数据中心服务器资源监控系统的设计与实现
2019-07-15台宪青吴梦悦马玉峰赵旦谱
台宪青 吴梦悦 马玉峰 赵旦谱
1(中国科学院电子学研究所苏州研究院 江苏 苏州 215121)2(江苏物联网研究发展中心 江苏 无锡 214135)
0 引 言
当前,随着云、分布式、虚拟化等技术的发展,多层级、分布式、多中心的服务体系架构已经普遍存在于公司、企业、政府等多种单位机构中。服务器在服务体系架构中扮演着重要的角色,并且会影响该体系架构的服务质量。因此,为了保障服务体系架构的稳定运行,运维人员需要通过对服务器进行监控的方式,时刻记录服务器资源的状态信息[1-3]。
然而,随着服务体系架构的不断扩大,对服务器集群的运维和监管变得日益复杂。另外,由于服务器集群上的数据量巨大,对服务器状态的监控和故障定位已然给运维人员带来了很大的难度[4-5],导致投在运维上的人力物力成本逐渐加大。此时,如何设计一种直观、高效的服务器资源监控系统,从而规范、合理的管理服务器集群,已经是一个亟待解决的问题[6-9]。
本文考虑了数据中心中服务器资源的有效监控问题,并结合中科院先导科技专项(编号:XDA19000000)软件平台对数据中心服务器集群的监控需求,建立一套完整的实时针对分布式集群服务器资源的监控系统。该系统可以实现如下功能:
(1) 统一管理数据中心的用户权限、服务器及相关设备;
(2) 实时采集服务器运行的状态信息,并进行统计分析和异常报警;
(3) 全面掌控应用系统的进程状态和计算资源使用情况,以便第一时间察觉服务宕机等情况的发生,减少服务失效造成的损失。
1 总体设计
本系统主要由六个模块组成:① 数据采集模块,② 数据存储模块,③ 统计分析模块,④ 异常报警模块,⑤ 系统管理模块,⑥数据可视化模块。系统架构图如图1所示。
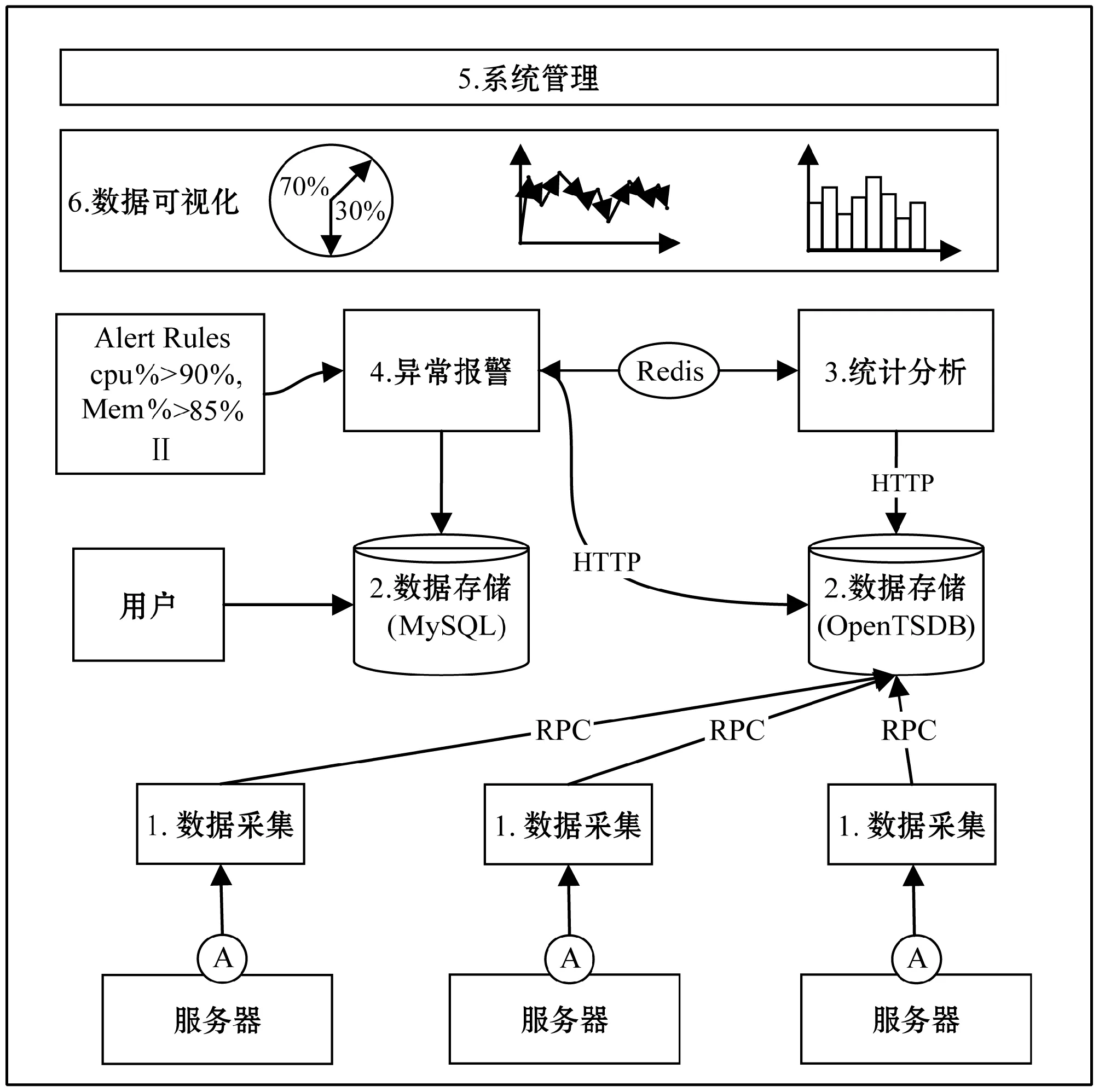
图1 服务器资源监控系统架构图
每个模块的功能概括如下:
① 数据采集模块:该模块负责实时采集服务器资源状态信息,并将信息发送到存储模块进行长期保存。为了减少采集代理对宿主机产生大负载,本系统的采集模块将基于轻量级的采集工具Telegraf进行开发[10]。
② 数据存储模块:该模块用于接收采集模块的数据并进行持久化存储。本系统设计将根据业务需求,采用关系数据库MySQL和时序数据库OpenTSDB组合的方式,对服务器进行实时监控。MySQL主要用于存储用户权限、机房设备等基本数据,而OpenTSDB主要用于存储实时监控数据,并提供高并发访问特性。
③ 统计分析模块:该模块对数据存储模块(OpenTSDB)中的实时数据进行多个维度(比如物理维度、时间维度等)的统计和处理。统计分析的结果主要用于分析服务器的资源使用特性和规律,并为服务器的异常判断提供依据。
④ 异常报警模块:该模块将对采集的数据进行实时的异常检测,并对硬件资源和进程状态异常进行实时报警,避免服务器长时间故障和受到安全威胁造成的损失。
⑤ 系统管理模块:该模块将对中心机房设备、应用服务进程、用户权限等信息进行统一管理,提高机房管理人员的监管效率。
⑥ 数据可视化模块:该模块提供多维、直观的可视化效果,用户可依据自己的需求来定制化配置界面。
2 详细设计
2.1 数据采集模块
由于数据中心的数据量巨大,为了不影响数据中心的整体性能,数据采集模块将基于占用内存小、对宿主机器产生负荷小的Telegraf采集器进行开发。首先介绍采集模块需要采集的信息项,然后详细地介绍基于Telegraf的采集插件开发。
2.1.1采集信息项
本监控系统需要从数据中心服务器中采集到的详细信息如表1-表7所示。这些信息主要分为三种类型:系统信息(表1)、计算资源状态信息(表2-表5)、服务进程信息(表6和表7)。

表1 系统信息

表2 CPU类信息
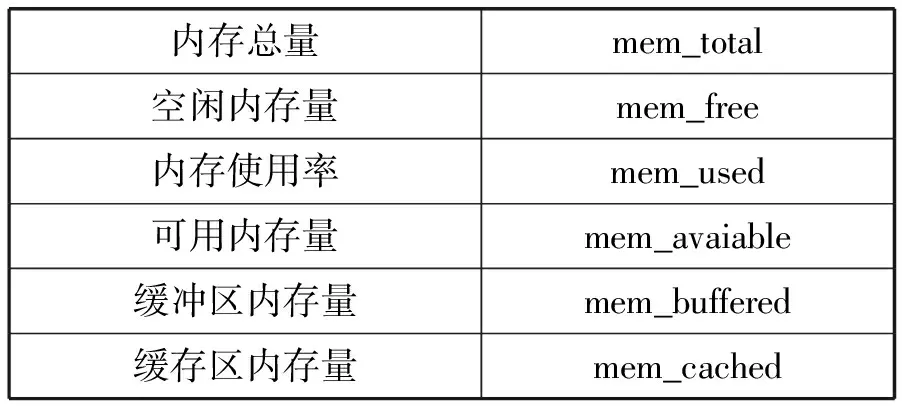
表3 Mem类信息
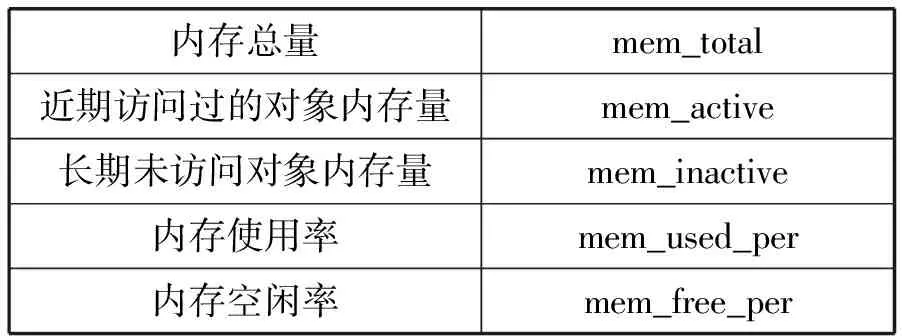
续表3
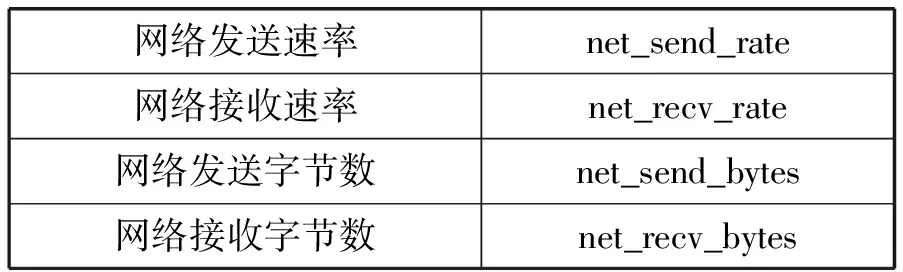
表4 Net类信息
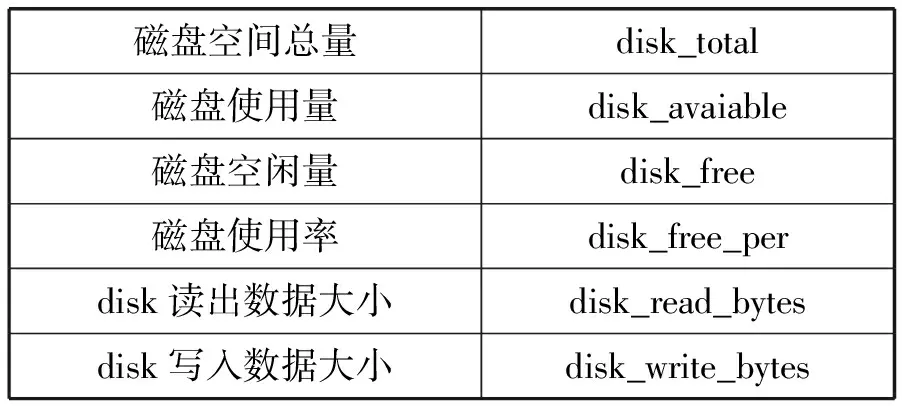
表5 Disk类信息

表6 Process总体信息

表7 Process详细信息
计算资源状态信息包括CPU、内存、网络、磁盘的相关运行状态信息。服务进程信息包括服务器进程总体信息和进程的详细信息,其中进程总体信息是指系统进程总数以及处在各种状态的进程数量;详细进程信息是指单个进程信息的进程名、进程ID以及计算资源利用率。
2.1.2采集器Telegraf插件化开发
Telegraf结构由Input、Processor、Aggreator和Output四个模块组成,如图2所示。其中,Input是数据输入端,支持多种协议方式的数据采集;Processor对采集的数据进行简单的格式化、编码和过滤;Aggregator提供数据的简单聚合功能,如最大值、最小值操作;Output是数据输出端,主要用于将采集到的数据发送到存储端,能够支持的多种类型的数据库和存储方式,如关系数据库、时序数据库、文件系统等。
由于Telegraf仅支持服务器端的系统信息和计算资源状态信息采集,而不支持应用进程相关信息的采集,所以,为了能够采集到服务器的进程信息,我们需要在Input插件模块中添加“process”插件。
图3是Process插件的主函数开发流程图。在该流程中,首先,调用Init()函数初始化Input插件,将其命名为“process”。然后,定义Description()函数对其功能、属性进行描述;定义SampleConfig()函数对其参数进行配置。最后,创建核心函数Gather()用来进行监控数据的统计,统计好的数据在Gather()函数中进行封装,并回到主函数中完成插件的注册。
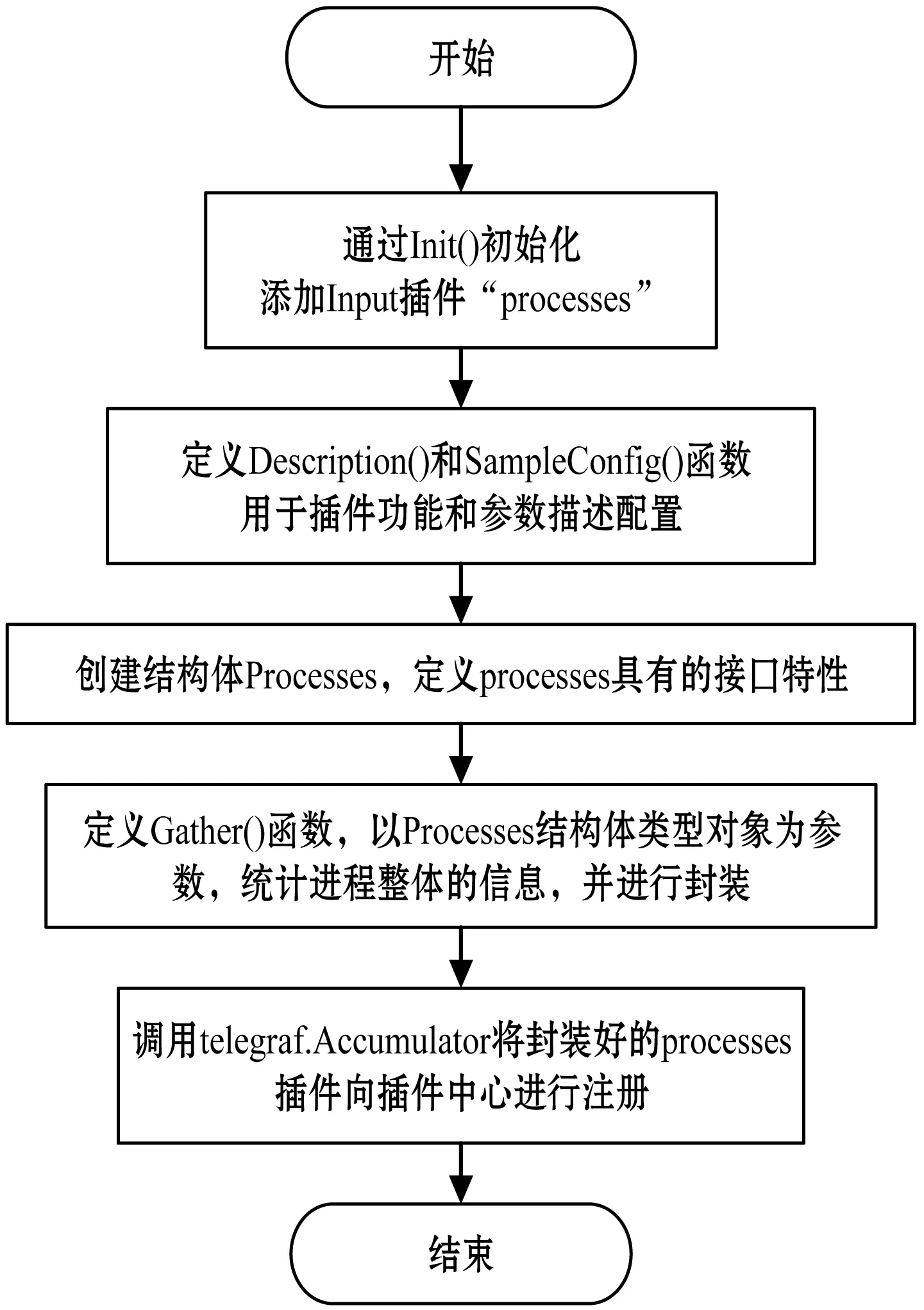
图3 Telegraf input插件开发主函数流程图
Gather()函数的开发流程如图4所示。首先,传入参数acc。接着,获取空的fields数组进行属性定义。然后,通过runtime.GOOS获取系统类型,并调用getFromProc()函数(图5)读取服务器/proc目录下的内核信息进行进程信息的统计,最后对measurement、fields数组封装。

图4 gather()函数流程图
2.2 数据存储模块
本监控系统的存储模块主要用于存储两类信息:静态的基本信息和动态的监控信息。基本信息包括用户、权限、机房、机柜、服务器、应用服务等,多为结构化数据,主要用于联表查询,因此采用关系数据库MySQL来存储。MySQL中包含的表ER图如图6所示。

图6 MySQL表ER图
监控信息多为海量连续的时间序列数据信息。为了提高该种类型数据的存储效率,采用基于HBASE改进的OpenTSDB时序数据库来对监控信息数据进行存储。在该数据库的执行过程中,为了提高存储和传输效率,采用key-Value的存储形式,以此来减少传输和存储过程中所占用的空间大小,其中key的值可以结合具体应用场景来设置为时间、机器编号等值。监控信息的数据存储格式如下所示:
metric:cpu_usage
timestamp:1234567890
value:0.42
tags:host=web42,pool=static
其中:metric表示监控信息名称;timestamp表示数据产生的时间;value表示监控信息(metric)的具体值;tags是对监控数据的描述,通过tags可实现数据的快速定位、检索和统计分析。
2.3 统计分析模块
统计分析模块对数据分析过程分为三部分:数据读取、聚合分析、数据存储,如图7所示。首先,读取OpenTSDB中存储的原始数据。然后,进行多维度的计算分析,依靠服务协调来保证计算过程的准确性、实时性、扩展性,获取数据的周期特性和统计特性,便于管理人员和运维人员掌握数据中心服务器总体资源的概况。最后,将统计结果存入到OpenTSDB数据库。

图7 统计分析过程图
在数据的读取过程中,采集器以秒级频率采集数据。由于单线程读取数据的时间效率很低,当时间跨度较大时,读取过程采用多线程方式。而当时间长度大于小时级别时,为进一步提高读取效率,对时间间隔进行划分,采用低粒度的时间间隔读取数据,每一个小的时间间隔用一个线程来读取,读取的数据发送到统计分析服务器进行分析处理。数据读取逻辑如图8所示。
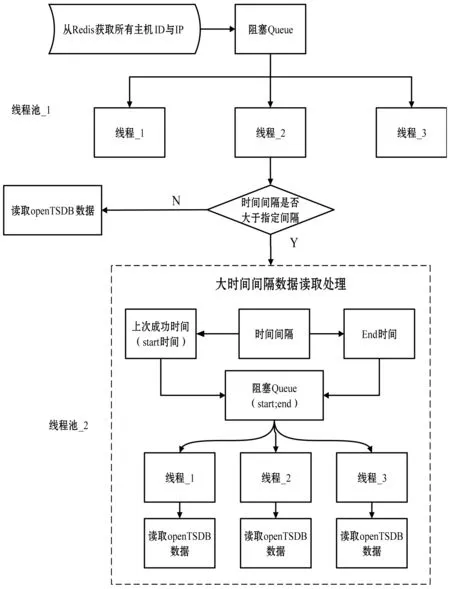
图8 多线程数据读取逻辑图
另外,OpenTSDB支持http接口协议,对服务器IP、时间戳、监控信息项进行封装,通过httpClient向OpenTSDB发出请求,其将结果通过同样的格式返回,统计分析模块对结果进行Json解析,最后以Java对象格式获取数据。HTTP请求OpenTSDB逻辑如图9所示。
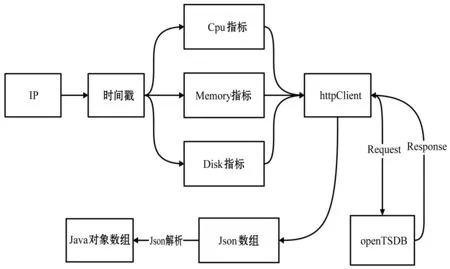
图9 OpenTSDB HTTP协议访问流程图
聚合分析模块使用HTTP接口从OpenTSDB读取监控信息进行分析处理,并将结果使用HTTP接口写回时序数据库,以备前段页面进行展示和历史纪录查询。
聚合分析主要是对一段时间内各类监控信息数据求均值,用于资源状态的评估。对于秒级和分钟级的聚合操作直接利用时序数据库的高并发特性聚合读取,而对于小时、日、月、年等级别的数据聚合则要通过数据分级统计,粗粒度时间聚合在细粒度数据聚合基础之上进行计算。分级统计逻辑如图10所示。

图10 分级统计逻辑图
在图10中,分级统计采用双队列多线程池方式,细时间粒度的数据完成自身数据的聚合操作,同时将数据存入数据库作为粗时间粒度数据聚合的基础,实现一次数据读取、多次数据处理的效果。同时计算型线程和IO型线程分离,提高了统计分析的效率。
本系统需支持多个机房百台至千台级别服务器的监控,实时采集周期最小支持为1秒,监控信息项为60条,统计分析维度达10个维度。为满足海量数据的实时处理要求,系统采用分布式集群方式对监控信息进行处理,通过服务协调来保障新增服务器数据被处理、且只被单个统计服务实例处理。其中为防止统计分析服务实例宕机造成的个别服务器数据不被处理,使用Hash取模法对服务器id进行计算,获得该服务器所属的服务实例。当出现服务实例宕机的状况便对所有服务器id进行重Hash计算。统计分析模块实现流程图如图11所示。
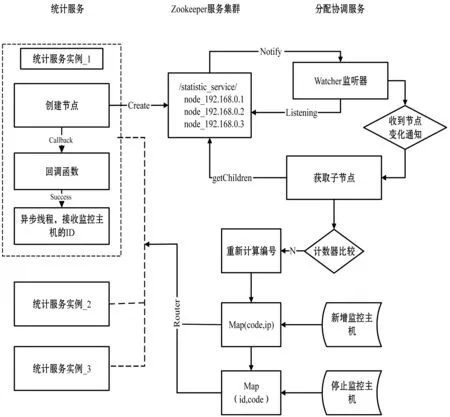
图11 统计分析模块实现流程图
各个统计服务是并行计算的,统计服务实例可以根据监控服务器数量增加或减少,实现了统计服务的弹性部署,合理利用资源。
采用zookeeper集群监控当前在线的统计服务实例的运行状态,当一台统计服务器上线时,会向其注册临时节点,该临时节点的值为当前服务器的IP地址和端口号构成的可路由的地址,当一台统计服务实例下线的时候,临时节点便被删除。当服务器增加或者服务器减少,zookeeper集群都会通知协调分配服务,重新进行任务的划分。
协调分配服务通过watcher监听器监听服务器的变化,更新本地缓存表并对新增加的服务器进行编号,利用Hash算法对服务器id进行取模计算,获取对应的统计服务实例,或者删除某服务器id。
2.4 异常报警模块
进程挂机或者资源占用异常会影响服务器的处理速度或提供服务的能力,因此需要设定报警规则对异常事件进行报警。异常报警模块将提供报警规则设定和管理、历史报警事件记录的功能。
本文主要针对系统负载、计算资源和服务状态三个方面进行异常检测和报警通知。其报警模块架构图如图12所示。

图12 异常报警模块架构图
在本系统的报警规则中,当各个指标满足一定的报警条件时,报警模块将根据不同的阈值触发不同级别的报警。表8定义了warning和critical两种默认的报警级别。
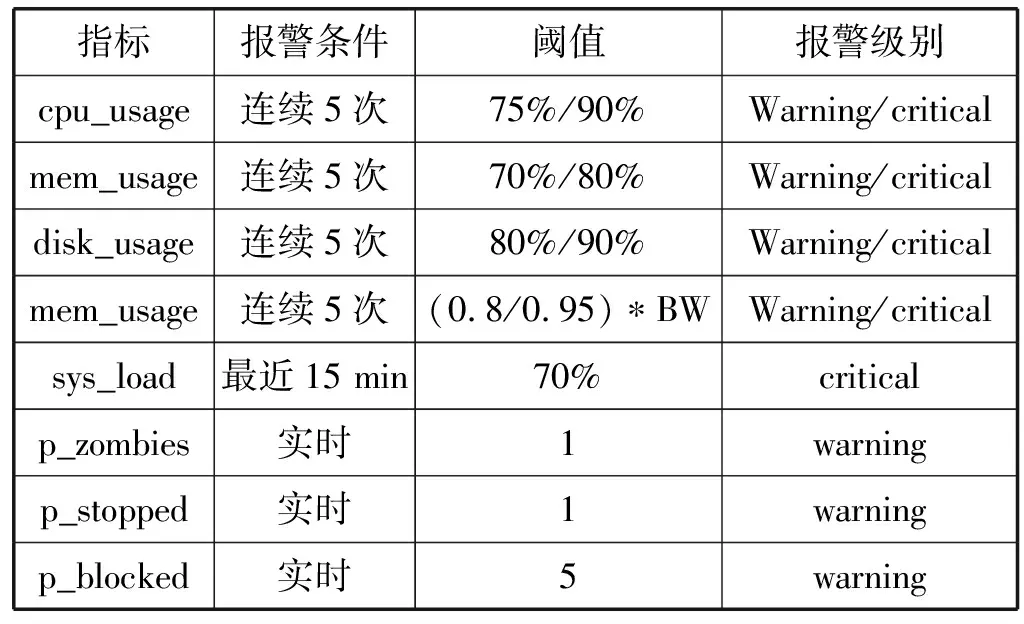
表8 默认报警规则表
另外,本系统还提供报警规则配置接口,供用户进行规则的自定义。异常报警模块的原理如图13所示。

图13 异常报警模块逻辑图
从OpenTSDB数据库中读取最新采集到的数据经过预处理操作,并和redis缓存的报警阈值数据进行对比,对于连续超过阈值和限定次数的事件判定为异常,可为各种报警方式提供触发信息。
2.5 管理模块
系统管理模块包括对用户权限信息管理和中心机房设备管理两部分,如图14所示。
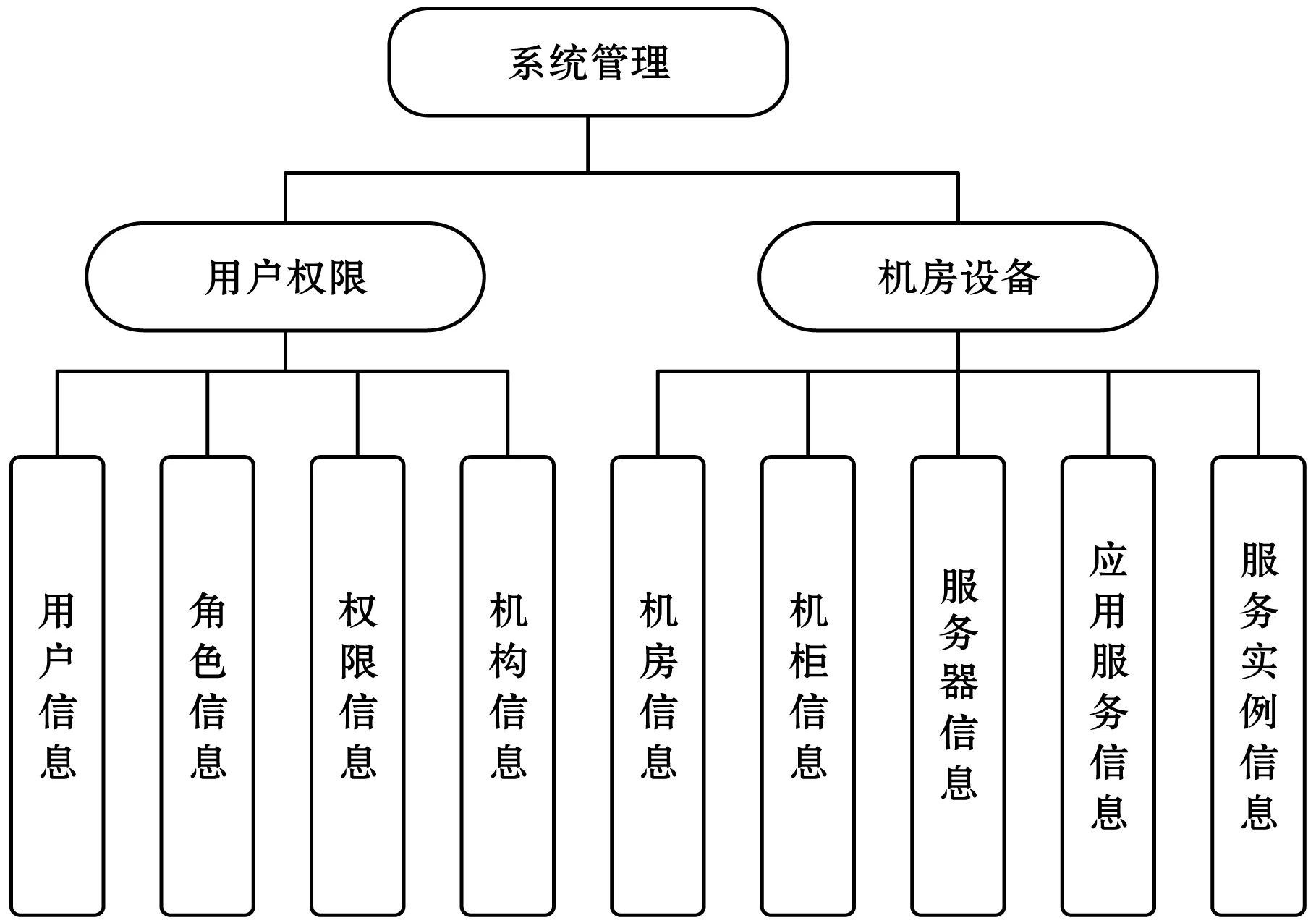
图14 系统管理模块功能结构图
在用户权限的管理中,系统根据用户的角色和所属机构进行角色权限访问控制。在机房设备管理中,系统采用树形层级结构来管理中心机房中的所有设备,以便维护人员可以根据层级关系查看总体概况。
3 系统实现
在本节中,我们将依次展示所开发的资源监控系统在数据采集、异常报警和系统管理方面的效果。
图15展示了系统在部分硬件指标上的数据采集结果。通过可视化分析工具,我们可以通过文字、柱状图、折线图等多种方式,直观、清晰地发现服务器在CPU、磁盘以及网络方面的实时状态结果。

图15 硬件指标数据实时显示
图16展示了报警规则设置界面,供用户根据实际情况进行报警规则自定义,用户可定义指标阈值和报警条件,并选择报警方式。

图16 报警规则配置界面
图17展示了系统给操作者提供的信息管理统一接口,以列表和表格的形式展示用户、角色、机构、权限、机房、机柜、服务器、应用服务、服务实例的信息,用户可在界面对数据进行查看、编辑和删除操作。

图17 系统管理模块界面
4 结 语
本系统针对数据中心大规模服务器资源的监控需求,设计并实现了一套完整的解决方案。在该方案中,采集端使用轻量级负载小的采集代理Telegraf,对服务器系统信息、计算资源状态信息、服务进程信息进行采集,并将采集结果发送到时序数据库OpenTSDB中存储。OpenTSDB以较小的存储空间和时序函数优越的查询性能,保证监控时序数据的高效存储和快速处理海量数据的能力。统计分析模块采用分布式集群技术、多机协同数据处理方法和分级聚合分析算法,对海量监控数据实现实时的分析处理。异常报警模块提供多种报警方式和报警手段。资源可视化模块提供了丰富的可视化形式和直观的监控信息展示方式。最后,系统实现用户信息、机房设备、服务应用的统一管理,将繁杂的信息管理系统化和条理化。
