基于大数据技术的短期负荷预测方法分析
2019-07-23王洪森王广府
王洪森,王广府,黄 锐
(广东电网揭阳普宁供电局有限责任公司,广东 揭阳 525300)
0 引 言
为实现系统安全稳定运行,且降低运营成本,电气企业必须做好电力需求预测,尤其是短期负荷预测。随着智能电网建设进程的加快,电力系统运行要求不断提高,对电力短期负荷预测结果与效率的要求也大大提升。
电力系统向自动化、智能化发展,采集的用电信息日益完善,涉及电力系统的监测数据、检测数据、营销数据及管理数据具有类型多、数量大及价值密度低的特点,与大数据典型特征相符。本文提出了基于大数据技术的短期负荷预测,通过特定的分析手段智能化挖掘海量数据,从而提高短期负荷预测的精度和效率,具有实用意义。
1 短期负荷预测的基础性分析
大面积推广应用智能电表和用户信息采集系统后,短期负荷预测要面对大量的信息。通过对用户的用电规律和短期负荷的影响因素等进行基础性分析,有助于短期负荷预测的有序开展。
1.1 电力用户的用电规律
电力用户的用电数据与其用电行为习惯存在一定关联。本文采用的是聚类分析法中简明、实用的SOM算法,即通过假设输入对象具有一定的顺序和拓扑结构,可实现从n维到2维的降维映射,且映射的结果保持了拓扑性质,在理论上与大脑处理有较强的联系[1]。例如,采用该算法对某电力用户10-12月期间的负荷进行分析,发现聚类结果存在5种日负荷类型。第一类,因为包括国庆节,所以负荷曲线明显不同于其他形状;第二类,稳定用电模式,天数为51 d,比例接近50%;第五类,因为存在极端天气致使用电异常,所以属于异常模式;第三类和第四类因为与稳定用电模式相比幅度波动较大,所以属于波动模式。
电力用户的用电模式为研究短期负荷的影响因素提供了基础,同时也为预测模型的设计提供了依据。如果用电负荷趋于稳定或者波动较小的变化规律可选择用时间序列等简单模型,否则需要结合波动原因借助神经网络和支持向量机等模型加以分析。
1.2 短期负荷的影响因素
短期负荷容易受到天气变化、日期类型以及事件类型等诸多因素的影响,而且因为生产特性不一,所以不同用户负荷之间差异明显。这就需要分析两者的相关性,筛选出主导影响因素,通过缩小考虑因素的范围降低数据处理工作量。本文在Spearman方法的帮助下对某地区10-12月份用户负荷数据进行了相关性分析。其中定序型数据包括温度、风速、降雨及湿度等数值。分析结果发现,温度和湿度在很大程度上可以决定负荷分类,而降雨和风速则为间接影响,但因素对用户负荷变化的影响具有优先次序以及阈值。为判断影响因素的重要程度,采用CRT决策树算法进行了计算和分析,结果证明其具有良好的分析效果和较高的准确度[2]。影响规则的分析有助于进一步阐述聚类结果,可以帮助工作人员确定用电模式与影响因素之间的定量关系,进而为研究负荷特性、优化预测参数及调整预测结果提高可靠参考和依据。
2 基于Hadoop的短期负荷预测架构
2.1 系统架构设计
Hadoop是一个用于运行和处理大规模数据的软件平台,可对海量数据进行分布式计算,可适用于大量、复杂电力数据的提取和分析。因此基于Hadoop提出了短期负荷预测系统。该系统主要包括整合用户用电数据、Hadoop处理数据以及分析与预测负荷三大层级和功能。其中,数据的整合指的是抽取、存储及转换采集的用户用电信息,用户涵盖了居民、商业及工业等多种行业。经整合后的数据会统一汇集至Hadoop的数据处理模块,并以业务应用为标准进行分别处理,形成多用户、多日数据的分布式存储与计算,实现个性化的用户数据。由于Hadoop属于大数据平台,连接的分布式服务器不只一台,所以处理效率非常可观,具体流程图1所示。
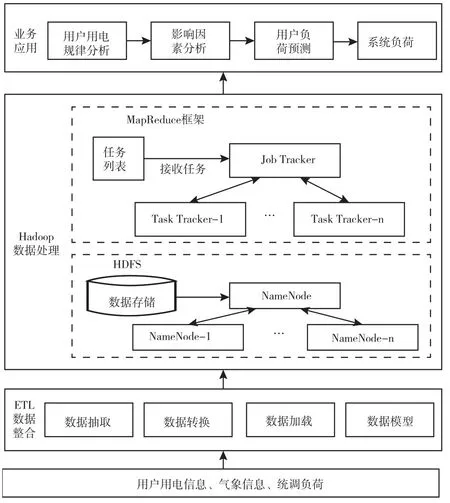
图1 短期负荷预测基本流程
2.2 实现途径分析
基于以上系统架构,需要借助一系列合理的大数据技术实现对短期负荷的预测。既要考虑用户负荷需求,又要兼顾系统网损,以提高负荷分析与预测结果的真实性与准确性。具体地,可以选择电力用户用电模式的类型作为预测模型的基础,选择用户用电影响因素的分析结果为模型参数,参数的设置需要参考实际情况。如果预测日中的气温、降水量及日类型等因素的累积效应对用户负荷有影响,则需要基于影响因素优化预测参数,并赋予其中主导因素以较大的权值[3]。为改善短期预测模型的适用条件和范围,还应切实考虑电力用户之间用电模式的差异性。因此,对短期负荷预测系统设计了适用于平稳序列的ARIMA(自回归移动平均模型)以及适用于易受外界因素干扰的一元回归、模式识别以及神经网络模型,共4个模型。
3 实验测试
为验证该短期负荷模型的预测结果,营造测试环境时选用了4台内存为500 G的PC服务器,配以Mapreduce程序改写并分布至4个接点用于负荷分析与预测计算任务的并发执行。设定某地区电力用户为120万,采集的用电负荷信息时间跨度为3年,基于15 min的采样间隔获得了1.2 T左右的数据,其中典型任务如用电规律和影响因素离线分析以及用户负荷在线预测的测试规模分别为120万用户3年和120万用户单户,测试完成所需时间分别为24 min和110 s,具体计算流程如图2所示。

图2 用户负荷分析与预测的具体流程
分析测试结果发现,基于Hadoop架构的分布式处理技术,能够很好地胜任大规模负荷数据的分析与预测,且随着节点数量的增加,处理能力也在线性增长。同时,基于1个月内用电数据的统计,日平均预测精度和最低精度分别为98.6%和97.4%,比传统的预测方法结果稳定且准确。这是由于全面考虑了短期负荷预测的影响因素,细化了预测对象,并使用了先进高效的数据挖掘技术。
4 结 论
合理预测短期负荷意义重大,但实际操作中却面临诸多影响因素。因此,需要工作人员与时俱进,借助大数据技术挖掘有效的价值信息,为短期负荷预测提供重要的数据支持。需注意结合实际,以大数据技术为媒介构建适用性强、算法精确的短期负荷预测模型,实现快速、准确的预测,以保障精细化的电力调度和经济可靠的电网运行。
