基于主题模型的中外期刊文献挖掘对比研究
2019-07-31单国栋肖彦翠
单国栋,肖彦翠,王 皓
(1.长春大学 理学院,长春 130022;2.东北财经大学 统计学院,辽宁 大连 116025)
学术期刊是科教事业发展过程中的关注焦点之一,对学术期刊文献进行统计分析,有助于直观地分析我国的科学创新和技术创新水平。如何从大量的期刊文本数据中发现有价值的信息,变得尤为重要。本文选取经济类的国内期刊《经济研究》和国外期刊《美国经济评论》为代表,对其进行WEB文本挖掘,然后对内容作描述性分析和词频趋势分析,以及文本挖掘模型的对比化分析。通过中外期刊对比,能够发现国内和国外相应领域目前的研究现状及关注热点的发展趋势,并且可以发现中文与英文分词方法的不同,同时为经济学者和读者的研究提供参考。
1 文本建模相关理论
1.1 文本分词处理和去停止词及词根还原
在进行文本挖掘之前,需要先对文本原始数据进行预处理。而在文本预处理过程中,分词是最重要的一个环节。对于英文文本,通过空格和标点很容易将文章拆分成词;但对于中文文本,文本分词的过程比较复杂,比较常用的中文分词方法包括:词典法[1],隐马尔科夫过程[2]和CRF模型[3]。通常一篇文本中的冠词、连词和介词等虚词以及在整个文本集中出现频率很高、但对区分类别作用不大的词,被称为停止词[4]。去除停止词是文本预处理中不可缺少的步骤,它们可以使分词结果变得更准确,为后续的特征表示和统计建模提高精度。与中文相比,英文中同一个词有词形的变化,而因为词义本身没有变化,就不应该作为独立的词来存储和参与分类计算。去除这些词形不同但词义相同的词,仅保留一个副本的步骤就称为“词根还原”,经过“词根还原”,英文文本预处理过程结束。
1.2 文本特征提取
文本挖掘的一个基本问题是文本的表示及其特征项的选取。如果直接将分词结果作为特征项来表示文本,那么这个文本向量的维度将会非常大,因而,必须从文本中提取出特征词来表示文本信息,即通过特征选择来降低文本向量的维度。特征项必须具备如下的特性:(1)文本内容需要被特征项所标识;(2)将目标文本与其他文本需要被特征项相区分;(3)特征项的个数不能太多,否则起不到降维的效果;(4)特征项分离比较容易实现。
特征项选取的方式通常有4种:(1)通过映射或变换的方法把原始特征映射为较少的新特征;(2)从原始特征中挑选出一些最具代表性的特征;(3)根据专家的知识挑选最有影响的特征;(4)用数学的方法找出最具分类信息的特征。这里的第4种方法是一种比较精确的方法,人为干扰因素较少,比较适用于文本自动分类挖掘系统。
1.3 基于LDA主题模型和CTM主题模型的文本建模理论
在自然语言处理领域,主题模型越来越受到广泛关注。主题模型是提取文档中隐含主题的一种概率模型,是对文字隐含主题进行建模的一种方法[5]。它打破了传统空间向量文档-词的思维定向,将文档映射到主题空间上,表示为文档-主题-词。用主题描述文档,有效地降低了维度,即主题模型克服了空间向量模型的缺点。
现阶段主要应用的主题模型包括LDA主题模型和CTM主题模型。
LDA(Latent Dirichlet Allocation)模型是Blei等人在2003年提出的[6],他们在pLSI方法[7]的基础上加入先验分布Dirichlet分布得到LDA模型。LDA主题模型生成文本的过程如下[8]:
(a)对于主题z,根据Dirichlet分布Dir(β)得到该主题上的一个单词多项式分布向量φ;
(b)根据泊松分布P得到文本的单词数目N;
(c)根据Dirichlet分布Dir(α)得到该文本的一个主题分布概率向量θ;
(d)对于该文本N个单词中的每一个单词Wn:
(d1)从θ的多项式分布Multinomial(θ)随机选择一个主题z;
(d2)从主题z的多项式条件概率分布Multinomial(θ)选择一个单词作为Wn。
其中,α和β是Dirichlet分布的参数,一般都是对称并且是固定值,α反映了文档集合中隐含主题间的相对强弱;β刻画了所有隐含主题自身的概率分布。
CTM模型则利用Logistic正态分布中的协方差矩阵来代表主题之间的关系。CTM主题模型生成文本的过程如下[9]:
(a)给定K个主题,各个主题都是全部词语的一个分布;
(b)从多维分布中,随机选取一个主题;
(c)从多维分布中,随机选取一个单词;
(d)重复以上过程,直到所有文档的所有词被抽取。
2 中外期刊文献挖掘对比研究
2.1 数据来源和文本数据预处理
《美国经济评论》(The American Economic Review,AER)是享誉经济学界的顶尖学术期刊,它涵盖了经济的各个领域,反映了人们关注的经济焦点,是经济学界的风向标。《经济研究》是全国性综合经济理论期刊,是在中国影响最大的经济理论期刊。本文通过爬虫技术分别爬取了1990年到2015年间刊登在《美国经济评论》和《经济研究》的所有文章,分别共有5684和3971篇文章,爬取的信息包括:文章题目、作者、年、月、摘要、关键词等。
获取到《美国经济评论》和《经济研究》的Web文本数据后,需要对这些文本数据进行预处理,包括:文本分词、停用词过滤等,这是对文本进行初步的过滤。经过前述的文本预处理过程后,则可以对预处理后的数据进行对比分析。
2.2 文本的描述性分析
2.2.1 科研年产出分析
由图1可以发现,《美国经济评论》的文章年产量明显高于《经济研究》的文章年产量。
就整体来看,《美国经济评论》文章年产量波动较大,而《经济研究》波动较小。而就局部来看,《美国经济评论》的年产量比较平稳,而《经济研究》的年产量波动较大。

图1 文章年产量
2.2.2 高产作者分析

图2和图3分别展示了《美国经济评论》和《经济研究》的高产作者数量。《美国经济评论》期刊中,nmax=24,得m=3.6,即发表文章在4篇及以上的作者为高产作者,有532位作者。《经济研究》期刊中,nmax=39,得m=4.7,即发表文章在5篇及以上的作者为高产作者,有240位作者。通过对比发现,《美国经济评论》的高产作者人数多于《经济研究》。就最高产作者发表文章数来看,《经济研究》高于《美国经济评论》。
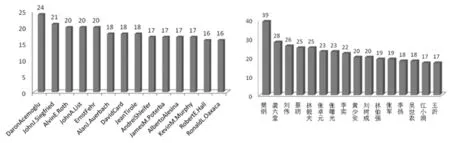
图2 《美国经济评论》高产作者 图3 《经济研究》高产作者
2.2.3 文章合著分析
《美国经济评论》1990-2015年间共发表5095篇文章,合著文章共3326篇,占总发表文章的65%。由图4的年合著率可以看出,合著率整体呈上升趋势。1990年合著率最低,占43%;2012年合著率最高,占82%。《经济研究》1990-2015年间共发表3971篇文章,其中合著文章共2014篇,占总发表文章的51%。年合著率整体呈上升趋势,1996年合著率最低,有13%,2014年合著率最高,有88%。

图4 文章合著率 图5 作者人数分布
通过对比合著率发现,随着时间的推移,《美国经济评论》与《经济研究》合著率的差距越来越小。1990-2005年《美国经济评论》的合著率均高于《经济研究》。2006年,《经济研究》的合著率超过了《美国经济评论》。2006-2013年之间,《美国经济评论》和《经济研究》的合著率相当。2014年和2015年《经济研究》的合著率明显高于《美国经济评论》。由以上数据可以得出结论:合著已经成为了一种比较普遍的现象。
针对《美国经济评论》和《经济研究》,我们统计了合作者人数及文章数,统计结果发现,《美国经济评论》合著作者人数最多为12人。对比之下,《经济研究》合著作者人数最多为16人。对比《美国经济评论》和《经济研究》的合作者人数(见图5),就一位作者来看,《经济研究》的合著占比高于《美国经济评论》。作者人数为2、3、4时,《美国经济评论》的占比均高于《经济研究》。综上所述,《美国经济评论》的作者倾向于合作,且以二人合作的形式居多;《经济研究》的作者更倾向于独著。
2.2.4 关键词分析
将《美国经济评论》的摘要分词除去停止词后,统计词语的频数。将词语按出现的次数从高到低排序,取前100个高频词语作词云图(见图6)。由图6发现,模型、影响、市场、价格出现的次数最多,即是《美国经济评论》的作者最关注的方面。取词频最高的前15个词语作柱状图,结果如图7所示。提取的高频词语能够反映出《美国经济评论》文献关注的主要内容,主要包括经济市场情况、影响、价格、政策、消费、变化等,其中最关注模型,说明《美国经济评论》的作者更多地致力于模型的研究。
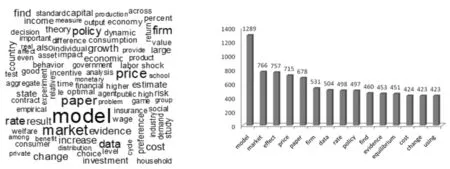
图6 《美国经济评论》高频词词云图 图7 《美国经济评论》高频词柱状图
按照同样的方式对《经济研究》词频进行统计,绘制图8、图9。由图8发现,中国、经济、影响、企业出现的次数最多,即是《经济研究》的作者最关注的方面。从提取的高频词语能够反映出《经济研究》文献关注的主要内容,主要包括我国经济情况、企业状况、面临问题、理论方面、改革等,其中最关注经济,说明《经济研究》的作者更关注于我国的经济情况。

图8 《经济研究》高频词词云图 图9 《经济研究》高频词柱状图
根据《美国经济评论》和《经济研究》高频词的词云图发现,《美国经济评论》和《经济研究》的作者均比较关注经济、政策、模型、理论、影响、企业、劳动力、产品等。除此之内外,《美国经济评论》的作者还比较关注工资、消费等,均是站在个人的角度和作者日常生活息息相关的。而《经济研究》的作者还比较关注农业、农村、工业等。
2.3 文本的主题分析
近年来,主题模型主要同文本聚类和文本分类相结合,应用于文献搜索和文献推荐等方面,LDA模型和CTM模型为主要应用模型。本小节针对《经济研究》和《美国经济评论》的数据,对其进行LDA主题模型和CTM主题模型分析。
2.3.1 《经济研究》的主题分析
根据《经济研究》的自身特点并且通过观察高频率词语不断调试主题个数,观察结果,最终确定《经济研究》主题个数为6个。
(1)LDA主题模型:得到的6个主题如表1所示,除第5个主题是理论经济学外,其他主题均是应用经济学。

表1 《经济研究》LDA主题模型结果
(2)CTM主题模型:6个主题如表2所示,除第5主题和第6主题是理论经济学外,其他主题均是应用经济学的内容。
2.3.2 《美国经济评论》的主题分析
根据《美国经济评论》的自身特点并且通过观察高频率词语不断调试主题个数,观察结果,最终确定,将《美国经济评论》分为8个主题。
(1)LDA主题模型:各个主题词根据其在文本主题出现的概率按照降序排列,如表3所示。

表3 《美国经济评论》LDA主题模型结果
(2)CTM主题模型:运用CTM主题模型得到的8个主题如表4所示,这同LDA模型的结果(表3)有所不同。

表4 《美国经济评论》CTM主题模型结果
2.3.3 总结与对比
经过上述分析,我们得到以下发现:
(1)在《美国经济评论》和《经济研究》数据集上,LDA主题模型效果更好一些。
(2)《美国经济评论》的LDA模型和CTM模型的结果都共同包括社会经济学、财政学、国际贸易学,但主题的词语有所差别。除此之外,LDA模型主题还包括投资学、教育经济学、国际贸易学、金融学和生育率对经济影响。CTM模型主题还包括政治经济学、发展经济学、保险学、货币银行学和宏观经济学。
(3)《经济研究》的LDA模型和CTM模型的结果都共同包含国民经济学、国际贸易学、货币银行学、产业经济学和政治经济学方面的内容,但主题的词语有所差别。除此之外,LDA模型还包括投资学等内容。CTM模型还包括宏观经济学内容。
(4)《美国经济评论》包括8个主题,《经济研究》包括6个主题。对比它们的LDA模型结果,发现《美国经济评论》和《经济研究》的主题均包含国民经济学、投资学和国际贸易学。除此之外,《美国经济评论》主题还包括社会经济学、财政学、教育经济学、金融学和生育率对经济的影响;《经济研究》主题还包括政治经济学、产业经济学、货币银行学。
3 结语
通过对《美国经济评论》和《经济研究》文献的文本数据的提取,对结构性数据进行描述性分析,对摘要进行分词、特征表示和特征提取,进而进行聚类分析和主题分析。
迄今为止,在针对期刊文本的研究中,所采用的分词技术主要是单一的针对中文,很少将中英文分词过程作对比。本文通过对外文期刊《美国经济评论》和中文期刊《经济研究》的摘要分词,对比中英文分词的相同与不同,从而为科研工作者提供便利。此外,本文深层次地挖掘中美两国经济研究领域权威期刊的内容,其结果对该领域学者的研究工作有一定的参考价值。
