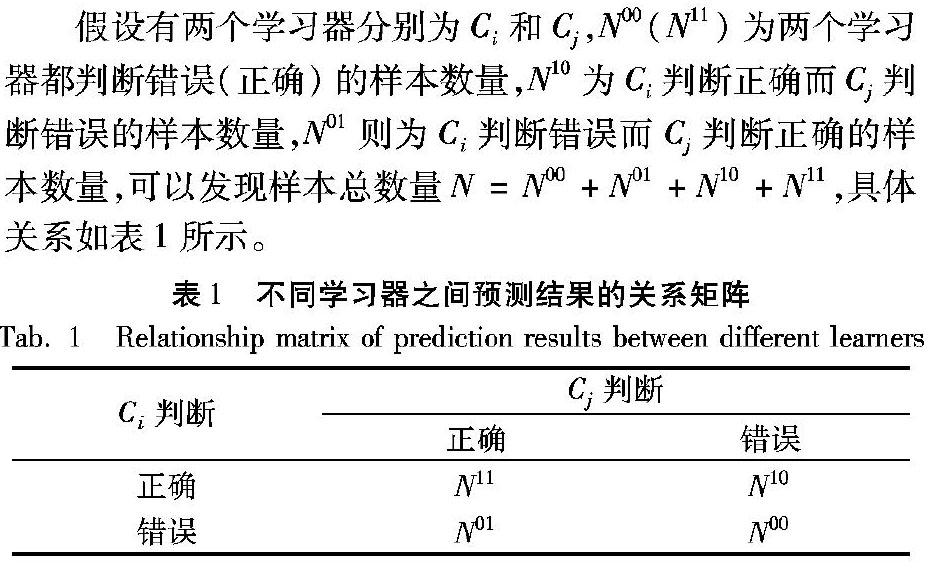
假设有两个学习器分别为Ci和Cj,N00(N11)为两个学习器都判断错误(正确)的样本数量,N10为Ci判断正确而Cj判断错误的样本数量,N01则为Ci判断错误而Cj判断正确的样本数量,可以发现样本总数量N=N00+N01+N10+N11,具体关系如表1所示。
当前研究中对不同学习器之间差异性的度量方法主要有四种,分别为Q统计、相关系数ρ、不一致度量(disagreement measure, dis)、双次失败度量(Double-Fault measure, DF)。
1)Q统计值(Q statistics)。
Q统计值源自统计学领域,计算方法如式(1)所示,其值为-1~1。如果两个分类器总是同时正确或错误分类,则Qi, j=1,此时两个学习器完全相同,相互之间的差异性最小。反之,如果两个分类器在每个样例上分类结果都相反,则Qi, j=-1,这种情况两个学习器之间差异性最高。
2)相关系数ρ。
两个学习器Ci和Cj之间相关系数ρ计算方法见式(2), ρ与Q统计值具有相同的符号,代表的意义也类似,即值越小则学习器之间的差异性越大。
3)不一致度量dis。
不一致度量dis计算方法如式(3),其关注分类器Ci和Cj分类结果差异的样本比例,这个比例越高,两个分类器之间差异性越高;反之则差异性越低。
4)双次失败度量DF。
双次失败度量DF的计算方法见式(4),其值为两个学习器Ci和Cj在相同的样例上判别错误的比例,可以认为这个比例越高,两个学习器越容易犯同样的错误,其集成以后泛化性也越低。
总体看来,Q统计指标的意义更加清晰明确,且计算过程相比相关系数ρ更为简便,故本文使用Q统计值作为各学习器之间差异性的度量指标。
2.3 集成学习训练
当前集成学习的训练方法主要可分为线性集成、非线性集成、统计集成三种。前两种方法都是对基学习器的预测结果进行直接组合,区别只是在于对各个基学习器结果的权重因子计算方法不同;第三种方法则是基于各基学习器的输出结果之上,使用其他模型进行多次学习,并生成获得新的学习器。
2.3.1 线性集成及非线性集成
由于贷款违约预测的结果是一个连续性的概率值,故本文的线性集成采取平均值法(AVerage, AV),即通过计算各基学习器所预测贷款违约概率的算术平均值得到集成后的违约概率 pAV,具体如式(5)所示:
其中:m为参与集成的基学习器数; pi为基学习器Ci预测的贷款违约概率。
而非线性集成方法需要为各基学习器的输出结果设置不同的权重因子(Weight Factor, WF),各基学习器权重因子与其预测准确性相关[26]。由于AUC值具有一致性和稳定性特点,本文使用基学习器的预测结果AUC值代表其预测准确性,并以此计算其权重因子,集成后的违约概率pWF如式(6)所示:
2.3.2 统计学习集成
二层学习(Double-level Learning,DL)集成是统计集成的一种,是指以基学习器结果作为输入,通过第二层模型学习训练获得集成学习器的方法。本文选择使用逻辑回归(LR)作为二层学习集成的模型。二层学习集成方法的贷款违约概率 pDL计算方法如式(7)所示:
2.4 集成学习器的预测效果检验
对于训练获得的集成学习器,将从预测准确性和错误情况两方面进行检验,其中准确性使用预测结果的AUC值进行度量。
学习器在预测时出现的错误可分为一类错误和二类错误。前者是指将实际违约贷款判别为正常,后者则是将未违约贷款判别为违约。一类错误可能造成对违约贷款的投资失误,对资金安全影响更大。本文使用一类错误数量作为度量学习器犯错情况的指标,该数值越高,则学习器预测失误越严重。
2.5 算法实现
按照总体研究框架,本文构建了基于AUC和Q统计值的集成学习训练算法(Training Algorithm Based on AUC and Q statistics, TABAQ),覆盖集成學习从构造、筛选、训练、检验和持续优化的全过程。
算法说明:在所有备选基学习器中,选择分类准确性最高,且差异性最大的基学习器作为初始集成学习器,然后循环筛选剩余的基学习器进入集成学习过程,直到集成后学习器的准确性不再提升,或者所有基学习器都被集成后为止。
3 P2P贷款数据实证分析
基于实际P2P贷款数据,使用本文算法TABAQ来训练并生成集成学习器,并基于此对单一数据源与融合数据源、单学习器与集成学习器的预测结果分别进行了实证对比分析。
实证分析主要分为三部分:1)训练基学习器,设置实验对比基准,并对不同基学习器之间差异性进行对比分析;2)使用TABAQ训练生成集成学习器,并对不同集成方法、集成参数对集成学习效果的影响进行对比分析;3)对单信息源与多信息源、单学习器与集成学习器的预测结果进行对比分析。
实验使用到的基学习器共5类,覆盖了基于借款人端信息和投资人端信息的两类预测模型,前者包括逻辑回归(LR)、支持向量机(SVM)、决策树(DT),后者包括投资人稳定性(LS)和投资人效用(LU2)。集成学习方法则选择平均值法(AV)、权重因子(WF)和二层学习(DL)三种。
3.1 实验数据说明
实证数据来自P2P借贷平台Prosper,使用的样本属性在借款人端包括借款人信用评级分、借款人预期损失率、借款利率、借款人每月还款金额、借款人借款收入比、借款人是否拥有住房等,投资人端则包括投资总金额、历史投资违约情况、贷款出价利率、贷款出资额等。
實证数据分别被划分为训练数据集(Train Dataset)、验证数据集(Verification Dataset)和测试数据集(Test Dataset)。其中:测试数据集用于训练基学习器;验证数据集用于计算基学习器的AUC值、一类错误数量、相互间的差异性Q统计值等数值,以训练获得集成学习的参数;测试数据集则用于对各种基学习器和集成学习器的预测效果进行检测和对比。
各数据集通过放回取样的方式从贷款数据中随机选取,每个数据集包含的贷款数量都为1000笔,共抽取10个数据集,各数据集轮流用于训练、验证和测试。进行10次实验,将各轮次实验结果取平均值用作对比分析。
3.2 实验结果分析
3.2.1 基学习器之间多样性分析
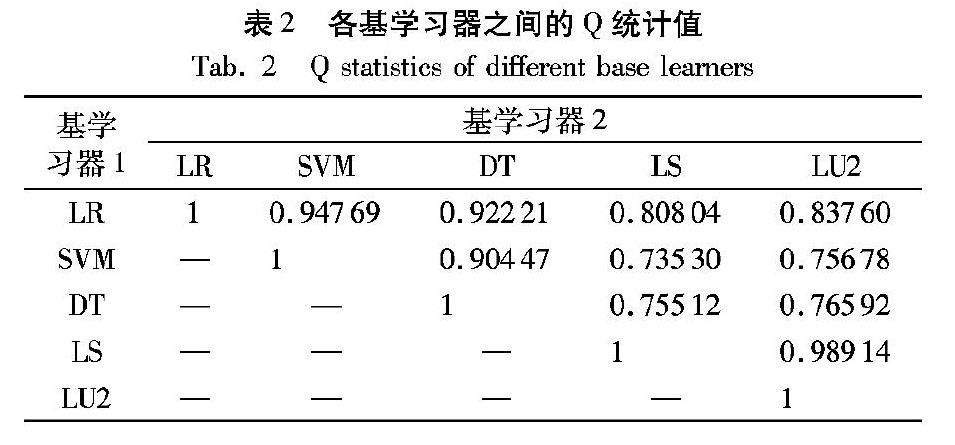
表2为各基学习器间的差异性Q统计值,可以发现:基于不同信息源的学习器之间Q统计值较低,如基于借款人端信息的LR、SVM、DT学习器,与基于投资人端信息的LS和LU2学习器之间,说明这些基学习器之间存在较强互补性。而基于相同信息源的模型之间Q统计值则都较高,表示较低的多样性。
3.2.2 不同集成方法的比较
三种集成方法训练获得的学习器的预测结果见表3,其中,Error-I为预测结果中的一类错误数量。可以看到属于统计集成的二层学习方法(DL)表现更好,取得了更高的AUC值以及更低的一类错误数量,而平均值方法(AV)和权重因子方法(WF)则表现欠佳,训练获得的集成学习器预测效果甚至低于单个基学习器。
在集成更多的基学习器后,并不能确保获得更好的预测效果,在集成学习训练过程中,需要考虑“更多并非更好”的原则,避免盲目增加基学习器对实际效果产生负面影响。
3.2.3 模型预测结果综合对比分析
不同信息源、不同学习器预测结果的综合对比见表4,其中BL列表示是单个基学习器(Base Learner),EL表示的是集成学习器(Ensemble Learner),总体上来看通过融合数据源和采取集成学习的方法,对提升预测效果都有帮助。从不同的数据源来看,基于投资人端信息的学习器获得了比基于借款人端信息学习器更好的效果,即更高的预测AUC值及更低的一类错误数量,这说明由于不存在提供虚假信息的道德风险,投资人端的信息对于贷款违约预测更有帮助。在借款人端信息的基础之上,通过融入投资人端的信息,预测AUC值获得了较大提升,而预测的一类错误数量则更少,这证明引入投资人端的信息,对于降低信息不对称性、提高预测准确性,特别是降低一类错误造成的投资失误有帮助。
无论是基于借款人端的信息源,还是投资人端的信息源,集成学习方法总体上都取得了比单学习器更好的预测效果。
需要关注的一点是基于投资人端信息的基学习器经过集成学习以后,预测AUC值降低了0.00054,这应该与基学习器之间的多样性不足有关。
从表2可以发现该类基学习器之间的差异性Q统计值非常高,说明基学习器之间的多样性极低,这证明了基学习器的多样性与集成学习效果之间的正相关性,集成学习过程中如果引入的基学习器过分相似,泛化性不足,最终的预测效果可能受到负面影响。
同时采取融合信息源和集成学习方法后,取得了最优的预测效果,预测AUC值保持稳步提升的同时,一类错误的数量更是进一步降低为86.3,相对于单学习器最优的90.7进一步下降了4.85%。这说明TABAQ能够有效地将多信息源融合与多学习器集成进行结合,同时发挥双方面的优势作用,降低信息不对称性,提升学习器的准确性,为提高贷款违约的预测效果、避免投资失误、保障资金安全提供了有效支持。
4 结语
本文基于预测AUC值及差异性Q统计值,提出了一种集成学习的训练算法TABAQ。使用P2P贷款数据进行实证分析发现,使用统计集成的方法可以获得比单个学习器更好的预测效果。集成学习的效果与基学习器的准确性和多样性关系密切,但与被集成基学习器数量的相关性较低,集成了过多、过于相似的基学习器,可能会对集成学习的泛化性造成负面影响。通过融合投资人端的信息数据,能够有效地降低贷款违约预测中的信息不对称性问题。TABAQ能结合多数据源融合和多学习器集成的双方面优势,预测的准确性持续提升,同时一类错误的数量相对单模型、单数据源、融合数据源等都更低。后续可以考虑更加准确地量化和度量不同数据源信息对预测效果的影响程度,并基于此对优化集成学习过程中的各类参数开展进一步研究。
参考文献(References)
[1] ZHOU X. Ensemble Methods: Foundations and Algorithms [M]. Boca Racton: CRC Press, 2012: 15-17.
[2] DIMITRAS A I, ZANAKIS S H, ZOPOUNIDIS C. A survey of business failures with an emphasis on prediction methods and industrial applications[J]. European Journal of Operational Research, 1996, 90(3): 487-513.
[3] HAND D J, HENLEY W E. Statistical classification methods in consumer credit scoring: a review[J]. Journal of the Royal Statistical Society, 1997, 160(3): 523-541.
[4] MIN J H, LEE Y C. Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters[J]. Expert Systems with Applications, 2005, 28(4): 603-614.
[5] LI H, SUN J, WU J. Predicting business failure using classification and regression tree: an empirical comparison with popular classical statistical methods and top classification mining methods[J]. Expert Systems with Applications, 2010, 37(8): 5895-5904.
[6] CHARALAMBOUS C, CHARITOU A, KAOUROU F. Application of feature extractive algorithm to bankruptcy prediction[C]// Proceedings of the 2000 IEEE-Inns-Enns International Joint Conference on Neural Networks. Washington, DC: IEEE Computer Society, 2000: 5303.
[7] AMIN R K, INDWIARTI, SIBARONI Y. Implementation of decision tree using C4.5 algorithm in decision making of loan application by debtor (case study: bank pasar of Yogyakarta special region) [C]// Proceedings of the 2015 International Conference on Information and Communication Technology. Piscataway, NJ: IEEE, 2015: 75-80.
[8] GENG R, BOSE I, CHEN X. Prediction of financial distress: an empirical study of listed Chinese companies using data mining[J]. European Journal of Operational Research, 2015, 241(1): 236-247.
[9] VERIKAS A, KALSYTE Z, BACAUSKIENE M, et al. Hybrid and ensemble-based soft computing techniques in bankruptcy prediction: a survey[J]. Soft Computing, 2010, 14(9): 995-1010.
[10] JADHAV S, HE H, JENKINS K W. An academic review: applications of data mining techniques in finance industry[J]. International Journal of Soft Computing and Artificial Intelligence 2016, 4(1): 79-95.
[11] ERGER S C, GLEISNER F. Emergence of financial intermediaries in electronic markets: the case of online P2P lending[J]. Business Research, 2010, 2(1): 39-65.
[12] JIN Y, ZHU Y. A data-driven approach to predict default risk of loan for online Peer-to-Peer (P2P) lending[C]// Proceedings of the Fifth International Conference on Communication Systems and Network Technologies. Piscataway, NJ: IEEE, 2015: 609-613.
[13] EMEKTER R, TU Y. Evaluating credit risk and loan performance in online Peer-to-Peer (P2P) lending[J]. Applied Economics, 2015, 47(1): 54-70.
[14] 談超, 孙本芝, 王冀宁. P2P网络借贷平台中的逾期行为研究[J]. 财会通讯, 2015(2): 49-51. (TAN C, SUN B Z, WANG J N. Research on overdue behavior in P2P lending platform[J]. Communication of Finance and Accounting, 2015(2): 49-51.)
[15] 鄧帆帆, 薛菁, 闫海鑫.商业银行参与P2P网络借贷的路径分析及建议——基于贝叶斯网络投资模型的测算结果[J]. 集美大学学报(哲学社会科学版), 2015, 18(2): 53-58. (DENG F F, XUE J, YAN H X. Analysis and suggestions of commercial banks participation in P2P lending — based on the measurement results of Bayesian network model[J]. Journal of Jimei University (Philosophy and Social Sciences), 2015, 18(2): 53-58.)
[16] WANG P, ZHENG H, CHEN D, et al. Exploring the critical factors influencing online lending intentions[J]. Financial Innovation, 2015, 1(1): 1-11.
[17] EVERETT C R. Information asymmetry in relationship versus transactional debt markets: evidence from peer-to-peer lending[D]. West Lafayette: Purdue University, 2011: 63-66.
[18] LUO C, XIONG H, ZHOU W, et al. Enhancing investment decisions in P2P lending: an investor composition perspective[C]// Proceedings of the 2011 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2011: 292-300.
[19] ZHAO H, WU L, LIU Q, et al. Investment recommendation in P2P lending: a portfolio perspective with risk management[C]// Proceedings of the 2014 IEEE International Conference on Data Mining. Piscataway, NJ: IEEE, 2014: 1109-1114.
[20] 章宁, 陈钦. 基于TF-IDF算法的P2P贷款违约预测模型[J]. 计算机应用, 2018, 38(10): 3042-3047. (ZHANG N, CHEN Q. P2P loan default prediction model based on TF-IDF algorithm[J]. Journal of Computer Applications, 2018, 38(10): 3042-3047.)
[21] KUNCHEVA L I, WHITAKER C J. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy[J]. Machine Learning, 2003, 51(2): 181-207.
[22] CHEN N, RIBEIRO B, AN C. A Financial credit risk assessment: a recent review[J]. Artificial Intelligence Review, 2016, 5(1): 1-23.
[23] CANUTO A M P, ABREU M C C, OLIVEIRA L D M, et al. Investigating the influence of the choice of the ensemble members in accuracy and diversity of selection-based and fusion-based methods for ensembles[J]. Pattern Recognition Letters, 2007, 28(4): 472-486.
[24] FAWCETT T. An introduction to ROC analysis[J]. Pattern Recognition Letters, 2006, 27(8): 861-874.
[25] MYERSON J, GREEN L, WARUSAWITHARANA M, et al. Area under the curve as a measure of discounting [J]. Journal of the Experimental Analysis of Behavior, 2001, 76(2): 235-243.
[26] MEYNET J, THIRAN J P. Information theoretic combination of classifiers with application to AdaBoost[C]// Proceedings of the 2007 International Conference on Multiple Classifier Systems. Berlin: Springer, 2007: 171-179.
