基于深度学习的实时图像目标检测系统设计
2019-07-25
(1.西北工业大学 计算机学院,西安 710072;2.西安职业技术学院 动漫软件学院,西安 710077)
0 引言
图像目标检测作为当前计算机视觉和深度学习领域的研究热点,主要解决图像中目标的类别和位置信息的获取问题。早期的图像目标检测算法主要基于手工特征提取和分类器实现,如HOG+SVM方法[1]和DPM[2]算法等,不仅缺乏有效的图像表征方法,而且计算复杂。自2012年Krizhevsky等人提出的深度卷积神经网络AlexNet[3]在ImageNet大规模视觉识别挑战赛中夺冠以来,掀起了深度学习技术在图像识别应用领域的研究热潮。众多研究者提出了诸如R-CNN[4]、Faster R-CNN[5]、YOLO[6]和SSD[7]等优秀的深度学习目标检测算法,较大程度地提高了图像目标检测的效率和识别准确率。
在当前研究中,为了构建深度学习图像目标识别系统,算法的实现分为软件和硬件两类。大部分研究者采用软件编程或基于当前流行的Caffe[8]或TensorFlow[9]等深度学习框架在CPU或GPU上实现[3-9]。也有一些研究者采用FPGA或ASIC来设计专用的硬件算法加速器的实现方式[10-11]。采用软件编程方式存在着计算效率低、占用资源多以及功耗高等缺点。基于ASIC实现虽然可以获得良好的计算效率和功耗,但是存在灵活性差和成本高的问题。而FPGA以其丰富的片上资源和可重构的特性,比较适合用于实现硬件算法加速器,但是当前研究中并没有完全发挥出算法和FPGA的计算潜能。
为了适应图像目标检测的嵌入式实时应用需求,充分挖掘目标检测算法及FPGA的并行计算特性,本文首先对基于SSD[7]与MobileNet[12]的深度学习目标检测算法进行了计算优化;然后在基于ZYNQ可扩展平台上搭建了图像目标检测系统,并给出了了软硬件的详细设计;最后通过多个实验表明,系统可有效实现图像目标检测的功能,对于VGA分辨率(640*480)的视频图像处理速度可以达到 45FPS,满足嵌入式实时应用的要求。
1 基于SSD和MobileNet的深度学习目标检测算法及优化
目前主流的深度学习目标检测算法包括以Faster R-CNN[5]为代表的基于区域选择的目标检测算法,和以YOLO[6]和SSD[7]为代表的基于回归学习的目标检测算法。后者相对于前者具有更好的计算效率,只需前馈网络一次计算即可得到检测结果。同时,SSD[7]算法相对于YOLO[6]算法具有较高的识别准确率。因此,本文中将采用基于SSD[7]框架的深度学习目标检测算法进行设计。
1.1 基于MobileNet[12]的SSD深度学习目标检测算法
SSD[7]算法模型通过一个基础的深度卷积神经网络来提取图像的特征,然后在多尺度特征图上的提取局部特征,并将得到的特征用于预测结果。基于MobileNet[12]的SSD[7]深度学习算法模型如图1所示。
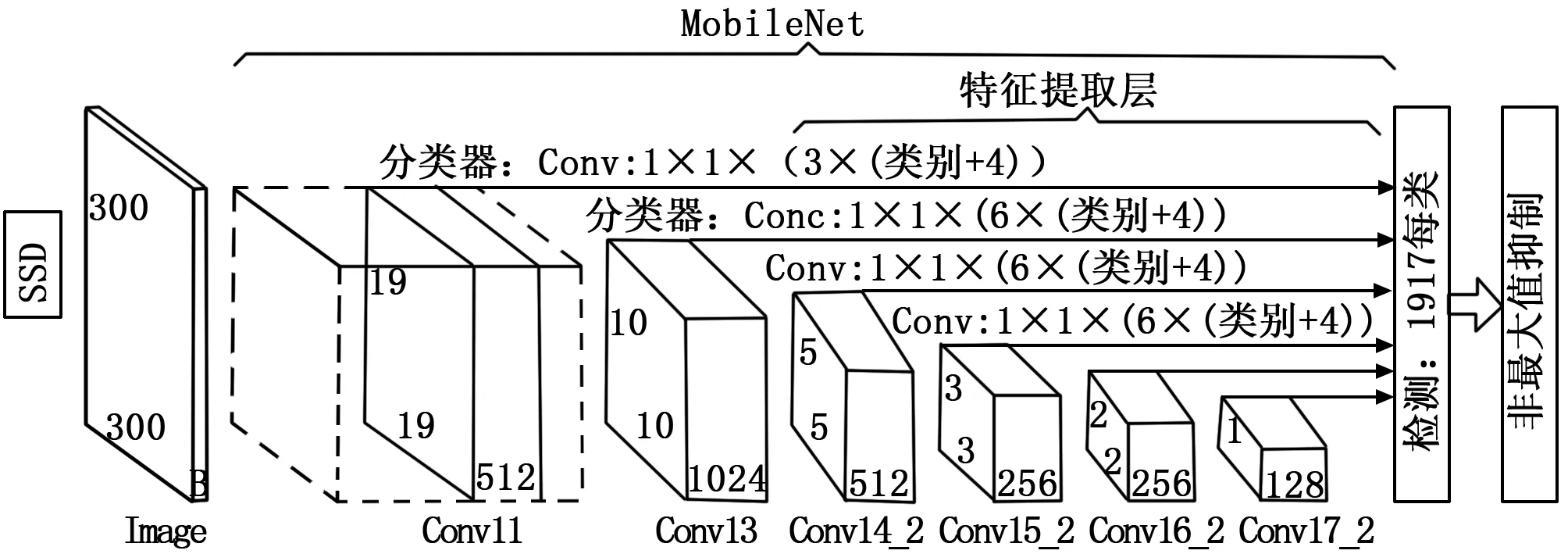
图1 基于MobileNet的SSD深度学习算法模型
为了实现实时处理,本研究采用了适用于嵌入式移动端的轻量级的MobileNet[12]代替文献[7]中的VGGNet作为SSD[7]算法的基础卷积神经网络。MobileNet[12]采用了如图2(b)所示的深度可分离卷积代替标准卷积,很大程度减少了深度卷积网络的参数和计算量。

图2 深度可分离卷积与标准卷积的对比[7]
从图1算法模型和图2中MobileNet[12]的计算结构可以看出,特征提取算法是由卷积层、批量归一化层和非线性激活函数层。下面将根据这些层的计算抽象出算法加速器所支持的基本运算并进行优化。
1.1.1 卷积层
卷积层由多个局部滤波器(卷积核)组成,主要用于从输入特征图中提取不同的局部特征。当输入特征图的尺寸为W×H×Cin,Cout个通道的卷积核表示为Kx×Ky×Cin×Cout,则位于输出特征图fo(fo∈Cout)的(x,y)位置上的神经元N的计算公式如式(1)所示。
(1)
式中,W和B为参数分别表示权重和偏置,N表示神经元,Sx和Sy表示卷积运算在x和y方向上的步长。深度可分离卷积的卷积核通道数Cout的值为1,输出特征图由对应的输入特征图进行卷积运算得到。
1.1.2 批量归一化层
批量归一化层使得整个网络模型更加稳定,并且加快了深度卷积网络训练和收敛的速度,以特征图为一批时,它的计算如式(2)所示。
(2)
式中,mean,variance,scalefactor和ε均为学习得到的参数,mean为与特征图同维度的均值向量、variance为与特征图同维度的方差向量,scalefactor为一维缩放因子,ε为一个很小的常数,通常取0.00001。
1.1.3 缩放层
缩放层对归一化后的神经元N进行比例缩放和位移,它的计算如式(3)所示:
(3)
式中,α和β为与特征图同维度的向量参数。在模型中并不体现该层,由于本文采用深度学习框架Caffe[8]进行算法模型的训练和参数的获取,在该框架中将实际的批量归一化计算分为式(2)和式(3)两步来实现。
1.1.4 非线性激活函数层
为了使深度神经网络具有非线性的学习及表达能力,在其中加入了非线性激活函数层。在基于MobileNet[12]的SSD[7]算法中采用了非线性整流函数(ReLU)作为非线性激活函数,它的计算公式如式(4)所示。
(4)
式中,Ni表示输入神经元。
1.2 算法优化
本文在设计目标检测系统时,侧重于算法推理阶段的计算,训练及参数获取将采用深度学习框架Caffe[8]完成。根据对算法各层的分析,从图2、式(2)和式(3)可以看出实际归一化层和缩放层位于卷积层之后,它们的计算都是针对特征图内单个神经元进行的。因此,通过对训练获取的参数进行预处理,即可将它们合并到卷积层进行计算。具体过程为,设定卷积层输出神经元为Nconv,批量归一化层输出神经元为NBN,缩放层输出神经元为Nscale,首先根据式(2),令:
(5)
(6)
则根据式(2)、式(5)和式(6),式(3)可以变为:
Nscale=αNBN+β=α(PBN_a*Nconv+PBN_b)+
β=αPBN_a*Nconv+αPBN_b+β.
(7)
将式(2)带入到式(7),可以得到:
αPBN_b+β
(8)
式中,α,β,PBN_a,PBN_b为与卷积运算输出特征图同维且对应的参数向量。将批量归一化层和缩放层的参数与卷积层的权重参数进行合并,即可实现三层合一,不仅减少了参数而且减少了计算量。
另外由于算法加速器部分采用了16位有符号定点数来表示神经元和参数,因此对于非线性激活函数ReLU通过判断神经元的符号位即可实现,为了计算的便利性将其设计在算法加速器的计算单元(PE)内,减少了分层计算时将特征图存储后再取出计算的时间。
2 实时图像目标检测系统结构及软硬件设计
2.1 深度学习实时图像目标检测系统体系结构及软硬件划分
实时图像目标检测嵌入式系统应具有图像数据的采集、处理及输出的功能,基于Xilinx公司的ZYNQ可扩展开发平台设计了如图3所示的图像目标检测系统。
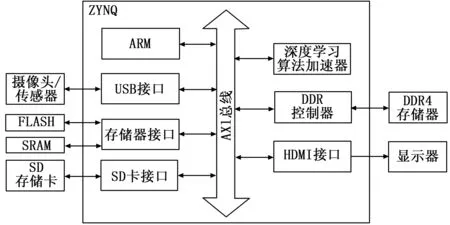
图3 基于ZYNQ的图像目标检测系统结构框图
根据ZYNQ系统的结构和对算法可加速部分的分析进行软硬件的划分。优化后的深度学习目标检测算法的大量计算集中在卷积网络计算,占据了整个算法计算量的90%以上,因此将该部分采用ZYNQ的可编程逻辑端(PL端)以硬件算法加速器的方式实现。算法的PriorBox计算、非最大值抑制计算和Softmax输出因包含开方、指数等计算不便采用硬件实现,因此将采用软件方式计算。系统的图像采集、缓存及输出显示操作将采用软件方式在ZYNQ的可编程系统端(PS端)实现。
在如图3所示的系统结构中,实时的图像采集采用了一款30W像素的CMOS摄像头,捕获画面分辨率为640×480,帧速率30/60 FPS可选,输出为YUV格式,通过USB接口将捕获到的视频图像缓存于DDR4存储器中。
图像的预处理通过ARM处理器通过软件方式完成。主要实现将采集到的YUV图像转换为RGB格式,并进行图像目标检测前的调整大小和去均值操作。
图像的目标检测由深度学习硬件算法加速器完成。算法加速器的参数及操作指令存储于片外的FLASH存储器中,在系统启动时通过AXI总线发送至PL端FPGA的BRAM中,进行图像目标检测时,将预处理后的图像通过AXI总线发送至FPGA的用于存储输入特征图的BRAM中进行目标检测计算,计算完成后将计算结果通过AXI总线发送至PS端缓存中。由PS端完成算法的其余计算。
图像目标检测结果的输出显示由软件实现,将DDR4缓存中的目标检测结果经过标注后通过开发板的HDMI接口在显示器上显示。
2.2 软件设计
ZYNQ的可编程系统端(PS端)的ARM处理器运行在Linux操作系统之上,Linux操作系统的镜像文件存储在外部的SD存储卡中。PS端的软件编程采用了Linux下的PYTHON语言在Jupyter Notebook环境下实现。在本系统中,软件用于控制整个系统的工作流程,主要实现对采集图像的预处理,调用可编程逻辑端的深度学习算法加速器计算,算法的其余计算,以及计算结果在采集图像上标注后输出显示,系统工作的流程如图4所示。

图4 系统工作流程图
目标检测系统的软件部分还包括了参数预处理软件和深度学习指令编译器软件。由于这两部分是在本系统外一次完成,在此不再赘述。
2.3 硬件设计
2.3.1 体系结构设计
根据算法分析及系统软硬件的划分,算法加速器主要完成算法优化后的卷积计算,具有并行度高,计算量大的特点,在此基础上设计了如图5所示的算法加速器体系结构。
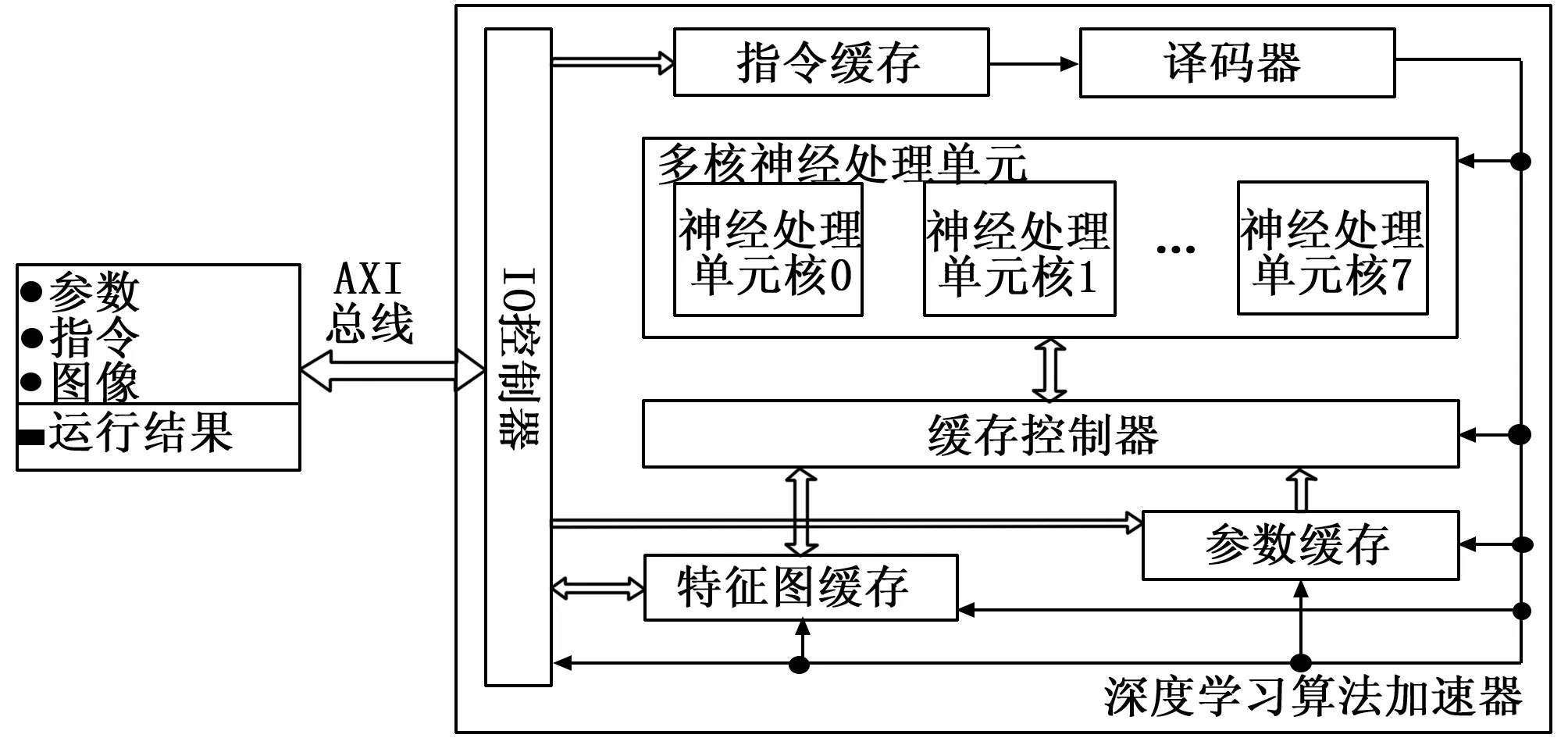
图5 深度学习算法加速器体系结构图
算法加速器结构包含了:I/O控制器、指令缓存、译码器、多核神经处理单元、缓存控制器、特征图缓存(包含输入特征图缓存、输出特征图缓存和临时缓存)和参数缓存。
算法加速器工作时,首先接收系统发送的参数存储于参数缓存,接着在图像预处理完成后接收系统发送的算法加速器指令并读取图像数据存于特征图缓存中,在缓存控制器的控制下从特征图缓存和参数缓存中读取卷积运算的数据和参数经过数据建立组织后发送至多核神经处理单元进行卷积运算。多核神经处理单元包含八个处理核,按照特征图并行的方式进行计算,神经处理单元内为二维的计算单元,以二维并行的方式完成特征图内神经元的计算。神经处理单元完成计算后将输出特征图经过缓存控制器存储于特征图缓存中,以便于下一层计算。直至一帧图像计算完成后将卷积运算结果经I/O控制器发送至PS端,用于后续的PriorBox、非最大值抑制及Softmax输出计算。
2.3.2 神经处理单元核和计算单元的设计
神经处理单元核的设计思路来源于图像卷积运算时的二维滑动窗口过程,采用了二维计算单元的组织方式,并且支持局部的神经元数据传输,以此来减少多次读取特征图的代价。设计的神经处理单元如图6所示。
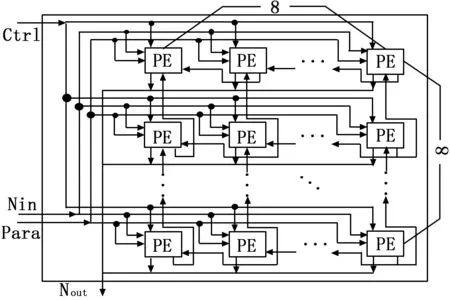
图6 神经处理单元结构
在每个神经处理单元核内包含8*8个计算单元,可同时计算一个特征图中的64个神经元的卷积运算。计算单元采用局部寄存器设计支持神经元数据的行与列传输,基于乘累加器设计了卷积运算单元,通过判断符号位实现了ReLU的计算,所设计的计算单元如图7所示。

图7 计算单元结构
采用Vivado2018.1开发环境基于Xilinx的ZCU104评估板进行算法加速器的硬件实现,占用可编程逻辑端的资源情况如表1所示。
3 实验结果与分析
3.1 训练
深度学习目标检测算法模型基于深度学习框架Caffe以离线方式进行训练,训练过程中采用的硬件环境包括:
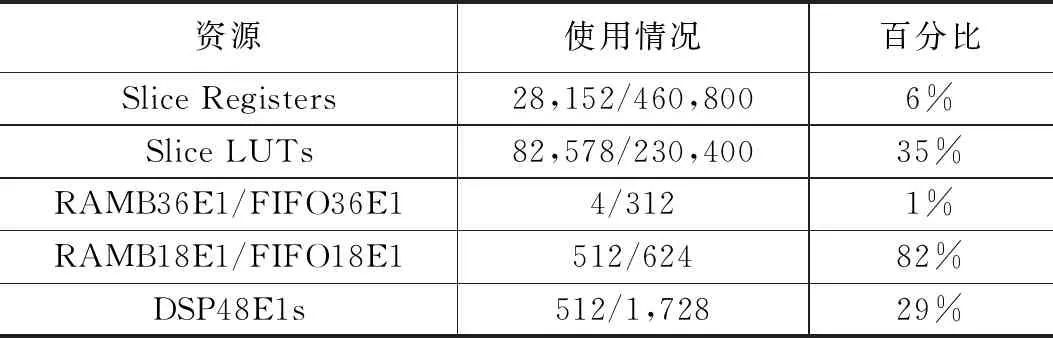
表1 算法加速器主要资源占用情况
Intel Core i7 6700HQ CPU和NVIDIA的GTX960 GPU。训练数据集采用了在Microsoft的COCO[13]数据集上进行预训练,然后在Pascal VOC0712[14]数据集上微调训练,可检测不包括背景的20种物体,获得的平均精度均值(mAP)为0.727。在获取参数并进行预处理后对系统进行测试。
3.2 测试
系统测试环境为Xilinx的ZCU104评估开发板。开发板的PS端运行频率为500MHz,PL端运行频率为200 MHz。采用VOC0712[14]训练验证标准数据集进行静态图片的系统测试测得平均精度均值(mAP)为0.721。
在单幅图片的目标检测时,本文开发系统对比基于Caffe[8]的深度学习框架在3.1节所述CPU和GPU上的运行速度如表2所示。

表2 本文与Caffe在CPU/GPU上运行速度对比
对摄像头实时采集图像进行目标检测时,近景目标检测效果如图8所示,远景检测效果如图9所示,连续帧的目标检测效果如图10所示。

图8 近景效果图

图9 远景效果图
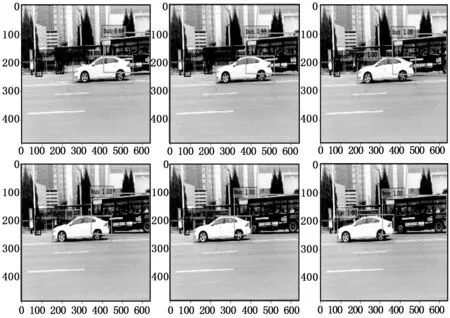
图10 连续帧检测效果图
3.3 测试结果分析
根据测试结果可以看出,在标准测试集上进行测试时,本文设计系统的测试精确率与深度学习软件框架Caffe[8]的测试结果误差不超过1%。由表2可得,本系统的处理速度是CPU的4.9倍,是GPU的1.7倍,检测速度达到45FPS完全满足实时处理的需求。由图8、图9和图10可以看出本系统完全满足对实时采集数据的目标识别,但是对于重叠物和小目标的识别还需改进。
4 结束语
本文针对图像目标检测的嵌入式实时应用,在对算法优化的基础上,采用软硬件结合的方式,基于ZYNQ可扩展处理平台设计了一种基于深度学习的实时目标检测系统。经过多项测试,该系统处理速度可以达到45FPS,完全满足嵌入式实时图像目标检测的应用需求。
