深度学习语义分割方法在遥感影像分割中的性能分析
2019-07-25王俊强李建胜波2
王俊强,2,李建胜,丁 波2,蔡 富
(1.信息工程大学,郑州 450000; 2.中国人民解放军78123部队,成都 610000)
0 引言
遥感影像分割作为遥感影像解译的重要分支之一,是将图像分割为若干对象区域,每个区域内的像素之间具有较好的相似性,同时保证对象区域之间有较大的异质性[1]。智能的遥感影像分割可实现典型要素自动提取,如快速提取道路网数据,能够为导航图提供数据支持。传统分割方式一般使用随机森林[2]或者纹理基元森林方法[3]来构建用于语义分割的分类器,这类方法需要人工制作复杂特征,鲁棒性差,难以满足大范围自动化作业需求。近年来,深度学习在多种高级计算机视觉任务中取得成功,特别是监督学习下的卷积神经网络在图像分类、目标检测方面成功鼓舞着研究人员探索此类网络对于像素级标记,如语义分割方面的能力。2014年Jonathan Long等提出的全卷积神经网络(Fully Convolutional Network,FCN)[4],是深度学习应用于图像语义分割的开山之作,将传统卷积神经网络(Convolutional Neural Network,CNN)中的全连接层转化成卷积层,编码部分通过卷积和池化操作获取特征图,解码部分通过反卷积上采样恢复原图尺度,实现像素级分割。然而,相比于CNN下采样阶段的结构规整,FCN上采样时的结构相对凌乱。因此,2015年Vijay Badrinarayanan提出SegNet算法[5],采用了几乎和下采样对称的上采样结构,分割精度及效率均得到提升。针对现有模型由于没有引入足够的上下文信息及不同感受野下的全局信息而存在分割出现错误的情景,Zhao H提出了使用全局场景下的类别信息的PSPNet算法[6],另外还提出了引入辅助损失的深度残差网络(ResNet)[7]优化方法。Deeplab系列(v1,v2,v3,v3+)是由Liang-Chieh Chen等[8-10]提出的,通过不断优化,最近的Deeplabv3+[10]在引用多孔空间金字塔池化(ASPP)网络模块,利用解码编码的形式,扩展了感受野,获取更多的上下文信息,能够实现图像鲁棒分割。总而言之,这些基于深度学习的语义分割算法不断优化,性能得到提升,但这些算法都基于公开自然场景数据集上评价分析,当前针对于高分辨率遥感影像分割分析较少,因此,研究分析这些算法在遥感影像中的分割性能,对于选择合适算法用于遥感图像语义分割具有参考价值。
本文将基于无人机遥感影像,通过定性对比试验和定量评价分析典型的3种语义分割算法SegNet、PSPNet、Deeplabv3+的分割性能。本文首先介绍了这3种语义分割算法基本原理,其次阐述了优化策略,最后通过实验进行全面分析评价。
1 算法原理
1.1 SegNet算法
SegNet类似于全卷积网络的解码编码形式,但编码和解码使用的技术不一致,其网络结构如图1所示。该网络结构是一种对称结构,编码部分使用的是VGGNet网络[11]的前13层卷积网络,通过卷积提取高维特征,并通过池化使图片变小,解码部分通过上采样与反卷积操作使特征图像变大,恢复至原输入图像大小,最后通Softmax层,输出每个像素点不同分类的最大值。由于最大池化和子采样的叠加,会导致边界细节损失增大,因此SegNet在编码特征图过程中储存了最大池化标记位置,并且在上采样过程恢复最大池化位置。

图1 SegNet算法原理
1.2 PSPNet算法
针对大部分全卷积网络的模型都缺少合适的策略去利用全局场景下的类别信息,PSPNet算法引入金字塔池化模块,其原理示意图如图2所示。输入图像通过特征提取网络得到原来图像尺寸1/8的特征图像,特征图像送入金字塔池化模块,金字塔池化分为4种不同尺度,池化之后可得到不同尺寸的特征图,对每个金字塔层级特征图进行1*1卷积降维操作,然后直接对低维的特征图进行上采样,得到原图尺寸。最后,不同层的特征图与原特征图融合连接后经过卷积输出结果。
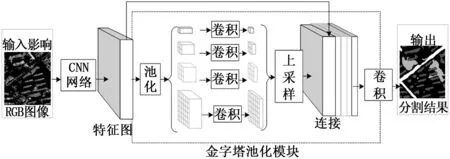
图2 PSPNet算法原理
1.3 Deeplabv3+算法
Deeplabv3+算法采用类似于FCN的编码器-解码器的方式,其原理示意图如图3所示。
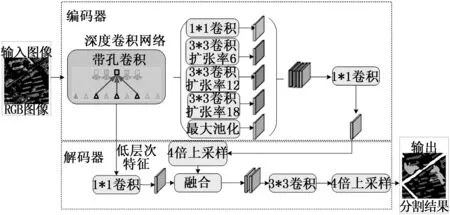
图3 Deeplabv3+原理示意
输入图像利用特征提取网络生成比原图缩小16倍特征图。该算法以Xception网络作为骨架网络,其网络结构由一系列深度可分离卷积、类似ResNet中的残差连接和一些其他常规的操作组成,由于Deeplabv2版本采用的是ResNet作为骨架网络,Deeplabv3+精度较Deeplabv2提升,因此本文不再对该算法下以ResNet作为骨架网络进行训练。Xception网络中引入了ASPP模块,可以在多尺度上捕获信息,实现鲁棒分割。然后将特征图输入到一个256通道的1*1卷积层中。最后,将卷积后的特征图输入至解码器部分实现恢复至原图像大小的分割结果。该解码器借鉴全卷积网络的跳步连接方式,首先利用48通道1*1卷积对低层次特征图卷积,实现特征图降维,再将其与经4倍双线性内插上采样的高层次特征图融合,最后进行3*3卷积操作后经4倍的双线性内插恢复至原图大小,获得分割预测图。
2 优化策略
2.1 迁移学习
受限于硬件环境能力,实际训练中可能不具备分布式GPU环境,并且训练样本规模有限,如果随机给定初始化模型参数权值,训练效果不一定良好。
迁移学习是将算法中的骨架网络在经过海量图像分类数据预训练好的权值,迁移至训练任务中,对网络权值进行初始化。通过迁移学习可加速网络训练速度,提高训练精度[12]。但语义分割算法中的骨干网络和图像分类任务预训练的模型不一定完全一致,如PSPNet算法中的ResNet网络引入空洞卷积策略,而实际预训练ResNet模型不具备该参数,导致两者参数无法一一对应,因此,实际只从预训练模型中加载模型中包含的相关参数字段。
2.2 CNN网络替换
骨干网络是语义分割算法的基础网络,对于提取特征至关重要,网络结构越合理,模型算法效果将更优,也更容易进行训练。为寻求更优的骨干网络,可对算法骨干网络部分进行替换实验,例如,针对PSPNet算法,文献[6]中特征提取网络采用的是带有空洞卷积的ResNet网络,为对比不同骨架网络下的算法性能,本文同时设计采用DenseNet网络[13]作为特征提取网络进行对比实验。DenseNet是一种具有密集连接的卷积神经网络,其基本思路与ResNet一致,但相对于ResNet的“短路连接”,其建立的是前面所有层与后面层的密集连接,可实现特征重用,提升效率。在图像分类领域里,同等精度下,DenseNet的参数量要小于ResNet。
在PSPNet算法基础上,本文利用ResNet和DenseNet不同网络层数的网络结构作为骨干网络设计模型进行实验,分别为ResNet-34,ResNet-50、ResNet-101、DenseNet121、DenseNet169以及DenseNet201,算法生成模型大小如表1所示,其中以DenseNet121为骨架网络的PSPNet模型参数最少,模型复杂度最低,训练时需要梯度下降的参数更少。本文将在节3.3对不同骨干网络进行精度分析。
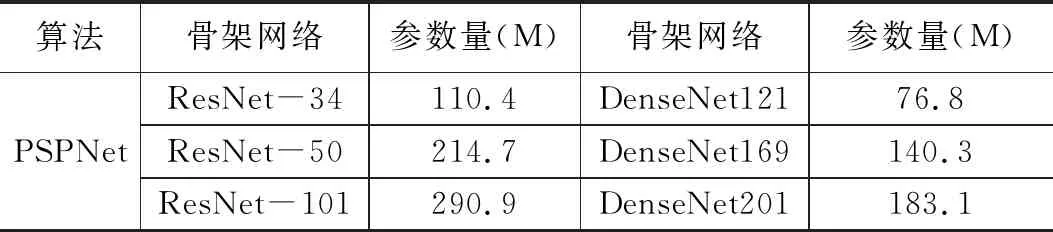
表1 模型参数大小
3 实验分析
3.1 实验平台与数据
实验硬件为联想P920工作站,操作系统为Ubuntu16.04,配置96G内存及NVIDIA TITAN Xp显卡。编程语言为Python,深度学习框架为Pytorch。
实验训练数据为南方某区域2015年5张不同像素大小及区域的无人机遥感影像及相应标记数据,标记分为5类,分别为背景、植被、建筑、水体及道路。将其中4张裁切为300*300大小图片1900张,另外1张裁切为300*300大小图片300张作为验证集。另有多张不同场景的测试影像数据(不带标记)作为分割效果可视化对比验证。由于训练样本数据量有限,仅利用上述样本训练,会造成过拟合现象,为解决这个问题,本文设计了适应遥感数据特点的数据增强器,该数据增强器相比于常规的通过图像单个变换方式增强,不同之处在于其以概率的形式对多种图像变换方式进行组合操作,再将数据固定到指定尺寸,如图4所示。
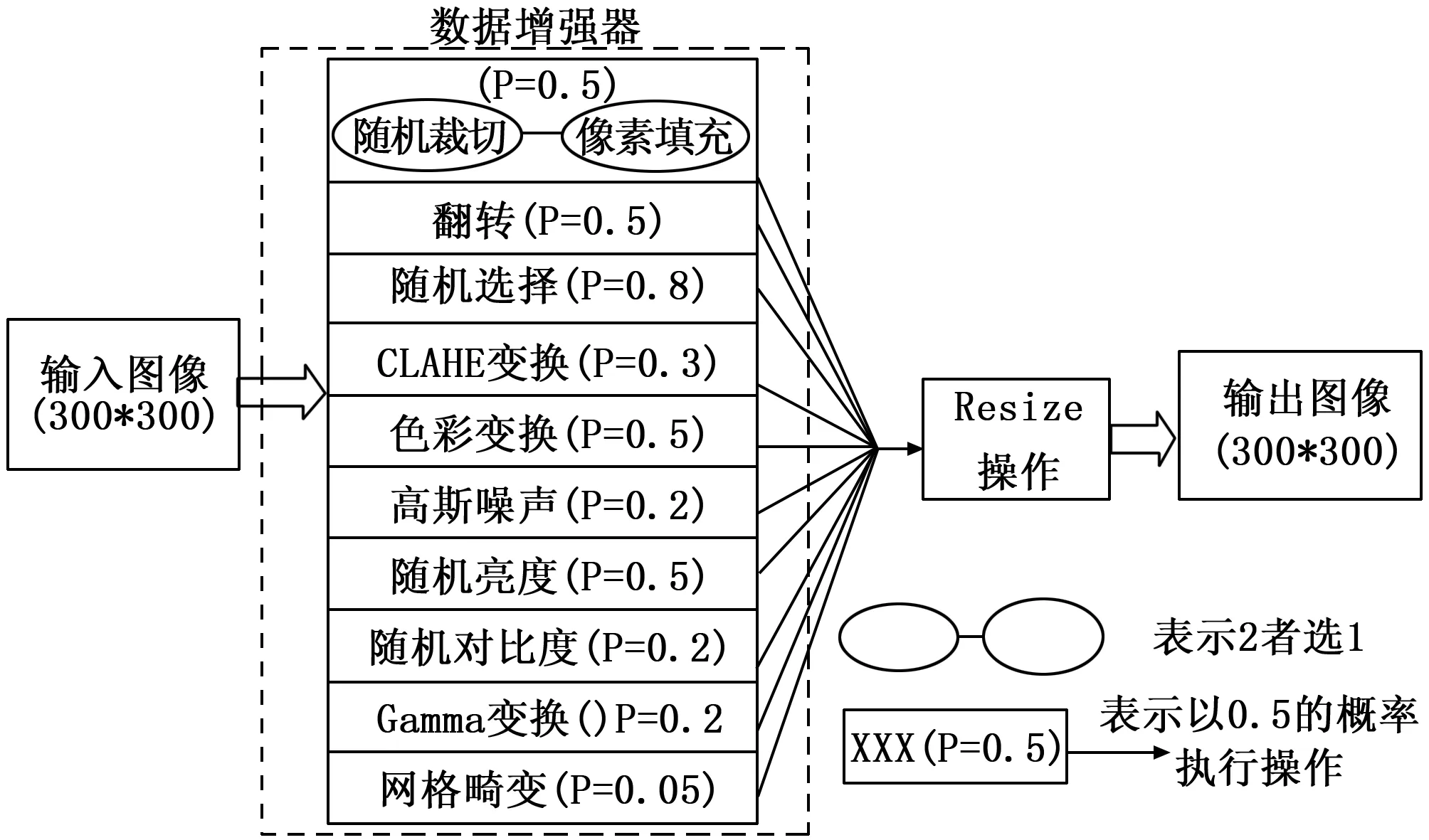
图4 数据增强器设计
在该图像增强器的处理下,每次输入网络中的图片能从色彩、亮度、纹理、尺度等方面保持差别。因此,通过数据增强器能够有效丰富样本的数量。
3.2 精度评价指标
传统影像分类方法采用总体精度(overrall accuracy,OA)、平均精度(average accuracy,AA)和Kappa系数作为评价指标[15]。本文将继续采用OA和AA指标,并引入深度学习标准度量MIoU作为评价指标。假设图像共有k+1个待分割签类别(从L0到Lk,其中L0为背景类),pii表示本属于类i但被预测为类j的像素数量。即pii表示真正例的数量,而pij、pji则分别为假正例和假负例。则总体精度可表示为:
(1)
平均精度是总体精度的一种简单提升,计算每个类别被正确分类像素数量的比例后,计算所有类别的平均值,可表示为:
(2)
MIoU是计算真实值和预测值两个集合的交集和并集之比,在每个类别计算IoU后取平均值,可表示为:
(3)
该指标综合反映了目标的捕获程度(使预测标签与标注尽可能重合)和模型的精确程度使并集尽可能重合)情况。
3.3 迁移学习支持下的性能分析
以PSPNet和SegNet算法为例,骨干网络分别采用ResNet-101和VGG16网络,对迁移训练和未迁移训练的总体精度随着训练epoch(训练集中的全部样本训练一次为1个epoch)变化情况进行对比分析,如图5所示,两种算法均训练150个epoch,批处理尺寸为8,初始学习率为0.001,每50个epoch下降为原来0.1倍。

图5 迁移学习支持下的总体精度对比
从图5可知,在SegNet及PSPNet算法中迁移训练方式结果均要优于随机初始化权值方式,总体精度大概能提升2~5个百分点。收敛速度方面,迁移训练方式快于初始化权值方式,尤其PSPNet算法表现更明显,PSPNet学习率为0.001的情况下,迁移训练方式训练前20个epoch精度上升较快,在第50个epoch降低学习率后,第60个epoch达到收敛,初始化权值方式明显经过训练更多epoch后收敛。因此,利用迁移学习方式是一种有效提升训练效率和精度的方式,尤其是在数据量小或深度学习设备性能有限情况下,迁移学习方式作用更突出。
3.4 不同骨干网络下的性能分析
在迁移学习的基础上,对表1设计的不同骨干网络模型进行训练,训练参数设置同上,训练总体精度随着epoch变化情况如图6所示。结合表1及图6可知,以DenseNet121为基础的PSPNet算法参数量最少,约为以ResNet-34为基础的0.7倍,但最终精度略高于ResNet-34。ResNet和DenseNet相互对应的几种级别网络中,DenseNet精度总体与ResNet相当,表明DenseNet这种密集连接型的卷积神经网络更加优化,能够保证精度的前提下降低模型复杂度,从而降低训练难度。
3.5 验证集精度分析
通过以上实验,验证了迁移学习方式对于训练效果的提升。本文将使用迁移学习对以上3种算法进行训练,其中PSPNet算法采用ResNet-50、ResNet-101、DenseNet169以及DenseNet201网络,SegNet算法采用VGG网络,Deeplabv3+采用Xception网络,3种算法均训练150个epoch,批处理大小为8,初始学习率为0.001,每50个epoch下降为原来0.1,统计分析总体精度、平均精度以及MIoU如表3所示。从总体精度和平均精度来看,Deeplabv3+算法达到最高的总体精度89.3%及平均精度88.9%,相对于SegNet和PSPNet算法提升幅度较大,PSPNet算法中不同骨架网络精度略有不同,但总体变化幅度不大,以ResNet-101为骨架网络精度最高。从MIoU来看,Deeplabv3+算法达到最高80.4%,较SegNet和PSPNet算法提升较大。从分类别精度(AA和IoU)来看,所有类别Deeplabv3+算法均达到最高精度,SegNet算法所有类别精度均不如PSPNet算法,道路及建筑物分割由于复杂程度高于水体及植被,其精度相对于水体及植被更低。为尝试集成学习方法对结果的影响,以PSPNet算法与SegNet算法为基础,利用简单的多数投票法的方式对各模型结果进行融合[16],获得最终结果,从表2可知,融合后的MIoU值相对于PSPNet可以提升1个百分点。
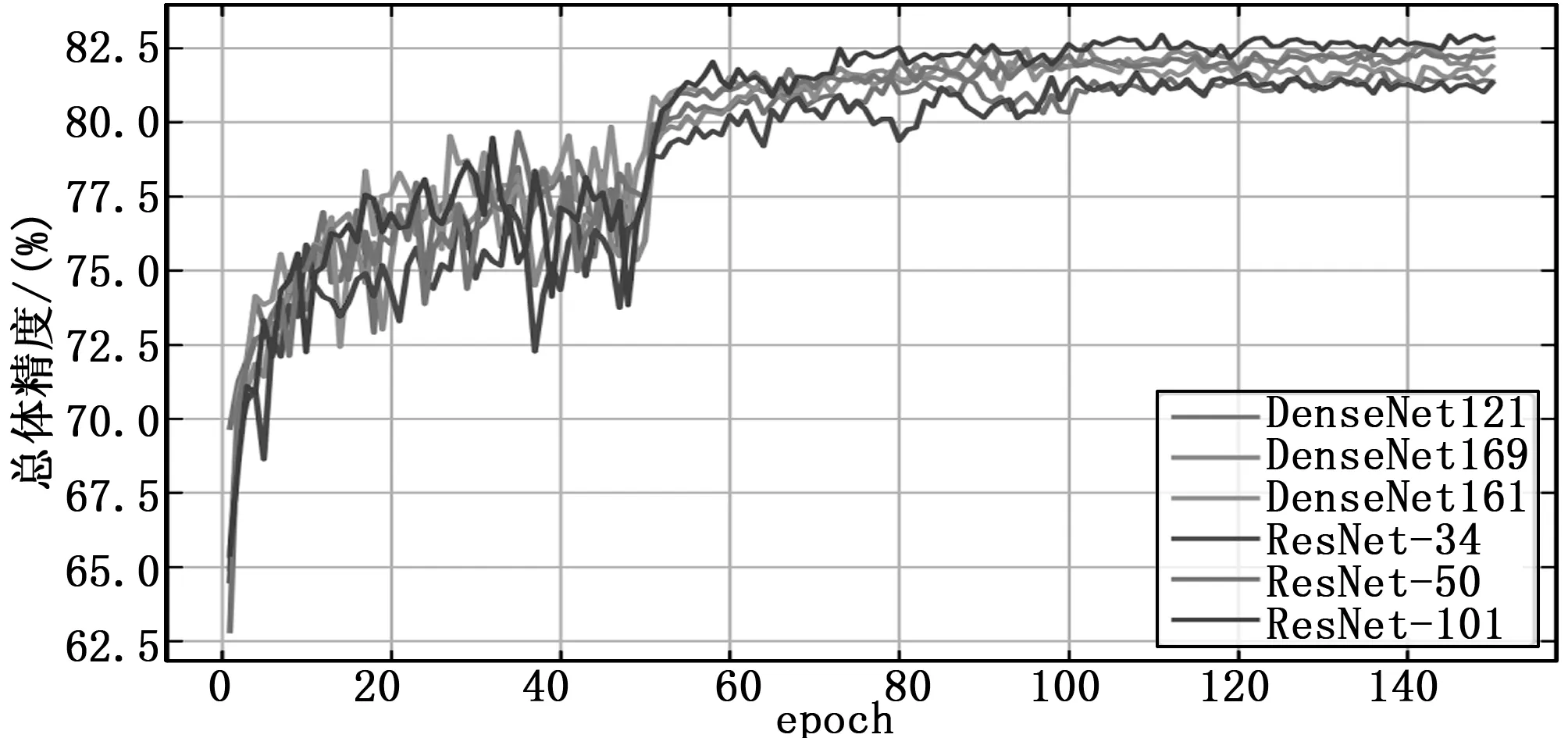
图6 迁移学习支持下的总体精度对比
综合以上可知,Deeplabv3+算法精度远高于其他两种算法,是深度学习语义分割方法运用于遥感影像高精度分割的不错选择。在各种模型算法精度较差情况下,通过多模型投票融合可提升分割精度。PSPNet算法精度虽不如Deeplabv3+算法,但其优势是较为模块化的结构,便于更换CNN网路,降低模型复杂程度。
图7分别采用以上3种算法及SegNet与PSPNet投票融合的方式对验证集图片进行分割可视化(黑色为背景,绿色为植被,蓝色为河流,红色为建筑物,白色为道路),从图7可知,Deeplabv3+算法分割效果最优,边界信息较其他方法更完整,SegNet算法分割图像较粗糙,要素信息完整性不如其他两种算法。通过SegNet与PSPNet算法融合后,分割效果较单个算法更优。
3.6 测试集上结果过对比
测试数据上的分割结果如图8所示,输入图像选择3张1500*1500像素大小的无人机影像,Deeplabv3+分割完整性及边缘信息均要优于PSPNet算法及SegNet算法,尤其是道路的连通性,建筑物的边界效果,说明Deeplabv3+算法能够实现目标的鲁棒分割。
4 结论
基于深度学习的语义分割算法基本结构均是采用解码和编码形式,但通过在算法结构中引入不同模块,可达到不同分割效果。本文对比分析了代表性的3种3种深度学习语义分割方法SegNet、PSPNet、Deeplabv3+的性能。通过无人机影像数据分割试验分析,可得到以下结论:利用迁移学习方式训练,可提升训练精度和加快训练进度,提升总体精度2-5个百分点。编码器部分不同骨架网络可达到不同精度效果,选择一种结构最优且精度较高的骨架网络(如DenseNet),可保证精度的前提下,降低模型复杂度。通过投票集成方式对不同模型或者同模型不同尺度下的预测结果进行融合,可提升训练精度。 Deeplabv3+算法较其两种算法精度更优,能够实现目标的鲁棒分割,将其应用于遥感影像高精度解译是较好的选择。
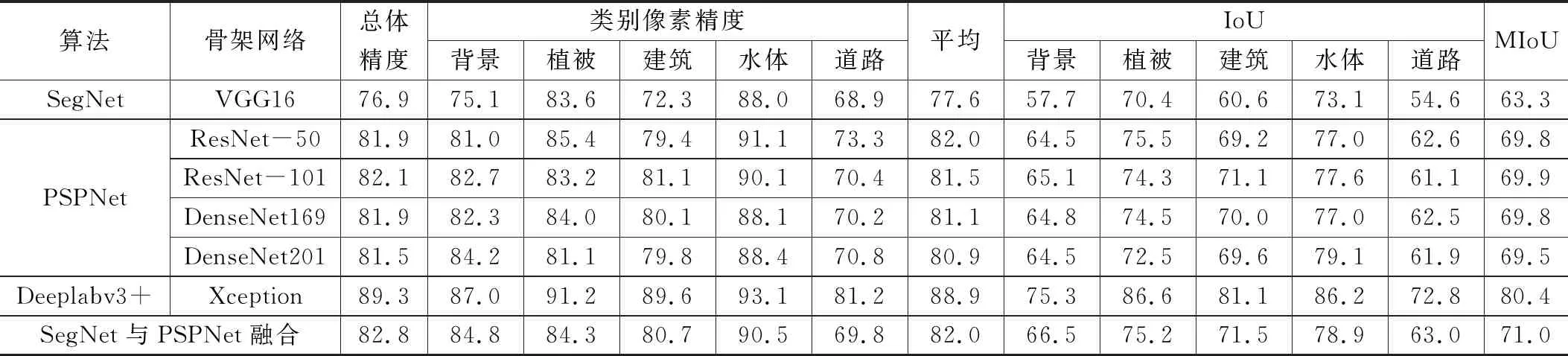
表2 不同算法精度统计情况 (%)

图7 不同算法在验证集上的预测效果对比

图8 测试图片分割效果对比
本文分析的几种典型的算法,对于将深度学习方法用于遥感影像分割方面具有一定参考价值,但由于当前深度学习发展迅速,可能会涌现出更多好的算法,如在网络中引入全局上下文信息模块的EncNet[17],同样能够达到较好效果,后续可对这些算法作进一步研究。
