音强斜率特性区别同卵双胞胎语音的实验研究∗
2019-07-25杨俊杰陈建新胡耀民李剑锋
杨俊杰 何 磊 陈建新 胡耀民 李剑锋
(1山西警察学院刑事科学技术系 太原 030401)
(2苏黎世大学计算语言学院 苏黎世 CH-8050)
(3北京阳宸电子技术公司 北京 100029)
0 引言
在司法话者识别领域,语音的个体特殊性一直是各位学者所追寻的。作为语音四要素的重要内容[1],音强与时长特性近年来更是受到国内外专家的高度关注。对于音强,其强弱与人说话时的开口度密切相关[2−3]。先前研究表明,普通人群音强曲线在曲率分布、拐点数与分布、极值数与分布、极值特征、音节间过渡特征等方面具有总体特殊性[4],在韵母音强随时间的分布状态[5]和音节间音强关系等方面也具有个体特殊性[6−7]。即使是发音器官高度相似的同卵双胞胎语音,其音强特性也具有一定的个体特殊性[8−10]。对于时长,Ulrike等[11]指出“······即使话者自身变异较大,不同说话人元音、辅音、浊音或峰间的时长差异仍然非常明显”。
杨俊杰等[10]曾对利用音节间相对音强与相对时长鉴别同卵双胞胎语音进行了研究。结果发现,在30对同卵双胞胎语音中,单独利用音节间相对音强时,有19对无法区别开;单独利用音节间相对时长时,有20对无法区别开;综合利用二者进行检验,结果仍有13对无法区别开。
近年来,有学者把音强与时长二维参量联合起来进行话者识别的研究[9,11]。其中,Ulrike等[11]的研究发现,单独用音强或音强与时长联合检验的区别力均强于单独利用时长的区别力。尤其是Lei等[9]在研究了普通个体连续语音音强的动态特性后发现,音节音强的下降斜率比上升斜率更具有个体特殊性,音强曲线斜率特性可能对话者自动识别,特别是司法话者识别具有重要价值。这些结果启发我们利用音强斜率的动态特性进行了同卵双胞胎语音的话者识别研究。实验研究中,针对13对同卵双胞胎的由16个音节组成的声样,分别分析了每个音节音强的上升斜率和下降斜率。数据的统计分析结果表明:在90%的置信度下,实验中的13对同卵双胞胎语音都得到正确的区分,佐证并发展了Lei等[9]的研究结论,为识别同卵双胞胎发音人提供了有效声学参量。
1 研究语料与方法
1.1 语料
为了保证实验结果的可比性,该实验使用杨俊杰等[10]曾经使用过的,利用音节间相对音强与相对时长仍无法识别的13对同卵双胞胎语音进行研究(发音人16女10男,年龄范围11∼40岁,平均年龄21.3岁,年龄标准差为8.2,均无语言及听觉障碍,每对双胞胎从小到大一直在一起生活;每人朗读声样5遍,语音为普通话或略带口音的普通话;采样率为16 kHz,单声道),分析语句为包含ta qu wu xi shi chu chai,wo dao hei long jiang jian cha gong zuo(他去无锡市出差,我到黑龙江检查工作)共16个音节的两句话。
1.2 音强曲线及其峰谷的提取
语音分析设备为北京阳宸电子技术公司生产的IV-12智能语音工作站(10.0版)。音强的计算步骤为
(1)分帧:帧移(步长)为10 ms,帧长20 ms。
(2)加窗:类型为汉明窗。
(3)音强计算:根据公式(1)对每帧能量进行计算,以得到音强级别(dB)。
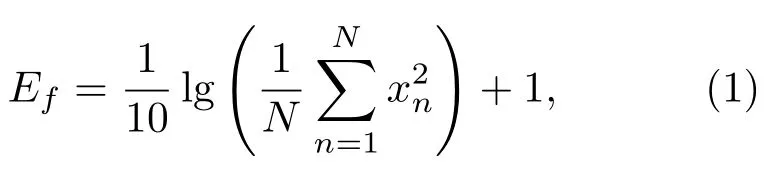
其中,Ef为第f帧能量,N为每帧采样点数,xn为帧内第n点的振幅值。
(4)平滑:应用5阶中值滤波(式(2))与5阶线性滤波(式(3))对音强曲线进行后平滑处理,进而得到音强曲线。

音节音强的峰值(IP)是音节区间内音强的最大值,音节音强的谷值(IT)是相邻音强峰值间的音强最小值(图1),可以通过IV-12智能语音工作站(10.0版)将对应区间音强数据输出到Excel后,分别利用自动求最大值与最小值函数求得。
1.3 音节音强斜率的计算
音强斜率的计算如图1所示,在音强曲线上分别找出每个音节的峰值(IP)、谷值(IT)及其在时间轴上的对应点时间(tT、tP)。然后根据公式计算每个音节音强的正斜率(音节音强上升斜率),根据公式
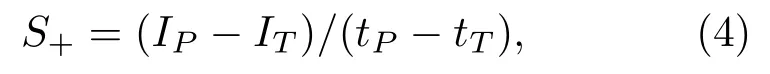
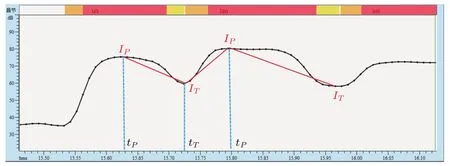
图1 音节音强正负斜率计算示意图Fig.1 Calculation diagram of positive and negative slopes of syllable
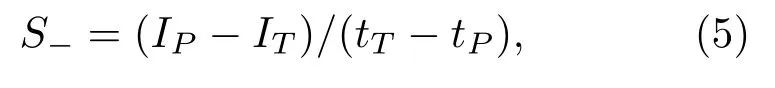
计算每个音节音强的负斜率(音节音强下降斜率)。
1.4 统计分析
1.4.1 统计原理
司法话者识别的基本前提是语音个体变异要小于其人间差异[12]。本文围绕这一前提对同卵双胞胎语音音节音强斜率的个体变异及人间差异分别进行统计分析。
根据统计学理论,首先需要确定斜率数据的分布类型。先前研究表明,同一人相同内容的多遍语音,其音节音强与时长分布整体符合正态分布[10]。根据两个相互独立正态分布的线性转化仍为正态分布的原理可以推知,作为音强差与时长差之比的音强斜率也符合正态分布。而在司法实践中,语音样本数量一般为5次左右,属小样本范畴。根据数理统计规律,小样本正态分布数据的分布范围可以在一定置信度下由式(6)求得[13]
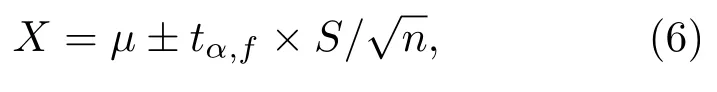
其中,µ是样本均值,tα,f为一定置信度(1−α)100%与自由度f=n−1下的置信系数,可由t分布表中查出,S为标准差,n为样本个数。式(6)的概率意义是它表明真值X落在置信区间的置信度概率为P=1−α。
根据实验条件,实验中f=5−1=4;在90%、95%、98%置信度下,α分别为0.10、0.05、0.02;查t分布表得tα,f分别为2.13、2.78、3.75。于是在90%、95%、98%置信度下,式(6)又可以分别表示为

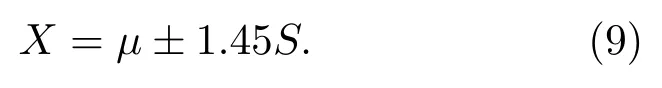
这些等式确定的分布范围,正是不同置信度下音节音强斜率的个体变异范围。如果比较值落在这一区域内,则表明二者之间没有明显差异;如果比较值落在这一区域外,则表明二者之间存在明显差异。
1.4.2 统计步骤及内容
(1)单个音节音强斜率比较
对于利用公式(4)、公式(5)分别计算出的每个音节音强的斜率,按表1分别统计每对双胞胎个体音强斜率的两类差异。表1中“RT”、“RJ”分别代表一对双胞胎中的两个同胎个体;“S+”、“S−”分别代表音节音强的正斜率与负斜率;“S+A类差异”、“S−A类差异”分别代表音节音强的正斜率、负斜率的个体变异(RT的每遍数据与其分布范围相比较存在的差异。如“ta4”的“S+”值为299.14,其落在RJ“S+”的分布范围251.10∼298.85之外,存在显著差异,标为“1”);“S+B类差异”、“S−B类差异”分别代表音节音强的正斜率、负斜率的人间差异(RJ的每遍数据与RT数据的分布范围比较存在的差异。如RJ的“ta2”的“S+”值为305.86,其落在RT“S+”的分布范围251.10∼298.85之外,存在显著差异,标为“1”);“0”表示目标值落在被比较的数据分布范围之内,二者之间没有显著差异;“90%分布范围”是指在90%置信度下,根据公式(7)计算出的S+、S−的分布区间。同理,可以计算出95%、98%置信度下各个音节正负斜率个体变异与人间差异。
(2)每对双胞胎音节音强正负斜率个体变异与人间差异统计
在对每对双胞胎每个音节音强正负斜率个体变异与人间差异统计的基础上,再对每对双胞胎语音16个音节音强正负斜率的个体变异与人间差异进行统计,90%置信度下的统计结果实例见表2。其中的阿拉伯数字是指5遍语音中每个音节对应差异特性存在显著差异的遍数(例如,“ta”的“S±B类差异”“ta”行单元格内的“4”表示RJ“ta”的音强正负斜率与RT“ta”的音强正负斜率的分布范围相比较时,各有4个斜率值不在RT的分布范围内,存在显著差异)。
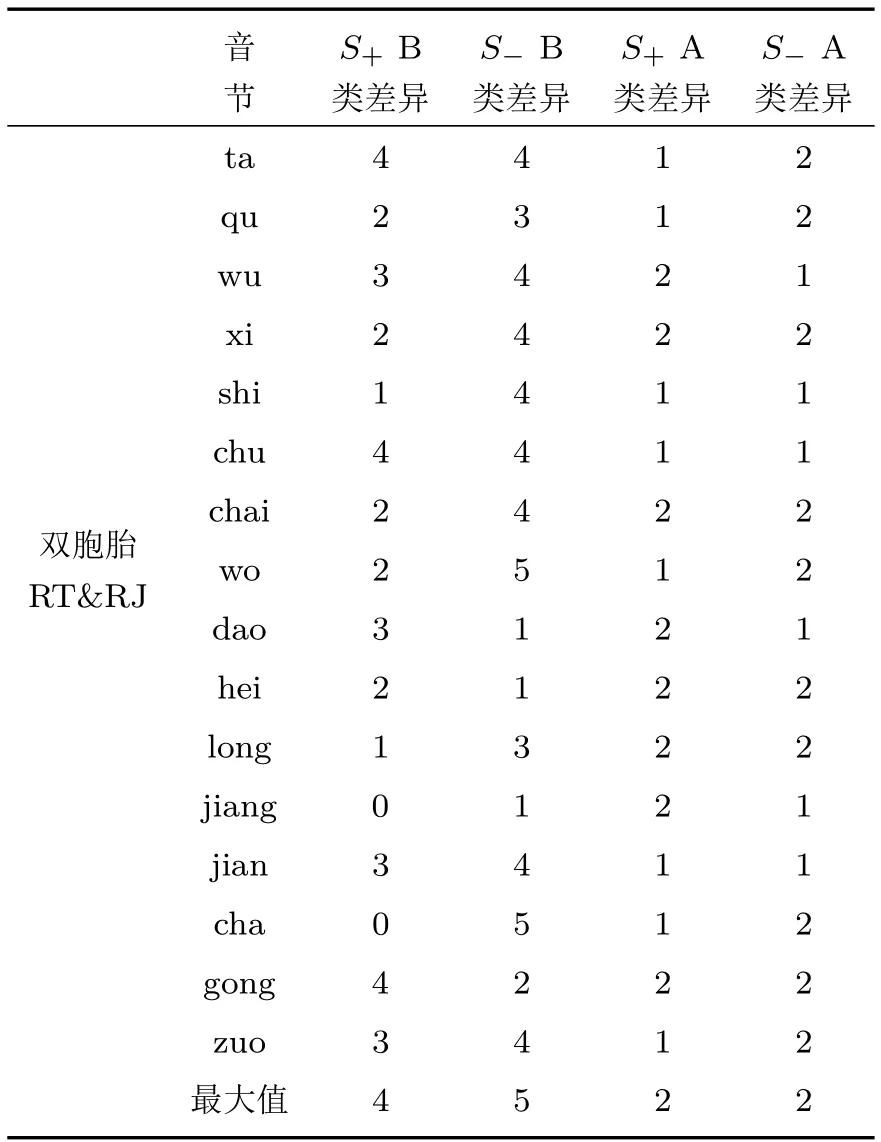
表2 双胞胎RT&RJ的不同音节的个体和人间显著差异音节个数的统计结果Table 2 Statistical results of the number of syllables with significant differences within and between individuals of twins RT&RJ
2 实验结果
2.1 不同置信度下的统计结果
在90%、95%、98%的置信度下,分别对13对同卵双胞胎语音音节音强正负斜率的个体变异与人间差异进行统计,结果见表3。
表3中“置信度”下的“90%、95%、98%”的单元格分别表示置信度水平,“发音人”右侧单元格表示各对同卵双胞胎,“差异类别”右侧行中的“B”是指B类差异,即双胞胎两个同胎个体的人间差异,“A”是指A类差异,即每个双胞胎个体的自身差异,“最大值”指所有比对音节中S+或S−的最大差异遍数(例如,表3中“XG&CG”90%行S+A列单元格的红色“3”表示16个比对音节中,发音人“XG”S+的最大个体自身显著差异音节数是3个。
由表3可以发现,在各级别的置信度下,各对双胞胎语音S+与S−的B类差异的最大值均大于A类差异的最大值,这说明在统计上有可能依据S+与S−将双胞胎语音区别开。在90%置信度下,各对双胞胎语音的S+与S−中,每遍语音的人间差异均大于其个体变异;但在95%、98%置信度下,每遍语音的人间差异与其个体变异会存在没有显著差异的情况。从检验的角度考虑,90%置信度下的置信区间更有利于检验工作的开展。
2.2 90%置信度下S+与S−的个体变异与人间差异统计结果
在确认90%置信度比较有利于区分双胞胎语音之后,本文对13对同卵双胞胎语音S+与S−的个体变异与人间差异分别进行了统计,结果见表4。其中,“全显著差异音节数”是指在所比较的5遍语音(每遍16个音节)中,分别在S+或S−上5遍均存在显著差异的音节个数;“S+、S−之和”是指每一遍语音均存在B类差异或A类差异的音节数之和。例如,“WJ&WY”B类差异“S−”列“全显著差异音节数”行的数值是“6”,表示WY 5遍语音各个音节音强的S−与WJ对应音节音强S−的分布范围相比较时,每遍语音都有6个音节的S−存在显著差异;“WJ&WY”B类差异的“S+、S−之和”为“11”,反映了说话人WY每遍语音的16个音节中有11个音节S+、S−的值与WJ对应音节S+、S−的分布范围存在显著差异。
从表4“S+、S−之和”一行的数据可以发现,13对双胞胎中,同胎个体间S+与S−的B类差异之和均大于双胞胎每个个体S+与S−的A类差异之和,这说明在90%置信度下,13对同卵双胞胎同胎个体语音S+、S−的人间差异总数均大于其个体变异总数。因此,联合利用S+与S−,可以将同卵双胞胎的同胎个体区别开。
进一步对表4中双胞胎同胎个体间S+、S−中“5个差异音节数”B类差异进行分析、统计发现,各对双胞胎同胎个体间S+人间差异音节数(黑色)均小于S−人间差异音节数(红色);S+的人间差异音节数为22个,占所有人间差异的22.03%,而S−的人间差异音节数为64个,占所有人间差异的77.97%(见图2)。
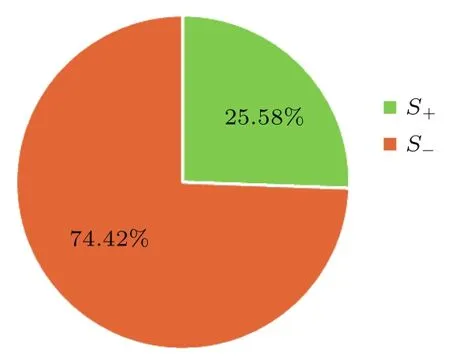
图2 S+与S−比例统计图Fig.2 Proportional statistical chart of S+&S−
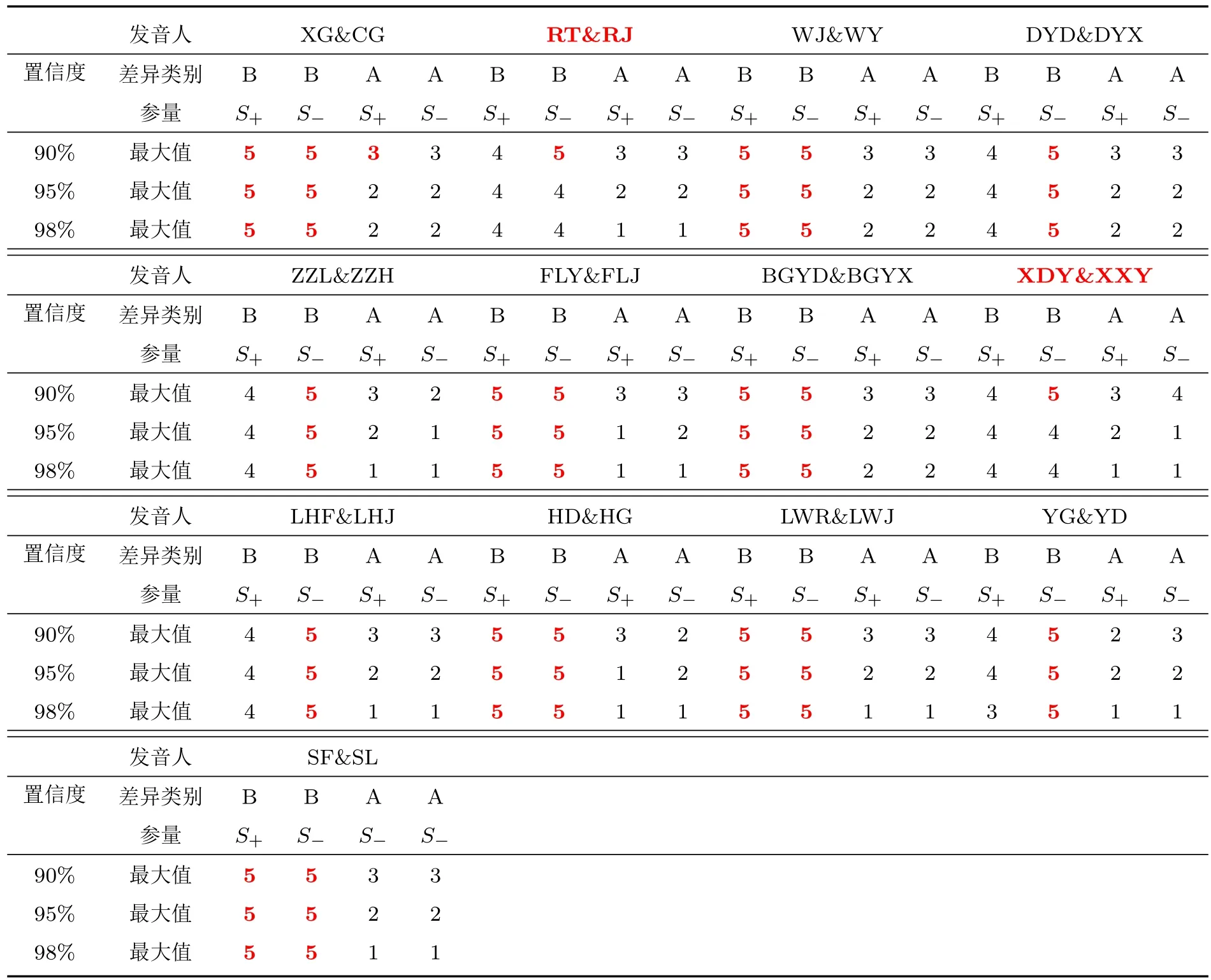
表3 不同置信度下,13对同卵双胞胎语音音节音强正负斜率个体变异与人间显著差异最大个数统计结果Table 3 Statistical results of the largest number of significant differences within and between individuals in the positive and negative intensity slopes of syllables of 13 pairs identical twins with different confidence levels

表4 90%置信度下13对同卵双胞胎S+与S−的个体变异与人间差异统计表Table 4 Statistical table of individual Variation and interpersonal difference of S+and S−in 13 identical twins with 90%confidence level
3 分析与结论
表4“全显著差异音节数”数据证明,在90%置信度下,所考查的13对同卵双胞胎同胎个体语音S+、S−的人间差异总数均大于其个体变异总数。因此,联合利用S+与S−,是可以将同卵双胞胎的同胎个体区别开的。本实验研究证明,汉语音节音强斜率在区分同卵双胞胎语音的司法鉴定中的有效性。
此外,研究发现所有S−的人间差异比S+的人间差异更加明显。图2中,S+的人间差异仅占所有人间差异的22.03%,而S−的人间差异占所有人间差异的77.97%。这些结果与Lei等[9]的实验结果相一致,即:S−的区别力比S+的区别力更强。至于具体原因,Lei等[9]认为,根据运动程序理论,说话时说话人会主动计划和控制调音器官以达到发音目标。这样的发音目标位于嘴巴打开阶段的转折点,与元音音强的最大值相对应。为了最大限度地提高相互理解能力,说同一语言的人应该表现得更为一致。一旦达到语音目标,发音人便可减少对发音器官的控制,从而产生更多体现个体嘴巴闭合运动特点的发音特性。也就是说,这两个发音过程可能受两个运动特性的影响:可控性和内在属性。在嘴巴打开过程中可控性在发挥更大的作用,而在嘴巴闭合过程中,内在属性发挥更大的作用[9]。
我们认为S−的人间差异比S+的人间差异更加明显,可能还与音节开头辅音较多有关。因为S+的计算中包含了更多的辅音音强,而辅音的个体稳定性较差,进而导致其个体变异加大,降低了人间差异。
在实验结果中,S−的人间差异所占比率(77.97%)比Lei等[9]的70.35%更高,这种差异可能与研究所用的语言有关。因为汉语(尤其是汉语普通话)音节结构比德语的音节结构简单,辅音也相对较少[14]。尤其是在音节末尾的辅音上,汉语普通话只有[n]、[ŋ]两个并且还都是浊音,其音强的稳定性要比擦音、塞擦音等辅音的稳定性更强。本研究为Lei等的研究结果提供了更加有力的佐证。
对于同卵双胞胎而言,尽管受遗传因素的影响其发音器官高度一致,语音也高度相似,但反映其嘴巴打开与闭合习惯的音强斜率特性仍具有良好的区别能力,更进一步说明发音器官的调音运动具有个人特点[15],同卵双胞胎语音的音强特性也具有个体特殊性。但S+中也包含一定个体信息,实践中应联合应用。
从实验结果可以发现,本文使用的S+与S−两个参量比利用音节间相对音强与相对时长在区别双胞胎语音时更加有效。同时,本文的检验方法所需语句少,更适合于实际案件中的短时语音检材。但是,在实际应用中尚有以下问题需要进一步研究:
(1)需要对非同期语音样本间的个体变异作进一步研究。
(2)需要对不同语速、不同语气、不同说话音量等条件下,汉语说话人S+、S−两个参量的可比性进行研究。因为不同语言改变语速的方式可能不同[16]。对于汉语,语音受语速的影响不同,随语速的加快音段/音节时长会缩短,音段时长缩短的幅度与音段属性有关,辅音时长缩短的程度小于元音[12]。
(3)需要对自然语音与朗读语音间音强斜率的一致性进行研究。因为在自然口语中,犹豫、错误发声、填音等都会影响到发音器官的运动情况[9]。
此外,也需要对不同信道对音强斜率的影响进行相关研究,诸如对语音进行信道补偿的电话语音等。
