空-谱协同正则化稀疏超图嵌入的高光谱图像分类
2019-07-12陈美利王丽华李政英
黄 鸿,陈美利,王丽华,李政英
重庆大学光电技术与系统教育部重点实验室,重庆 400044
高光谱遥感图像通过从可见光到短波红外区域的密集光谱采样,可在数百个窄而连续的相邻光谱波段中提供空间场景,包含了丰富的空间、辐射和光谱信息,为地物精细分类提供了强有力的探测手段,目前已广泛应用于矿物勘探、环境监测、精准农业和目标识别等领域[1-2]。然而,高光谱数据具有数据量大、波段数多、波段间相关性强等特点,传统方法易导致“维数灾难”问题[3-4]。因此,如何减少波段数且尽量保留有用信息已成为高光谱遥感领域的研究热点问题。
维数约简是克服数据冗余的有效方法,可在降低数据维数的同时尽可能保留数据中的本征信息[5]。目前学者们提出了一系列的维数约简方法,如主成分分析(principal component analysis,PCA)[6]、线性判别分析(linear discriminant analysis,LDA)[7]、等距映射(isometric feature mapping,ISOMAP)[8]、局部线性嵌入(local linear embedding,LLE)[9]、邻域保持嵌入(neighborhood preserving embedding,NPE)[10]、拉普拉斯等距离映射(Laplacian eigenmaps,LE)[11]及局部保持投影(locality preserving projection,LPP)[12]。上述方法可统一在图嵌入框架(graph embedding,GE)[13-14]下,其异于如何定义本征图和惩罚图,但都为非监督方法,其分类性能受限。针对此问题,学者们通过将样本先验知识引入到图嵌入框架来改善分类性能,提出了边缘Fisher分析(marginal Fisher analysis,MFA)[15]和正则化局部判别嵌入(regularized local discriminant embedding,RLDE)[16]等监督学习方法,以提升分类精度。
然而,直接图嵌入方法只考虑数据间一元关系,在实际应用中高维数据通常具有复杂的多元几何结构[17-18]。为表征高维数据中的复杂结构,学者们试图引入超图学习来表示高光谱数据间的高阶关系。文献[19]提出了一种判别超-拉普拉斯投影(discriminant hyper-Laplacian projections,DHLP)方法,通过构造超图来获得超-拉普拉斯矩阵,实现维数约简。文献[20]提出了一种超图拉普拉斯联合稀疏化处理方法来分析像元的内在关系,以提取低维特征进行分类。
上述方法仅利用了样本的光谱信息,却忽略了像元之间的空间位置关系,而研究表明空-谱联合维数约简方法可明显提高地物分类性能。文献[21]通过空间自适应方法提取影像的空间特征和光谱特征,在分类精度和计算效率上均取得了较好效果。文献[22]提出了一种空-谱协同嵌入方法(spatial-spectral coordination embedding,SSCE),利用样本空间块替代单个样本度量数据间相似性,降低异类地物被选为近邻的概率,从而改善地物分类效果。与此同时,空间信息也被引入超图模型中,文献[17]提出了一种融合空-谱信息的超图嵌入方法,利用像元空间邻域构造超边,能有效提取低维特征,但忽视了像元的类别信息。在文献[23]中,通过像元波段选取提取扩展形态学特征,并与光谱信息融合来构建超图模型,提取嵌入特征以提升地物分类性能。上述空-谱联合维数约简方法,或是忽略了像元间多元几何结构关系,或是在构造超图模型时没有充分利用样本标签信息,限制了分类性能的进一步提升。
针对上述问题,本文提出了一种空-谱协同正则化稀疏超图嵌入方法(spatial-spectral regularized sparse hypergraph embedding,SSRSHE)。该方法运用稀疏系数自适应揭示数据间近邻关系,并结合类别信息构建正则化稀疏超图,从而有效表征高光谱数据的多元几何结构。同时,融入图像的空间信息,构造局部空间邻域散度来表征样本局部邻域结构,同时定义样本总体散度矩阵来保证数据全局信息,提取有效鉴别特征,实现维数约简。在Indian Pines和PaviaU高光谱数据集上验证了本文算法的有效性。
1 本文算法
假设文中高光谱数据集Z=[z1,z2,…,zi,…,zn]∈Rd×n,其中d为波段数,n为样本数,类别标签集L=[l1,l2,…,li,…,ln],li∈{1,2,…,u},其中u为样本类别数。低维嵌入特征可表示为Y=PTZ,Y∈Rτ×n,τ(τ< 为更好地理解维数约简算法,学者们提出了一种图嵌入框架(GE)来表示数据几何结构,并将PCA、LDA、ISOMAP、LLE、LE、NPE及LPP等算法统一到该框架中。在图嵌入框架下,需构建本征图和惩罚图两个无向图。本征图GI(V,WI)表征数据中需要保持的统计或几何性质,惩罚图GP(V,WP)描述数据中应避免的某种特性,其中V为顶点集,WI和WP分别为图GI和GP的权重矩阵,可通过简单法或热核函数来定义。 图嵌入框架意在低维空间中保留数据集的某些统计或几何属性,其低维嵌入特征可通过优化以下目标函数得到 (1) 直接图嵌入模型仅考虑了两点间一阶关系,而超图模型能有效表征数据间的多元特性[17]。超图模型可表示为GH=(VH,EH,WH),其中VH表示顶点集,EH为超边集,对应的相似权重矩阵是WH,以度量超边内各顶点间相关性。 为表示GH的内在关系,假设每一超边ei含有N(ei)个顶点,其权重表示为w(ei)∈EH,则关联矩阵H=[Hmn:h(em,vn)]∈R|EH|×|VH|、超边em的度d(em)和顶点vn的度d(vn)可分别定义为 (2) (3) (4) 综上,超图内每一超边由某一像元与其近邻点构成,揭示数据间内在多元关系。其对应的关联矩阵H,每行中的非零元素,描述每一超边内各点分布情况。超图通过多对顶点连通以表征邻域内顶点间多元结构,因而可更好地描述数据中多元关系。 为表征高光谱数据中的多元几何结构关系,并联合像元的空间-光谱信息,本文提出了一种空-谱协同正则化稀疏超图嵌入(SSRSHE)方法。首先利用样本的稀疏系数来自适应性选择其近邻,构建稀疏本征超图和惩罚超图来揭示高光谱数据间的多元结构。同时,依据空间一致性原理构造局部空间邻域散度以保持像元局部空间近邻关系,并采用样本总体散度来表征高光谱数据整体特性。在低维鉴别空间中,使类内数据尽可能聚集、类间数据尽可能发散,提取鉴别特征,提升地物分类性能。该算法的具体流程如图1所示。 图1 SSRSHE算法流程Fig.1 Flowchart of the proposed SSRSHE method 1.3.1 正则化稀疏超图模型构建 在构建超图时,首先需要选择合适的样本近邻点。目前的欧氏距离度量方法存在近邻点选取不准确及参数难以确定等问题,而稀疏表示具有自然鉴别力能自适应地揭示出数据的内在关系。某个样本可以由一个足够大的样本空间来近似线性表示,且表示系数大部分为零,只有极少数与该样本同类别数据对应的系数为非零,因此可反映数据的本征属性。 基于此,本文提出了一种正则化稀疏超图模型,首先通过稀疏表示[24]得到数据的稀疏系数矩阵,揭示数据内在关联特性,以自适应获取像元近邻。稀疏系数可通过以下l1范数求解 (5) 式中,ε为稀疏误差;E是全为1的向量。在具体计算中,可通过将式(5)问题进一步转化为Lasso问题求解[25],即可得到稀疏系数矩阵S=[s1,s2,…,sn]T。 图2为基于稀疏系数自适应选取近邻构造超边示意图。因稀疏系数可反映数据间相似性,对应系数非零则表示像元间具有相关性,其值越大则属于同类近邻点可能性越大。因此相比欧氏度量,利用稀疏系数自适应选择近邻能更为有效反映数据内蕴信息。 图2 基于稀疏系数的自适应选取近邻构造超边Fig.2 Construction of sparse hyperedge (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) 在低维映射空间中,为提取鉴别特征,应使同类数据尽可能聚集、不同类数据尽可能远离,因此目标函数可表示为 (16) (17) 由式(16)、式(17)中的目标函数,可进一步转化为以下最优化问题 (18) 在训练样本较少的情况下,式(18)易受奇异点影响。故在此引入正则化项,则式(18)中的优化问题可拓展为 (19) 式中,η(0<η<1)表示正则化参数。正则项ZZT用于保持样本的多样性。将ZLwZT对角化,以改善式(19)问题求解的稳定性,即其对应的特征值在较大时可自适应减小,在极小或是零时增大。因此,式中分母项矩阵满足非奇异性。假如η=0,式(19)即为式(18);若η=1,以单位矩阵替代对角矩阵,式(19)则等效为PCA。 1.3.2 局部空间邻域散度和总体散度计算 鉴于高光谱图像空间一致性特点,即在空间局部邻域内近邻属于同类概率较大。以像元zi:(xi,yi)为中心作方形窗口δ(zi),(xi,yi)为zi在图像中的空间坐标位置,则窗口为γ×γ(γ是正奇数)的空间邻域像元集可记作 δ(zi)={zim:(xm,ym)|xi-c yi-c (20) 式中,c=(γ-1)/2,zim:(xm,ym)对应空间邻域里第m个像元点。δ(zi)共有γ×γ个像元。则空间邻域距离可定义为 (21) (22) 此外,为揭示影像数据多样性,保持数据的整体结构,定义总体散度矩阵 (23) 1.3.3 空-谱协同低维嵌入 为在嵌入空间中提取低维空-谱鉴别特征,不仅要保持高光谱数据局部空间近邻结构,还需使超图中的类内数据聚集、类间数据远离。因此,式(19)、式(22)和式(23)可进一步转化为以下优化问题 (24) 式中,参数η,ξ∈[0,1];Mw=ξ[(1-η)Nw+ηdiag(diag(Nw))]+(1-ξ)A,用于表征类内与局部数据紧致性,Nw=ZLwZT;Mb=ξ[(1-η)Nb+ηZZT]+(1-ξ)B,用于表示类间与全局数据发散度,Nb=ZLbZT。 依据拉格朗日乘子法,式(24)可转换为以下广义特征值求解 MbP=λMwP (25) 将式(25)特征值降序排列,选取前τ个特征值对应的特征向量构成最优映射矩阵P=[p1,p2,…,pτ-1,pτ]。在低维空间里,测试样本ztest的空-谱协同特征是ytest=PTztest。 为验证本文算法的有效性,在公开的Indian Pines和PaviaU高光谱数据集上进行分类试验,并与相关的维数约简算法进行了对比。 (1) Indian Pines数据集为美国宇航局在1992年利用AVIRIS传感器拍摄位于美国Indian州西北100 km2范围的高光谱遥感影像,其尺寸为145×145像素,共220个波段,空间分辨率为20 m,剔除受水气(噪声)影响的波段后,余下200个波段用于试验。该数据集主要包含16类地物,其假彩色图和真实地物图如图3所示。 图3 Indian Pines高光谱图像Fig.3 Indian Pines hyperspectral image (2) PaviaU数据集为2002年采用ROSIS传感器拍摄的意大利北部的帕维亚大学周围的高光谱影像,其尺寸为610×340像素,空间分辨率为1.3 m,共有115个波段,去除受噪声影响严重的12个波段后,剩余103个波段用于对比试验。该数据集包括道路、砖块、屋顶和裸土等9类地物,图4为其假彩色图和真实地物图。 图4 PaviaU 高光谱图像Fig.4 University of Pavia hyperspectral image 在试验中,每次试验随机选取一定数目的样本用于训练,其余进行测试。鉴于在实际应用中,高光谱图像中存在部分地物类别样本数量非常少,例如在Indian Pines数据集中,Alfalfa(46)、Oats(20)、Stone-steel towers(93),括号中为对应的样本数。为避免出现某些类别选取训练样本所占比例过高或数量过少,在试验中设置如下:假设每类地物随机选取样本量为ni,Ni表示某类地物的总样本数,若ni≥Ni/2,则ni=Ni/2;若ni≤10,则定ni=10。通过采用各维数约简算法得到投影矩阵后,将所有样本投影到低维空间得到嵌入特征,并通过利用最近邻分类器(1-NN)进行分类。在每种试验条件下均进行10次重复试验,将总体分类精度(the overall accuracies,OAs)、平均分类精度(the average accuracies,AAs)及Kappa系数作为分类结果的评价指标。 试验中,将本文方法与PCA、LDA、MFA、LPP、RLDE、DHLP、SSCE、LPSNPE等维数约简算法进行比较,采用交叉验证方法获得各算法的最佳参数。SSCE在两个数据集中空间窗口均设置为5,SSCE和LPP的最近邻取5,DHLP中近邻数为9;RLDE和MFA的类内和类间近邻数分别为3、5,8、60。LDA的嵌入维数为u-1,u为类别数,其他算法的嵌入维数均设置为30。 为探索本文方法中参数η、ξ,空间窗口γ对分类精度的影响,从数据集中每类地物中随机选取5个样本进行训练,其余样本作为测试样本。令α=10,ε=0.006,η与ξ的取值范围均设置为{0,0.01,0.05,0.1,0.2,…,0.9,1},γ={3,5,…,39}。图5为本文SSRSHE算法在不同η和ξ值下的分类结果,图6是本文SSRSHE算法在不同γ下的分类结果。 由图5可知,随着ξ的增加,其分类精度随之增加而后达到平稳,但是ξ值过大时,分类精度有所下降。这是因为在SSRSHE中,ξ用于平衡光谱信息和空间结构在特征提取中作用,ξ过小时未能有效利用超图所表征的像元间的复杂多元结构关系,过大时则忽略了空间结构,也不利于鉴别特征提取。与此同时,尽管试验中每类样本数量仅有5个,但是在同一η值下,分类结果比较稳定,有利于实际场景应用。为平衡光谱信息与空间信息对分类性能的影响,依据试验结果,本文在Indian Pines数据集设置ξ为0.3,η为0.7;对于PaviaU数据集,设置η=0.5及ξ=0.2。 图5 SSRSHE在不同η和ξ参数值下的总体分类精度Fig.5 OAs of SSRSHE with different values of parameters η and ξ on Indian Pines and PaviaU data sets 图6 SSRSHE在不同空间窗口γ下的总体分类精度Fig.6 OAs of SSRSHE with different size γ on different data sets 由图6知,随着空间窗口γ变大,能利用的空间信息愈发丰富,分类精度随之增加;但γ过大时,空间窗口内包含来自于不同类数据的可能性增大,导致分类性能下降,且窗口过大,会导致计算复杂度增加。因此,综合考虑算法性能及计算效率,在Indian Pines数据集上设置γ=7,在PaviaU数据集上γ=15。 试验中,从Indian Pines数据集的每类地物里分别按照5、20、50、100、200样本数随机选取数据用于训练,剩余样本用于测试。采用各维数约简算法训练得到嵌入特征后,采用1-NN进行分类。表1为在不同样本数量下不同算法的总体分类精度和Kappa系数值。 表1 不同降维算法在Indian Pines数据集上的分类效果 Tab.1 Classification with different numbers of training data via different DR methods on Indian Pines data set 5总体分类精准度/(%)Kappa20总体分类精准度/(%)Kappa50总体分类精准度/(%)Kappa100总体分类精准度/(%)Kappa200总体分类精准度/(%)KappaRAW43.6±2.80.37254.9±1.70.49560.1±1.40.55263.6±0.90.58866.9±0.60.622PCA43.4±2.70.37054.9±1.60.49560.2±1.20.55363.9±0.80.59167.0±0.60.622LDA32.5±4.80.25351.6±1.90.45964.4±1.20.59971.0±0.50.67274.4±0.70.706LPP43.6±3.70.37154.5±1.80.49159.7±1.20.54662.7±1.00.57865.8±0.50.609MFA44.1±4.00.37757.1±1.60.52066.8±1.90.62570.8±1.10.66972.0±1.00.680RLDE41.7±3.70.35160.9±1.50.56169.8±1.40.65974.6±0.70.71178.4±0.60.751RSHE48.6±3.40.42263.2±1.90.58771.0±1.70.67277.1±0.90.73980.0±0.70.770DHLP44.1±3.80.37757.2±2.10.52268.9±1.20.64973.8±0.80.70277.6±0.70.741SSCE30.2±4.50.23069.7±1.00.65876.3±0.90.73079.1±0.50.76082.9±0.60.801LPSNPE60.2±3.50.59474.0±1.40.70679.3±0.70.75981.6±0.60.79184.2±0.60.817SSRSHE65.6±2.30.61574.8±1.20.70680.0±1.00.76582.9±1.00.80386.7±1.00.829 从表1可得知,各种维数约简算法的分类性能都随着训练样本数目的增大而不断提高,这是由于随着训练数据量的增加,蕴含的信息就越丰富,有利于特征提取。DHLP、RSHE等超图方法的分类精度大多数情况下均优于传统图嵌入方法,表明利用数据间的多元几何结构特性可有效提高分类精度。与此同时,SSCE、LPSNPE等空-谱类方法,通过融合样本数据的空间信息,其分类性能要优于PCA、LDA、LPP、MFA、RLDE等仅利用了光谱信息的图嵌入方法。在各种训练条件下SSRSHE方法的分类性能均优于其他算法,因为它利用了超图框架来表示各样本邻域内顶点间的多元几何关系,因而可更好描述数据中复杂邻域结构。同时SSRSHE将样本类别信息融入超图框架,分别构建了稀疏本征超图和惩罚超图,能充分揭示数据间的复杂判别多元关系,提取出更有效的低维鉴别特征,进一步提升分类精度。 为进一步探索SSRSHE对每种地物的分类性能,从Indian Pines数据集每一类里随机选择3%的像元为训练样本,余下数据用于测试。表2为不同维数约简算法对于每一种地物的总体分类精度、平均分类精度、Kappa系数及降维运行时间,其对应在整个数据集上的分类结果如图7所示。 表2 不同算法在Indian Pines数据集每类地物上的分类精度 Tab.2 Classification accuracy of different types of features on Indian Pines data set by different algorithms (%) 图7 在Indian Pines数据集上,各降维算法对应的全分类结果Fig.7 Classification map of different DR methods on Indian Pines data set 从表2可发现,SSRSHE的分类性能表现最佳,在每类上的总体分类精度、平均分类精度、Kappa值均优于其他方法,且对比SSCE算法,其运行效率快,优势明显。这是因为SSRSHE算超图学习,充分揭示了数据间高阶关系,以及像元空间特征的有效利用,有效表征了影像内蕴特性,提取的嵌入特征更具鉴别力,更有助于地物分类。同时,从图7可以看到,本文算法相比其他算法,在其分类结果图更趋于平滑,尤其在“Alfalfa”、“Soybeans-min”、“Stone-steel towers”等区域更明显。由此可见,本文算法基于空-谱信息与超图模型协同学习,实现有效鉴别特征提取,改善影像分类精度,确实具有一定实践意义。 在试验中,从每种地物中随机选取5、20、50、100、200个样本用于训练,其余数据用来测试,采用最近邻分类器进行分类。表3为在不同的训练样本数目下各维数约简算法对应的总体分类精度及Kappa值。 依据表3,在大多数训练条件下,DHLP、RSHE等超图方法和SSCE、LPSNPE等空-谱联合方法的分类结果要优于直接图嵌入方法,这表明超图学习和空-谱融合信息均有利于高光谱数据鉴别特征提取,有效改善地物分类性能。本文提出的SSRSHE方法在各种试验条件下,均具有最佳分类性能,这是因为其不仅通过超图学习发现高光谱数据中复杂结构,且有效融入了空间信息,在低维空间中使同类信息聚集、非同类信息远离,提高了数据可分性,进而有效提高地物分类效果。 为进一步分析SSRSHE方法在每种地物上的分类性能,从每类地物里随机选择5%的像元组成训练样本集,其他部分为测试样本集。表4反映了不同维数约简方法在每类地物的分类效果,图8则为各方法对整个PaviaU遥感图像分类的结果图。由表4可以看到,SSRSHE在大多数地物类别中的分类性能要优于其他方法,表明在影像地物分类过程中,SSRSHE算法可使同类数据的关联性,异物数据间奇异性增强,鉴别特征尤为突出,分类性能更佳。同时,在图8中,本文方法在“Asphalt”,“Meadows”,“Gravel”等地物区域的分类结果较为光滑,误分点较少,且运行时间并没大幅度增加,表明联合空-谱特性与超图学习的SSRSHE算法的地物分类性能有明显提升,更适合实际应用场景。 图8 在PaviaU数据集上,各降维算法对应的全分类结果Fig.8 Classification map of different DR methods on PaviaU data set 算法5总体分类精准度/(%)Kappa20总体分类精准度/(%)Kappa50总体分类精准度/(%)Kappa100总体分类精准度/(%)Kappa200总体分类精准度/(%)KappaRAW60.5±4.20.51266.4±2.40.58373.5±1.60.66376.4±0.80.69878.8±0.80.724PCA60.5±4.20.51266.5±2.20.58373.4±1.60.66276.4±0.80.69778.7±0.80.724LDA46.7±6.40.35159.6±1.80.49573.5±1.40.66278.9±0.90.72783.4±0.60.782LPP47.0±5.60.35459.3±2.60.50072.8±2.30.65478.3±1.30.72282.2±1.20.768MFA64.5±4.30.55569.2±4.50.61376.4±2.00.69978.1±2.40.71579.1±2.20.730RLDE64.4±3.20.55574.6±2.70.67777.9±2.20.71882.1±1.00.77084.8±1.00.802RSHE63.2±4.10.54075.4±2.30.68578.3±1.40.72083.4±0.90.78484.9±1.30.802DHLP56.8±8.00.47162.2±3.60.53070.8±2.10.62977.5±2.70.71180.2±1.50.742SSCE42.3±5.30.30963.3±2.90.54375.8±1.70.69282.7±1.20.81487.0±0.80.828LPSNPE68.0±4.20.60680.0±2.20.74786.3±1.30.82287.9±0.90.84289.9±0.60.877SSRSHE71.6±2.70.64682.6±2.30.77687.5±1.10.83790.0±1.50.88292.2±0.20.908 表4 不同算法在PaviaU数据集每种地物上的分类精度 针对传统图嵌入降维方法存在不能表征高光谱数据中的多元关系且未有效利用空间信息等问题,本文提出了一种空-谱协同正则化稀疏超图嵌入算法。本文算法利用稀疏系数实现自适应近邻选取,构建正则化稀疏超图模型来揭示高光谱数据间的多元几何结构。此外,考虑到保持样本的全局特性和局部邻域结构分别定义样本总体散度与局部空间邻域散度,实现空-谱鉴别特征提取。在Indian Pines和PaviaU高光谱数据集上试验结果表明,相比其他算法,在训练样本数较少时,SSRSHE地物分类性能仍有明显提升。但本文方法仅运用光谱信息构建超图,在下一步工作将考虑空-谱联合超图模型构建,以进一步提升地物分类效果。1.1 图嵌入学习

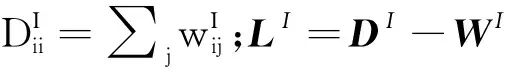
1.2 超图模型

1.3 SSRSHE算法



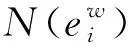


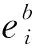



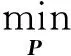





2 试验结果与分析
2.1 数据集


2.2 试验设置


2.3 Indian Pines试验结果与分析



2.4 PaviaU试验结果与分析



3 总 结
