逻辑回归算法在电商大数据推荐系统中的应用研究
2019-07-16潘正军赵莲芬王红勤
潘正军 赵莲芬 王红勤


摘要:针对电商用户大数据的特点,研究了基于品牌偏好预估的推荐算法,比较了关联规则推荐算法和逻辑回归算法在基于品牌流行度的推荐系统中的准确率、召回率和F1性能指标。实验表明,在特征工程比较完善的情况下,逻辑回归算法性能优于基于关联规则的推荐算法。
关键词:大数据;电商推荐系统;逻辑回归算法
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2019)15-0291-03
Abstract: According to the characteristics of big data of e-commerce users, this paper studies the recommendation algorithm based on brand preference prediction, and compares the accuracy, recall and F1 performance indicators of association rule recommendation algorithm and logistic regression algorithm in the recommendation system based on brand popularity. Experiments show that the performance of the logistic regression algorithm is better than that of the recommendation algorithm based on association rules when the feature engineering is relatively perfect.
Key words: Big data; E-commerce recommendation system; Logical regression algorithm
在电商领域,随着用户行为数据的不断累积增长,产生了海量的用户大数据。为了使用户有更好的一站式购物体验,就需要引入推荐系统利用好海量大数据来解决信息过载问题,充分根据用户历史行为、地理位置、社交关系等推荐一些用户想要的个性化结果[1]。推荐的核心问题是如何发现用户对潜在商品的偏好,在用户没有明确意图的情况下,帮助用户发现自己偏好的商品。目前,推荐系统已经在工业界获得了广泛的应用,比如音乐推荐、电影推荐、个性化阅读推荐、社交网络好友推荐、朋友圈推荐以及基于位置的服务推荐等。据统计,Netflix有60%多的电影因推荐而被观看,Google News因推荐提升40%的点击率,亚马逊因推荐被购买的销售占比高达38%。因此,如何利用推荐提高电商用户的体验具有很强的实用价值[2][3]。
1 相关推荐算法介绍
常用的推荐算法主要包括基于关联规则的推荐、协同过滤推荐以及基于逻辑回归模型的推荐等[4]。
1.1 基于关联规则的推荐
基于关联规则的推荐的前提是用户已经购买了某个商品,然后根据用户已购买商品和其他商品之间的相关性做出推荐。关联规则的建立是采用概率统计的方式来判断某两种或者多种商品之间的相关性有多大。这种推荐以实现容易,通用性较好在零售业中得到了较好的应用。但这种推荐的缺点是关联规则的建立容易受到隐含因素的影响,有可能得出相反的结论,要用实际结果校验关联规则的有效性。使用基于关联规则的推荐时,往往借助两个指标评价商品间的关联程度,支持度和信任度,如公式(1)和(2)所示[5][6]。
1.2 协同过滤推荐
协同过滤推荐是利用最近邻算法得到目标用户对物品的喜好程度而产生推荐结果。该算法在一定的数据量下有优秀的表现,也得到了广泛应用。但这种算法的缺点是对于稀疏数据效果不好且性能开销较大,仅适合处理密集数据,如User-based的协同过滤和Item-based的协同过滤的实现[7]。
1.3 逻辑回归算法
该算法是机器学习中的一种分类模型,由于算法的简单和高效,在实际中应用非常广泛。逻辑回归模型的思想来源于线性回归,为了解决线性回归的量纲敏感问题,逻辑回归在线性回归的基础上套用了一个Logistic函数,它的核心思想是,如果线性回归的结果输出是一个连续值,而值的范围是无法限定的,那是否可以把这个结果映射为(0, 1)上的概率值,帮助判断结果。sigmoid函数就是这样一个简单的函数,函数公式如(3)所示。
直观地在二维空间理解逻辑回归,sigmoid函数的特性使得判定的阈值能够映射为平面的一条判定边界,当然随着特征的复杂化,判定边界可能是多種多样的样貌,但是它能够较好地把两类样本点分隔开,解决分类问题[8][9]。
2 基于逻辑回归的推荐算法应用
传统的推荐系统通常采用基于关联规则或者协同过滤作为核心算法,本文研究基于逻辑回归作为推荐的核心算法。通过和关联规则算法进行对比,比较它们在准确率、召回率和F1值上的性能指标。
逻辑回归算法本质是一个线性模型,为了使该算法具有非线性拟合能力,需要使用特征提取、特征选择和特性组合使得特征具备非线性。特征组合是决定该算法性能好坏的关键。本文使用基于规则和基于逻辑回归研究品牌偏好的推荐。
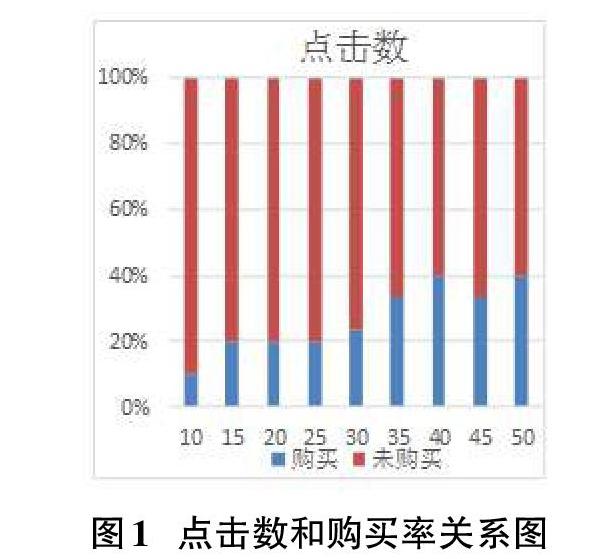
基于规则可以实现简单的推荐,比如,热门排行榜就是一种基于规则(按照访问量取top-k)的简单推荐。对于这类问题,可以根据用户平时的购物习惯得出点击次数越多的品牌,就越有可能购买。因此可对数据集进行分析,分析点击数与购买比例的关系,如图1所示,横轴代表点击次数,纵轴是该点击次数下,品牌是否被购买的比例关系。点击次数越多,购买的可能性越大,因此可以使用这些观察到的规则来进行推荐。
然而,基于规则的推荐因为不能够很好地进行控制导致推荐效果有限。为了得到更好的推荐效果,通常采用其他的推荐算法,比如协同过滤、随机森林、逻辑回归等。由于选取的数据集有限,又限于用户矩阵和商品矩阵过于稀疏,很难通过协同过滤来发现合适的相关性,因此本文选用逻辑回归算法作为推荐算法。
Logistic regression(逻辑回归)是当前业界比较常用的机器学习方法,用于估计某事件的可能性。如某用户购买某商品的可能性、广告被某用户点击的可能性等。如图2所示,逻辑回归公式将事件可能性限制在0到1之间,对应事件发生的概率。
通过逻辑回归,可以得到某用户购买某品牌的可能性,最终按照这个可能性排序来取top-k进行推荐。
3 实验分析
在电商领域,每天都会有数千万的用户通过品牌发现自己喜欢的商品,品牌是连接消费者与商品最重要的纽带。本文的任务就是根据用户6个月在某电商平台的行为日志,建立用户的品牌偏好,并预测他们在将来一个月内对品牌下商品的购买行为。
为了获取更高的F1得分,本文采取不为每位用户都生成推荐内容,而是生成最有可能的购买推荐列表,这一点正好和传统的推荐系统相反。
本文的目标是根据原始的6个月的交互日志数据集来推测下一个月的购买情况。通常的做法是要根据这6个月的数据集通过训练得到推荐模型,在将模型应用到数据中,来得到下一个月的預测结果,再将结果应用到具体的测试数据集中,得到最终的F1得分。因此,首先要将数据集划分为训练集与测试集,训练集用于建立推荐模型,而测试集用于评估模型效果。一般的做法是将原始脱敏数据集均匀分为两份,通过不断地调整特征或者规则,逐步改善推荐模型的效果。
推荐系统的效果,一方面取决于所采用的算法,另一方面则取决于所使用的特征,业界有个常见的说法“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”,可见“特征”在推荐系统中的重要性[10][11]。
对于本研究的问题而言,核心任务定位于特征的选择,通常可以根据用户的网购习惯,综合影响成交的因素,并根据原始实验数据集,将这些因素转化为具体的特征,然后进行检验,争取得到更高的F1得分。
本实验脱敏后的数据集文件有大约10M左右,涉及2千左右电商用户,几千个电商品牌,总共20万多条的行为记录。数据集字段说明如表1所示。
用户对任意商品的行为都会映射为一行数据,其中,所有商品ID都已汇总为商品对应的品牌ID。用户和品牌均用数字ID来表示,且所有行为的时间都精确到“天”级别(隐藏年份)。
3.1 实验环境及评价指标
本实验所采用的环境包括:Linux(Ubuntu14.1)、Python2.7以及依赖包numpy、pandas、statsmodels、scipy、patsy。
实验评价指标:
预测的结果用户存入文本文件中,格式为: user_id \t brand_id , brand_id , brand_id \n,如图3所示。
3.2 基于规则的推荐算法的实验步骤
对基于规则的推荐,通过简化流程,直接根据推荐规则生成推荐结果,并对推荐效果进行检验。
通过实现基于规则的推荐的代码,基准代码采用的推荐规则是推荐最近一个月内有交互,且点击次数大于10次的品牌。运行“recommend-rule.py”,就可以得到最终的推荐效果,代码recommend-rule.py已对执行过程进行了封装,核心代码如下所示:
# 1. 加载数据
data = loadUserData()
# 2. 根据推荐规则生成推荐结果
recommend = getRecommendByRule(data)
# 3. 对推荐结果进行检验
showF1Score(recommend)
通过在userRule.py中定义getRecommendByRule()函数进行特征计算并形成推荐规则,来得到F1的值。通过不断的改进这个函数可以提高F1的值。
3.3 基于逻辑回归的推荐算法的实验步骤
对基于逻辑回归的推荐,则相对复杂一些,通过将前3个月的数据作为训练集,建立推荐模型,然后将推荐模型应用到后3个月的数据中,得到推荐结果。
同样,通过实现基于逻辑回归的推荐的代码,使用到的特征有点击次数、购买次数、加入收藏夹次数、加入购物车次数,交互间隔日期,运行“recommend-logistic.py”,得到推荐结果。
通过在文件userFeature.py中定义generateFeature()函数来进行特征计算,来得到F1的值,并可以通过不断改进该函数来得到更高的F1值。
3.4 两种推荐结果分析
为了直观的分析实验的结果,本文采用多次对比实验,将整个实验分为了采用逻辑回归的推荐和采用基于规则的推荐分别进行,然后二者对同样的数据做分析后得出不同的推荐结果,分别比较他们的准确率、召回率和F1性能指标。
图 4是本文采用的逻辑回归方法和一般的基于规则推荐的准确率比较。从图中数据可以得出,采用了逻辑回归模型对商品特征进行筛选过滤后和采用基于关联规则进行推荐,二者的差距虽然不是很明显,但还是有一定的区别,采用了逻辑回归模型的推荐效果其准确率高于标准的基于关联规则的推荐。随着推荐列表的增长,推荐效果的差距变小,效果最好的时候是在推荐列表为25的时候,此时,逻辑回归算法产生的准确率为4.2%,而基于规则的算法的准确率为3.5%。
图 5是两种不同方式产生结果的召回率比较。从图中数据可以得出,二者的召回率都随着推荐列表的增长出现提高的趋势。在推荐列表为45的时候达到了相对较好的实验结果,此时,采用逻辑回归模型的推荐召回率为9.5%,而基于关联规则的推荐召回率为8.3%左右。通过比较分析得出逻辑回归模型的推荐效果要优于基于关联规则的推荐系统。
根据二种方式的准确率和召回率,通过公式可以计算出它们各自的F1指标。虽然二者的准确率和召回率都不能全面反映最终的推荐效果,但是通过计算它们的F1可以减少对实验结果的影响,能够更好的反映最终的推荐效果。由图6数据得出,基于逻辑回归模型的推荐效果在F1 指标上要优于基于关联规则的推荐系统。
4 结束语
本文在实验中验证了电商大数据中品牌偏好基于关联规则的推荐算法和基于逻辑回归的推荐算法在预测准确率、召回率和F1上的性能指标,实验结果表明基于逻辑回归模型的推荐算法综合性能表现更好。由于数据集选取有限以及数据特征选取的局限性,下一步仍需要进一步在这方面进行验证和提高。
参考文献:
[1] 吴翔宇.数据挖掘在电商客户行为忠诚度预测研究中的应用[D].兰州财经大学,2016.
[2] 唐志燕.基于用户收视行为特征的产品精准推荐研究[D].浙江工业大学,2017.
[3] 卢嘉颖. 基于用户行为的电商推荐系统设计与实现[D].北京邮电大学,2017.
[4] 刘朋.混合个性化推荐方法研究[D].北方工业大学,2018.
[5] 李梦.考虑商品重复购买周期的推荐方法研究[D].武汉科技大学,2018.
[6] 刘军煜,贾修一.一种利用关联规则挖掘的多标记分类算法[J].软件学报,2017,28(11):2865-2878.
[7] 梅刚.基于用户聚类和隐语义模型的协同过滤推荐研究[D].海南大学,2018.
[8] 董书超.基于逻辑回归模型的广告点击率预估系统的设计与实现[D].哈尔滨工业大学,2016.
[9] 许腾腾.基于贝叶斯逻辑回归文本分类模型的改进及其应用[D].兰州财经大学,2018.
[10] 马雅从.基于特征组合的展示广告点击率预估模型研究[D].华南理工大学,2018.
[11] 钱超.基于特征优化的逻辑回归模型在广告点击率问题中的应用研究[D].华中师范大学,2018.
【通联编辑:唐一东】
