基于物品的协同过滤算法对“宁波地铁go”用户个性化推荐系统研究
2019-07-15曹夏琳周健勇
曹夏琳 周健勇

摘 要:随着数据挖掘技术的不断发展,个性化推荐系统在各个领域已被广泛应用,电子商务平台根据用户的历史数据,向其推荐感兴趣的商品,但如今也存在着推荐商品精确度低,特征提取能力有限,标签本身存在冗余问题等。文章通过基于物品的协同过滤算法,在用户群中找到指定用户的相似邻居用户,综合这些邻居用户的行为数据,再引入物品售价权重这一隐氏特征,避免热门物品对推荐结果的恶意干扰,改进传统算法,从而推荐更合适的商品。实验表明该算法对推荐预测有较好的效果。
关键词:数据挖掘;推荐系统;协同过滤算法;售价权重
中图分类号:F713.365.2 文献标识码:A
Abstract: With the continuous development of data mining technology, personalized recommendation system has been widely used in various fields. The E-commerce platform recommends products of interest according to the user's historical data, but now there are also problems of low accuracy in recommending commodities, the feature extraction capability is limited, and the tag itself has redundancy problems. Through the item-based collaborative filtering algorithm. This paper finds similar neighbor users of the specified users in the user group, integrates the behavior data of these neighbor users, and then introduces the hidden feature of the item price weight to avoid malicious interference of the popular items on the recommendation results. Improve traditional algorithms to recommend more suitable products. Experiment shows that the algorithm has a good effect on the recommended prediction.
Key words: data mining; recommendation system; collaborative filtering algorithm; price weight
0 引 言
隨着信息化技术的快速发展,网络已经在人们学习、生活和工作中担任着不可或缺的角色,而在信息过载的今天,如何在浩瀚的信息海洋中找到所需信息,已经越来越引起人们的关注。因此,许多学者致力于研究个性化推荐系统,好的个性化推荐系统能够很好地提高用户体验,帮助减少马太效应和长尾效应,扩大产品的盈利。
现代推荐系统中所使用的技术[1]主要有基于内容推荐、基于关联规则推荐、基于知识推荐、基于上下文推荐和基于深度学习推荐、混合推荐以及协同过滤。协同过滤算法是如今应用最多、最广泛的技术,其核心思想是:在预测用户喜好时,不仅考虑该用户的历史信息,还要结合其他用户对该商品的行动,计算给定用户(物品)之间的相似性,寻找目标用户(物品)的最近邻居集合,利用最近邻居集合中的评分情况来给目标用户推荐相关内容。
1992年,Xerox PARC研究中心开发了实验系统Tapestry[2],该系统首次利用协同过滤技术,帮助用户过滤邮件,解决垃圾邮件问题,此后协同过滤技术开始被广泛应用。
2001年,路海明、卢增祥等人[3]将协同过滤技术与内容相结合,通过网络Bookmark服务,给出了该算法的一个实际应用系统,得到很好的反响。黄光球等人[4]结合了用户兴趣度和协同过滤技术对客户的个人兴趣进行评价,提出了客户兴趣度的商品推荐参考模型,并将此模型应用于电子商务网站的商品推荐,得到了很好的反响。周珊丹等人[5]利用基于用户的协同过滤算法,为用户推荐个性化文物,提高用户在博物馆中的游览体验。王冠楠等人[6]使用多维兴趣向量刻画用户的兴趣,利用协同过滤技术,提高了系统中新闻推荐的专业度。吴国芳[7]通过对用户行为进行分析建立个性化Profile,在图书馆资源个性化推荐中得到了很好的应用。
本文基于协同过滤算法,分析“宁波地铁go”用户的历史数据,挖掘出用户物品间的相关度,再引入用户购买权重这一隐氏特征,综合分析以此预测出用户的消费偏好,并向其推送相应的商品,此方法能够很好地避免无关信息的干扰,解决用户数据不足带来的推荐不准确等问题。
1 协同过滤推荐算法
协同过滤推荐算法一般有两类:基于用户的协同过滤推荐和基于物品的协同过滤推荐。
1.1 基于用户的协同过滤算法
基于用户的协同过滤算法的基本思想是以用户为主体,注重社会属性,利用用户对物品的偏好度计算用户的邻居用户,然后把邻居用户的偏好物品推荐给当前用户,算法步骤如下。
(1)计算目标用户与其他用户的相似度,可以使用反差表忽略一部分用户;
(2)将相似度从高到低进行排列,找到K个与目标用户最相似的邻居用户;
(3)在邻居用户的偏好物品集中,计算出每一件物品的推荐度;
(4)根据每一件物品推荐度的高低向目标用户进行推荐。
这个算法实现起来比较简单,但在实际应用中也存在一些问题,比如当前大多数人喜欢的物品对你来说却毫无意义,或者一些实用性很强的物品,如新华字典、各种工具书等,在你想要买文学书的时候,可能没有必要推荐给你,导致推荐物品的个性化较低。
1.2 基于物品的协同过滤算法
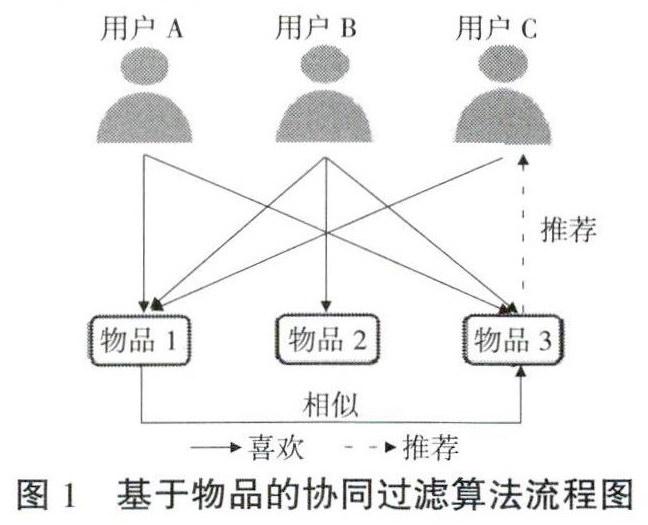
基于物品的协同过滤算法和基于用户的协同过滤算法很相似,核心思想是给用户推荐他们之前喜欢的物品的相似物品。从物品本身出发,基于用户的历史行为数据找到某一物品的相似物品,然后利用最近邻居物品来预测当前用户对邻居物品的偏好程度,从而将偏好度高的物品推荐给目标用户。算法流程如图1所示。
这两种算法各有优势,实际情况下,对于“宁波地铁go”公众号用户来说,目前用户的历史数据量有限,相似用户的可参考性价值不高,与其向用户推荐毫无意义的物品,以物品内在的联系为原则的推荐更加适合现在的平台情况。
2 算法实现
2.1 收集用户历史偏好
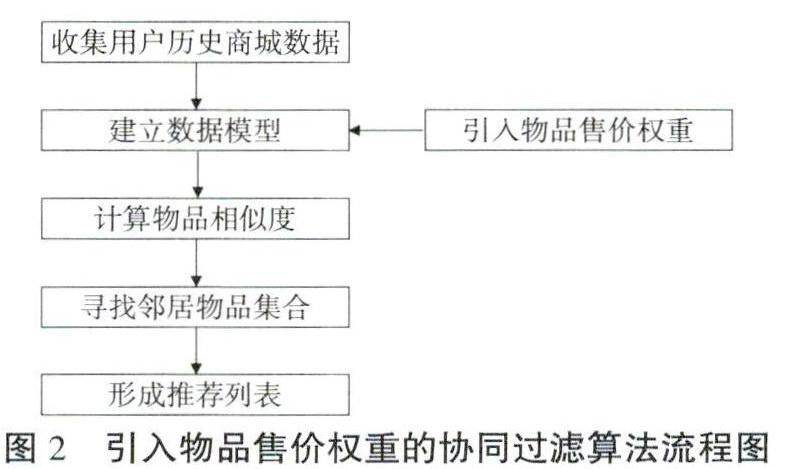
在“宁波地铁go”平台的用户历史商城数据包括用户ID、物品名称、购买数量、物品售价,本文将物品售价作为对某种物品偏好程度的衡量依据,根据用户ID、物品名称、购买数量这三种数据生成初始矩阵X,作为基于物品的协同过滤算法的初始输入数据。建立好数据模型之后,对初始矩阵X进行矩阵相乘,用来对物品售价矩阵L赋权,得到最终矩阵M。在平台所获取的用户数据来看,各种物品的售价差距不小,根据大多数用户的消费心理,售价小又实用的物品往往很受大家欢迎,而这类物品会对推荐结果产生很大的干扰,从而造成推荐结果不准确,这时物品的售价会在一定程度上反映偏好程度,售价高的物品用户仍然购买就说明对这一物品的喜爱程度很高,所以引入这一物品售价权重会使推荐结果更准确。图2为算法的流程图。
2.2 计算相似度
基于物品的协同过滤算法首先要计算物品之间的相似度,传统的方法有余弦相似度计算、皮尔逊相关系数计算等。
(1)余弦相似度计算
3.4 结果分析
本文把传统算法与引入售价权重后的改进算法进行对比,并使用MAE和APC评估其性能,首先售价权重对于整个系统的影响较大,因此需要事先确定一个最佳的售价权重以让整個系统性能最佳,实验结果如图3所示。
从图3可看出,当售价权重为0.4时的平均绝对误差最小,因此以0.4为最佳售价权重,改进传统的基于物品的协同过滤算法,得到的部分推荐结果如表4所示。
在其他参数相同的情况下,把售价权重为0.4时的改进算法与传统算法进行比较,所得推荐结果与实际兴趣物品集比较,并用MAE与APC两个指标来衡量,结果如图4、图5所示。
由图4可知,随着邻居数量的增加,传统基于物品的协同过滤算法与引入售价权重后的改进算法的MAE都逐渐减小到最小值后逐渐增加,并趋于平稳,当邻居数量为20时,两种算法的MAE都达到最小值,此时推荐系统的准确度最高,并且改进后的算法的MAE总体上都要小于传统算法。从图5可看出,改进后算法的平均覆盖率要高于传统算法,说明引入售价权重能够提高整个系统预测的覆盖率,从如今的消费者购物心理来看,售价这一变量确实在很大程度上能反应某些物品的热门度,单价低的物品销量高说明其热门度很高,但如果单价高的物品销量仍然很高就更能说明用户对其兴趣度很高,若以此特性来对用户进行精准营销,一定能增强用户的粘性,挖掘长尾物品,提高平台的利润。
4 结束语
本文在传统基于物品的协同过滤算法上引入售价权重这一隐氏特征,减少了热门物品对推荐结果的恶意干扰,实验结果表明改进后的算法的平均绝对误差和平均预测覆盖率均优于传统算法,在推荐精确度上有所提升。在实际应用中,对于供应商有很大意义,不仅对用户的喜好有所了解,给用户选择购物商品时带来方便,随着积累的用户数据量越来越大,可搭建类似DMP(Data Management Platform)数据管理平台,把分散的多方数据进行整合纳入统一的技术平台,并对这些数据进行标准化和细分,结合用户画像,供应商可以制定精准的营销方案,其经济利益将尤为可观。
参考文献:
[1] 孙光浩,刘丹青,李梦云. 个性化推荐算法综述[J]. 软件,2017,38(7):70-78.
[2] GOLDBERG D, NICOLS D. Using collaborative filtering to weave an information tapestry[J]. Communications of the ACM, 1992,35(12):61-70.
[3] 路海明,卢增祥,李衍达. 基于多Agent混合智能实现个性化信息推荐[J]. 高技术通讯,2001(4):28-31.
[4] 黄光球,靳峰,彭绪友. 基于兴趣度的协同过滤商品推荐系统模型[J]. 微电子学与计算机,2005,22(3):5-8.
[5] 周珊丹,周兴社,王海鹏,等. 智能博物馆环境下的个性化推荐算法[J]. 计算机工程与应用,2010(19):224-226.
[6] 王冠楠,陈端兵,傅彦. 新闻推荐的多维兴趣模型与传播分析[J]. 计算机科学,2013(11):126-130.
[7] 吴国芳. 数字图书馆个性化知识服务研究[J]. 计算机应用与软件,2014,31(5):93-94,183.
[8] 孙多. 基于兴趣度的聚类协同过滤推荐系统的设计[J]. 安徽大学学报(自然科学版),2007(5):19-22.
