浅谈TCP拥塞控制算法
2019-07-14

TCP/IP和Linux系统层级的很多设计都可以用于中间件系统架构上,比如说TCP拥塞控制算法也可以用在以响应时间来限流的中间件上。像TCP/IP协议这种技术,都是经过长时间的考验的,都是前人智慧的结晶,学习后可以给大家很多启示和帮助。
TCP协议有两个比较重要的控制算法,一个是流量控制,另一个就是拥塞控制。
TCP协议通过滑动窗口来进行流量控制,它是控制发送方的发送速度从而使接受者能及时接收并处理数据包(以下简称包)。而拥塞控制作用于整体网络,它是防止过多的包被发送到网络中,避免出现网络负载过大,出线网络拥塞的情况。
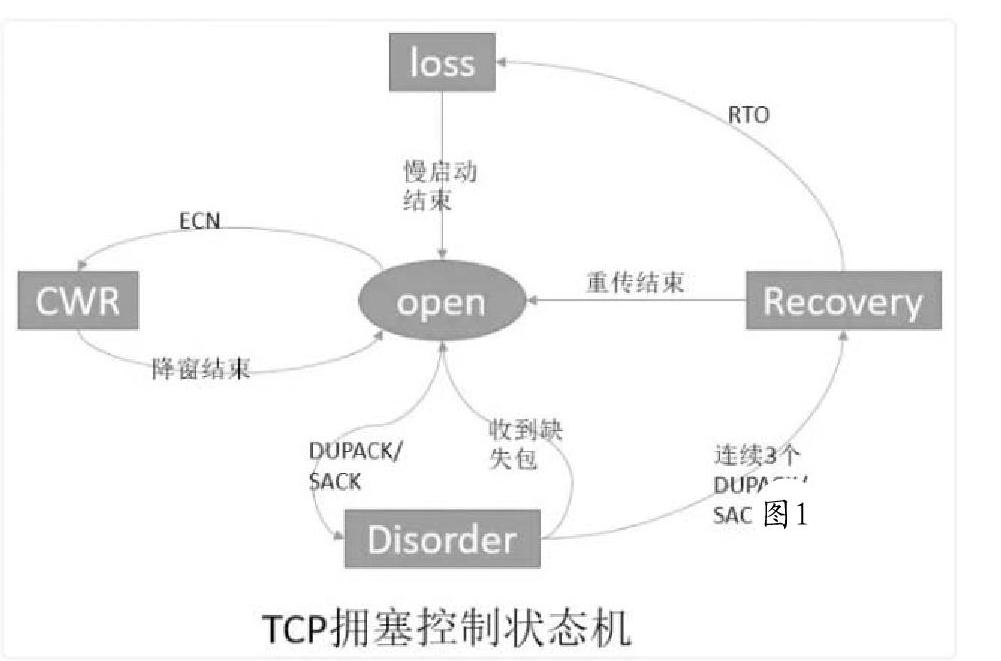
了解拥塞控制算法需要掌握其状态机和四种算法。拥塞控制状态机有五种,分别是Open、Disorder、CWR、Recovery和Loss状态。四个算法为慢启动、拥塞避免、拥塞发生时算法和快速恢复。
※拥塞控制状态机
和TCP一样,拥塞控制算法也有其状态。当发送方收到一个ACK时,LinuxTCP通过状态机的状态来决定其接下来的行为,是应该降低拥塞窗口cwnd(CongestionWindow)值,或者保持cwnd不变,还是继续增加cwnd。如果处理不当,可能会导致丢包或者超时。
1.Open状态
Open状态是拥塞控制状态机的默认状态。这种状态下,当ACK到达时,发送方根据拥塞窗口cwnd是小于还是大于慢启动阈值ssthresh(slowstartthreshold),来按照慢启动或者拥塞避免算法来调整拥塞窗口。
2.Disorder状态
当发送方检测到DACK(重复确认)或者SACK(选择性确认)时,状态机将转变为Disorder状态。在此状态下,发送方遵循飞行(in-flight)包守恒原则,即一个新包只有在一个旧包离开网络后才发送,也就是发送方收到旧包的ACK后,才会再发送一个新包。
3.CWR状态
发送方接收到一个显示拥塞通知时,并不会立刻减少拥塞窗口cwnd,而是每收到两个ACK就减少一个段,直到窗口的大小减半为止。当cwnd正在减小并且网络中有没有重传包时,这个状态就叫CWR(CongestionWindowReduced,拥塞窗口减少)状态。CWR状态可以转变成Recovery或者Loss状态。
4.Recovery状态
当发送方接收到足够(推荐为三个)的DACK(重复确认)后,进入该状态。在该状态下,拥塞窗口cnwd每收到两个ACK就减少一个段(segment),直到cwnd等于慢启动阈值ssthresh,也就是刚进入Recover状态时cwnd的一半大小。发送方保持Recovery状态直到所有进入Recovery状态时正在发送的数据段都成功地被确认,然后发送方恢复成Open状态,重传超时有可能中断Recovery状态,进入Loss状态。
5.Loss状态
当一个RTO(重传超时时间)到期后,发送方进入Loss状态。所有正在发送的数据标记为丢失,拥塞窗口cwnd设置为一个段(segment),发送方再次以慢启动算法增大拥塞窗口cwnd。
Loss和Recovery状态的区别是,Loss状态下拥塞窗口在发送方设置为一个段后增大,而Recovery状态下拥塞窗口只能被减小。Loss状态不能被其他的状态中断,因此,发送方只有在所有Loss状态开始时正在传输的数据都得到成功确认后,才能退到Open状态。
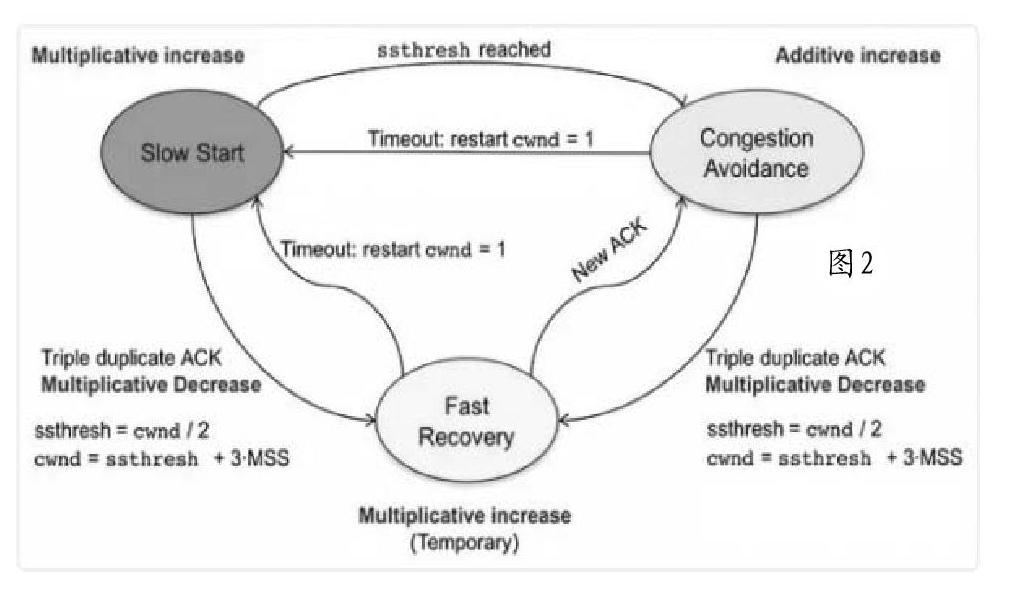
※四大算法
拥塞控制主要是四个算法:慢启动、拥塞避免、拥塞发生、快速恢复。这个四算法的发展经历了很多时间,直到今天都还在优化中。
1.慢启动算法(SlowStart)
所谓慢启动,也就是TCP连接刚建立,一点一点地提速,试探一下网络的承受能力,以免直接扰乱了网络通道的秩序。
(1)连接建好的,开始先初始化拥塞窗口,cwnd值大小为1,表明可以传一个MSS大小的数据;
(2)每当收到一个ACK,cwnd值加1,呈线性上升;
(3)每当过了一个往返延迟时间RTT(Round-TripTime),cwnd值直接翻倍,呈指数让升;
(4)还有一个ssthresh(slowstartthreshold),是一个上限,当cwnd≥ssthresh时,就会进入“拥塞避免算法”。
2.拥塞避免算法(CongestionAvoidance)
如同前邊所说的,当拥塞窗口大小cwnd大于等于慢启动阈值ssthresh后,就进入拥塞避免算法。算法如下:
收到一个ACK,则cwnd=cwnd+1/cwnd,每当过了一个往返延迟时间RTT,cwnd值加1。过了慢启动阈值后,拥塞避免算法可以避免窗口增长过快导致窗口拥塞,而是缓慢地增加调整到网络的最佳值。
3.拥塞状态时的算法
一般来说,TCP拥塞控制默认网络丢包是由于网络拥塞导致的,所以一般的TCP拥塞控制算法以丢包为网络进入拥塞状态的信号。对于丢包有两种判定方式,一种是超时重传RTO(RetransmissionTimeout)超时,另一个是收到三个重复确认ACK。
超时重传是TCP协议保证数据可靠性的一个重要机制,其原理是在发送一个数据以后就开启一个计时器,在一定时间内如果没有得到发送数据报的ACK报文,那么就重新发送数据,直到发送成功为止。
但是如果发送端接收到3个以上的重复ACK,TCP就意识到数据发生丢失,需要重传。这个机制不需要等到重传定时器超时,所以叫作快速重传,而快速重传后没有使用慢启动算法,而是使用拥塞避免算法,所以这又叫作快速恢复算法。
超时重传RTO超时,TCP会重传数据包。TCP认为这种情况比较糟糕,反应也比较强烈:
(1)由于发生丢包,将慢启动阈值ssthresh设置为当前cwnd的一半,即ssthresh=cwnd/2;
(2)cwnd重置为1;
(3)进入慢启动过程。
最为早期的TCPTahoe算法就是使用上述处理
办法,但是由于一丢包就一切重来,导致cwnd重置为1,十分不利于网络数据的稳定传递。
所以,TCPReno算法进行了优化。当收到3个重复确认ACK时,TCP就开启快速重传算法,而不用等到RTO超时再进行重传:
(1)cwnd大小缩小为当前的一半;(2)ssthresh设置为缩小后的cwnd值;(3)然后进入快速恢复算法(FastRecovery)。
4.快速恢复算法(FastRecovery)
TCPTahoe是早期的算法,所以没有快速恢复算法,而Reno算法有。在进入快速恢复之前,cwnd和ssthresh已经被更改为原有cwnd的一半。快速恢复算法的逻辑如下:
(1)cwnd=cwnd+3*MSS,加3*MSS的原因是因为收到3个重复的ACK;
(2)重传DACKs指定的数据包;(3)如果再收到DACKs,那么cwnd值增加1;(4)如果收到新的ACK,表明重传的包成功了,
那么退出快速恢复算法。将cwnd设置为ssthresh,然如图4所示,当第5个包发生了丢失,所以导致接收方接收到3个重复ACK,也就是ACK5。所以将ssthresh设置为当时cwnd的一半,也就是6/2=3,cwnd设置为3+3=6。然后重传第5个包。当收到新的ACK时,也就是ACK11,则退出快速恢复阶段,将cwnd重新设置为当前的ssthresh,也就是3,然后进入拥塞避免算法阶段。
本文为大家大致描述了TCP拥塞控制的一些机制,但是这些拥塞控制还是有很多缺陷和待优化的地方,业界也在不断推出新的拥塞控制算法,比如说谷歌的BBR。这些我们以后也会继续探讨,请大家继续关注。
