基于画像技术对学生实现精准分析和服务
2019-07-26葛晓滨
葛晓滨
(安徽财贸职业学院雪岩贸易学院,安徽 合肥 230601)
0 引言
目前,全球学术界对用户画像有各不相同的定义。北京邮电大学经济管理学院亓丛、吴俊[1]提出了用户画像方法、工具,比较互联网领域用户画像的主要应用场景、常用画像方法;中国科学技术大学郭光明[2]基于社交网络理论对用户行为模式进行研究;中国科学技术大学马超[3]提出:用户画像是推断用户特征的过程、手段和方法,他采用精确的标签对基于用户个性化信息实现一系列实际应用;武昌理工学院周鲜子[4]在大数据背景下,从用户画像建模技术出发,分析了电商在大数据下是如何构建用户画像的技术;浙江大学杨洁[5]将研究中心聚焦在全景用户画像和模型预测上,实现企业的精细化运营。桂林理工大学姜建武等[6]在大数据理论基础上提出了一种基于用户画像的智能信息推送方法;云南电信大数据运营中心刘光榕、任建涛[7]根据用户访问网络偏好,形成了丰富的用户网络标签和画像,利用用户画像对用户进行分类;成都信息工程大学统计学院曾鸿、吴苏倪[8]构建用户画像模型,描述企业用户群体行为特征,实现精准营销;首都经济贸易大学李映坤[9]从用户画像的用户属性、用户流失、用户行为三个主要方面进行了研究。
综合以上的研究成果,本文在传统用户画像的基础上,以高等职业教育的学生为对象进行用户画像技术的研究,旨在通过这种画像技术的研究,做到精准的学情分析,提升于高校学生管理工作的水平和精准度。
1 学生的用户画像的技术理念及实现流程
1.1 学生的用户画像技术综述
学生的用户画像是通过系统地收集与分析学生的学习、生活、消费行为等主要信息数据,抽象出该学生在某个特定领域中的全貌。从而有助于学校管理者通过学生的用户画像识别和判断学生在这个特定领域中的潜在或明确的特质。
学生的用户画像一般是采用高校数据中心提供的标准化行为与内容数据,这些数据包括学生课程成绩、教师的平时考评、图书借阅情况、辅导员考评、校园一卡通消费等数据,运用大数据分析手段,量化学生在规律性、努力程度、学习技能、经济状况、社交关系等多维度的特性,揭示学生成长轨迹,基于预测模型对学生的学业成绩、就业倾向、心理状况等进行预测,为学校对学生进行个性化与精准化的教育管理与引导提供重要依据。
通常,一个学生基础知识的掌握好坏可以影响到学生在相关课程中的成绩。在学生画像技术的实现上,我们借助高校数据中心整合的学生信息,基于矩阵分解的降维技术,可以分析出学生对具体基础知识的掌握程度,并获得每门课程所含有的知识体系。基于这些信息,通过学生画像不仅可以预测出每个学生在其他课程的得分,也可以预测出这个学生在其他课程的挂科可能性,而且为教师在课程教学中有针对性进行课程教学的调整提供了依据。
在学生画像的算法上,以学生学习成绩画像为例,我们采用的设计思想是通过分析课程之间在知识体系上的相关性来进行相关的预测。比如某学生在以往课程中学习的科目Ⅰ成绩不好,那么当他在修读科目Ⅰ的延伸课程科目Ⅱ的时候,预警系统就会预警该学生的挂科可能性比较大,提示教育者及早发现问题并进行干预,尽可能避免挂科问题。因而,挂科预警实现了从后置性应急管理转变为前置性预警引导。在现实运作过程中,由于课程成绩数据更新频率低,挂科预警无法实时更新预测结果。为此,我们辅助叠加学生学习努力程度因子、生活行为习惯因子等,提升学生画像系统的实时性。学生在校园内的行为习惯的变化是可以实时监测的,对于预测成绩的变化非常有价值,在学生学习努力程度因子上我们以到课率、晚自习率、出入图书馆的次数度量等度量;在生活行为习惯因子上,我们以生活规律性(包括学生出入宿舍、吃早饭、洗澡等行为习惯数据)、在教学楼打水次数等对学生进行刻画学生努力程度。最后,我们基于努力程度、生活规律性、基础知识以及兴趣爱好这些特性,设计多任务迁移学习算法来对学生未来成绩进行预测。该算法不仅通过多任务特性考虑了特征相关性在学院之间的差异性,而且还通过迁移学习特点考虑了不同学期之间相关性的变化。得出学生的成绩预测分析,能很好地反映出学生成绩的未来走势。
1.2 学生的用户画像数据标签化
学生画像的基础在于标签的构建。标签应是对学生的高度精炼的特征标识。根据高校学生的特质,我们在标签的设计思路可以分别采用基本标签和扩展标签。基本标签是对学生基本情况和特征的描述,包括学生的基础特征、学习特征、生活特征、环境特征等;扩展标签在基本标签基础上建立的学生深层次特征的描述标签,包括偏好、思维、爱好、行为、人际交往等。这些标签可以再进行一定程度的细分,形成多级标签。如表1和表2所示。

表1 学生画像的数据化基本标签

表2 学生画像的数据化扩展标签
1.3 学生的用户画像技术实现流程
在标签化的基础上,我们实现对学生的用户画像技术的实施,按照用户画像的常规方法,我们通过原始数据采集、标准化清洗、建立数据模型和算法、数据运算分析、可视化呈现等步骤实现对学生的画像。主要的技术流程如图1所示。

图1 学生画像的技术主要流程
第一步:原始数据采集
依托数字校园的基础,通过物联网和大数据系统,我们可以获得丰富的学生数据资源,这些数据是构建学生画像的核心依据。我们在这些原始数据的基础上,采用标签分类技术,依据画像的需要,对数据进行分类筛选。(如图2)
数字校园

图2 原始数据采集
第二步:标准化清洗
在标签化的数据源中,因为数据采集的环境或其他各种原因,会导致一部分无用、冗余、异常等状况的“杂质”数据源,比如成绩缺失、性别缺失,年龄异常等杂质数据,需要采用一定的数据规则通过计算机或计算机辅助人工进行筛选,将符合学生实际情况的数据留存,剔除那些无用、冗余、异常等状况的杂质数据,这就是标准化清洗。
第三步:数据模型和算法
在获取到较为可靠的数据源基础上,根据学生画像的目标,对数据建立加工模型,采用具备优化能力的算法,提炼出学生画像的关键要素,实现对数据的可操作性。
对学生的画像进行刻画的常见方法有多种:(1)普通的统计法;(2)贝叶斯网络法;(3)神经网络法;(4)主题模型法;(5)数据挖掘的聚类分析法等。
鉴于用户画像的表示方式、关注点各不相同,用户画像建模方法可分为以下几大类,即面向用户行为的用户画像模型、基于本体的用户画像模型、融合用户兴趣的画像模型等。
在学生用户画像的数据模型和算法上:
(1)利用校园一卡通和学生本体属性的模型来预测经济困难学生的状况,也可以作为学生行为画像的重要数据来源;
(2)利用图书馆管理系统的信息统计学生的阅读时间和访问行为等来构建了学生阅读行为画像和档案信息,同时基于学生阅读行为画像可以用来预测学生的学习情况和成绩等;
(3)通过收集学生的行为历史数据,包括图书馆借阅信息,学生以前历史成绩信息、以及通过课程历史成绩信息确定难易程度等,来进行多元回归分析,构建了一个贝叶斯网络模型,预测学生在某门课程的能否通过概率;
(4)利用校园网门户网站的数据信息分析学生活动规律、兴趣偏好等几方面信息构建学生状态画像。
第四步:数据运算分析
在数据模型基础上,依据学生的标签,从基本标签和扩展标签两个方面进行运算分析,得出学生画像的基态数据。
第五步:可视化呈现
在学生画像的基态数据基础上,需要采用直观的方式,呈现目标结果。包括应用各种图形(饼图、柱状图、点状图)以及原态标注画像直观地呈现学生画像效果。
在这个技术流程环节中,主要的技术核心在于学生基础信息收集、学生行为建模、学生画像三个步骤,如图3所示。

图3 学生画像的主要技术环节
2 技术实现及其实例研究
对学生用户画像的技术实践,需要结合学校管理的实际需求,分析出与需求关联的学生数据实体,以数据实体为中心规约数据维度类型和关联关系,形成符合学校管理实际需要的建模体系。在维度分解上,需要以学生、课程等数据实体为中心,进行数据维度分解和列举。根据相关性原则,选取和学生画像目的需求相关的数据维度,避免产生过多无用数据干扰分析过程。在数据源的获取以及数据整理上,学生画像的数据来源于学校的数据系统日常积累的各类数据系统,技术上一般通过Sqoop导入HDFS,也可以用代码来实现,比如Spark的JDBC连接校园数据库进行数据的Cache。还有一种方式,可以通过将数据写入本地文件,然后通过Spark SQL的Load或者Hive的Export等方式导入 HDFS。通过Hive编写UDF或者HiveQL根据业务逻辑拼接ETL,使用户对应上不同的用户标签数据,生成相应的源表数据,以便于后续用户画像系统,通过不同的规则进行标签的生成。在学生画像计算的框架上,一般选用Spark以及RHadoop进行,Spark的用途一是对于数据处理与上层应用所指定的规则的数据筛选过滤;另一个是服务于上层应用的Spark SQL。RHadoop的应用主要是利用协同过滤算法等各种推荐算法对数据进行各方面评分。
下面通过两个由表及里的代表性技术实例研究,说明学生画像的技术实现。限于篇幅,本文不对标签技术及数据呈现技术做深入探讨。
2.1 学生画像初始技术实现
以某校的学生画像为例,首先对相关数据源中的数据信息进行收集整理,主要来自于下面表3中的数据库系统。这些数据库系统中的信息,我们侧重点在于通过数据分析研究得出学生画像。

表3 来自校园内部不同系统的原始数据量
根据原始数据,我们对学生画像定义的标签信息包括:学生基本信息、学习用功度、成绩状况、生活规律性、兴趣爱好等画像的信息,如图4所示。

图4 学生张军的画像信息
这些信息的具体表达如下:
学生基本信息:姓名、性别、年龄、……;
学习用功度:刻苦、一般、懒散;
成绩状况:优秀、良好、一般、差;
生活规律性:早起早睡、晚睡晚起、正常规律、没有规律;
兴趣爱好:科技、运动、文艺、娱乐、时尚、游戏、旅游、音乐、其它。
画像流程:
1、从教务数据库中获取基本信息标签。这个标签的信息不需要太复杂的操作或计算,只是简单直接提取相关信息。
2、从图书管理系统中获取用功度信息。用功度信息一般是主观性比较大的信息,我们从学生停留在图书馆学习的时间、借阅上课相关书籍的次数和人为问卷(辅导员或第三者填写问卷)等数据进行评价。
3、从网络中心系统和校园卡的用餐信息中获取生活规律性信息。规律性的四类信息:早起早睡、晚睡晚起、正常规律、没有规律(其它三项中的时间段占比不超过60%),如表4分析。

表4 生活规律性标签信息
4、从教务数据库中获取学生学习成绩状况信息。通过学生过去学习过的课程考试成绩和学分绩点来判断学生的成绩状况。
5、从图书管理系统和网络中心系统中获取学生的兴趣爱好信息。提取比率最高的相关兴趣关键词共八大类:科技、运动、文艺、娱乐、时尚、游戏、旅游、音乐、其它。
对上述信息整合,可以生成学生初步状态信息画像。
2.2 成绩预警技术实现
学生成绩与多重要素相关,从数字校园可以获取多种学生的数据。在具体的处理环节上,我们一般把这些数据划分直接相关数据和间接相关数据。
直接相关数据是学生直接的学习状态数据,包括学生学习状态、以往的考试成绩、对基础知识掌握程度等。学生画像技术可以借助以往课程成绩信息,分析学生对具体基础知识的掌握程度。基于这些信息,可以预测每个学生在课程中挂科的可能性。
间接相关数据是学生的学习和生活状态数据。教育学者普遍认为,良好的行为习惯与学习成绩是呈正相关的。通过采集学生在校内行为,并将这些行为转化为可存储量化的标签化数据,这些行为数据包括:学生就寝时间、就餐规律性、校园购物频次及金额、打水规律、图书馆进出频次和停留时间、图书借阅数量和阅读时间、宿舍门禁进出规律等。我们对这些数据分析就能发现,学习好的学生与一般学生在学习生活轨迹上有明显的不同。
通过贝叶斯网络构建的学生成绩预警模型,依据直接相关数据和间接相关数据,可以预警学习状态不佳,或者个体的自律与自控能力较差的学生。学校可以有针对性地针对这些学生进行辅导和沟通,以提高学生的成绩。图5是数据结构课程成绩预测模型的贝叶斯网络图。

图5 数据结构课程成绩预测模型的贝叶斯网络图
利用贝叶斯网络,可以进行推理,对学生成绩预警。在贝叶斯网络中,根据常见的变量定义,分为:
●证据变量集E={E1,E2,…,Em}— 特定事件e
●查询变量X
●非证据变量集—Y隐变量(Hidden variable)={Y1,Y2,…,Yn}
●全部变量的集合U={x}∪E∪Y
贝叶斯推理即在一组证据变量Ei∈E={E1,E2,…,Em}时,推理计算查询变量的后验概率(条件概率)分布。即计算在特定事迹e给点的时候,X的后验概率(即条件概率)分布 P(X∣e)。
在本例的贝叶斯网络中,我们首先统计计算出借阅图书相关性BR、学习用功度LH的数据信息,而先导课程成绩OBP和学习成绩状况L则从学生个人画像标签中直接获得数据信息。那么根据贝叶斯定理有:
P(CP|BR,LH,OBP,L)*[P(BR)*P(LH)*P(OBP)*P(L)]
=P(BR|CP)*P(LH|CP)*P(OBP|CP)*P(L|CP)*P(CP)
在上述取得数据过程中,需要对相关数据和课程通过的数据进行归一化。根据对相关历史数据统计获得如下的数据信息。具体见表5-表10。

表5 数据结构(不)通过率表
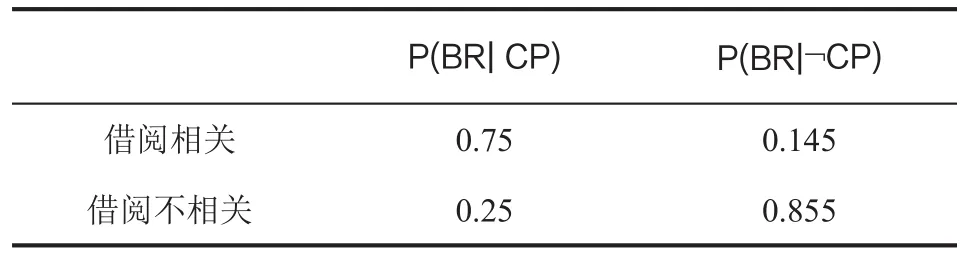
表6 数据结构(不)通过情况下的借阅图书相关性概率表
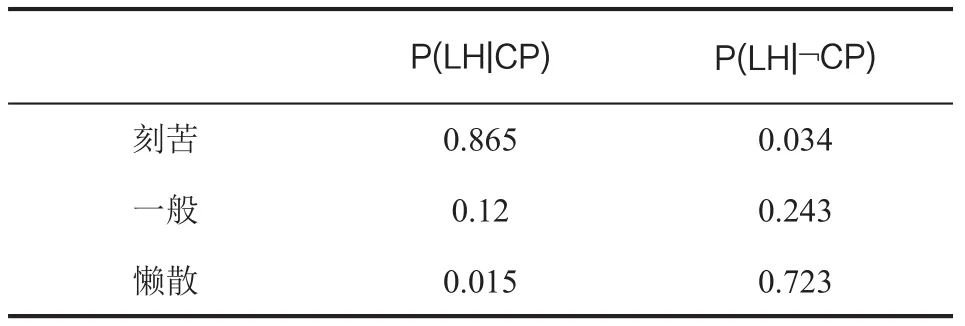
表7 数据结构(不)通过情况下学习用功度概率表
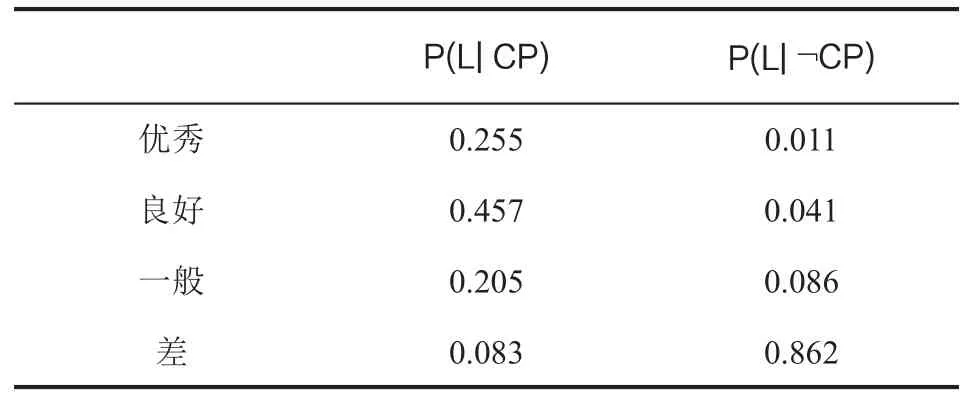
表8 数据结构(不)通过情况下学习成绩状况概率表

表9 数据结构(不)通过情况下先导课程C语言(不)通过概率表

表10 三名学生的后验概率示例数据表
在对数据信息进行分析后,我们发现:学生A数据结构课程通过概率是不通过概率的1422倍,学生B的课程通过概率是不通过概率的79倍,而学生C的不通过概率是通过概率的4.5倍。
3 结语
用户画像技术是一种较为复杂的应用技术,而采用用户画像技术对学生进行精准分析的探索也面临着诸多的难点和挑战。本文通过学生画像初始技术、成绩预警技术等重点技术的分析,试图解析这一技术的实施和应用要点。但是这种探索和尝试也存在数据的分析精度不够等问题,这是我们未来需要努力的方向。但我们也同时看到基于数字化校园的宽域、多载荷数据为构建有价值的大数据应用提供了良好机遇和宽广的应用空间,这为我们采用画像技术为学校的管理者切实做好学生管理工作提供有力的环境支持。未来,这一领域有更加广泛的应用空间及价值发现。
